信息存储
大多数计算机使用8位的块,或者字节(byte),作为最小的可寻址的内存单位,而不是访问内存中单独的位。机器级程序将内存视为一个非常大的字节数组,称为虚拟内存。内存的每个字节都由一个唯一的数字来标识,称为它的地址,所有可能地址的集合就称为虚拟地址空间。顾名思义,这个虚拟地址空间只是一个展现给机器级程序的概念性映像。实际的实现是将动态随机访问存储器(DRAM)、闪存、磁盘存储器、特殊硬件和操作系统软件结合起来,为程序提供一个看上去统一的字节数组。
十六进制表示法
一个字节由八位组成。在二进制表示法中,它的值域是0000 00002~1111 11112。如果看成十进制整数,它的值域就是010~25510。两种符号表示法对描述位模式来说都不是非常方便。二进制法太冗长,而十进制表示法与位模式转化很麻烦。代替的方法时,以16位基数,或者叫做十六进制数,来表示位模式。十六进制(简写为“hex”)使用数字0~9以及字符A~F来表示十六个可能的值。图1-1展示了十六个十进制数字对应的十进制值和二进制值。用十六进制书写,一个字节的值域为0016~FF16。

图1-1 十六进制法。每个十六进制数字都对十六个值中的一个进行了编码
在C语言中,以0x或0X开头的数字常量被认为是十六进制的值。字符A~F既可以大写也可以小写,甚至可以大小写混合。比如FA1D37B16可以写作0xFA1D73B、0xfa1d37b又或者0xFa1D37b。
字数据大小
每台计算机都有一个字长,指明指针数据的标称大小。因为虚拟地址是以这样的一个字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小。也就是说,对一个字长为w位的机器而言,虚拟地址的范围为0~2w-1,程序最多访问2w个字节。
大多数64位机器也可以运行32位机器编译的程序,这是一种向后兼容。因此,举例来说,当程序prog.c用如下伪指令编译后:
# gcc -m32 prog.c
该程序就可以在32位或64位机器上正确运行。另一方面,若程序用下述伪指令编译:
# gcc -m64 prog.c
那就只能在64位机器上运行。因此,我们将程序称为“32位程序”或“64位程序”时,区别在于该程序是如何编译的,而不是其运行的机器类型。
计算机和编译器支持多种不同方式编码的数字格式,如不同长度的整数和浮点数。比如,许多机器都有处理单个字节的指令,也有处理表示为2字节、4字节或者8字节整数的指令,还有些指令支持表示为4字节和8字节的浮点数。
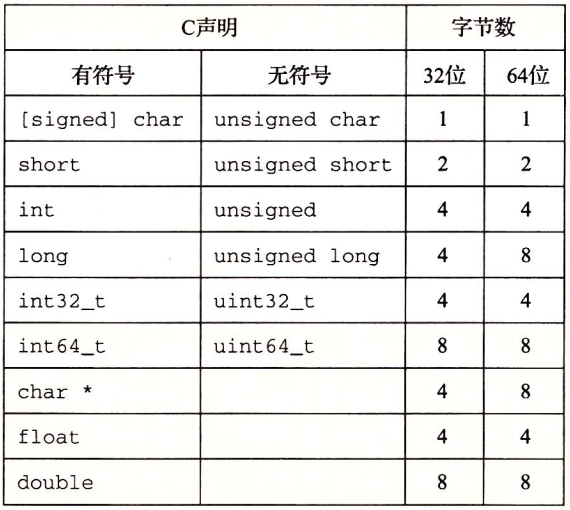
图1-2 基本C数据类型的典型大小(以字节为单位)。分配的字节数受程序是如何编译的影响而变化。
C语言支持整数和浮点数的多种数据格式。图1-2展示了为C语言各种数据类型分配的字节数。有些数据类型的确切字节数依赖于程序是如何被编译的。我们给出的是32位和64位程序的典型值。整数或者为有符号的,即可以表示负数、零和正数;或者为无符号的,即只能表示非负数。C的数据类型char表示一个单独的字节。尽管“char”是由于它被用来存储文本串中的单个字符这一事实而得名,但它也能被用来存储整数值。数据类型short、int和long可以提供各种数据大小。即使是为64位系统编译,数据类型int通常也只有4个字节。数据类型long一般在32位程序中为4字节,在64位程序中则为8字节。
为了避免由于依赖“典型”大小和不同编译器设置带来的奇怪行为,ISO C99引入了一类数据类型,其数据大小是固定的,不随编译器和机器设置而变化。其中就有数据类型int32_t和int64_t,它们分别为4个字节和8个字节。使用确定大小的整数类型是程序员准确控制数据表示的最佳途径。
大部分数据类型都编码为有符号数值,除非有前缀关键字unsigned或对确定大小的数据类型使用了特定的无符号声明。数据类型char是一个例外。尽管大多数编译器和机器将它们视为有符号数,但C标准不保证这一点。相反,正如方括号指示的那样,程序员应该用有符号字符的声明来保证其为一个字节的有符号数值。不过,在很多情况下,程序行为对数据类型char是有符号的还是无符号的并不敏感。
对关键字的顺序以及包括还是省略可选关键字来说,C语言允许存在多种形式。比如,下面所有的声明都是一个意思:
unsigned long unsigned long int long unsigned long unsigned int
图1-2还展示了指针(例如一个被声明为类型为“char *”的变量)使用程序的全字长。大多数机器还支持两种不同的浮点数格式:单精度(在C中声明为float)和双精度(在C中声明为double)。这些格式分别使用4字节和8字节。
程序员应该力图使他们的程序在不同的机器和编译器上可移植。可移植性的一个方面就是使程序对不同数据类型的确切大小不敏感。C语言标准对不同数据类型的数字范围设置了下界,但是却没有上界。在之前,32位机器和32位程序是主流的组合,许多程序的编写都假设为图1-2中32位程序的字节分配。随着64位机器的日益普及,在将这些程序移植到新机器上时,许多隐藏的对字长的依赖性就会显现出来,成为错误。比如,许多程序员假设一个声明为int类型的程序对象能被用来存储一个指针。这在大多数32位的机器上能正常工作,但是在一台64位的机器上却会导致问题。
寻址和字节顺序
对于跨越多字节的程序对象,我们必须建立两个规则:这个对象的地址是什么,以及在内存中如何排列这些字节。在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。例如,假设一个类型为int的变量x的地址为0x100,也就是说,地址表达式&x的值为0x100。那么,(假设数据类型int为32位表示)x的4个字节将被存储在内存的0x100、0x101、0x102和0x103位置。
排列表示一个对象的字节有两个通用的规则。考虑一个w位的整数,其位表示为[xw-1,xw-2,…,x1,x0],其中xw-1是最高有效位,而x0是最低有效位。假设w是8的倍数,这些位就能被分组成为字节,其中最高有效字节包含位[xw-1,xw-2,…,xw-8],而最低有效字节包含位[x7,x6,…,x0],其他字节包含中间的位。某些机器选择在内存中按照从最低有效字节到最高有效字节的顺序存储对象,而另一些机器则按照从最高有效字节到最低有效字节的顺序存储。前一种规则——最低有效字节在最前面的方式,称为小端法(little endian)。后一种规则——最高有效字节在最前面的方式,称为大端法(big endian)。
假设变量x的类型为int,位于地址0x100处,它的十六进制值为0x01234567。地址范围0x100~0x103的字节顺序依赖于机器的类型:

对于大多数应用程序员来说,其机器所使用的字节顺序是完全不可见的。无论为哪种类型的机器所编译的程序都会得到同样的结果。不过有时候,字节顺序会成为问题。首先是在不同类型的机器之间通过网络传送二进制数据时,一个常见的问题是当小端法机器产生的数据被发送到大端法机器或者反过来时,接收程序会发现,字里的字节成了反序的。为了避免这类问题,网络应用程序的代码编写必须遵守已建立的关于字节顺序的规则,以确保发送方机器将它的内部表示转换成网络标准,而接收方机器则将网络标准转换为它的内部表示。
当阅读表示整数数据的字节序列时字节顺序也很重要。这通常发生在检查机器级程序时。作为一个示例,从某个文件中摘出了下面这行代码,该文件给出了一个针对Intel x86-64处理器的机器级代码的文本表示:
4004d3: 01 05 43 0b 20 00 add %eax,0x200b43(%rip)
这一行是由反汇编器(disassembler)生成的,反汇编器是一种确定可执行程序文件所表示的指令序列的工具。这条命令表述的意思是:十六进制字节串01 05 43 0b 20 00是一条指令的字节级表示,这条指令是把一个字长的数据加到一个值上,该值的存储地址由0x200b43加上当前程序计数器的值得到,当前程序计数器的值即为下一条将要执行指令的地址。如果取出这个序列的最后4个字节:43 0b 20 00,并且按照相反的顺序写出,我们得到00 20 0b 43。去掉开头的0,得到值0x200b43,这就是右边的数值。当阅读像此类小端法机器生成的机器级程序表示时,经常会将字节按照相反的顺序显示。书写字节序列的自然方式是最低位字节在左边,而最高位字节在右边,这正好和通常书写数字时最高有效位在左边,最低有效位在右边的方式相反。
字节顺序变得重要的第三种情况是当编写规避正常的类型系统的程序时。在C语言中,可以通过使用强制类型转换(cast)或联合(union)来允许以一种数据类型引用一个对象,而这种数据类型与创建这个对象时定义的数据类型不同。大多数应用编程都强烈不推荐这种编码技巧,但是它们对系统级编程来说是非常有用,甚至是必需的。
下面展示了一段C代码,它使用强制类型转换来访问和打印不同程序对象的字节表示。我们用typedef将数据类型byte_pointer定义为一个指向类型为“unsigned char”的对象的指针。这样一个字节指针引用一个字节序列,其中每个字节都被认为是一个非负整数。第一个例程show_bytes的输入是一个字节序列的地址,它用一个字节指针以及一个字节数来指示。该字节数指定为数据类型size_t,表示数据结构大小的首选数据类型。show_bytes打印出每个以十六进制表示的字节。C格式化指令“%.2x”表明整数必须用至少两个数字的十六进制格式输出。
#include <stdio.h>
typedef unsigned char *byte_pointer;
void show_bytes(byte_pointer start, size_t len)
{
size_t i;
for (i = 0; i < len; i++)
printf(" %.2x", start[i]);
printf("
");
}
void show_int(int x)
{
show_bytes((byte_pointer)&x, sizeof(int));
}
void show_float(float x)
{
show_bytes((byte_pointer)&x, sizeof(float));
}
void show_pointer(void *x)
{
show_bytes((byte_pointer)&x, sizeof(void *));
}
过程show_int、show_float和show_pointer展示了如何使用程序show_bytes来分别输出类型为int、float和void *的C程序对象的字节表示。可以观察到它们仅仅传递给show_bytes一个指向它们参数x的指针&x,且这个指针被强制类型转换为“unsigned char *”。这种强制类型转换告诉编译器,程序应该把这个指针看成指向一个字节序列,而不是指向一个原始数据类型的对象。然后,这个指针会被看成是对象使用的最低字节地址。
这些过程使用C语言的运算符sizeof来确定对象使用的字节数。一般来说,表达式sizeof(T)返回存储一个类型为T的对象所需要的字节数。使用sizeof而不是一个固定的值,是向编写在不同机器类型上可移植的代码迈进了一步。
void test_show_bytes(int val)
{
int ival = val;
float fval = (float)ival;
int *pval = &ival;
show_int(ival);
show_float(fval);
show_pointer(pval);
}
图1-3为在不同机器上运行上述代码的结果。
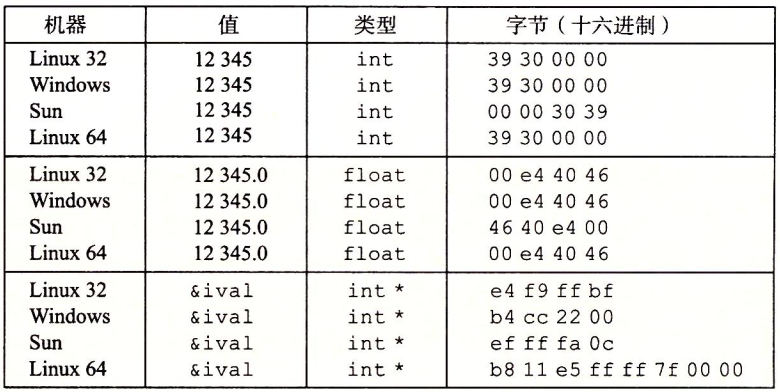
图1-3 不同数据值的字节表示。除了字节顺序以外,int和float的结果是一样的。指针值与机器相关
参数12345的十六进制表示为0x00003039。对于int类型的数据,除了字节顺序以外,我们在所有机器上都得到相同的结果。特别地,我们可以看到在Linux 32、Windows和Linux 64上,最低有效字节值0x39最先输出,这说明它们是小端法机器;而在Sun上最后输出,这说明Sun是大端法机器。同样地,float数据的字节,除了字节顺序以外,也都是相同的。另一方面,指针值却是完全不同的。不同的机器/操作系统配置使用不同的存储分配规则。一个值得注意的特性是Linux 32、Windows和Sun的机器使用4字节地址,而Linux 64使用8字节地址。
可以观察到,尽管浮点型和整型数据都是对数值12345编码,但是它们有截然不同的字节模式:整型为0x00003039,而浮点数为0x4640E400。一般而言,这两种格式使用不同的编码方法。如果我们将这些十六进制模式扩展为二进制形式,并且适当地将它们移位,就会发现一个有13个相匹配的位的序列,用一串星号标识出来:

这并不是巧合。当我们研究浮点数格式时,还将再回到这个例子。
布尔代数
布尔注意到通过将逻辑值TRUE(真)和FALSE(假)编码为二进制值1和0,能够设计出一种代数,以研究逻辑推理的基本原则。

图1-4 布尔代数的运算
图1-4中的运算符~、&、|、^分别表示逻辑运算NOT、AND、OR、EXCLUSIVE-OR。
C语言的一个很有用的特性就是它支持按位布尔运算。事实上,我们在布尔运算中使用的那些符号就是C语言所使用的:就是OR(或),&就是AND(与),~就是NOT(取反),而^就是EXCLUSIVE-OR(异或)。这些运算能运用到任何“整型”的数据类型上,包括图1-2所示内容。以下是一些对char数据类型表达式求值的例子:

正如示例说明的那样,确定一个位级表达式的结果最好的方法,就是将十六进制的参数扩展成二进制表示并执行二进制运算,然后再转换回十六进制。
C语言中的位级运算
C语言的一个很有用的特性就是它支持按位布尔运算。事实上,我们在布尔运算中使用的那些符号就是C语言所使用的:就是OR(或),&就是AND(与),~就是NOT(取反),而^就是EXCLUSIVE-OR(异或)。这些运算能运用到任何“整型”的数据类型上,包括图1-2所示内容。以下是一些对char数据类型表达式求值的例子:
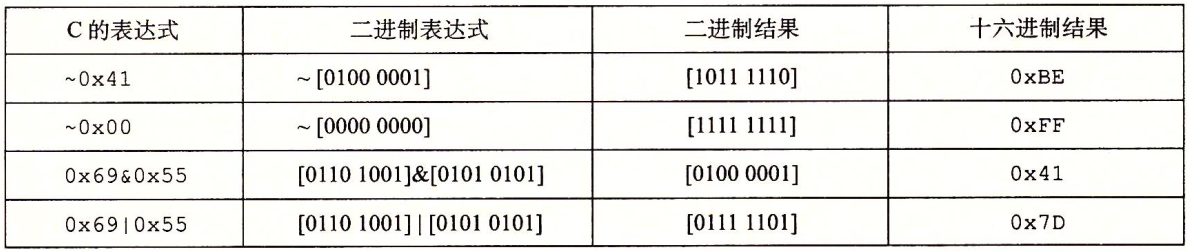
正如示例说明的那样,确定一个位级表达式的结果最好的方法,就是将十六进制的参数扩展成二进制表示并执行二进制运算,然后再转换回十六进制。
C语言中的逻辑运算
C语言还提供了一组逻辑运算符‖、&&和!,分别对应于命题逻辑中的OR、AND和NOT运算。逻辑运算很容易和位级运算相混淆,但是它们的功能是完全不同的。逻辑运算认为所有非零的参数都表示TRUE,而参数0表示FALSE。它们返回1或者0,分别表示结果为TRUE或者为FALSE。以下是一些表达式求值的示例。
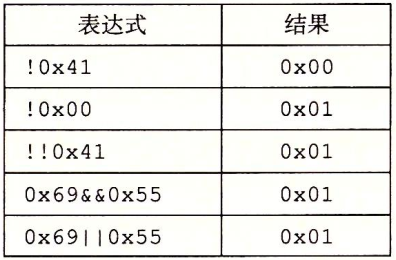
可以观察到,按位运算只有在特殊情况下,也就是参数被限制为0或者1时,才和与其对应的逻辑运算有相同的行为。
逻辑运算符&&和‖与它们对应的位级运算&和之间第二个重要的区别是,如果对第一个参数求值就能确定表达式的结果,那么逻辑运算符就不会对第二个参数求值。因此,例如,表达式a&&5/a将不会造成被零除,而表达式p&&*p++也不会导致间接引用空指针。
C语言中的移位运算
C语言还提供了一组移位运算,向左或者向右移动位模式。对于一个位表示为[xw-1,xw-2,…,x0]的操作数x,C表达式x<<k会生成一个值,其位表示为[xw-k-1,xw-k-2,…,x0,0,…,0]。也就是说,x向左移动k位,丢弃最高的k位,并在右端补k个0。移位量应该是一个0~w-1之间的值。移位运算是从左至右可结合的,所以x<<j<<k等价于(x<<j)<<k。
有一个相应的右移运算x>>k,但是它的行为有点微妙。一般而言,机器支持两种形式的右移:逻辑右移和算术右移。逻辑右移在左端补k个0,得到的结果是[0,…,0,xw-1,xw-2,…,xk]。算术右移是在左端补k个最高有效位的值,得到的结果是[xw-1,…,xw-1,xw-1,xw-2,…,xk]。这种做法看上去可能有点奇特,但是我们会发现它对有符号整数数据的运算非常有用。
让我们来看一个例子,下面的表给出了对一个8位参数x的两个不同的值做不同的移位操作得到的结果:

斜体的数字表示的是最右端(左移)或最左端(右移)填充的值。可以看到除了一个条目之外,其他的都包含填充0。唯一的例外是算术右移[10010101]的情况。因为操作数的最高位是1,填充的值就是1。
C语言标准并没有明确定义对于有符号数应该使用哪种类型的右移——算术右移或者逻辑右移都可以。不幸地,这就意味着任何假设一种或者另一种右移形式的代码都可能会遇到可移植性问题。然而,实际上,几乎所有的编译器/机器组合都对有符号数使用算术右移,且许多程序员也都假设机器会使用这种右移。另一方面,对于无符号数,右移必须是逻辑的。
与C相比,Java对于如何进行右移有明确的定义。表达是x>>k会将x算术右移k个位置,而x>>>k会对x做逻辑右移。