cgroups资源限制
上一节中Docker背后的内核知识(一),我们了解了Docker背后使用的资源隔离技术namespace,通过系统调用构建了一个相对隔离的shell环境,也可以称之为简单的“容器”。这一节将讲解另一个强大的内核工具——cgroups。它不仅可以限制被namespace隔离起来的资源,还可以为资源设置权重、计算使用量、操控任务(进程或线程)开启和暂停等等。在介绍完基本概念后,将详细讲解Docker中使用到的cgroups内容。
cgroups是什么
cgroups(Control Groups)最初叫Process Container,由Google工程师(Paul Menage和Rohit Seth)于2006年提出,后来因为Container有多重含义容易引起误解,就在2007年更名为Control Groups,并被整合进Linux内核。顾名思义就是把进程放到一个组里面统一加以控制。官方的定义如下:
cgroups是Linux内核提供的一种机制,这种机制可以根据需求把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。
通俗的来说,cgroups可以限制、记录任务组使用的物理资源(包括:CPU、Memory、IO等),为容器实现虚拟化提供了基本保证,是构建Docker等一系列虚拟化管理工具的基石。
对开发者来说,cgroups有如下四个特点:
- cgroups的API以一个伪文件系统的方式实现,用户态的程序可以通过文件操作实现cgroups的组织管理。
- cgroups的组织管理操作单元可以细粒度到线程级别,用户态代码可以创建和销毁cgroup,从而实现资源再分配和管理。
- 所有资源管理的功能都以子系统的方式实现,接口统一。
- 子进程创建之初与其父进程处于同一个cgroups的控制组。
本质上来说,cgroups是内核附加在程序上的一系列钩子(hooks),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。
cgroups的作用
实现cgroups的主要目的是为不同用户层面的资源管理,提供一个统一化的接口。从单个进程的资源控制到操作系统层面的虚拟化。cgroups提供了以下四大功能:
- 资源限制:cgroups可以对任务使用的资源总额进行限制。如设定应用运行时使用内存的上限,一旦超过这个配额就发出OOM(Out of Memory)。
- 优先级分配:通过分配的CPU时间片数量及硬盘IO带宽大小,实际上就相当于控制了任务运行的优先级。
- 资源统计: cgroups可以统计系统的资源使用量,如CPU使用时长、内存用量等等,这个功能非常适用于计费。
- 任务控制:cgroups可以对任务执行挂起、恢复等操作。
过去有一段时间,内核开发者甚至把namespace也作为一个cgroups的子系统加入进来,也就是说cgroups曾经甚至还包含了资源隔离的能力。但是资源隔离会给cgroups带来许多问题,如pid namespace加入后,PID在循环出现的时候,cgroup会出现了命名冲突、cgroup创建后进入新的namespace导致其他子系统资源脱离了控制等等,所以在2011年就被移除了。
术语表
- task(任务):在cgroups的术语中,任务表示系统的一个进程或线程。
- cgroup(控制组):cgroups 中的资源控制都以cgroup为单位实现。cgroup表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个cgroup,也可以从某个cgroup迁移到另外一个cgroup。
- subsystem(子系统):cgroups中的子系统就是一个资源调度控制器。比如CPU子系统可以控制CPU时间分配,内存子系统可以限制cgroup内存使用量。
- hierarchy(层级):层级由一系列cgroup以一个树状结构排列而成,每个层级通过绑定对应的子系统进行资源控制。层级中的cgroup节点可以包含零或多个子节点,子节点继承父节点挂载的属性。整个系统可以有多个层级。
组织结构与基本规则
传统的Unix进程管理,实际上是先启动init进程作为根节点,再由init节点创建子进程作为子节点,而每个子节点又可以创建新的子节点,如此往复,形成一个树状结构。而系统中的多个cgroups也构成类似的树状结构,子节点从父节点继承属性。
它们最大的不同在于,系统中多个cgroup构成的层级并非单根结构,可以允许存在多个。如果任务模型是由init作为根节点构成的一棵树,那么系统中的多个cgroup则是由多个层级构成的森林。这样做的目的也很好理解,如果只有一个层级,那么所有的任务都将被迫绑定其上的所有子系统,这会给某些任务造成不必要的限制。在Doccker中,每个子系统独自构成一个层级,这样做非常易于管理。
了解了cgroups的组织结构,我们再来了解cgroups、任务、子系统、层级四者间的相互关系及其基本规则。
- 规则1: 同一个层级可以附加一个或多个子系统。如下图1-4,CPU和Memory的子系统附加到了一个层级。
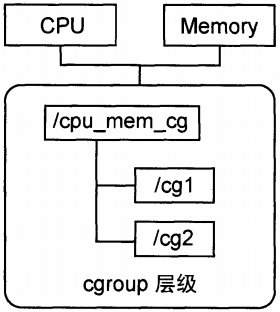
图1-4 同一个层级可以附加一个或多个子系统
- 规则2: 一个子系统可以附加到多个层级,当且仅当这些层级只有这唯一一个子系统时。如图1-5小圈中的数字表示子系统附加的时间顺序,CPU 子系统附加到层级A的同时不能再附加到层级B,因为层级B已经附加了内存子系统。如果层级B没有附加过内存子系统,那么CPU 子系统同时附加到两个层级是允许的。

图1-5 一个已经附加在某个层级上的子系统不能附加到其他含有别的子系统的层级上
- 规则3: 系统每次新建一个层级时,该系统上的所有任务默认构成了这个新建的层级的初始化cgroup,这个cgroup也称为root cgroup。对于创建的每个层级,任务只能存在于其中一个cgroup中,即一个任务不能存在于同一个层级的不同cgroup中,但是一个任务可以存在在不同层级中的多个cgroup中。如果操作时把一个任务添加到同一个层级中的另一个cgroup中,则会从第一个cgroup中移除。在图1-6中可以看到,httpd进程已经加入到层级 A中的/cg1而不能加入同一个层级中的/cg2,但是可以加入层级B中的/cg3。

图1-6 一个任务不能属于同一个层级的不同cgroup
- 规则4: 任务在fork/clone自身时创建的子任务默认与原任务在同一个cgroup中,但是子任务允许被移动到不同的cgroup中。即fork/clone完成后,父子任务间在cgroup方面是互不影响的。图1-7中小圈中的数字表示任务出现的时间顺序,当httpd刚fork出另一个httpd时,两者在同一个层级中的同一个cgroup中。但是随后如果PID为4840的httpd需要移动到其他cgroup也是可以的,因为父子任务间已经独立。总结起来就是:初始化时子任务与父任务在同一个cgroup,但是这种关系随后可以改变。

图1-7 刚fork/clone出的子任务在初始状态与其父任务处于同一个cgroup
子系统简介
子系统实际上就是cgroups的资源控制系统,每种子系统独立地控制一种资源,目前Docker使用如下九种子系统,其中,net_cls任务子系统在内核中已经广泛实现,但是Docker尚未使用。以下是它们的用途:
- blkio:任务可以为块设备设定输入/输出限制,比如物理驱动设备(包括磁盘、固态硬盘、USB等)。
- cpu:任务使用调度程序控制任务对CPU的使用。
- cpuacct:自动生成cgroup中任务对CPU资源使用情况的报告。
- cpuset:可以为cgroup中的任务分配独立的CPU(此处针对多处理器系统)和内存。
- devices:可以开启或关闭cgroup中任务对设备的访问。
- freezer:可以挂起或恢复cgroup中的任务。
- memory:可以设定cgroup中任务对内存使用量的限定,并且自动生成这些任务对内存资源使用情况的报告。
- perfevent:使用后使cgroup中的任务可以进行统一的性能测试。
- net_cls:Docker没有直接使用它,它通过使用等级识别符(classid)标记网络数据包,从而允许Linux流量控制程序(Traffic Controller,TC)识别从具体cgroup中生成的数据包。
上述子系统如何使用虽然很重要,但Docker并没有对cgroup本身做增强,容器用户一般也不需要直接操作cgroup。Linux中cgroup的实现形式表现为一个文件系统,因此需要mount这个文件系统才能够使用,挂载成功后,就能看到各类子系统。
# mount -t cgroup cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
在/sys/fs/cgroup/cpu的cpu子目录下创建控制组,控制组目录创建完成后,它下面就会有很多类似的文件了。
# cd /sys/fs/cgroup/cpu # mkdir cg1 # ls cg1/ cgroup.clone_children cgroup.procs cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release cgroup.event_control cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
下面的例子展示如何限制当前shell的进程ID(PID)的CPU使用配额:
# echo $$ 14113 # echo 14113 >> /sys/fs/cgroup/cpu/cg1/tasks #限制14113进程 # echo 2000 > /sys/fs/cgroup/cpu/cg1/cpu.cfs_quota_us #将CPU限制为最高使用20%
在Docker的实现中,Docker daemon会在单独挂载了每一个子系统的控制目录(比如/sys/fs/cgroup/cpu)下创建一个名为docker的控制组,然后在docker控制组里面,再为每个容器创建一个以容器ID为名称的容器控制组,这个容器里的所有进程的进程号都会写到该控制组tasks中,并且在控制文件(比如cpu.cfs_quota_us)中写入预设的限制参数值。
cgroups实现方式及工作原理简介
在对cgroups规则和子系统有一定了解后,下面简单介绍操作系统内核级别上cgroups的工作原理。cgroups的实现本质上是给系统进程挂上钩子,当任务运行的过程中涉及到某个资源时,就会触发钩子上所附带的子系统进行检测,根据资源类别的不同,使用对应的技术进行资源限制和优先级分配。
cgroups如何判断资源超限及超出限额之后的措施
对于不同的系统资源,cgroups提供了统一的接口对资源进行控制和统计,但限制的具体方式则不尽相同。比如memory子系统,会在描述内存状态的“mm_struct”结构体中记录它所属的cgroup,当进程需要申请更多内存时,就会触发cgroup用量检测,用量超过cgroup规定的限额,则拒绝用户的内存申请,否则就给予相应内存并在cgroup的统计信息中记录。实际实现要比以上描述复杂得多,不仅需考虑内存的分配与回收,还需考虑不同类型的内存如cache (缓存)和swap(交换区内存拓展)等。
进程所需的内存超过它所属的cgroup最大限额以后,如果设置了OOM Control(内存超限控制),那么进程就会收到OOM信号并结束;否则进程就会被挂起,进人睡眠状态,直到cgroup中其他进程释放了足够的内存资源为止。Docker中默认是开启OOM Control的。其他子系统的实现与此类似,cgroups提供了多种资源限制的策略供用户选择。
cgnmp与任务之间的关联关系
实现上, cgroup与任务之间是多对多的关系,所以它们并不直接关联,而是通过一个中间结构把双向的关联信息记录起来。每个任务结构体task_struct中都包含了一个指针,可以査询到对应cgroup的情况,同时也可以査询到各个子系统的状态,这些子系统状态中也包含了找到任务的指针,不同类型的子系统按需定义本身的控制信息结构体,最终在自定义的结构体中把子系统状态指针包含进去,然后内核通过container_of(这个宏可以通过一个结构体的成员找到结构体自身)等宏定义来获取对应的结构体,关联到任务,以此达到资源限制目的。同时,为了让cgroups便于用户理解和使用,也为了用精简的内核代码为cgroup提供熟悉的权限和命名空间管理,内核开发者们按照Linux虚拟文件系统转换器(VirtualFilesystem Switch, VFS)接口实现了一套名为cgroup的文件系统,非常巧妙地用来表示cgroups的层级概念,把各个子系统的实现都封装到文件系统的各项操作中。
Docker在使用cgroup时的注意事项
在实际的使用过程中,Docker需要通过挂载cgroup文件系统新建一个层级结构,挂载时指定要绑定的子系统。把cgroup文件系统挂载上以后,就可以像操作文件一样对cgroups的层级进行浏览和操作管理(包括权限管理、 子文件管理等)。除了cgroup文件系统以外,内核没有为cgroups的访问和操作添加任何系统凋用。
如果新建的层级结构要绑定的子系统与目前已经存在的层级结构完全相同,那么新的挂载会重用原来已经存在的那一套(指向相同的css_set)。否则,如果要绑定的子系统已经被别的层级绑定,就会返回挂载失败的错误。如果一切顺利,挂载完成后层级就被激活并与相应子系统关联起来,可以开始使用了。
目前无法将一个新的子系统绑定到激活的层级上,或者从一个激活的层级中解除某个子系统的绑定。
当一个顶层的cgroup文件系统被卸载(umount)时,如果其中创建过深层次的后代cgroup目录,那么就算上层的cgroup被卸载了,层级也是激活状态,其后代cgroup中的配置依旧有效。只有递归式地卸载层级中的所有cgroup,那个层级才会被真正删除。
在创建的层级中创建文件夹,就类似于fork了一个后代cgroup,后代cgroup中默认继承原有cgroup中的配置属性,但是可以根据需求对配罝参数进行调整。这样就把一个大的cgroup系统分割成一个个嵌套的、可动态变化的“软分区”。
/sys/fs/cgroup/cpu/docker/<container-ID>下文件的作用
前面已经说过,以资源开头(比如cpu.shares)的文件都是用来限制这个cgroup下任务的可用的配置文件。一个cgroup创建完成,不管绑定了何种子系统,其目录下都会生成以下几个文件,用来描述cgroup的相应信息。同样,把相应信息写入这些配置文件就可以生效。
一个cgroup创建完成,不管绑定了何种子系统,其日录下都会生成以下几个文件,用来描述cgroup的相应信息。同样,把相应信息写入这些配置文件就可以生效,内容如下:
- tasks:这个文件中罗列了所有在该cgroup中任务的TID,即所有进程或线程的ID。该文件并不保证任务的TID有序,把一个任务的TID写到这个文件中就意味着把这个任务加入这个cgroup中,如果这个任务所在的任务组与其不在同一个cgroup, 那么会在 cgroup.procs文件里记录一个该任务所在任务组的TGID值,但是该任务组的其他任务并不受影响。
- cgroup.procs:这个文件罗列所有在该cgroup中的TGID (线程组ID),即线程组中第一个进程的PID。该文件并不保证TGID有序和无重复。写一个TGID到这个文件就意味着把与其相关的线程都加到这个cgroup中。
- notify_on_release:填0或1,表示是否在cgroup中最后一个任务退出时通知运行release agent,默认情况下是0,表示不运行。
- release_agent:指定release agent执行脚本的文件路径(该文件在最顶cgroup目录中存在),这个脚本通常用于自动化卸载无用的cgroup。