1 分类
分类是将事物按特性进行分类,例如将手写数字图片分类为对应的数字。
1.1 MINIST数字图片集分类
MINST就是一个70000张规格较小的手写数字图片,如何将他们分类为对应的数字?MINIST这个数据集是由矩阵数组结构,70000个矩阵,每个矩阵28*28=784,每个点代表一个像素值,取值范围在0-256之间。

(1)获取数据集
Scikit-Learn 提供了许多辅助函数,以便于下载流行的数据集。
from sklearn.datasets import fetch_mldata
>>> mnist = fetch_mldata('MNIST original')#获取数字数据集
>>> mnist {'COL_NAMES': ['label', 'data'], 'DESCR': 'mldata.org dataset: mnist-original', 'data': array([[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]], dtype=uint8), 'target': array([ 0., 0., 0., ..., 9., 9., 9.])}
data是数据集,target是目标数字,也就是每个图片矩阵代表的真实数字。
(2)获取其中一个图片数据转换后画图显示
x, y = mnist["data"], mnist["target"] #获取数据集中的数据
%matplotlib inline#声明使用jupyter的后端渲染图片
import matplotlib import matplotlib.pyplot as plt #引入画图
some_digit = X[36000] #取第36000个数据,是一个784的长形数组
some_digit_image = some_digit.reshape(28, 28) #转换为28*28的矩阵
plt.imshow(some_digit_image, cmap = matplotlib.cm.binary, interpolation="nearest") plt.axis("off") plt.show()#画出矩阵图片显示数字
(3)准备数据训练
分成了一个训练集(前 60000 张图片)和一个测试集(最后 10000 张图片),冒号在前表示取前60000之前的数据,冒号在后表示取60000之后的数据。
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000],y[60000:]
打乱训练集,洗牌,避免不均匀分布。
import numpy as np
shuffle_index = np.random.permutation(60000) X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
1.2 二分类器训练
二分类器就是是和否的分类,比较简单。
(1)首先获取训练集和测试集中的为5的数据子集
y_train_5 = (y_train == 5) # True for all 5s, False for all other
digits. y_test_5 = (y_test == 5)
(2)用Scikit-Learn 的 SGDClassifier分类器去训练。这个分类器能够高效地处理非常大的数据 集。可以一次只处理一条数据,适合在线学习。
from sklearn.linear_model import SGDClassifier #引入
sgd_clf = SGDClassifier(random_state=42) #创建分类器对象
sgd_clf.fit(X_train, y_train_5)#训练
sgd_clf.predict([some_digit]) #测试
array([ True], dtype=bool)#测试结果正确
1.3 性能评估
1.3.1 使用交叉验证评估性能
让我们使用 cross_val_score() 函数来评估 SGDClassifier 模型,同时使用K折交叉验证,此 处让 k=3 。即两组训练,一组测试,共测试三轮。
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")
array([ 0.9502 , 0.96565, 0.96495]
1.3.2 混淆矩阵
(1)混淆矩阵的定义
混淆矩阵是指列举出判断错误和判断正确的次数的矩阵。例如上面的二分器,判断为非5的正确的和错误,已经判断为5的正确的和错误的。得到一个2*2的矩阵。为了计算混淆矩阵,首先你需要有一系列的预测值,这样才能将预测值与真实值做比较。
(2)获取预测值
from sklearn.model_selection import cross_val_predict y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
cross_val_predict() 也使用 K折交叉验证。返回基于每一个测试折做出的一个预测值。
(3)根据预测值和实际值生成混淆矩阵
在使用 confusion_matrix() 函数,你将会得到一个混淆矩阵。传递目标类(y_train_5)和预 测类( y_train_pred )给它。
>>> from sklearn.metrics import confusion_matrix
>>> confusion_matrix(y_train_5, y_train_pred)
array([[53272, 1307],
[ 1077, 4344]])
53272表示判断为正确的非5(true negative),1307表示判断为错误的非5(false negative)。1077表示判断为错误的5(false positive),4344表示判断为正确的5(true positive)。
(4)准确率和召回率定义
准确率(precision):true positive/( true positive+ false positive)=4344/(1077+4344)
召回率(recall):也叫做敏 感度(sensitivity)或者真正例率(true positive rate, TPR)
recall=ture positive/(true postive+false negative)=4344/(4344+1307)
(1) 准确率和召回率函数计算
Scikit-Learn 提供了一些函数去计算分类器的指标,包括准确率和召回率。
>>> from sklearn.metrics import precision_score, recall_score
>>> precision_score(y_train_5, y_pred) # == 4344 / (4344 + 1307) 0.76871350203503808
>>> recall_score(y_train_5, y_train_pred) # == 4344 / (4344 + 1077) 0.79136690647482011
(2) 调和平均值F1
常结合准确率和召回率来综合的判断算法的准确性。还需要综合实际应用场景,综合考虑采用哪种作为准确性的判断的需要。当准确性和召回率都高的时候,调和平均值才会高。
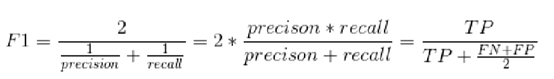
1.3.3 准确性和召回率的折中
(1)准确性和召回率不能同时提升?
通常情况下提高准确性会降低召回率,反之亦然,即他们是互斥的。为什么准确性和召回率不能同时提升?按照公式将false positive和false negative值都减小不就可以同时提高准确性和召回率,理想情况下,false positive和false negative都为0,准确性和召回率都为100%,为什么不能同时提高呢?
precision=true positive/( true positive+ false positive)=4344/(1077+4344)
recall=ture positive/(true postive+false negative)=4344/(4344+1307)
(2)原因分析
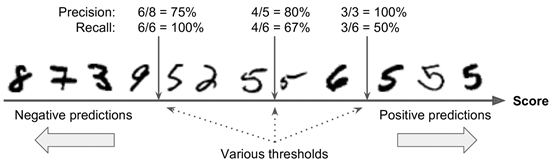
如下图所示, SGDClassifier分类器会对分析的数据进行评分,然后按照分数从小到大排列,设定一个阈值,大于阈值时判定为positive,小于阈值判定为negative。阈值越大准确性越高,但是同时有些是5的数据被判定到negative中,变成false negative,虽然准确性达到100%,但是false negative的数量也增加了,召回率变成50%。
(3)获取单个数据评分值
Scikit-Learn 不让你直接设置阈值,但是它给你提供了获取决策分数的方法decision_function()。这个方法返回每一个样例的分数值,你自己设置阈值去预测。
>>>some_digit = X[36000]#取一个数据
>>> y_score = sgd_clf.decision_function([some_digit])#获取这个数据的评分值
>>> y_scores #显示评分值
array([ 161855.74572176])
>>> threshold = 0 #设置阈值为0
>>> y_some_digit_pred=(y_scores>threshold) #布尔值赋值显示y_score大于0所以为true
array([ True], dtype=bool)
>>> threshold = 200000#重新设置阈值200000
>>> y_some_digit_pred =(y_score >threshold) # y_score小于阈值
>>> y_some_digit_pred array([False], dtype=bool)#得出false
(1) 获取所有数据的评分值
用cross_val_predict()交叉预测方法,设置method="decision_function",得到的不是预测值,而是得到每一个样例的分数值。
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function")
(5)根据评分调用函数precision_recall_curve计算准确率和召回率
现在有了这些分数值。对于任何可能的阈值,使用 precision_recall_curve() ,你都可以计算 准确率和召回率:
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
(6)定义画图函数画出准确率和召回率相对于不同阈值的曲线
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(thresholds, precisions[:-1], "b--", label="Precision") plt.plot(thresholds, recalls[:-1], "g-", label="Recall") plt.xlabel("Threshold")
plt.legend(loc="upper left")
plt.ylim([0, 1])
plot_precision_recall_vs_threshold(precisions, recalls, thresholds) plt.show()
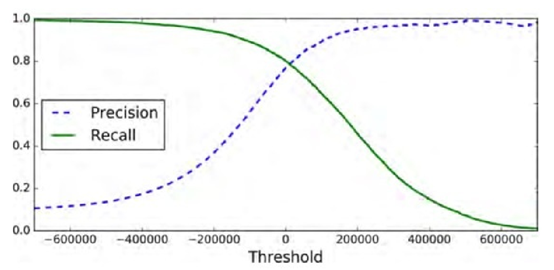
你可以画出准确率和召回率的曲线图,在曲线图上根据实际项目应用确定准确率和召回率。
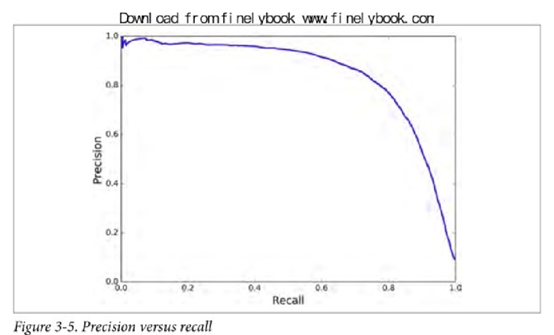
1.3.4 ROC曲线
(1)定义
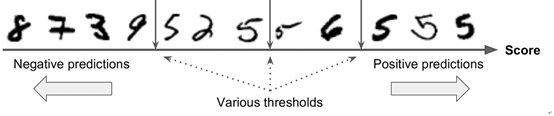
ROC(Receiver Operating Characteristic)曲线是横坐标为假正率,纵坐标为真正率的曲线图。假正率是指判为真的当中假的数量,站总的假的数量的比值。真正率是指判为真的当中真的数量占总的真的数量的比值,和召回率意义一样。还用之前的例子,如下图所示,共有12个数字,其中6个是真5,其他6个是假5。左一位置处,真正率为6/6=100%,假正率为2/6的33.33%。中间位置,真正率为4/6=66.66%,假正率为1/6=16.67%。右侧位置处,真正率为3/6=50%,假正率为0/6=0%。
(2) 曲线下方面积比较分类器性能
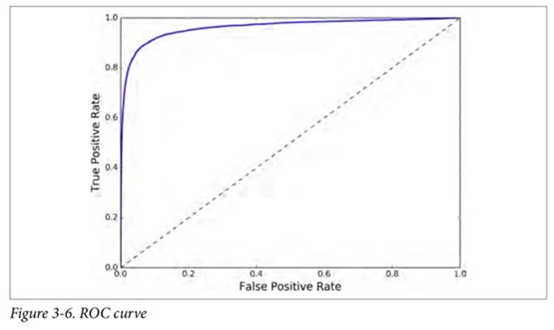
roc曲线下面的面积越大,或roc曲线越靠左上角,性能越好,测量ROC曲线下的面积(AUC)评估分类器的好坏。Scikit-Learn 提供了一个函 数来计算 ROC AUC:
>>> from sklearn.metrics import roc_auc_score
>>> roc_auc_score(y_train_5, y_scores)
0.97061072797174941
(3)画出曲线图比较性能
也可以画出两个分类器的ROC曲线,看谁更接近左上角。
1)计算SGDClassifier分类器
为了画出 ROC 曲线,你首先需要计算各种不同阈值下的 TPR、FPR,使用 roc_curve() 函 数:
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
2)计算RandomForestClassifier的TPR和FPR
RandomForestClassifier 不提供 decision_function() 方法。相反,它提供 predict_proba()方法,返回一个数组,每一行代表一个数字记录,每一列代表所属于的类别,数组中数值含义是这一行这个数是这一列这个类的概率。例如数字判断中,每一列是“是5”和“非5”,每一行是一个图片记录,数组中的值是图片“是5”和“非5”的概率,把这个概率值作为评分值。
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,method="predict_proba")
y_scores_forest = y_probas_forest[:, 1] # 是5的概率值作为评分
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest)
3)画出曲线图
plt.plot(fpr, tpr, "b:", label="SGD") #SGD的ROC曲线图
plot_roc_curve(fpr_forest, tpr_forest, "Random Forest") #随机森林的ROC
plt.legend(loc="bottom right")
plt.show()
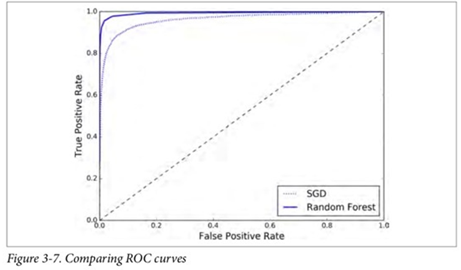
如你所见, RandomForestClassifier 的 ROC 曲线比 SGDClassifier 的好得多:它更靠近左上 角。所以,它的 ROC AUC 也会更大。
>>> roc_auc_score(y_train_5, y_scores_forest)
0.99312433660038291
1.4 多分类器
1.4.1 定义
二分类器只能区分两个类,而多类分类器(也被叫做多项式分类器)可以区分多于两个类。如随机森林分类器或者朴素贝叶斯分类器可以直接处理多类分类。(比如 SVM 分类器或者线性分类器)则是严格的二分类器。
一对所有(ONE VS ALL):例如训练0~9共10个分类器,你想对某张 图片进行分类的时候,让每一个分类器对这个图片进行分类,选出决策分数最高的那个分类 器。
一对1=一(ONE VS ONE)0,1之间,0,2之间……,共N(N-1)/2分类器,当你想对一张图片进行分类,你必须将这张图片跑在全部45个二分类器上。然后 看哪个类胜出。
1.4.2 SGDClassifier实现多分类
>>> sgd_clf.fit(X_train, y_train) # 训练
>>> sgd_clf.predict([some_digit])#预测输出是 array([ 5.])
>>> some_digit_scores = sgd_clf.decision_function([some_digit]) >>> some_digit_scores array([[-311402.62954431, -363517.28355739, -446449.5306454 , -183226.61023518, -414337.15339485, 161855.74572176, -452576.39616343, -471957.14962573, -518542.33997148, -536774.63961222]])#获取评分
>>> np.argmax(some_digit_scores) #输出评分最大的结果是5
1.4.3 OneVsOneClassifier 类 或者OneVsRestClassifier类
>>> from sklearn.multiclass import OneVsOneClassifier
>>> ovo_clf = OneVsOneClassifier(SGDClassifier(random_state=42)) >>> ovo_clf.fit(X_train, y_train)
>>> ovo_clf.predict([some_digit])
array([ 5.])
>>> len(ovo_clf.estimators_) 45
1.4.4 RandomForestClassifier多分类
随机森林分类器能够直接将一个样例 分到多个类别。你可以调用 predict_proba() ,得到样例对应的类别的概率值的列表。
>>> forest_clf.fit(X_train, y_train)
>>> forest_clf.predict([some_digit])
array([ 5.])
>>> forest_clf.predict_proba([some_digit]) array([[ 0.1, 0. , 0. , 0.1, 0. , 0.8, 0. , 0. , 0. , 0. ]])
1.5 误差分析
探索方案,尝试多种模型,选择最好的模型,用GridSearchCV调试超参数优化模型。要使用 cross_val_predict() 做出预测,然后调 用 confusion_matrix()函数。
>>> y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
>>> conf_mx = confusion_matrix(y_train, y_train_pred) >>> conf_mx array([[5725, 3, 24, 9, 10, 49, 50, 10, 39, 4], [ 2, 6493, 43, 25, 7, 40, 5, 10, 109, 8], [ 51, 41, 5321, 104, 89, 26, 87, 60, 166, 13], [ 47, 46, 141, 5342, 1, 231, 40, 50, 141, 92], [ 19, 29, 41, 10, 5366, 9, 56, 37, 86, 189], [ 73, 45, 36, 193, 64, 4582, 111, 30, 193, 94], [ 29, 34, 44, 2, 42, 85, 5627, 10, 45, 0], [ 25, 24, 74, 32, 54, 12, 6, 5787, 15, 236], [ 52, 161, 73, 156, 10, 163, 61, 25, 5027, 123], [ 43, 35, 26, 92, 178, 28, 2, 223, 82, 5240]])
Matplotlib 的 matshow() 函数,将混淆矩阵以图像的方式呈现,将会更 加方便。
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show()

主对角线上意味着被分类 正确。数字 5 对应的格子看起来比其他数字要暗淡许多。数据集当中数字 5 的图片 比较少,又或者是分类器对于数字 5的表现不如其他数字那么好。
将混淆矩阵的每一个值除以相应类别的 图片的总数目。这样子,你可以比较错误率,而不是绝对的错误数(这对大的类别不公平)。用 0 来填充对角线正确的分类。最后得到的就是错误率的矩阵和图像。
row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx / row_sums
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show()

第 8、9 列相当亮,这告诉你许多图片被误分成数字 8 或者数字 9,第一行很暗,这意味着大部分的数字 1 被正确分类。分析混淆矩阵通常可以给你提供深刻的见解去改善你的分类器。回顾这幅图,看样子你应该 努力改善分类器在数字 8 和数字 9 上的表现,和纠正 3/5 的混淆
1.6 多标签分类KNeighborsClassifier
(1)分类实现
让你的分类器给 一个样例输出多个类别。例如一个人脸识别分类器,这个分类 器被训练成识别三个人脸,Alice,Bob,Charlie;然后当它被输入一张含有 Alice 和 Bob 的 图片,它应该输出 [1, 0, 1] 。(意思是:Alice 是,Bob 不是,Charlie 是)。这种输出多个二 值标签的分类系统被叫做多标签分类系统。例如要对数字进行分类,两个要求(1)大于等于7;(2)是奇数。
from sklearn.neighbors import KNeighborsClassifier #引入分类器
y_train_large = (y_train >= 7)#大于7的目标值
y_train_odd = (y_train % 2 == 1) #是奇数的目标值
y_multilabel = np.c_[y_train_large, y_train_odd] #组合两种分类值
knn_clf = KNeighborsClassifier()#创建分类器对象
knn_clf.fit(X_train, y_multilabel)#进行分类训练
>>> knn_clf.predict([some_digit]) #输出5的预测值
array([[False, True]], dtype=bool)#结果为小于7,是奇数
(2)F1值评估分类器
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_train, cv=3)
>>> f1_score(y_train, y_train_knn_pred, average="macro") #平均
0.96845540180280221
,如果你的 Alice 的照片比 Bob 或者 Charlie 更多的时候,也许你想让分类器在 Alice 的照片上具有更大的权重。设置 average="weighted" 。
1.7 多输出分类
是多标签分类的简单泛化,在这里每一个标签可以是多类别的(比如说,它可以有多于两个可能值)。例如去除噪音的系统,输入是含有噪音的图片,输出是一个干净的数字图片,由像素强度数组表示,一个像素是一个标签,每个标签的取值是 0~255。标签的取值多范围就是多输出分类。
我们先给训练数据加上噪音,然后再进行降噪处理。
noise = rnd.randint(0, 100, (len(X_train), 784)) #制造噪音
noise = rnd.randint(0, 100, (len(X_test), 784))
X_train_mod = X_train + noise #加上噪音
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
knn_clf.fit(X_train_mod, y_train_mod) #训练KNeighborsClassifier分类器
clean_digit = knn_clf.predict([X_test_mod[some_index]]) #输出降噪预测值
plot_digit(clean_digit)
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: