序列化框架
除了writable实现序列化之外,只要实现让类型和二进制流相互转换,都可以作为hadoop的序列化类型,为此Hadoop提供了一个序列化框架接口,他们在org.apache.hadoop.io.serializer包中,Writable可以作为MapReduce支持的类型也是因为实现了这个框架接口。使用流程是定义序列化类实现框架接口->io.serializations参数配置序列化类名称,用一个逗号隔开的类名列表—> SerializationFactory构造函数中会读取配置,根据反射机制和类名创建序列化对象,保存在队列中—>通过SerializationFactory的函数getSerializer(Class<T> c)获取入序列化对象,入参是要获取对象的类名称。
在先来看看序列化开接口,以及writable是怎么实现的。
(1)序列化接口Serializer:
打开流,序列化,关闭流
public interface Serializer <T> {
void open(java.io.OutputStream outputStream) throws java.io.IOException;
void serialize(T t) throws java.io.IOException;
void close() throws java.io.IOException;
}
(2)反序列化接口:Deserializer
定义了一组接口,打开流,反序列化,关闭流
public interface Deserializer <T> {
void open(java.io.InputStream inputStream) throws java.io.IOException;
T deserialize(T t) throws java.io.IOException;
void close() throws java.io.IOException;
}
(3)序列化判断和实例获取接口
Accept函数判断是否支持序列化,要求是writable的子类,getSerializer函数返回序列化的实例,getDeserializer获取反序列化实例。通过实例调用接口函数去实现序列化函数。
public interface Serialization <T> {
boolean accept(java.lang.Class<?> aClass);
org.apache.hadoop.io.serializer.Serializer<T> getSerializer(java.lang.Class<T> tClass);
org.apache.hadoop.io.serializer.Deserializer<T> getDeserializer(java.lang.Class<T> tClass);
}
(4)定义序列化类
Writable定义序列化类要实现上面的三个接口, 实现接口中的序列化和反序列化函数。
public class WritableSerialization extends Configured
implements Serialization<Writable> {
//定义静态反序列化类
static class WritableDeserializer extends Configured
implements Deserializer<Writable> {
private Class<?> writableClass;
private DataInputStream dataIn;
//定义构造函数
public WritableDeserializer(Configuration conf, Class<?> c) {
setConf(conf);
this.writableClass = c;
}
//打开输入流
public void open(InputStream in) {
if (in instanceof DataInputStream) {
dataIn = (DataInputStream) in;
} else {
dataIn = new DataInputStream(in);
}
}
//反序列化函数,读取数据
public Writable deserialize(Writable w) throws IOException {
Writable writable;
if (w == null) {
writable
= (Writable) ReflectionUtils.newInstance(writableClass, getConf());
} else {
writable = w;
}
writable.readFields(dataIn);
return writable;
}
//关闭输入流
public void close() throws IOException {
dataIn.close();
}
}
序列化类
static class WritableSerializer implements Serializer<Writable> {
private DataOutputStream dataOut;
//打开输出流
public void open(OutputStream out) {
if (out instanceof DataOutputStream) {
dataOut = (DataOutputStream) out;
} else {
dataOut = new DataOutputStream(out);
}
}
序列化函数写入数据
public void serialize(Writable w) throws IOException {
w.write(dataOut);
}
//关闭输出流
public void close() throws IOException {
dataOut.close();
}
}
//判断是否是writable的子类
public boolean accept(Class<?> c) {
return Writable.class.isAssignableFrom(c);
}
//返回反序列化对象
public Deserializer<Writable> getDeserializer(Class<Writable> c) {
return new WritableDeserializer(getConf(), c);
}
//返回序列化对象
public Serializer<Writable> getSerializer(Class<Writable> c) {
return new WritableSerializer();
}
}
(5)序列化工厂
public class SerializationFactory extends Configured {
private static final Log LOG = LogFactory.getLog(SerializationFactory.class.getName());
private List<Serialization<?>> serializations = new ArrayList();
public SerializationFactory(Configuration conf) {
super(conf);
//通过读取配置信息conf中的io.serializations参数来确定Serializations,这个参数是一个逗号隔开的类名列表
String[] arr$ = conf.getStrings("io.serializations", new String[]{WritableSerialization.class.getName(), //默认包含Writable和Avro
AvroSpecificSerialization.class.getName(), AvroReflectSerialization.class.getName()});
int len$ = arr$.length;
for(int i$ = 0; i$ < len$; ++i$) {
String serializerName = arr$[i$];
this.add(conf, serializerName);
}
}
//添加到list的函数
private void add(Configuration conf, String serializationName) {
try {
Class<? extends Serialization> serializionClass = conf.getClassByName(serializationName);
//根据类名和反射机制创建序列化对象,保存到 serializations的List中
this.serializations.add((Serialization)ReflectionUtils.newInstance(serializionClass, this.getConf()));
} catch (ClassNotFoundException var4) {
LOG.warn("Serialization class not found: ", var4);
}
}
public <T> Serializer<T> getSerializer(Class<T> c) {
Serialization<T> serializer = this.getSerialization(c);
return serializer != null ? serializer.getSerializer(c) : null;
}
public <T> Deserializer<T> getDeserializer(Class<T> c) {
Serialization<T> serializer = this.getSerialization(c);
return serializer != null ? serializer.getDeserializer(c) : null;
}
public <T> Serialization<T> getSerialization(Class<T> c) {
Iterator i$ = this.serializations.iterator();
Serialization serialization;
do {
if (!i$.hasNext()) {
return null;
}
serialization = (Serialization)i$.next();
} while(!serialization.accept(c));
return serialization;
}
}
其他序列化框架对比
|
ObjectInput(Out)Stream |
1.无法跨语言。内部私有的协议, 2.序列后的码流太大。java序列化的大小是二进制编码的5倍多! |
|
google的Protobuf |
1.结构化数据存储格式(xml,json等) |
|
faceBook的Thrift |
1.Thrift支持多种语言(C++,C#,Cocoa,Erlag,Haskell,java,Ocami,Perl,PHP,Python,Ruby,和SmallTalk) |
|
Kryo |
1.速度快,序列化后体积小 |
|
hessian |
1.默认支持跨语言 |
|
fst |
fst是完全兼容JDK序列化协议的系列化框架,序列化速度大概是JDK的4-10倍,大小是JDK大小的1/3左右。 |
|
Gson |
Gson是目前功能最全的Json解析神器, Gson的应用主要为toJson与fromJson两个转换函数,无依赖,不需要例外额外的jar,能够直接跑在JDK上。而在使用这种对象转换之前需先创建好对象的类型以及其成员才能成功的将JSON字符串成功转换成相对应的对象。类里面只要有get和set方法,Gson完全可以将复杂类型的json到bean或bean到json的转换,是JSON解析的神器。 |
|
FastJson |
Fastjson是一个Java语言编写的高性能的JSON处理器,由阿里巴巴公司开发。无依赖,不需要例外额外的jar,能够直接跑在JDK上。FastJson在复杂类型的Bean转换Json上会出现一些问题,可能会出现引用的类型,导致Json转换出错,需要制定引用。FastJson采用独创的算法,将parse的速度提升到极致,超过所有json库。 |
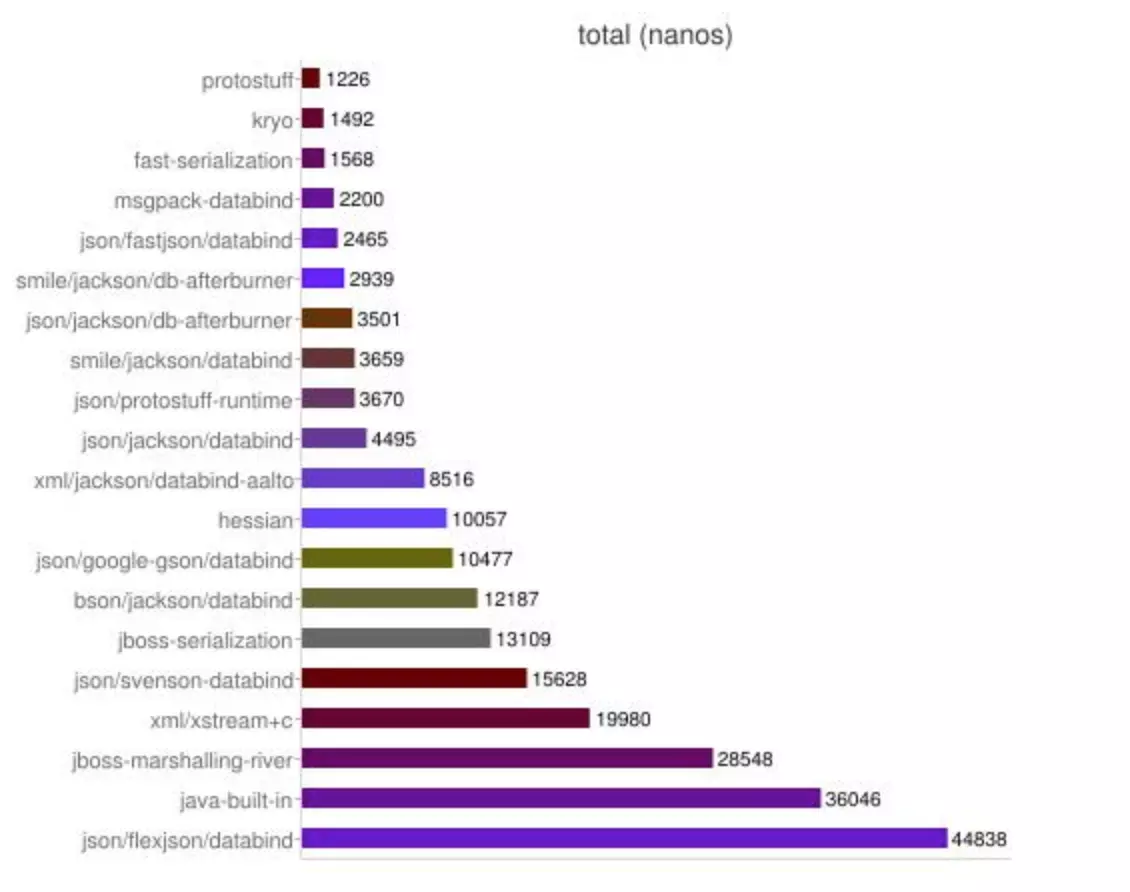
引用:
https://www.jianshu.com/p/937883b6b2e5
https://www.helplib.com/Java_API_Classes/article_62465
https://blog.csdn.net/lipeng_bigdata/article/details/51202764
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: