一、普里姆算法
源码:普里姆算法
1,介绍
普里姆算法是图结构中寻找最小生成树的一种算法。所谓生成树,即为连通图的极小连通子图,其包含了图中的n个顶点,和n-1条边,这n个顶点和n-1条边所构成的树即为生成树。当边上带有权值时,使生成树中的总权值最小的生成树称为最小代价生成树,简称最小生成树。最小生成树不唯一,且需要满足一下准则:
- 只能使用图中的边构造最小生成树
- 具有n个顶点和n-1条边
- 每个顶点仅能连接一次,即不能构成回路
2,案例
看一个应用场景和问题:
- 有胜利乡有7个村庄(A, B, C, D, E, F, G) ,现在需要修路把7个村庄连通
- 各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里
- 问:如何修路保证各个村庄都能连通,并且总的修建公路总里程最短?

3,思路

4,实现O(n3)
采用三层for循环,第一层控制生成的边的条数,第二层表示已经被访问的顶点,第三层为未被访问的顶点。获取满足这三者的最小权重值
//最终会生成vertexNum-1条边,故而只需要遍历vertexNum-1次。当然也可以多遍历因为后面会有最小值的控制 for (int k = 1; k < graph.vertexNum; k++) { min = 10000; //表示被访问的结点 for (int i = 0; i < graph.vertexNum; i++) { //表示未被访问的结点 for (int j = 0; j < graph.vertexNum; j++) { //如果当前为i结点被访问,j结点为未被访问,当前路径权重小于最小权重 if (visited[i]==1 && visited[j]==0 && graph.weight[i][j] < min ) { //此时记录最小权重,记录i结点和j结点 min = graph.weight[i][j]; x = i; y = j; } } } //如果当前结点全部被访问,则min==10000,否则就有边未被访问。 if (min < 10000) { //记录当前y为被访问,并输出此时访问的边 visited[y] = 1; System.out.println(getVertex(x) +" -> " +getVertex(y) +" "+ min); } }
5,优化实现O(n2)
int minIndex: 记录每轮查找的最小值对应索引 int[] indexArr:记录每次访问的结点对应的索引 int[] visited: 记录访问状态(如果为0表示已访问)和距离。当查找到最小值对应的索引minIndex后,如果以minIndex为原点到达各顶点的距离 小于 原始visited的值,就更新visited当前索引值
/** * prim算法(优化) * * @param data 顶点 * @param weight 邻接矩阵 * @param start 开始顶点 */ public static void prim(char[] data,int[][] weight,int start) { int length = data.length; //记录各最小节点的索引 int[] indexArr = new int[length]; //如果当前值为0 表示已经被访问, 其他情况表示未访问 int[] visited = new int[length]; //获取start这一行与其他节点的距离 for (int i = 0; i < length; i++) { visited[i] = weight[start][i]; } //标记start行为已访问 visited[start] = 0; //记录第一个结点 int index = 0; indexArr[index++] = start; int min; int minIndex ; //记录权重 int sum = 0; for (int i = 1; i <length; i++) { //记录每轮最小值 min = 10000; //记录每轮的最小索引 minIndex = -1; //获取visited中最小值(非零) for (int j = 0; j < length; j++) { if (visited[j] != 0 && visited[j] < min ) { min = visited[j]; minIndex = j; } } //证明这一轮没有最小索引,循环结束 if (minIndex == -1) { break; } //记录(最小的索引) indexArr[index++] = minIndex; sum += min; //更新visited中的数据 visited[minIndex] = 0; for (int j = 0; j < length; j++) { //如果当前visited数组中j的值 > 邻接矩阵中从minIndex到j的值 更新visited if (visited[j] != 0 && visited[j] > weight[minIndex][j]) { visited[j] = weight[minIndex][j]; } } } System.out.println("总的权重为: " + sum); for (int i = 0; i < length; i++) { System.out.printf("%s ",data[indexArr[i]]); } System.out.println(); }
二、克鲁斯卡尔算法
源码:克鲁斯卡尔算法
1,介绍
- 克鲁斯卡尔(Kruskal)算法,是用来求加权连通图的最小生成树的算法。
- 基本思想:按照权值从小到大的顺序选择 n-1 条边,并保证这 n-1 条边不构成回路
- 具体做法:首先构造一个只含 n 个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止
2,案例
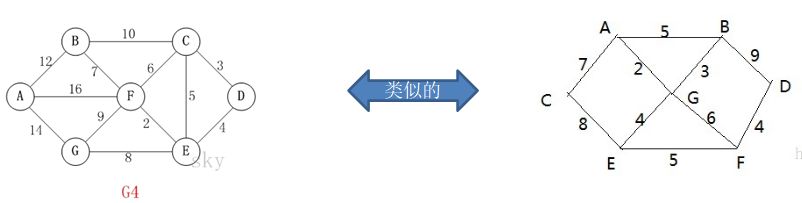
看一个应用场景和问题:
- 某城市新增7个站点(A, B, C, D, E, F, G) ,现在需要修路把7个站点连通
- 各个站点的距离用边线表示(权) ,比如 A – B 距离 12公里
- 问:如何修路保证各个站点都能连通,并且总的修建公路总里程最短?
3,思路
- 对所有的边按照权值大小进行排序
- 添加权值最小并且不构成回路的边
如果判定新添加的边是否与原来的边构成回路?新添加边的两个顶点的终点不相同,下面展示如果求指定索引的终点:
/** * 查询当前索引对应的终点的索引 * 如果当前索引对应的终点为0,则直接返回自己, * 如果不为0记录向后找当前的终点 循环得到其终点 * 例如: E的终点为F D的终点为E(此时会通过E找到F) 那么就是D和E的终点均为F * @param end 数组就是记录了各个顶点对应的终点是哪个,ends 数组是在遍历过程中,逐步形成 * @param i 表示传入的顶点对应的下标 * @return 返回的就是 下标为i的这个顶点对应的终点的下标 */ public int getEnd(int[] end,int i) { while (end[i] != 0) { i = end[i]; } return i; }
4,代码实现
遍历图的右半边,将其构建成一个存储所有边的数组。对边进行排序(升序),遍历每条边获取其start和end的终点是否相同,不同就加入结果集,并更新终点数组。
/** * 克鲁斯卡尔算法 */ public void kruskal() { System.out.println("排序前:"+Arrays.toString(edges)); sort(edges); System.out.println("排序后:"+Arrays.toString(edges)); //最终的结果肯定是length-1条 Edge[] res = new Edge[vertexs.length-1]; int index = 0; for (int i = 0; i < edges.length; i++) { int start = getIndexByChar(edges[i].start); int end = getIndexByChar(edges[i].end); //获取start结点的终点 int startParent = getEnd(ends, start); //获取end结点的终点 int endParent = getEnd(ends, end); //如果两个结点的 终点不是同一下标 则记录 if (startParent != endParent) { //将当前边加入到结果集中 res[index++] = edges[i]; //同时更新start结点的终点为end结点的终点 ends[startParent] = endParent; } } for (int i = 0; i < res.length; i++) { System.out.println(res[i]); } }
三、迪杰斯特拉算法
源码:迪杰斯特拉算法
1,介绍
迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个结点到其他结点的最短路径。它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。
2,案例
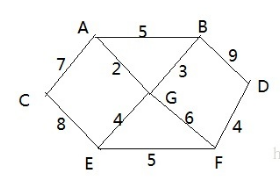
看一个应用场景和问题:
- 战争时期,胜利乡有7个村庄(A, B, C, D, E, F, G) ,现在有六个邮差,从G点出发,需要分别把邮件分别送到 A, B, C , D, E, F 六个村庄
- 各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里
- 问:如何计算出G村庄到 其它各个村庄的最短距离?
- 如果从其它点出发到各个点的最短距离又是多少?
3,思路
- 从指定起点开始,找出所有邻接节点,更新起点到邻接节点路径权值和记录的前驱节点,从中选出路径权值最小的一个节点,作为下一轮的起点
- 从次轮起点开始,重复第一轮的操作
- 每一轮更新记录的路径权值,是把 “记录得原始起点到该目标节点的路径总权值” 与 “记录中原始起点到本轮起点的路径权值 + 本轮起点到邻接节点的权值” 比较,保留小的
- 更新了权值的同时要记得更新路径终点的前驱节点
- 每一轮都将此轮的起点设置为已访问,并且寻找邻接节点时也要跳过那些已访问的
- 所有节点都"已访问"时结束
4,代码实现
思路:1,构建一个vistedvetex对象(pre数组记录到达当前顶点的上一个顶点索引;already数组记录当前顶点是否被访问;dis数组记录从初始顶点出发到达当前顶点的距离) 2,初始化根据初始顶点,构建:除初始顶点以外所有dis均为最大值(65535),除初始顶点以外的所有顶点均为被访问 3,以index(第一次index为初始顶点,之后均为获取当前dis数组中未被访问的最短距离为index,并标记当前index为已访问) 作为基准点,获取当前dis中index的值(该值则为从初始结点到index的距离) + index到i(遍历图变化) 距离之和 记为len, 用len与dis中i的值进行比较:如果len < dis[i],则说明以index作为基准点 更为合适,此时更新dis[i] = len ; pre[i] = index
/** * 迪杰斯特拉算法 * * @param index 初始顶点的坐标 */ public void dsj(int index) { //初始化visitedVetex vv = new VisitedVetex(index, vertex.length); //以index作为介质,更新visitedvetex中的dis和pre update(index); //记录当前存储在dis数组中 并 未被访问的最小节点的距离 int i; //如果当前i==-1 ,则表示dis数组中所有的数据均被访问过 while ((i = vv.updateArr()) != -1) { //以i作为介质 更新vv update(i); } //打印 vv.show(); } /** * 更新以当前结点为 介质 的visitedvetex的 dis和pre数组 * * @param index 当前结点的索引 */ private void update(int index) { //遍历以index作为结点 获取 与其连接的所有结点 for (int i = 0; i < matrix[index].length; i++) { //len为 从index到i结点的邻接距离 + 存储在dis数组中的起始点到index的距离 int len = matrix[index][i] + vv.dis[index]; //如果len < 存储在dis数组中的起始点到i 结点的距离 并且当前i结点未被访问过(只有i在dis数组中为最小的数时才会被访问) if (len < vv.dis[i] && !vv.isVisited(i)) { //更新dis数组中 起始点到i的距离为len vv.updateDis(i, len); //修改当前i结点的前驱结点为index vv.updatePre(i, index); } } }
四、弗洛伊德算法
源码:弗洛伊德算法
1,介绍
- 弗洛伊德(Floyd)算法也是一种用于寻找给定的加权图中顶点间最短路径的算法
- 弗洛伊德算法(Floyd)计算图中各个顶点之间的最短路径
- 迪杰斯特拉算法用于计算图中某一个顶点到其他顶点的最短路径。
- 弗洛伊德算法 VS 迪杰斯特拉算法:
- 迪杰斯特拉算法通过选定的被访问顶点,求出从出发访问顶点到其他顶点的最短路径;
- 弗洛伊德算法中每一个顶点都是出发访问点,所以需要将每一个顶点看做被访问顶点,求出从每一个顶点到其他顶点的最短路径。
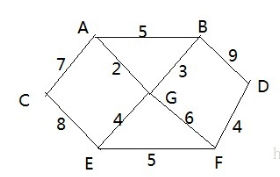
2,案例
- 胜利乡有7个村庄(A, B, C, D, E, F, G)
- 各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里
- 问:如何计算出各村庄到其它各村庄的最短距离?
3,思路
- 设置顶点vi到顶点vk的最短路径已知为Lik,顶点vk到vj的最短路径已知为Lkj,顶点vi到vj的路径为Lij,则vi到vj的最短路径为:min((Lik+Lkj),Lij),vk的取值为图中所有顶点,则可获得vi到vj的最短路径
- 至于vi到vk的最短路径Lik或者vk到vj的最短路径Lkj,也是以同样的方式获得
4,代码实现
/** * 弗洛伊德算法 : 以i为中间点 比较j->i->k 的距离与 j->k的距离 * 如果采用i作为中间顶点距离短则记录i为前驱顶点,并更新距离 * 如果是j->k 距离更短 则直接记录j * @param vetex 顶点集合 * @param w 邻接矩阵 */ public static void floyd(char[] vetex, int[][] w) { //存储前驱结点 char[][] pre = new char[vetex.length][vetex.length]; // 对pre数组初始化, 注意存放的是前驱顶点的下标 for (int i = 0; i < vetex.length; i++) { Arrays.fill(pre[i], vetex[i]); } //作为中间结点 for (int i = 0; i < vetex.length; i++) { //初始结点 for (int j = 0; j < vetex.length; j++) { //终点 for (int k = 0; k < vetex.length; k++) { //j->i->k的距离 int len = w[j][i] + w[i][k]; if (w[j][k] > len) { w[j][k] = len; //记录前驱结点为中间结点 pre[j][k] = pre[i][k]; } } } } }
五、马踏棋盘算法(骑士周游问题)
源码:马踏棋盘算法
1,介绍
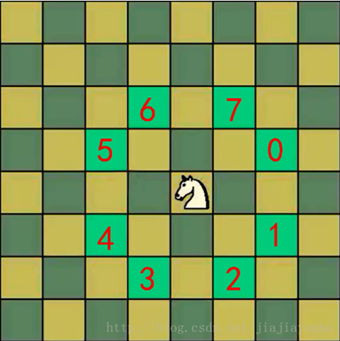
将马随机放在国际象棋的8×8棋盘Board[0~7][0~7]的某个方格中,马按走棋规则(马走日字)进行移动。要求每个方格只进入一次,走遍棋盘上全部64个方格
2,思路
- 马踏棋盘问题(骑士周游问题)实际上是图的深度优先搜索(DFS)的应用。
- 编码思路
- 创建棋盘 chessBoard,是一个二维数组
- 将当前位置设置为已经访问,然后根据当前位置,计算马儿还能走哪些位置,并放入到一个集合中(ArrayList),下一步可选位置最多有8个位置, 每走一步,就使用 step+1
- 遍历ArrayList中存放的所有位置,看看哪个可以走通,如果走通,就继续,走不通,就回溯
- 判断马儿是否完成了任务,使用 step 和应该走的步数比较 , 如果没有达到数量,则表示没有完成任务,将整个棋盘置 0
- 注意:马儿不同的走法(策略),会得到不同的结果,效率也会有影响(优化)
3,代码实现
/** * 马踏棋盘算法核心 * * @param x 初始棋子在棋盘的哪一行 * @param y 初始棋子在棋盘的哪一列 * @param step 当前是第几步 */ public void start(int x, int y, int step) { //首先存储对应的步数 chess[x][y] = step; //获取当前x,y对应的 visited数组中的索引位置 int index = x * Y + y; //标记为已访问 visited[index] = true; //构建当前point Point currentPoint = new Point(x, y); List<Point> ps = next(currentPoint); //对ps进行排序,排序的规则就是对ps的所有的Point对象的下一步的位置的数目,进行非递减排序 sort(ps); while (!ps.isEmpty()) { //将第一个元素移除 Point removePoint = ps.remove(0); //未被访问过,则调用当前 if (!visited[(removePoint.x) * Y + removePoint.y]) { start(removePoint.x, removePoint.y, step + 1); } } //回溯 if (step < X * Y && !finished) { chess[x][y] = 0; visited[index] = false; } else { finished = true; } } /** * 对ps集合进行非递减排序 * @param ps 集合 */ private void sort(List<Point> ps) { ps.sort((p1, p2) -> { //获取当前p1和p2 各自对应的 List<Point> next1 = next(p1); List<Point> next2 = next(p2); return next1.size() - next2.size(); }); } private List<Point> next(Point currentPoint) { List<Point> ps = new ArrayList<>(); int x, y; //0 if ((x = currentPoint.x - 1) >= 0 && (y = currentPoint.y + 2) < Y) { ps.add(new Point(x, y)); } //1 if ((x = currentPoint.x + 1) < X && (y = currentPoint.y + 2) < Y) { ps.add(new Point(x, y)); } //2 if ((x = currentPoint.x + 2) < X && (y = currentPoint.y + 1) < Y) { ps.add(new Point(x, y)); } //3 if ((x = currentPoint.x + 2) < X && (y = currentPoint.y - 1) >= 0) { ps.add(new Point(x, y)); } //4 if ((x = currentPoint.x + 1) < X && (y = currentPoint.y - 2) >= 0) { ps.add(new Point(x, y)); } //5 if ((x = currentPoint.x - 1) >= 0 && (y = currentPoint.y - 2) >= 0) { ps.add(new Point(x, y)); } //6 if ((x = currentPoint.x - 2) >= 0 && (y = currentPoint.y - 1) >= 0) { ps.add(new Point(x, y)); } //7 if ((x = currentPoint.x - 2) >= 0 && (y = currentPoint.y + 1) < Y) { ps.add(new Point(x, y)); } return ps; }