下图为ext2文件系统的存储布局。
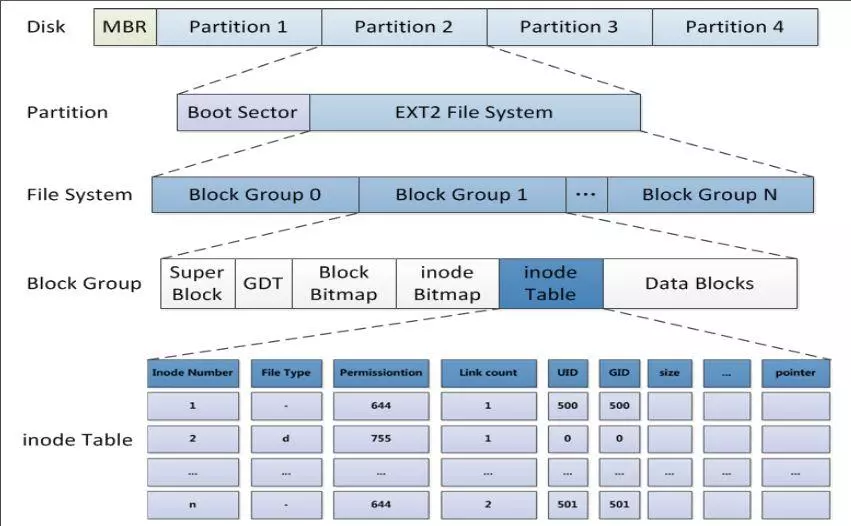
The Second Extended File System(ext2)文件系统是Linux系统中的标准文件系统,是通过对Minix的文件系统进行扩展而得到的,其存取文件的性能极好。
在ext2文件系统中,文件由inode(包含有文件的所有信息)进行唯一标识。一个文件可能对应多个文件名,只有在所有文件名都被删除后,该文件才会被删除。此外,同一文件在磁盘中存放和被打开时所对应的inode是不同的,并由内核负责同步。
ext2文件系统采用三级间接块来存储数据块指针,并以块(block,默认为1KB)为单位分配空间。其磁盘分配策略是尽可能将逻辑相邻的文件分配到磁盘上物理相邻的块中,并尽可能将碎片分配给尽量少的文件,以从全局上提高性能。ext2文件系统将同一目录下的文件(包括目录)尽可能的放在同一个块组中,但目录则分布在各个块组中以实现负载均衡。在扩展文件时,会尽量一次性扩展8个连续块给文件(以预留空间的形式实现)。
一、磁盘组织
在ext2系统中,所有元数据结构的大小均基于“块”,而不是“扇区”。块的大小随文件系统的大小而有所不同。而一定数量的块又组成一个块组,每个块组的起始部分有多种多样的描述该块组各种属性的元数据结构。ext2系统中对各个结构的定义都包含在原始码的include/linux/ext2_fs.h文件中。
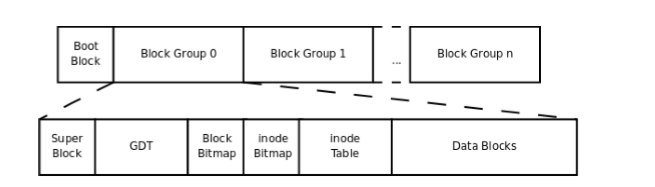
1、超级块
每个ext2文件系统都必须包含一个超级块,其中存储了该文件系统的大量基本信息,包括块的大小、每块组中包含的块数等。同时,系统会对超级块进行备份,备份被存放在块组的第一个块中。超级块的起始位置为其所在分区的第1024个字节,占用1KB的空间,其结构如下:
struct ext2_super_block {
__le32 s_inodes_count; // 文件系统中inode的总数
__le32 s_blocks_count; // 文件系统中块的总数
__le32 s_r_blocks_count; // 保留块的总数
__le32 s_free_blocks_count; // 未使用的块的总数(包括保留块)
__le32 s_free_inodes_count; // 未使用的inode的总数
__le32 s_first_data_block; // 块ID,在小于1KB的文件系统中为0,大于1KB的文件系统中为1
__le32 s_log_block_size; // 用以计算块的大小(1024算术左移该值即为块大小)
__le32 s_log_frag_size; // 用以计算段大小(为正则1024算术左移该值,否则右移)
__le32 s_blocks_per_group; // 每个块组中块的总数
__le32 s_frags_per_group; // 每个块组中段的总数
__le32 s_inodes_per_group; // 每个块组中inode的总数
__le32 s_mtime; // POSIX中定义的文件系统装载时间
__le32 s_wtime; // POSIX中定义的文件系统最近被写入的时间
__le16 s_mnt_count; // 最近一次完整校验后被装载的次数
__le16 s_max_mnt_count; // 在进行完整校验前还能被装载的次数
__le16 s_magic; // 文件系统标志,ext2中为0xEF53
__le16 s_state; // 文件系统的状态
__le16 s_errors; // 文件系统发生错误时驱动程式应该执行的操作
__le16 s_minor_rev_level; // 局部修订级别
__le32 s_lastcheck; // POSIX中定义的文件系统最近一次检查的时间
__le32 s_checkinterval; // POSIX中定义的文件系统最近检查的最大时间间隔
__le32 s_creator_os; // 生成该文件系统的操作系统
__le32 s_rev_level; // 修订级别
__le16 s_def_resuid; // 报留块的默认用户ID
__le16 s_def_resgid; // 保留块的默认组ID
// 仅用于使用动态inode大小的修订版(EXT2_DYNAMIC_REV)
__le32 s_first_ino; // 标准文件的第一个可用inode的索引(非动态为11)
__le16 s_inode_size; // inode结构的大小(非动态为128)
__le16 s_block_group_nr; // 保存此超级块的块组号
__le32 s_feature_compat; // 兼容特性掩码
__le32 s_feature_incompat; // 不兼容特性掩码
__le32 s_feature_ro_compat; // 只读特性掩码
__u8 s_uuid[16]; // 卷ID,应尽可能使每个文件系统的格式唯一
char s_volume_name[16]; // 卷名(只能为ISO-Latin-1字符集,以’\0’结束)
char s_last_mounted[64]; // 最近被安装的目录
__le32 s_algorithm_usage_bitmap; // 文件系统采用的压缩算法
// 仅在EXT2_COMPAT_PREALLOC标志被设置时有效
__u8 s_prealloc_blocks; // 预分配的块数
__u8 s_prealloc_dir_blocks; // 给目录预分配的块数
__u16 s_padding1;
// 仅在EXT3_FEATURE_COMPAT_HAS_JOURNAL标志被设置时有效,用以支持日志
__u8 s_journal_uuid[16]; // 日志超级块的卷ID
__u32 s_journal_inum; // 日志文件的inode数目
__u32 s_journal_dev; // 日志文件的设备数
__u32 s_last_orphan; // 要删除的inode列表的起始位置
__u32 s_hash_seed[4]; // HTREE散列种子
__u8 s_def_hash_version; // 默认使用的散列函数
__u8 s_reserved_char_pad;
__u16 s_reserved_word_pad;
__le32 s_default_mount_opts;
__le32 s_first_meta_bg; // 块组的第一个元块
__u32 s_reserved[190];
};
2、块组描述符
一个块组描述符用以描述一个块组的属性。块组描述符组由若干块组描述符组成,描述了文件系统中所有块组的属性,存放于超级块所在块的下一个块中。一个块组描述符的结构如下:
struct ext2_group_desc
{
__le32 bg_block_bitmap; // 块位图所在的第一个块的块ID
__le32 bg_inode_bitmap; // inode位图所在的第一个块的块ID
__le32 bg_inode_table; // inode表所在的第一个块的块ID
__le16 bg_free_blocks_count; // 块组中未使用的块数
__le16 bg_free_inodes_count; // 块组中未使用的inode数
__le16 bg_used_dirs_count; // 块组分配的目录的inode数
__le16 bg_pad;
__le32 bg_reserved[3];
};
3、块位图和inode位图
块位图和inode位图的每一位分别指出块组中对应的那个块或inode是否被使用。
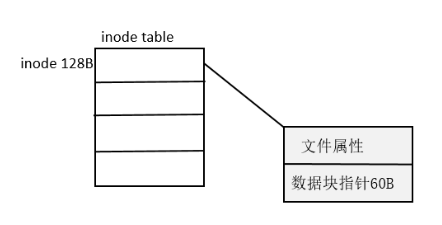
4、inode表
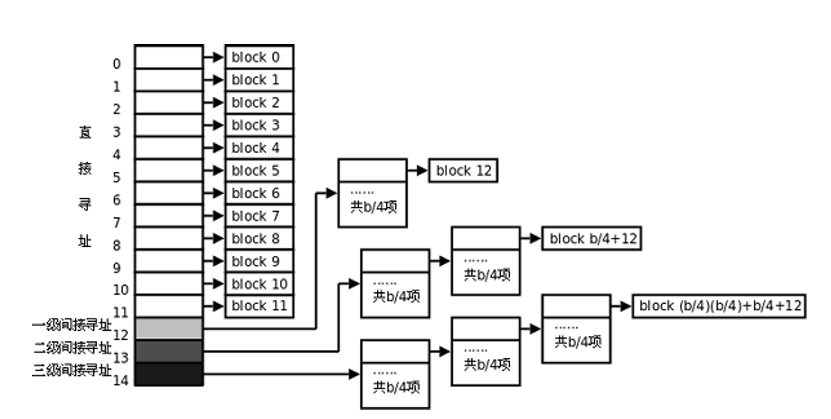
一个inode占128字节,其中60个字节用于指向存放文件内容的数据块指针。每个指针4字节,那么有15个指针。最后3个指针用分级间接寻址。 假设block为1KB。
12个直接指向,可以有12条记录。
一级间接寻址:1024/4=256,可以有256条记录。
二级间接寻址,可以有256*256条记录。
三级间接寻址,可以有256*256*256条记录。
所以对于1KB的块大小最大可以表示(256^3+256^2+256+12)*1KB≈16GB的文件。
inode表用于跟踪定位每个文件,包括位置、大小等(但不包括文件名),一个块组只有一个inode表。一个inode的结构如下:
struct ext2_inode {
__le16 i_mode; // 文件格式和访问权限
__le16 i_uid; // 文件所有者ID的低16位
__le32 i_size; // 文件字节数
__le32 i_atime; // 文件上次被访问的时间
__le32 i_ctime; // 文件创建时间
__le32 i_mtime; // 文件被修改的时间
__le32 i_dtime; // 文件被删除的时间(如果存在则为0)
__le16 i_gid; // 文件所有组ID的低16位
__le16 i_links_count; // 此inode被连接的次数
__le32 i_blocks; // 文件已使用和保留的总块数(以512B为单位)
__le32 i_flags; // 此inode访问数据时ext2的实现方式
union {
struct {
__le32 l_i_reserved1; // 保留
} linux1;
struct {
__le32 h_i_translator; // “翻译者”标签
} hurd1;
struct {
__le32 m_i_reserved1; // 保留
} masix1;
} osd1; // 操作系统相关数据
__le32 i_block[EXT2_N_BLOCKS]; // 定位存储文件的块的数组,前12个为块号,第13个为一级间接块号,第14个为二级间接块号,第15个为三级间接块号
__le32 i_generation; // 用于NFS的文件版本
__le32 i_file_acl; // 包含扩展属性的块号,老版本中为0
__le32 i_dir_acl; // 表示文件的“High Size”,老版本中为0
__le32 i_faddr; // 文件最后一个段的地址
union {
struct {
__u8 l_i_frag; // 段号
__u8 l_i_fsize; // 段大小
__u16 i_pad1;
__le16 l_i_uid_high; // 文件所有者ID的高16位
__le16 l_i_gid_high; // 文件所有组ID的高16位
__u32 l_i_reserved2;
} linux2;
struct {
__u8 h_i_frag; // 段号
__u8 h_i_fsize; // 段大小
__le16 h_i_mode_high;
__le16 h_i_uid_high; // 文件所有者ID的高16位
__le16 h_i_gid_high; // 文件所有组ID的高16位
__le32 h_i_author;
} hurd2;
struct {
__u8 m_i_frag; // 段号
__u8 m_i_fsize; // 段大小
__u16 m_pad1;
__u32 m_i_reserved2[2];
} masix2;
} osd2; // 操作系统相关数据
};
5、数据块
数据块中存放文件的内容,包括目录表、扩展属性、符号链接等。
二、目录结构
在ext2文件系统中,目录是作为文件存储的。根目录总是在inode表的第二项,而其子目录则在根目录文件的内容中定义。目录项在include/linux/ext2_fs.h文件中定义,其结构如下:
struct ext2_dir_entry_2 {
__le32 inode; // 文件入口的inode号,0表示该项未使用
__le16 rec_len; // 目录项长度
__u8 name_len; // 文件名包含的字符数
__u8 file_type; // 文件类型
char name[255]; // 文件名
};
文件的属性大多数是位于该文件的inode结构中的标准属性,也还包含其他一些扩展属性(于系统中所有的inode相关,通常用于增加额外的功能),在fs/ext2/xattr.h文件中定义。
inode的i_file_acl字段中保存扩展属性的块的块号。属性头部项位于属性块的起始位置,其后为属性入口项,而属性值能根据属性入口项找到所在位置。
1、属性头部项
struct ext2_xattr_header {
__le32 h_magic; // 标识码,为0xEA020000
__le32 h_refcount; // 属性块被链接的数目
__le32 h_blocks; // 用于扩展属性的块数
__le32 h_hash; // 所有属性的哈希值
__u32 h_reserved[4];
};
2、属性入口项
struct ext2_xattr_entry {
__u8 e_name_len; // 属性名长度
__u8 e_name_index; // 属性名索引
__le16 e_value_offs; // 属性值在值块中的偏移量
__le32 e_value_block; // 保存值的块的块号
__le32 e_value_size; // 属性值长度
__le32 e_hash; // 属性名和值的哈希值
char e_name[0]; // 属性名
};
Ext3是一种日志式文件系统,是对ext2系统的扩展,它兼容ext2。日志式文件系统的优越性在于:由于文件系统都有快取层参与运作,如不使用时必须将文件系统卸下,以便将快取层的资料写回磁盘中。因此每当系统要关机时,必须将其所有的文件系统全部shutdown后才能进行关机。
如果在文件系统尚未shutdown前就关机如(停电)时,下次重开机后会造成文件系统的资料不一致,故这时必须做文件系统的重整工作,将不一致与错误的地方修复。然而,此一重整的工作是相当耗时的,特别是容量大的文件系统,而且也不能百分之百保证所有的资料都不会流失。
为了克服此问题,使用所谓“日志式文件系统 (Journal File System)” 。此类文件系统最大的特色是,它会将整个磁盘的写入动作完整记录在磁盘的某个区域上,以便有需要时可以回溯追踪。
由于资料的写入动作包含许多的细节,像是改变文件标头资料、搜寻磁盘可写入空间、一个个写入资料区段等等,每一个细节进行到一半若被中断,就会造成文件系统的不一致,因而需要重整。
然而,在日志式文件系统中,由于详细纪录了每个细节,故当在某个过程中被中断时,系统可以根据这些记录直接回溯并重整被中断的部分,而不必花时间去检查其他的部分,故重整的工作速度相当快,几乎不需要花时间。
1、高可用性
系统使用了ext3文件系统后,即使在非正常关机后,系统也不需要检查文件系统。宕机发生后,恢复ext3文件系统的时间只要数十秒钟。
2、数据的完整性
ext3文件系统能够极大地提高文件系统的完整性,避免了意外宕机对文件系统的破坏。在保证数据完整性方面,ext3文件系统有2种模式可供选择。其中之一就是“同时保持文件系统及数据的一致性”模式。采用这种方式,你永远不再会看到由于非正常关机而存储在磁盘上的垃圾文件。
3、文件系统的速度
尽管使用ext3文件系统时,有时在存储数据时可能要多次写数据,但是,从总体上看来,ext3比ext2的性能还要好一些。这是因为ext3的日志功能对磁盘的驱动器读写头进行了优化。所以,文件系统的读写性能较之Ext2文件系统并来说,性能并没有降低。
4、数据转换
由ext2文件系统转换成ext3文件系统非常容易,只要简单地键入两条命令即可完成整个转换过程,用户不用花时间备份、恢复、格式化分区等。用一个ext3文件系统提供的小工具tune2fs,它可以将ext2文件系统轻松转换为ext3日志文件系统。另外,ext3文件系统可以不经任何更改,而直接加载成为ext2文件系统。
5、多种日志模式
Ext3有多种日志模式,一种工作模式是对所有的文件数据及metadata(定义文件系统中数据的数据,即数据的数据)进行日志记录(data=journal模式);另一种工作模式则是只对metadata记录日志,而不对数据进行日志记录,也即所谓data=ordered或者data=writeback模式。系统管理人员可以根据系统的实际工作要求,在系统的工作速度与文件数据的一致性之间作出选择。
Ext4(The fourth extended file system)
Ext4是一种针对ext3系统的扩展日志式文件系统,是专门为 Linux 开发的原始的扩展文件系统(ext 或 extfs)的第四版。 Linux kernel 自 2.6.28 开始正式支持新的文件系统 Ext4。 Ext4 是 Ext3 的改进版,修改了 Ext3 中部分重要的数据结构,而不仅仅像 Ext3 对 Ext2 那样,只是增加了一个日志功能而已。Ext4 可以提供更佳的性能和可靠性,还有更为丰富的功能。
相对于Ext3,特点如下:
1. 与 Ext3 兼容。 执行若干条命令,就能从 Ext3 在线迁移到 Ext4,而无须重新格式化磁盘或重新安装系统。原有 Ext3 数据结构照样保留,Ext4 作用于新数据,当然,整个文件系统因此也就获得了 Ext4 所支持的更大容量。
2. 更大的文件系统和更大的文件。 较之 Ext3 目前所支持的最大 16TB 文件系统和最大 2TB 文件,Ext4 分别支持 1EB(1,048,576TB, 1EB=1024PB, 1PB=1024TB)的文件系统,以及 16TB 的文件。
3. 无限数量的子目录。 Ext3 目前只支持 32,000 个子目录,而 Ext4 支持无限数量的子目录。
4. Extents。 Ext3 采用间接块映射,当操作大文件时,效率极其低下。比如一个 100MB 大小的文件,在 Ext3 中要建立 25,600 个数据块(每个数据块大小为 4KB)的映射表。而 Ext4 引入了现代文件系统中流行的 extents 概念,每个 extent 为一组连续的数据块,上述文件则表示为“该文件数据保存在接下来的 25,600 个数据块中”,提高了不少效率。
5. 多块分配。 当 写入数据到 Ext3 文件系统中时,Ext3 的数据块分配器每次只能分配一个 4KB 的块,写一个 100MB 文件就要调用 25,600 次数据块分配器,而 Ext4 的多块分配器“multiblock allocator”(mballoc) 支持一次调用分配多个数据块。
6. 延迟分配。 Ext3 的数据块分配策略是尽快分配,而 Ext4 和其它现代文件操作系统的策略是尽可能地延迟分配,直到文件在 cache 中写完才开始分配数据块并写入磁盘,这样就能优化整个文件的数据块分配,与前两种特性搭配起来可以显著提升性能。
7. 快速 fsck。 以前执行 fsck 第一步就会很慢,因为它要检查所有的 inode,现在 Ext4 给每个组的 inode 表中都添加了一份未使用 inode 的列表,今后 fsck Ext4 文件系统就可以跳过它们而只去检查那些在用的 inode 了。
8. 日志校验。 日志是最常用的部分,也极易导致磁盘硬件故障,而从损坏的日志中恢复数据会导致更多的数据损坏。Ext4 的日志校验功能可以很方便地判断日志数据是否损坏,而且它将 Ext3 的两阶段日志机制合并成一个阶段,在增加安全性的同时提高了性能。
9. “无日志”(No Journaling)模式。 日志总归有一些开销,Ext4 允许关闭日志,以便某些有特殊需求的用户可以借此提升性能。
10. 在线碎片整理。 尽管延迟分配、多块分配和 extents 能有效减少文件系统碎片,但碎片还是不可避免会产生。Ext4 支持在线碎片整理,并将提供 e4defrag 工具进行个别文件或整个文件系统的碎片整理。
11. inode 相关特性。 Ext4 支持更大的 inode,较之 Ext3 默认的 inode 大小 128 字节,Ext4 为了在 inode 中容纳更多的扩展属性(如纳秒时间戳或 inode 版本),默认 inode 大小为 256 字节。Ext4 还支持快速扩展属性(fast extended attributes)和 inode 保留(inodes reservation)。
12. 持久预分配(Persistent preallocation)。 P2P 软件为了保证下载文件有足够的空间存放,常常会预先创建一个与所下载文件大小相同的空文件,以免未来的数小时或数天之内磁盘空间不足导致下载失败。 Ext4 在文件系统层面实现了持久预分配并提供相应的 API(libc 中的 posix_fallocate()),比应用软件自己实现更有效率。
13. 默认启用 barrier。 磁 盘上配有内部缓存,以便重新调整批量数据的写操作顺序,优化写入性能,因此文件系统必须在日志数据写入磁盘之后才能写 commit 记录,若 commit 记录写入在先,而日志有可能损坏,那么就会影响数据完整性。Ext4 默认启用 barrier,只有当 barrier 之前的数据全部写入磁盘,才能写 barrier 之后的数据。(可通过 "mount -o barrier=0" 命令禁用该特性。)