爬虫的规定
Robots协议
网站开发者对于网络爬虫的规范的公告,你可以不遵守可能存在法律风险,但尽量去遵守
Robots协议:在网页的根目录+/robots.txt 如www.baidu.com/robots.txt
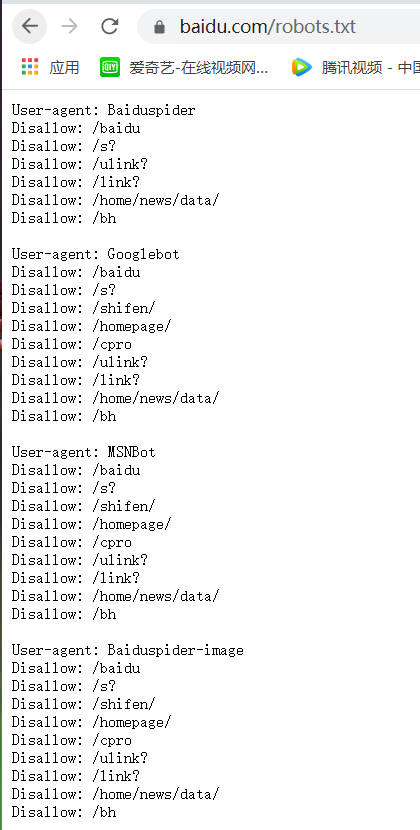
Robots协议的基本语法:
#*代表所有,/代表根目录 User-agent:* #user-agent代表来源 Allow:/ #代表运行爬取的内容 Disallow:/ #代表不可爬取的目录,如果是/后面没有写内容,便是其对应的访问者不可爬取所有内容
并不是所有网站都有Robots协议
如果一个网站不提供Robots协议,是说明这个网站对应所有爬虫没有限制
可以不参考robots协议,比如我们写的小程序访问量很少,内容也少但是内容不能用于商业用途
总的来说请准守Robots协议