本篇总结涉及到的相关词汇:
数据集:SQuAD、TriviaQA、MS MARCO
深度学习:R-Net、S-Net、Char-CNN、Glove
本文同时在不断补充更新中~
一、基于知识图谱的QA
以知识图谱构建事实性问答系统,称之为KBQA,是从知识图谱中寻找答案。对事实性问答任务而言,这种做法依赖于知识图谱,准确率比较高,同时也要求我们的知识图谱是比较大规模的,因为KB-QA无法给出在知识图谱之外的答案。KB-QA又可以分成两类:基于符号表示的KB-QA,基于向量表示的KB-QA。
- 基于符号表示的KBQA
这种做法主要是利用语义解析的方法对问题进行解析,把问题转换成逻辑表达式,再加上一些规则,得到一个结构化的SQL查询语句,用来查询知识库得到答案。
- 语义解析的传统做法是:问题->短语检测->资源映射->语义组合->逻辑表达式
- 短语检测:词性标注、实体识别
- 资源映射: 实体链接、实体消岐、关系抽
- 语义组合:将映射得到的资源进行组合,得到逻辑形式。
- 训练分类器:计算每一种语义解析结果的概率,再对于问答对计算损失函数。
- 现在的做法一般是:建图->信息抽取->提取特征->查询图特征->分类器
- 建图:包含知识库实体(圆角矩形,比如family guy),聚合函数(棱形,比如argmin),中间变量 y 和答案变量 x
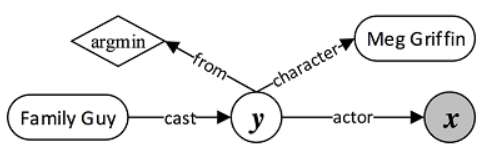
-
- 信息抽取:提取问题特征(问题词,问题焦点,问题主题词和问题中心动词),识别命名实体,进行词性标注来删除限定词和介词。构建查询图特征:主题词链接特征,核心推导链特征,约束聚合特征,总体特征
- 确定核心推导链:将自然语言问题,映射为一个谓语序列
- 增加约束和聚合:增加约束和聚合函数相当于扩展查询图,缩小答案范围
- 分类器:对查询图做二分类,只有正确的查询图才是正样本
- 信息抽取:提取问题特征(问题词,问题焦点,问题主题词和问题中心动词),识别命名实体,进行词性标注来删除限定词和介词。构建查询图特征:主题词链接特征,核心推导链特征,约束聚合特征,总体特征
- 基于向量表示的KB-QA
- 如何学习问题向量:把问题用LSTM进行建模(因为问题本来就是自然语言)
- 如何学习答案向量:答案不能简单映射成词向量,一般是利用到答案实体,答案类型,答案路径(从问题主题词到答案的知识库路径),答案关系(从主题词到答案之间的知识库关系),答案上下文信息(与答案在一定范围内有连接的知识库实体),然后把这些特征分别映射成不同的向量,作为答案的其中一个向量(而不是直接拼接起来),最后用这些特征向量依次和问题做匹配,把score加起来作为总的score。
- 进行匹配:计算问题与答案的得分
- 参考方法
- 最简单的方法:直接进行向量点乘,可以用CNN对这种方式做改进
- Attention:计算答案对问题每一步的Attention
- 训练目标:进行Margin Loss,极大化对正确目标的score,极小化对错误目标的score
- 辅助方法a:Multi-Task Learning + TransE训练知识库
- 辅助方法b:记忆网络
- 比较
- 基于符号的方法
- 缺点:需要加入大量的人工规则,构建难度较大
- 优点:通过规则可以回答更加复杂的问题,有较强的解释性
- 基于向量的方法
- 缺点:目前只能回答较为简单的问题
- 优点:不需要人工规则,构建难度比较小
- 基于符号的方法
- 改进(突破)
- 复杂问句:目前end2end的模型只能解决简单问答
- 多源异构知识库问答:对于开放域问答,单一知识库不能完全回答所有问题
- 预料的训练:知识库中实体和关系;描述实体的文本信息;结合结构化和非结构化文本
二、基于阅读理解的问答系统
对非结构化文章进行阅读理解得到答案,又可以分成匹配式QA,抽取式QA和生成式QA,目前绝大部分是抽取式QA。
- 匹配式QA
给定文章,问题,和一个候选答案集(一般是实体或者单词),从候选答案中选一个score最高的作为答案。
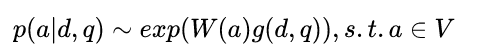
-
- d document / q query / a answer 求概率最大的候选答案 (词汇表V 可以定义为 document 和 query 中的所有词,也可以定义为所有的 entity,或者定义为这篇document里面的词,而有的会直接提供包括正确答案在内的 N个候选答案。)
- 重点在于求解g(d, q),g是对document和question建模得到的向量,把这个向量变化到词表空间再进行归一化可以得到所有候选score
- 方法一:直接把query跟document拼接起来,输入到双向LSTM中,最终得到一个向量g(LSTM Reader)
- 方法二:先对query用LSTM进行建模得到问题向量u,然后也对document建模,接下来用u 给document分配attention,去算文章向量r,再结合u和r得到g。相当于每读完一个问题,然后带着这个问题去读文档(Attentive Reader)
- 方法三:先对query用LSTM进行建模得到问题向量u,然后也对document建模,接下来用u 给document分配attention,去算文章向量r,再结合u和r得到g。相当于每读完一个问题,然后带着这个问题去读文档,增加了计算量(Impatient Reader)
- 方法四:Gated-Attenttion Reader
- 抽取式QA
数据形式是给定一篇文章,围绕这篇文章提出一些问题,然后从文章中抽取出答案。
目前已经有的数据集有斯坦福的SQuAD、TriviaQA数据集等。
-
- SQuAD数据集的特点,SQuAD数据集包含10w个样例,每个样例大致由一个三元组构成(文章Passage, 相应问题Query, 对应答案Answer), 以下皆用(P,Q,A)表示。
- 生成式QA
目前只有MSRA的MS MARCO数据集答案形式如下:
1)答案完全在某篇原文
2)答案分别出现在多篇文章中
3)答案一部分出现在原文,一部分出现在问题中
4)答案的一部分出现在原文,另一部分是生成的新词
5)答案完全不在原文出现(Yes / No 类型)
- MSRA发布这个数据集后,也发布了S-Net,在R-Net基础上使用Multi task Learning,先抽取出答案后,利用这个特征再对文章生成答案。
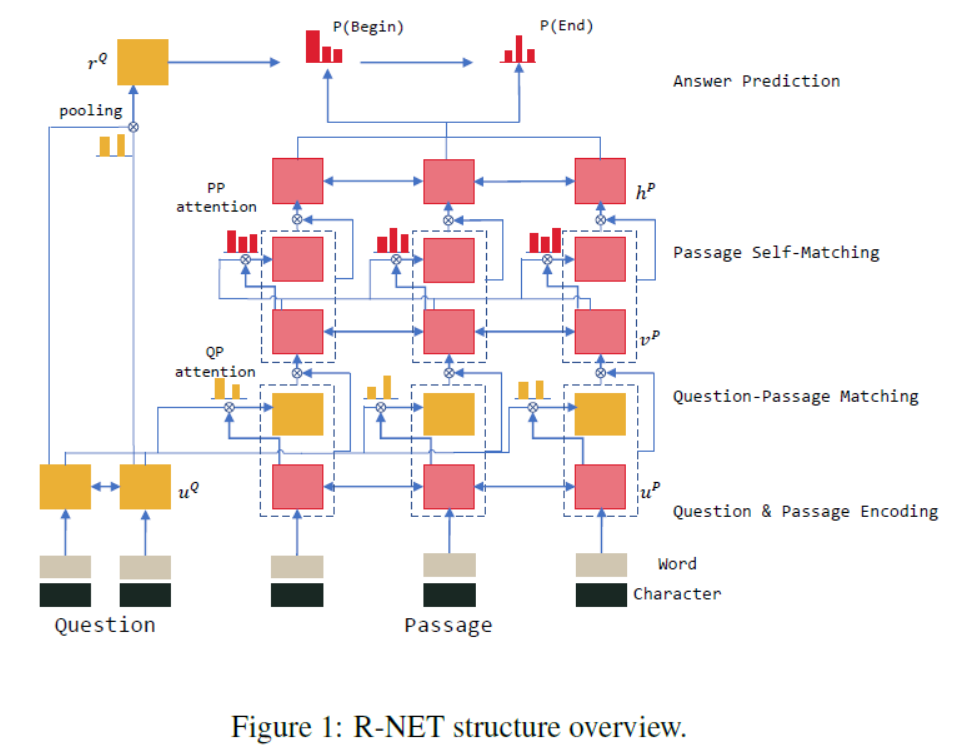
R-Net在之后的笔记中会做详细介绍

- 抽取部分
这个模型做了两个任务,预测答案id以及对文档进行排序
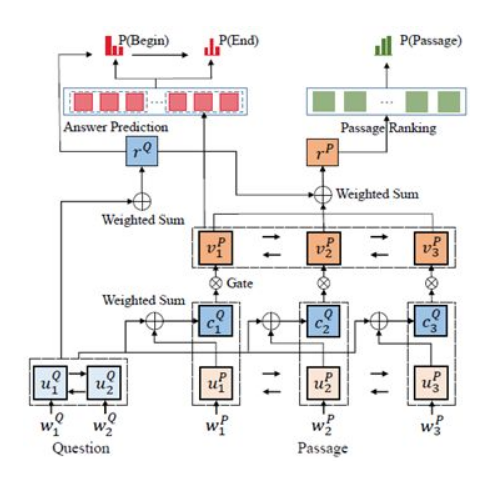
-
- 左下角是预测答案id
- 右下角是对文章进行建模
- 右上角是对文章进行排序(对问题和答案计算得出score然后进行排序)
- 生成部分
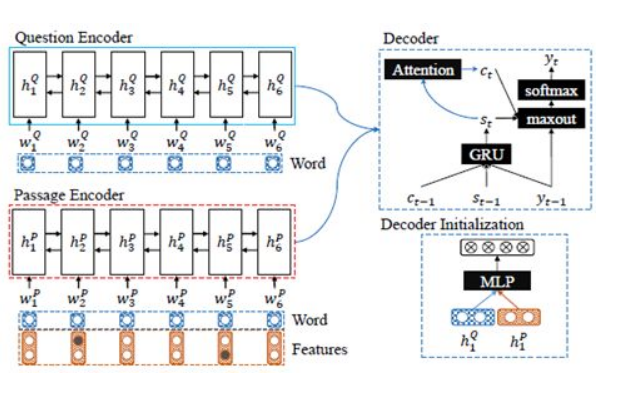
将答案标注出来后,将其作为一个特征信息叠加到文章向量中,然后对这段文章和问题重新进行encoder建模得到一个综合的语义向量,然后输入到decoder中生成答案,这就是一个简单的seq2seq模型(专栏作者认为问题所用的lstm可以与之前的抽取模型中的问题lstm进行共享,这样就不在需要进行重新的问题lstm)
参考链接
知乎专栏QA小结 https://zhuanlan.zhihu.com/p/35667773
R-Net解读 https://zhuanlan.zhihu.com/p/36855204
Char-CNN解读 https://blog.csdn.net/liuchonge/article/details/70947995
Glove(Global Vectors for Word Representation)详解 http://www.fanyeong.com/2018/02/19/glove-in-detail/