// 启动 journalnode(在所有 datanode 上执行,也就是 cluster1, cluster2, cluster3)
$ hadoop-daemon.sh start journalnode 启动后使用 jps 命令可以看到 JournalNode 进程
// 格式化 HDFS(在 cluster1 上执行)
$ hdfs namenode -format
// 格式化完毕后可关闭 journalnode(在所有 datanode 上执行)
$ hadoop-daemon.sh stop journalnode
// 启动 HDFS(cluster1 上)
$ start-dfs.sh
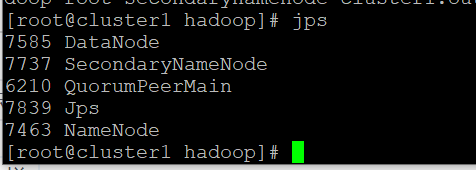
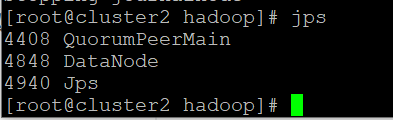
// 启动后 cluster1 上使用 jps 可以看到 NameNode, DataNode, SecondaryNameNode cluster2 和 cluster3 上可以看到 DataNode
$ jps
-----------------------------------------------------------------------------------------------------------------------------------------
结果,cluster1 上使用 jps 看到 NameNode, SecondaryNameNode cluster2 和 cluster3 上什么都没看到!!!!
原因是:
当我们使用hadoop namenode -format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件中dfs.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,datanode中保存的current/VERSION文件中的clustreID的值是上一次格式化保存的clusterID,这样,datanode和namenode之间的ID不一致。
也就是只能格式化一次,以后不用格式化了!!!
解决方法:

删除后,重新格式化一次,再启动,就可以看到了!