理论学习:
3. 算法详述
3.1 步骤:
为了判断未知实例的类别,以所有已知类别的实例作为参照
选择参数K
计算未知实例与所有已知实例的距离
选择最近K个已知实例
根据少数服从多数的投票法则(majority-voting),让未知实例归类为K个最邻近样本中最多数的类别
3.2 细节:
关于K
关于距离的衡量方法:
3.2.1 Euclidean Distance(欧式距离) 定义

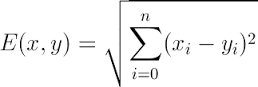
其他距离衡量:余弦值(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)
4. 算法优缺点:
4.1 算法优点
简单
易于理解
容易实现
通过对K的选择可具备丢噪音数据的健壮性
4.2 算法缺点
需要大量空间储存所有已知实例
算法复杂度高(需要比较所有已知实例与要分类的实例)
当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例实际并木接近目标样本
5. 改进版本
考虑距离,根据距离加上权重
比如: 1/d (d: 距离)
应用:
1、用库来进行实现算法
1 from sklearn import neighbors 2 from sklearn import datasets 3 4 knn = neighbors.KNeighborsClassifier() 5 6 iris = datasets.load_iris() 7 8 print(iris) 9 10 knn.fit(iris.data, iris.target) # 建模,两个参数:二维的特征值矩阵、一维的每一个实例所对应的对象 11 12 predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]]) 13 14 print(predictedLabel)
2、不调用任何库来实现knn算法,其中使用到的数据集是sklearn自带的iris数据集
1 # 不调用任何库来实现knn算法 2 3 import csv 4 import random 5 import math 6 import operator 7 8 # 将数据集装载到Python里面 9 # filename:数据集存放的文件 10 # split:以此参数为界限将数据集分为trainingSet训练集和testSet测试集 11 def loadDataset(filename, split, trainingSet=[], testSet=[]): 12 with open(filename, 'r') as csvfile: # 打开文件 13 lines = csv.reader(csvfile) # 读取文件的所有行 14 dataset = list(lines) # 文件内容转换成list结构 15 16 # 将数据集分为两部分 17 for x in range(len(dataset) - 1): 18 for y in range(4): 19 dataset[x][y] = float(dataset[x][y]) 20 # 随机数小于split放入训练集,大于就放入测试集 21 if random.random() < split: 22 trainingSet.append(dataset[x]) 23 else: 24 testSet.append(dataset[x]) 25 26 # 计算两个实例之间的欧式距离 27 # instance1、instance2是两个实例 28 # length是实例的维数 29 def euclideanDistance(instance1, instance2, length): 30 distance = 0 # 设置初始值为0 31 32 # 计算所有维度的差的平方和 33 for x in range(length): 34 distance += pow((instance1[x] - instance2[x]), 2) 35 return math.sqrt(distance) 36 37 # 测试集中的一个实例到训练集的距离最近的k个实例 38 # trainingSet:训练集 39 # testInstance:测试集实例 40 # k:距离最近的个数 41 def getNeighbors(trainingSet, testInstance, k): 42 distances = [] 43 length = len(testInstance) - 1 44 for x in range(len(trainingSet)): 45 dist = euclideanDistance(testInstance, trainingSet[x], length) 46 distances.append((trainingSet[x], dist)) 47 distances.sort(key=operator.itemgetter(1)) 48 neighbors = [] 49 for x in range(k): 50 neighbors.append(distances[x][0]) 51 return neighbors 52 53 def getResponse(neighbors): 54 """ 55 得到 56 :param neighbors:附近的实例 57 :return:得票最多的类别情况 58 59 """ 60 classVotes = {} 61 for x in range(len(neighbors)): 62 response = neighbors[x][-1] 63 if response in classVotes: 64 classVotes[response] += 1 65 else: 66 classVotes[response] = 1 67 sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True) # classVotes.iteritems() 68 return sortedVotes[0][0] 69 70 def getAccuracy(testSet, predictions): 71 """ 72 得到预测的正确率 73 :param testSet:测试集 74 :param predictions: 预测结果 75 :return: 预测的正确率 76 77 """ 78 correct = 0 79 for x in range(len(testSet)): 80 if testSet[x][-1] == predictions[x]: 81 correct += 1 82 return (correct/float(len(testSet))) * 100.0 83 84 85 def main(): 86 """ 87 88 :return: 89 """ 90 trainingSet = [] 91 testSet = [] 92 split = 0.67 # 把2/3的数据作为训练集,1/3为测试集 93 loadDataset(r'irisdata.txt', split, trainingSet, testSet) 94 print('Train set: ' + repr(len(trainingSet))) 95 print('Test set: ' + repr(len(testSet))) 96 97 predictions = [] 98 k = 3 99 for x in range(len(testSet)): 100 neighbors = getNeighbors(trainingSet, testSet[x], k) # 找到各个测试集实例最近的邻居 101 result = getResponse(neighbors) 102 predictions.append(result) 103 print('> predicted=' + repr(result) + ',actual=' + repr(testSet[x][-1])) 104 accuracy = getAccuracy(testSet, predictions) 105 print('Accuracy: ' + repr(accuracy) + '%') 106 107 108 if __name__ == '__main__': 109 main()