引言
狭义的分布式系统指由网络连接的计算机系统,每个节点独立地承担计算或存储任务,节点间通过网络协同工作。广义的分布式系统是一个相对的概念,正如Leslie Lamport所说[1]:
What is a distributed systeme. Distribution is in the eye of the beholder.
To the user sitting at the keyboard, his IBM personal computer is a nondistributed system.
To a flea crawling around on the circuit board, or to the engineer who designed it, it's very much a distributed system.
一致性是分布式理论中的根本性问题,近半个世纪以来,科学家们围绕着一致性问题提出了很多理论模型,依据这些理论模型,业界也出现了很多工程实践投影。下面我们从一致性问题、特定条件下解决一致性问题的两种方法(2PC、3PC)入门,了解最基础的分布式系统理论。
一致性(consensus)
何为一致性问题?简单而言,一致性问题就是相互独立的节点之间如何达成一项决议的问题。分布式系统中,进行数据库事务提交(commit transaction)、Leader选举、序列号生成等都会遇到一致性问题。这个问题在我们的日常生活中也很常见,比如牌友怎么商定几点在哪打几圈麻将:

《赌圣》,1990
假设一个具有N个节点的分布式系统,当其满足以下条件时,我们说这个系统满足一致性:
- 全认同(agreement): 所有N个节点都认同一个结果
- 值合法(validity): 该结果必须由N个节点中的节点提出
- 可结束(termination): 决议过程在一定时间内结束,不会无休止地进行下去
有人可能会说,决定什么时候在哪搓搓麻将,4个人商量一下就ok,这不很简单吗?
但就这样看似简单的事情,分布式系统实现起来并不轻松,因为它面临着这些问题:
- 消息传递异步无序(asynchronous): 现实网络不是一个可靠的信道,存在消息延时、丢失,节点间消息传递做不到同步有序(synchronous)
- 节点宕机(fail-stop): 节点持续宕机,不会恢复
- 节点宕机恢复(fail-recover): 节点宕机一段时间后恢复,在分布式系统中最常见
- 网络分化(network partition): 网络链路出现问题,将N个节点隔离成多个部分
- 拜占庭将军问题(byzantine failure)[2]: 节点或宕机或逻辑失败,甚至不按套路出牌抛出干扰决议的信息
假设现实场景中也存在这样的问题,我们看看结果会怎样:
我: 老王,今晚7点老地方,搓够48圈不见不散! …… (第二天凌晨3点) 隔壁老王: 没问题! // 消息延迟 我: …… ---------------------------------------------- 我: 小张,今晚7点老地方,搓够48圈不见不散! 小张: No …… (两小时后……) 小张: No problem! // 宕机节点恢复 我: …… ----------------------------------------------- 我: 老李头,今晚7点老地方,搓够48圈不见不散! 老李: 必须的,大保健走起! // 拜占庭将军
(这是要打麻将呢?还是要大保健?还是一边打麻将一边大保健……)
还能不能一起愉快地玩耍...
我们把以上所列的问题称为系统模型(system model),讨论分布式系统理论和工程实践的时候,必先划定模型。例如有以下两种模型:
- 异步环境(asynchronous)下,节点宕机(fail-stop)
- 异步环境(asynchronous)下,节点宕机恢复(fail-recover)、网络分化(network partition)
2比1多了节点恢复、网络分化的考量,因而对这两种模型的理论研究和工程解决方案必定是不同的,在还没有明晰所要解决的问题前谈解决方案都是一本正经地耍流氓。
一致性还具备两个属性,一个是强一致(safety),它要求所有节点状态一致、共进退;一个是可用(liveness),它要求分布式系统24*7无间断对外服务。FLP定理(FLP impossibility)[3][4] 已经证明在一个收窄的模型中(异步环境并只存在节点宕机),不能同时满足 safety 和 liveness。
FLP定理是分布式系统理论中的基础理论,正如物理学中的能量守恒定律彻底否定了永动机的存在,FLP定理否定了同时满足safety 和 liveness 的一致性协议的存在。

《怦然心动 (Flipped)》,2010
工程实践上根据具体的业务场景,或保证强一致(safety),或在节点宕机、网络分化的时候保证可用(liveness)。2PC、3PC是相对简单的解决一致性问题的协议,下面我们就来了解2PC和3PC。
2PC
2PC(tow phase commit)两阶段提交[5]顾名思义它分成两个阶段,先由一方进行提议(propose)并收集其他节点的反馈(vote),再根据反馈决定提交(commit)或中止(abort)事务。我们将提议的节点称为协调者(coordinator),其他参与决议节点称为参与者(participants, 或cohorts):

2PC, phase one
在阶段1中,coordinator发起一个提议,分别问询各participant是否接受。
2PC, phase two
在阶段2中,coordinator根据participant的反馈,提交或中止事务,如果participant全部同意则提交,只要有一个participant不同意就中止。
在异步环境(asynchronous)并且没有节点宕机(fail-stop)的模型下,2PC可以满足全认同、值合法、可结束,是解决一致性问题的一种协议。但如果再加上节点宕机(fail-recover)的考虑,2PC是否还能解决一致性问题呢?
coordinator如果在发起提议后宕机,那么participant将进入阻塞(block)状态、一直等待coordinator回应以完成该次决议。这时需要另一角色把系统从不可结束的状态中带出来,我们把新增的这一角色叫协调者备份(coordinator watchdog)。coordinator宕机一定时间后,watchdog接替原coordinator工作,通过问询(query) 各participant的状态,决定阶段2是提交还是中止。这也要求 coordinator/participant 记录(logging)历史状态,以备coordinator宕机后watchdog对participant查询、coordinator宕机恢复后重新找回状态。
从coordinator接收到一次事务请求、发起提议到事务完成,经过2PC协议后增加了2次RTT(propose+commit),带来的时延(latency)增加相对较少。
3PC
3PC(three phase commit)即三阶段提交[6][7],既然2PC可以在异步网络+节点宕机恢复的模型下实现一致性,那还需要3PC做什么,3PC是什么鬼?
在2PC中一个participant的状态只有它自己和coordinator知晓,假如coordinator提议后自身宕机,在watchdog启用前一个participant又宕机,其他participant就会进入既不能回滚、又不能强制commit的阻塞状态,直到participant宕机恢复。这引出两个疑问:
- 能不能去掉阻塞,使系统可以在commit/abort前回滚(rollback)到决议发起前的初始状态
- 当次决议中,participant间能不能相互知道对方的状态,又或者participant间根本不依赖对方的状态
相比2PC,3PC增加了一个准备提交(prepare to commit)阶段来解决以上问题:
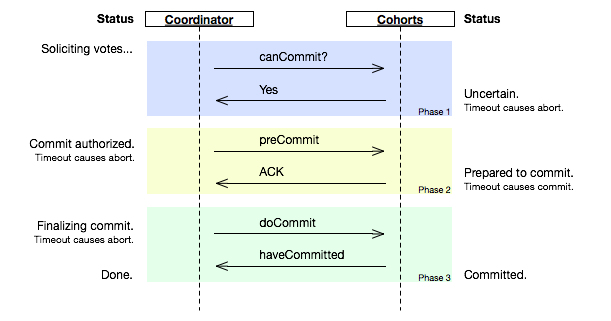
图片截取自wikipedia
coordinator接收完participant的反馈(vote)之后,进入阶段2,给各个participant发送准备提交(prepare to commit)指令。participant接到准备提交指令后可以锁资源,但要求相关操作必须可回滚。coordinator接收完确认(ACK)后进入阶段3、进行commit/abort,3PC的阶段3与2PC的阶段2无异。协调者备份(coordinator watchdog)、状态记录(logging)同样应用在3PC。
participant如果在不同阶段宕机,我们来看看3PC如何应对:
- 阶段1: coordinator或watchdog未收到宕机participant的vote,直接中止事务;宕机的participant恢复后,读取logging发现未发出赞成vote,自行中止该次事务
- 阶段2: coordinator未收到宕机participant的precommit ACK,但因为之前已经收到了宕机participant的赞成反馈(不然也不会进入到阶段2),coordinator进行commit;watchdog可以通过问询其他participant获得这些信息,过程同理;宕机的participant恢复后发现收到precommit或已经发出赞成vote,则自行commit该次事务
- 阶段3: 即便coordinator或watchdog未收到宕机participant的commit ACK,也结束该次事务;宕机的participant恢复后发现收到commit或者precommit,也将自行commit该次事务
因为有了准备提交(prepare to commit)阶段,3PC的事务处理延时也增加了1个RTT,变为3个RTT(propose+precommit+commit),但是它防止participant宕机后整个系统进入阻塞态,增强了系统的可用性,对一些现实业务场景是非常值得的。
小结
以上介绍了分布式系统理论中的部分基础知识,阐述了一致性(consensus)的定义和实现一致性所要面临的问题,最后讨论在异步网络(asynchronous)、节点宕机恢复(fail-recover)模型下2PC、3PC怎么解决一致性问题。
阅读前人对分布式系统的各项理论研究,其中有严谨地推理、证明,有一种数学的美;观现实中的分布式系统实现,是综合各种因素下妥协的结果。
[1] Solved Problems, Unsolved Problems and Problems in Concurrency, Leslie Lamport, 1983
[2] The Byzantine Generals Problem, Leslie Lamport,Robert Shostak and Marshall Pease, 1982
[3] Impossibility of Distributed Consensus with One Faulty Process, Fischer, Lynch and Patterson, 1985
[4] FLP Impossibility的证明, Daniel Wu, 2015
[5] Consensus Protocols: Two-Phase Commit, Henry Robinson, 2008
[6] Consensus Protocols: Three-phase Commit, Henry Robinson, 2008
[7] Three-phase commit protocol, Wikipedia