目录
1、何为数据解析
2、xml解析
3、Excel解析
4、json解析
一、何为数据解析
举个栗子----如果不同的程序之间需要通信,假如说A程序需要B程序做一件事,B程序说
我可以做这件事,但是需要给我必须的数据。我才能做这件事。
我们可以用下面一副图表示:
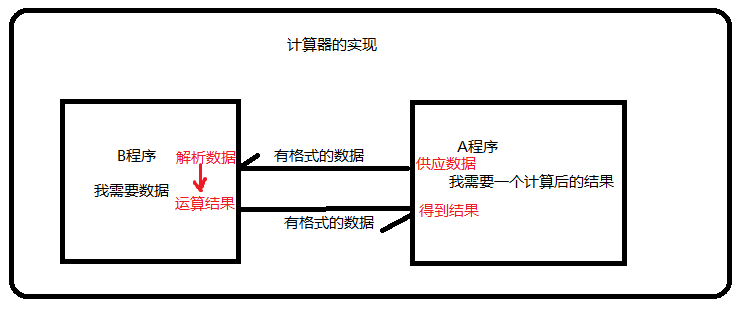
在上面这幅图中,两个数据的传输都是有数据格式的。我们要做的就是解析这种数据格式或者生成这种数据格式的数据
二、XML解析
首先我们先认识一下xml数据:
可扩展标记语言(英语:Extensible Markup Language,简称:XML),是一种标记语言。标记指计算机所能理解的信息符号,通过此种标记,计算机之间可以处理包含各种信息的文章等。 -----by wiki
接下来我们看一个XML数据吧
<?xml version="1.0" encoding="UTF-8"?> <Students> <Student> <name java="初级">张三</name> <age>14</age> <fav>烫头</fav> </Student> <Student> <name java="高级">李四</name> <age>16</age> <fav>玩游戏</fav> </Student> </Students>
我们可以看到xml数据的格式,xml数据的第一行写的是xml版本号和字符编码集
它下面的字标签都是成对出现的,这个xml可以表示两个对象。
在Java中xml解析的常见方式大致可以分为以下几个
1、DOM解析----文本对象模型(Document Object Model) w3c标准
2、SAX解析---- 基于事务驱动的解析
3、JAXP SAX和DOM结合
4、JDOM 第三方开源项目 jdom-*.jar
5、DOM4J 第三方开源项目 dom4j-*.jar
在此,我们主要讲解一下java内置的SAX解析和DOM解析
1.DOM解析
原理:将整个xml文档看成一颗树,会将整个文档一次性读入内存中(适合于小型xml文件解析)
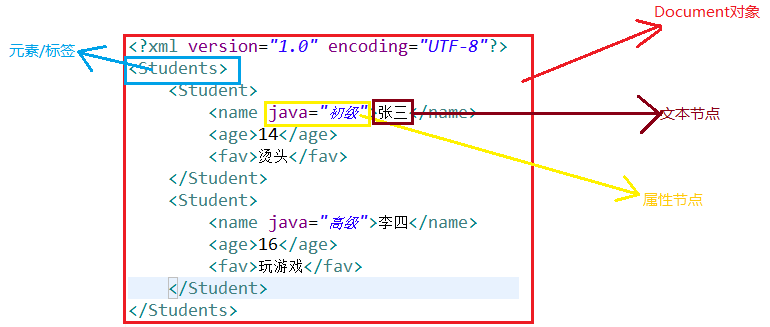
首先我们先要了解以下DOM解析里的一些名词
Document对象:文档对象 extends Node
Node对象:节点对象,所有节点类型的父接口包含元素/标签、属性、文本、注释
Element:元素/标签(extends Node)
Attr:属性节点(extends Node)
Text:文本节点(extends Node)
ps:除文档对象之外,其他的都是节点对象
为了更形象的解释一下,请看如下图:
XML解析的步骤大致可分为:
1、 构建器工厂
2、构建器
3、xml文件-》document对象
4、节点内容解析
package com.demo.udp; import java.io.File; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class DomParse { public static void parseXml(String xmlfile){ //创建一个document工厂实例 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); Document doc = null; try { //有document工厂实例构建一个documentBuilder对象 DocumentBuilder builder = factory.newDocumentBuilder(); //解析整个xml文件构建成一个Document对象 doc = builder.parse(new File(xmlfile)); } catch (ParserConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (SAXException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } //获取Document对象的根节点---->Students Element root = doc.getDocumentElement(); //根节点下找到所有的Student节点--->Student ps:这里的NodeList不是集合,不能foreach遍历 NodeList elelist = root.getElementsByTagName("Student"); for(int i =0 ;i<elelist.getLength();i++){ Node stunode = elelist.item(i); //由于Node里面没有getElementsByTagName方法,所以只能通过向下强转成Element才能找到子节点 if(stunode.getNodeType()==Node.ELEMENT_NODE){ Element stuele = (Element)stunode; Node name = stuele.getElementsByTagName("name").item(0); System.out.println("name:"+name.getTextContent()); //Node name2 = root.getElementsByTagName("name").item(i); //System.out.println(name2.getFirstChild().getNodeValue()); Node java = name.getAttributes().getNamedItem("java"); System.out.println("java:"+java.getNodeValue()); } } } public static void main(String[] args) { parseXml("Students.xml"); } }
XML的生成大致可分为:
1、 构建器工厂
2、构建器
3、构造一个空的document树-----数据结构为树。
4、构造节点对象(元素、属性、文本)
5、设定节点之间的关系
6、转换(doc对象-》xml文件)
6.1 转换器工厂
6.2 转换器对象
6.3 输入源 doc对象-》Source对象 输出源 xml文件-》Result对象
6.4 transform(Source对象,Result对象)
/** * 创建xml文件 */ public static void createXml(String xmlfile){ //要写入的数据 Student student = new Student("张三",18,"LOL","学习"); Student student2 = new Student("李四", 19, "cs:go", "打游戏"); DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); Document doc = null; try { DocumentBuilder builder = factory.newDocumentBuilder(); //创建document对象 doc = builder.newDocument(); } catch (ParserConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } //创建根节点 Element students = doc.createElement("Students"); //创建元素节点 Element stu1 = doc.createElement("Student"); Element stu2 = doc.createElement("Student"); Element name1 = doc.createElement("name"); Element name2 = doc.createElement("name"); Element age1 = doc.createElement("age"); Element age2 = doc.createElement("age"); Element fav1 = doc.createElement("fav"); Element fav2 = doc.createElement("fav"); //设置节点的关系,构建成一颗树 doc.appendChild(students); students.appendChild(stu1); students.appendChild(stu2); stu1.appendChild(name1); stu1.appendChild(age1); stu1.appendChild(fav1); stu2.appendChild(name2); stu2.appendChild(age2); stu2.appendChild(fav2); //给属性节点与文本节点赋值 name1.setAttribute("java", student.getAlivable()); name2.setAttribute("java", student2.getAlivable()); name1.setTextContent(student.getName()); age1.setTextContent(student.getAge()+""); fav1.setTextContent(student.getFav()); name2.setTextContent(student2.getName()); age2.setTextContent(student2.getAge()+""); fav2.setTextContent(student2.getFav()); //讲构建好的dom树转换成xml文件 transform(doc,xmlfile); System.out.println("XML生成完毕!"); } /** * 树转换方法 * @param doc * @param filename */ private static void transform(Document doc,String filename){ //构建转换工厂 TransformerFactory factory = TransformerFactory.newInstance(); try { //创建转换器对象 Transformer transformer = factory.newTransformer(); Source sourse = new DOMSource(doc); Result result = new StreamResult(new File(filename)); transformer.transform(sourse, result); } catch (TransformerConfigurationException e) { e.printStackTrace(); } catch (TransformerException e) { // TODO Auto-generated catch block e.printStackTrace(); } }
生成的新xml文件格式如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <Students> <Student> <name java="学习">张三</name> <age>18</age> <fav>LOL</fav> </Student> <Student> <name java="打游戏">李四</name> <age>19</age> <fav>cs:go</fav> </Student> </Students>
2.SAX解析
前面我有提到SAX解析是一种基于数据事物驱动的解析,意思就是这个解析式被动式的。
它不会自己主动去解析xml文件,而是从上往下解析,遇到的xml文件是什么类型就执行相应的方法。
SAX解析中解析的规则需要是一个DefaultHandler的子类。这个子类中重写的方法则是解析规则。

下面就写一个实例来看看SAX解析的魅力吧:


package com.demo.udp; import java.io.IOException; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.SAXException; public class SAXParse { public static void start(String filePath){ SAXParserFactory factory = SAXParserFactory.newInstance(); try { SAXParser sax = factory.newSAXParser(); sax.parse(filePath, new MySax()); } catch (ParserConfigurationException | SAXException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static void main(String[] args) { start("Students.xml"); } }
package com.demo.udp; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; public class MySax extends DefaultHandler{ //标签名字 private String tagname=""; @Override public void startDocument() throws SAXException { // TODO Auto-generated method stub super.startDocument(); System.out.println("开启SAX解析..."); } @Override public void endDocument() throws SAXException { // TODO Auto-generated method stub super.endDocument(); System.out.println("SAX解析结束"); } /** * 这个方法的参数依次为----名称空间(如果没有是null),本地空间,如果没有命名空间这个为null,真实名称,属性 */ @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { // TODO Auto-generated method stub tagname = qName; super.startElement(uri, localName, qName, attributes); for(int i = 0 ;i<attributes.getLength();i++){ //输出属性 System.out.println(attributes.getQName(i)+":"+attributes.getValue(i)); } } @Override public void endElement(String uri, String localName, String qName) throws SAXException { // TODO Auto-generated method stub super.endElement(uri, localName, qName); //每次结束后需要将tagname置为空 tagname = ""; } /** * 接收元素中字符数据的通知参数依次为-----解析出来的字符,字符数组中开始的位置,字符数组中使用的长度 */ @Override public void characters(char[] ch, int start, int length) throws SAXException { // TODO Auto-generated method stub super.characters(ch, start, length); String str = new String(ch, start, length); if(tagname.equals("name")||tagname.equals("age")||tagname.equals("fav")){ System.out.println(str); } } }
以上代码中我忘了说明一下命名空间了
xml文件中存在一种命名空间的东西----XML命名空间(XML namespace,也译作XML名称空间、XML名字空间)用于在一个XML文档中提供名字唯一的元素和属性。
它相当于我们java工程里的包。命名空间是自己规定的,其它们的访问范围也是自己定义的。
命名空间的规则如下:

既然讲了SAX的解析,那么接下来讲一下SAX生成xml文件吧!
同样,更DOM生成xml文件一样,也是需要装换成xml文件

-------------------------我是分隔符---------------------------------------------

-----------------------主要类-------------------------

----------------------TransformerHandler的父类-------------------------------

package com.demo.udp; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.util.ArrayList; import java.util.List; import javax.xml.transform.OutputKeys; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.sax.SAXTransformerFactory; import javax.xml.transform.sax.TransformerHandler; import javax.xml.transform.stream.StreamResult; import org.xml.sax.SAXException; import org.xml.sax.helpers.AttributesImpl; public class CreateXMLBySAX { public void createMySAX(List<Student> students){ try { //创建一个SAX工厂实例向下强转 SAXTransformerFactory factory = (SAXTransformerFactory)SAXTransformerFactory.newInstance(); TransformerHandler handler = factory.newTransformerHandler(); Transformer tran = handler.getTransformer(); //设置转换中实际输出属性 tran.setOutputProperty(OutputKeys.INDENT, "yes"); tran.setOutputProperty(OutputKeys.ENCODING, "gbk"); tran.setOutputProperty(OutputKeys.VERSION, "1.0"); StreamResult result = new StreamResult(new FileOutputStream(new File("Students2.xml"))); handler.setResult(result); //开始生成document handler.startDocument(); AttributesImpl atts = new AttributesImpl(); atts.clear(); //根节点 handler.startElement("", "", "Students", atts); for (Student student : students) { //每次循环之前都要清空属性列表 atts.clear(); handler.startElement("", "", "Student", atts); //添加属性 atts.addAttribute("", "", "java", "", student.getAlivable()); handler.startElement("", "", "name", atts); //为name添加文本 handler.characters(student.getName().toCharArray(), 0, student.getName().length()); handler.endElement("", "", "name"); //这里将属性列表清空 atts.clear(); handler.startElement("", "", "age",atts); handler.characters((student.getAge()+"").toCharArray(), 0, (student.getAge()+"").length()); handler.endElement("", "", "age"); handler.startElement("", "", "fav", atts); handler.characters((student.getFav()+"").toCharArray(), 0, (student.getFav()+"").length()); handler.endElement("", "", "fav"); handler.endElement("", "", "Student"); } handler.endElement("", "", "Students"); handler.endDocument(); } catch (TransformerConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (SAXException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static void main(String[] args) { List<Student> stu = new ArrayList<>(); Student student = new Student("张三", 19, "电影", "中级"); stu.add(student); CreateXMLBySAX createXMLBySAX = new CreateXMLBySAX(); createXMLBySAX.createMySAX(stu); System.out.println("xml生成完毕"); } }
SAX生成xml的代码里面的方法与解析xml用的不是同一个类中的方法,DefaultHandel中的这些方法是重写了父类的这些方法的。
我们这里用的是从父类继承过来的方法。
这里的以start开头的方法相当于xml中的节点头部
这里的以end开头的方法相当于xml中的节点尾部
三、Excel解析
首先声明一下Exlel解析需要用到的jar包
链接:https://pan.baidu.com/s/1MkCRGDLM6NU-bgqcHDGN6A
提取码:s15e
我们需要用到的jar包如下:

想解析一种数据类型我们必须先了解这种数据类型的结构,我们先看一下Excel的结构吧

在这里我们还要明确另一个东西,由于Microsoft公司的office在2007版本之前使用的是xls格式,2007版本及以后版本使用的是xlsx版本
所以我们在解析之前要进行版本的判断。(一般根据后缀名就可以判断版本了)
如果是以xls结尾的则需要使用HSSF如果是xlsx结尾的需要使用XSSF
package com.demo.poi; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import org.apache.poi.hssf.usermodel.HSSFCell; import org.apache.poi.hssf.usermodel.HSSFRow; import org.apache.poi.hssf.usermodel.HSSFSheet; import org.apache.poi.hssf.usermodel.HSSFWorkbook; import org.apache.poi.xssf.usermodel.XSSFCell; import org.apache.poi.xssf.usermodel.XSSFRow; import org.apache.poi.xssf.usermodel.XSSFSheet; import org.apache.poi.xssf.usermodel.XSSFWorkbook; public class ExcelDemo { /** * xlsx文件解析 office2007及以后版本文件格式 * @param filepath */ public static void xlsxparse(String filepath){ try { XSSFWorkbook wb = new XSSFWorkbook(new FileInputStream(filepath)); for (int i = 0;i<wb.getNumberOfSheets();i++) { XSSFSheet sheet = wb.getSheetAt(i); if(sheet!=null){ for(int j=0;j<sheet.getLastRowNum();j++){ XSSFRow row = sheet.getRow(j); if(row!=null){ for(int k = 0;k<row.getLastCellNum();k++){ XSSFCell cell = row.getCell(k); if(cell!=null){ System.out.println(getValue(cell)); } } } } } } } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static void main(String[] args) { //从控制台接受信息 InputStream in = System.in; BufferedReader br = new BufferedReader(new InputStreamReader(in)); String str = null; try { //读取一行输入 str = br.readLine(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } String trim = str.trim(); String[] split = trim.split("\."); System.out.println(split.length); if(split[split.length-1].equals("xls")){ xlsparse(trim); }else if(split[split.length-1].equals("xlsx")){ xlsxparse(trim); } try { br.close(); in.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } //xls转换数据格式 private static String getValue(HSSFCell hssfRow) { if (hssfRow.getCellType() == hssfRow.CELL_TYPE_BOOLEAN) { return String.valueOf(hssfRow.getBooleanCellValue()); } else if (hssfRow.getCellType() == hssfRow.CELL_TYPE_NUMERIC) { return String.valueOf(hssfRow.getNumericCellValue()); } else { return String.valueOf(hssfRow.getStringCellValue()); } } // xlsx转换数据格式 private static String getValue(XSSFCell xssfRow) { if (xssfRow.getCellType() == xssfRow.CELL_TYPE_BOOLEAN) { return String.valueOf(xssfRow.getBooleanCellValue()); } else if (xssfRow.getCellType() == xssfRow.CELL_TYPE_NUMERIC) { return String.valueOf(xssfRow.getNumericCellValue()); } else { return String.valueOf(xssfRow.getStringCellValue()); } } /** * xls文件解析 office2003版本文件格式 * @param filename */ public static void xlsparse(String filename){ try { HSSFWorkbook wb = new HSSFWorkbook(new FileInputStream(filename)); for (int i = 0;i<wb.getNumberOfSheets();i++) { HSSFSheet sheet = wb.getSheetAt(i); if(sheet!=null){ for(int j=0;j<sheet.getLastRowNum();j++){ HSSFRow row = sheet.getRow(j); if(row!=null){ for(int k = 0;k<row.getLastCellNum();k++){ HSSFCell cell = row.getCell(k); if(cell!=null){ System.out.println(getValue(cell)); } } } } } } } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
以上是我学习数据解析的总结,如有错误,よろしくお願いします!