今天的主要活动是完成了实验一Linux系统常用命令
Spark运行基本流程
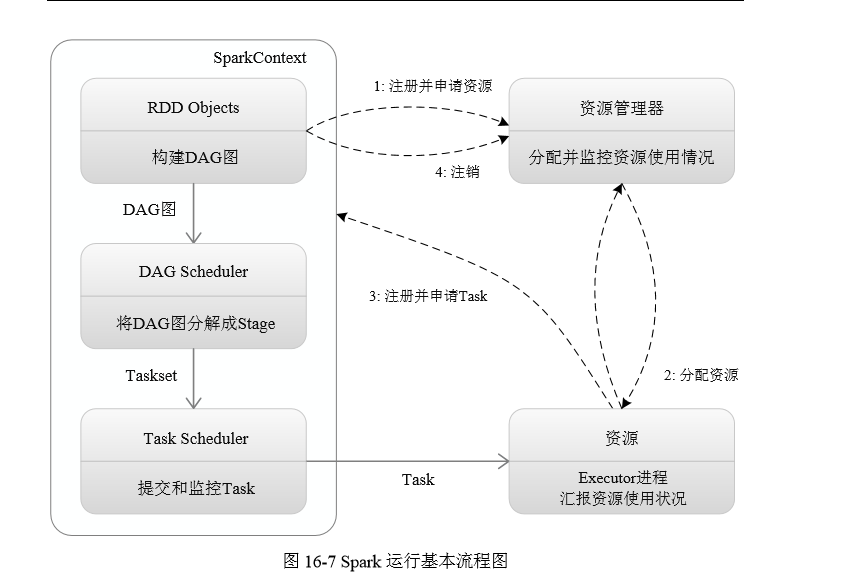
(1)当一个 Spark Application 被提交时,首先需要为这个应用构建起基本的运行环境, 即由 Driver 创建一个 SparkContext进行资源的申请、任务的分配和监控。
SparkContext 会向资源管理器注册并申 请运行 Executor 的资源;
(2)资源管理器为 Executor 分配资源,并启动 Executor 进程,
Executor 启动以后会不断向资源管理器汇报其运行情况
(3)SparkContext 根据 RDD 的依赖关系构建 DAG 图,DAG 图提交给 DAGScheduler 进行解析,将 DAG 图分解成 Stage,并且计算出各个 Stage 之间的依赖关系,(每一个Stage阶段里面都会包含多个task,这些task构成一个taskset)然后把一个个 TaskSet 提交给底层任务调度器 TaskScheduler 进行处理;
(TaskScheduler拿到taskset以后要把任务分配给相关的Executor 进程去运行这些task,但是它不能随便分配 必须接到Executor申请才会分配)
Executor 会向 SparkContext 申请 Task,Task Scheduler将相关Task发送给Executor运行,同时,SparkContext也会将应用程序代码发放给Executor;
(4)Task 在 Executor 上运行,把执行结果反馈给 TaskScheduler,然后反馈给 DAGScheduler,运行完毕后写入数据并释放所有资源。
RDD概念
一个 RDD 就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个 RDD 可分成多个分区,每个分区就是一个数据集片段,并且一个 RDD 的不同分区可以被保存到 集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD 提供了一种高 度受限的共享内存模型,即 RDD 是只读的记录分区的集合,不能直接修改,只能基于稳定 的物理存储中的数据集创建 RDD,或者通过在其他 RDD 上执行确定的转换操作(如 map、 join 和 group by)而创建得到新的 RDD
从输入中逻辑上生成 A 和 C 两个 RDD,经过一系列转换操作,逻辑上生成了 F(也是一个 RDD),之所以说是 逻辑上,是因为这时候计算并没有发生,Spark 只是记录了 RDD 的生成和依赖关系。当 F 要进行输出时,也就是当F进行动作操作的时候,Spark才会根据RDD的依赖关系生成DAG, 并从起点开始真正的计算。
RDD 中不同的操作会使得不同 RDD 中的分区会产生不同的依赖。
RDD 中的依赖关系 分为窄依赖与宽依赖,
窄依赖表现为一个父 RDD 的分区对应于一个子 RDD 的分区,或多个父 RDD 的分区对 应于一个子 RDD 的分区;
宽依赖则表现为存在一个父 RDD 的一个分区对应一个子 RDD 的多个分区。
窄依赖典型的操作包括 map、filter、union 等,宽依赖典型的操作包括 groupByKey、sortByKey 等。对于连接(join)操作,可以分为两种情况,如果连接操作使 用的每个分区仅仅和已知的分区进行连接,就是窄依赖,其他 情况下的连接操作都是宽依赖(如图 16-9(b)中的连接操作)。宽依赖的情形通常伴随着 Shuffle 操作。
Spark划分
通过分析各个 RDD 的依赖关系生成了 DAG,再通过分析各个 RDD 中的分区之 间的依赖关系来决定如何划分 Stage,
具体划分方法是:在 DAG 中进行反向解析,遇到宽 依赖就断开,遇到窄依赖就把当前的RDD加入到Stage中;将窄依赖尽量划分在同一个Stage 中,可以实现流水线计算 提高了计算的效率。
RDD 在 Spark 架构中的运行过程:
(1)创建 RDD 对象;
(2)SparkContext 负责计算 RDD 之间的依赖关系,构建 DAG;
(3)DAGScheduler 负责把 DAG 图分解成多个 Stage,每个 Stage 中包含了多个 Task,每个 Task 会被 TaskScheduler 分发给各个 WorkerNode 上的 Executor 去执行。