补充一个filter中大于小于的用法
models.course_info.objects.filter(id__gte=30).delete()
_exact 精确等于 like 'aaa' __iexact 精确等于 忽略大小写 ilike 'aaa' __contains 包含 like '%aaa%' __icontains 包含 忽略大小写 ilike '%aaa%',但是对于sqlite来说,contains的作用效果等同于icontains。 __gt 大于 __gte 大于等于 __lt 小于 __lte 小于等于 __in 存在于一个list范围内 __startswith 以...开头 __istartswith 以...开头 忽略大小写 __endswith 以...结尾 __iendswith 以...结尾,忽略大小写 __range 在...范围内 __year 日期字段的年份 __month 日期字段的月份 __day 日期字段的日 __isnull=True/False 例子: >> q1 = Entry.objects.filter(headline__startswith="What") >> q2 = q1.exclude(pub_date__gte=datetime.date.today()) >> q3 = q1.filter(pub_date__gte=datetime.date.today()) >>> q = q.filter(pub_date__lte=datetime.date.today()) >>> q = q.exclude(body_text__icontains="food")
这篇博客主要整理一下数据库表的查询,之前也一直没有搞的很清楚
首先我们先构建一个对多的表结构吧,我们搞一个省和市的例子
先看下省表
class pro(models.Model):
pro_name = models.CharField(max_length=64)
def __str__(self):
return self.pro_name
在看下市表
class city(models.Model):
city_name = models.CharField(max_length=64)
city_pro = models.ForeignKey("pro",on_delete=models.CASCADE)
def __str__(self):
return self.city_name
然后我们创建数据,首先要创建省表中的数据,因为市表要关联省表,所以省表必须要先有数据
先构建省表中的数据,通过create方法
s1 = "广州"
s2 = "深圳"
s3 = "东莞"
for i in range(3):
models.pro.objects.create(
pro_name = s1 + str(i)
)
for i in range(3):
models.pro.objects.create(
pro_name = s2 + str(i)
)
for i in range(3):
models.pro.objects.create(
pro_name = s3 + str(i)
)
然后在构建市表的数据
for i in range(3):
pro_name = models.pro.objects.filter(id=1)
print(pro_name[0].pro_name,"--------------------->")
models.city.objects.create(
city_name = s1 + str(i),
city_pro = pro_name[0]
)
for i in range(3):
pro_name = models.pro.objects.filter(id=2)
print(pro_name[0].pro_name,"--------------------->")
models.city.objects.create(
city_name = s2 + str(i),
city_pro = pro_name[0]
)
for i in range(3):
pro_name = models.pro.objects.filter(id=3)
print(pro_name[0].pro_name,"--------------------->")
models.city.objects.create(
city_name = s3 + str(i),
city_pro = pro_name[0]
)
市表关联省表的时候要十分注意,下面这段代码返回的是一个对象的列表,我们需要通过列表的索引来获取我们要的值
pro_name = models.pro.objects.filter(id=1)
city_pro = pro_name[0]
这样我们就创建好了省表和市表,且把数据也初始化ok了
省表
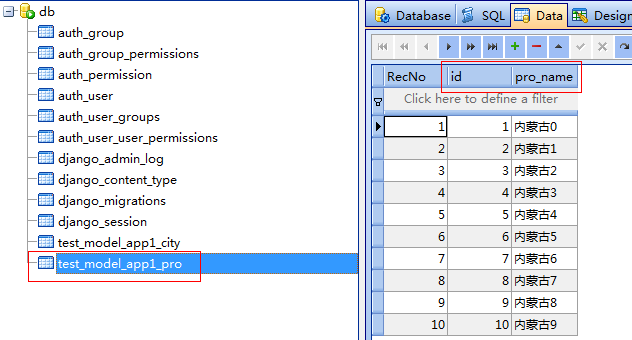
市表
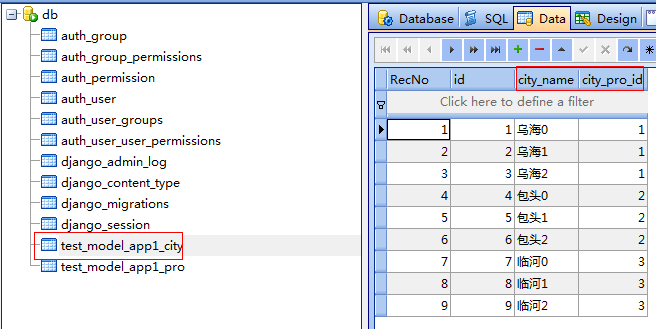
做好准备工作后,我们就可以开始练习查询了
一、先说下单表查询
1、查询所有的数据,用all方法
res = models.pro.objects.all()
for i in res:
print(i)
2、使用filter方法过滤,filter方法
res = models.city.objects.filter(id=2)
print(res[0].city_pro)
3、查看某个对象是否存在,exists方法
print(models.city.objects.filter(id=2).exists())
4、统计数量,使用count方法
print(models.city.objects.filter(id=2).count())
5、查看第一个对象和最后一个对象
res = models.city.objects.all().first()
print(res)
print(models.city.objects.first())
print(models.city.objects.last())
6、也可以传递一个字典进去
dict_city = {"id":1,"city_name":"乌海0"}
print(models.city.objects.filter(**dict_city).exists())
二、然后说一下一对多的查询
首先看下表的字段
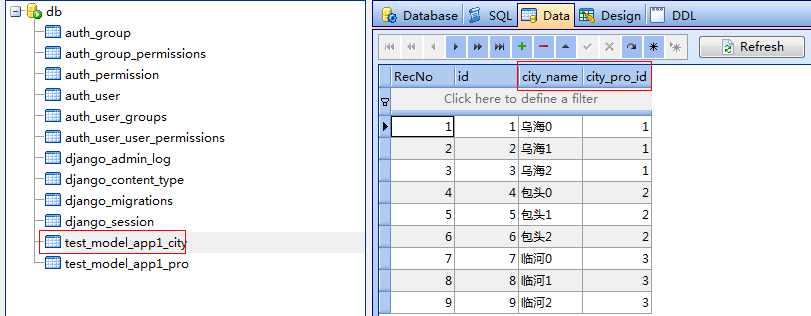

1、先看正向查询,从有外键的表开始查询,这里要用到两个下划线的方法,由django为我们做跨表查询
先看all方法,all方法返回的是一个对象
res = models.city.objects.all()
print(res[0].city_pro)
print(res[1].city_pro)
结果
内蒙古0 内蒙古0
在values方法,返回的是一个字典,因为我们是通过city_pro字段去关联其他表,city_pro__pro_name,去查询其他的表的指定字段,记住这里是两个下划线,这里的filter中的字段可以city这个表的字段,也可以使用pro这个表的字段,但是如果是pro这个表的字段,则就需要使用两个下划线的功能
res = models.city.objects.filter(city_pro__id=3).values("id","city_name","city_pro","city_pro__pro_name","city_pro__id")
for i in res:
print(i)
结果
{'id': 7, 'city_name': '临河0', 'city_pro': 3, 'city_pro__pro_name': '内蒙古2', 'city_pro__id': 3}
{'id': 8, 'city_name': '临河1', 'city_pro': 3, 'city_pro__pro_name': '内蒙古2', 'city_pro__id': 3}
{'id': 9, 'city_name': '临河2', 'city_pro': 3, 'city_pro__pro_name': '内蒙古2', 'city_pro__id': 3}
上面可以使用filter也可以使用all
res = models.city.objects.all().values("id","city_name","city_pro","city_pro__pro_name","city_pro__id")
for i in res:
print(i)
结果
{'id': 1, 'city_name': '乌海0', 'city_pro': 1, 'city_pro__pro_name': '内蒙古0', 'city_pro__id': 1}
{'id': 2, 'city_name': '乌海1', 'city_pro': 1, 'city_pro__pro_name': '内蒙古0', 'city_pro__id': 1}
{'id': 3, 'city_name': '乌海2', 'city_pro': 1, 'city_pro__pro_name': '内蒙古0', 'city_pro__id': 1}
{'id': 4, 'city_name': '包头0', 'city_pro': 2, 'city_pro__pro_name': '内蒙古1', 'city_pro__id': 2}
{'id': 5, 'city_name': '包头1', 'city_pro': 2, 'city_pro__pro_name': '内蒙古1', 'city_pro__id': 2}
{'id': 6, 'city_name': '包头2', 'city_pro': 2, 'city_pro__pro_name': '内蒙古1', 'city_pro__id': 2}
{'id': 7, 'city_name': '临河0', 'city_pro': 3, 'city_pro__pro_name': '内蒙古2', 'city_pro__id': 3}
{'id': 8, 'city_name': '临河1', 'city_pro': 3, 'city_pro__pro_name': '内蒙古2', 'city_pro__id': 3}
{'id': 9, 'city_name': '临河2', 'city_pro': 3, 'city_pro__pro_name': '内蒙古2', 'city_pro__id': 3}
也可以使用values_list方法,返回的是一个列表
res = models.city.objects.all().values_list("id","city_name","city_pro","city_pro__pro_name")
for i in res:
print(i)
结果
(1, '乌海0', 1, '内蒙古0') (2, '乌海1', 1, '内蒙古0') (3, '乌海2', 1, '内蒙古0') (4, '包头0', 2, '内蒙古1') (5, '包头1', 2, '内蒙古1') (6, '包头2', 2, '内蒙古1') (7, '临河0', 3, '内蒙古2') (8, '临河1', 3, '内蒙古2') (9, '临河2', 3, '内蒙古2')
2、然后看下反向查询,通过没有外键的表查询,这里我们要用set方法和两个下划线的方法
方法1
获取所有的省
res = models.pro.objects.all()
获取第一个省
temp = res[0]
获取第一个省下的所有的市,用city_set方法
print(temp.city_set.all())
结果
<QuerySet [<city: 乌海0>, <city: 乌海1>, <city: 乌海2>]>
方法2
res = models.pro.objects.filter(id=3).first()
print(res.city_set.all())
结果
<QuerySet [<city: 临河0>, <city: 临河1>, <city: 临河2>]>
通过反向查找也可以使用values方法,但是其中的字段是下面这样的,values中的字段都是多表中的字段,但是如果要查询一表中的字段,也需要通过多表中的外键关联的字段加上两个下划线进行查询
city_list = models.pro.objects.get(id=1).city_set.values("city_pro","city_name","city_pro_id","id","city_pro__pro_name")
结果
{'city_pro': 1, 'city_name': '乌海0', 'city_pro_id': 1, 'id': 1, 'city_pro__pro_name': '内蒙古0'}
{'city_pro': 1, 'city_name': '乌海1', 'city_pro_id': 1, 'id': 2, 'city_pro__pro_name': '内蒙古0'}
{'city_pro': 1, 'city_name': '乌海2', 'city_pro_id': 1, 'id': 3, 'city_pro__pro_name': '内蒙古0'}
三、最后说一下多对多的查询
首先看下第三张表由django默认创建的场景
我们举一个这样的例子,书和作者的例子,一个书可以多个作者,一个作者也可以写多个书,所以书和作者就是一个多对多的关系
先在models中创建书这个表的对象
class Book(models.Model):
book_name = models.CharField(max_length=64)
def __str__(self):
return self.book_name
然后在models中创建作者这个表的对象
class Auther(models.Model):
auther_name = models.CharField(max_length=64)
auther_book = models.ManyToManyField("Book")
def __str__(self):
return self.auther_name
我们这里注意到,只在作者这个表中有manyToManyField。我们在创建作者这个表的时候可以完全不关注auther_book这个字段,我们在创建书这个表的时候也可以完全不关注作者
这个字段,我们可以在后面为两张表创建关联关系
我们现在后台给书这个表写了一些数据,数据如下

我们写一个前端的代码,实现的效果就是注册一个作者,然后可以选择你哪些书
前端代码如下
<form action="/app1/many_to_many_func/" method="post">
<p>
名字:<input type="text" name="new_add_name">
</p>
<h1>请选择你的学校</h1>
<select name="new_add_book" multiple="multiple">
{% for i in book_list %}
<option value ={{ i.id }}>
{{ i.book_name }}
</option>
{% endfor %}
</select>
<p><input type="submit" value="submit提交"></p>
</form>
django后端接受数据的代码
def many_to_many_func(request):
if request.method.lower() == "get":
book_list_temp = models.Book.objects.all()
return render(request, "test1.html", {"book_list": book_list_temp})
else:
auther_name = request.POST.get("new_add_name")
# 获取前段发来的作者的名称
book_list = request.POST.getlist("new_add_book")
# 获取前端发来的书的列表,这里要通过getlist方法来获取
models.Auther.objects.create(
auther_name = auther_name
)
# 先为作者的数据库写入数据
auther_name_obj = models.Auther.objects.filter(auther_name = auther_name).first()
# 在数据库中获取这个作者的对象
auther_name_obj.auther_book.add(*book_list)
# 通过add方法为这个作者添加多对多的映射
return HttpResponse("hahah")
book_list_temp = models.Book.objects.all()
return render(request, "test1.html", {"book_list": book_list_temp})
删除某个映射关系
del_auther_obj = models.Auther.objects.filter(auther_name="zhouyongbo").first()
del_auther_obj.auther_book.remove(14)
更新某个映射关系,记住,这里要传递一个可迭代的对象
del_auther_obj = models.Auther.objects.filter(auther_name="zhouyongbo").first()
# del_auther_obj.auther_book.remove(14)
del_auther_obj.auther_book.set([18,14])
清空某个映射关系,记住,只要传递一个可迭代的对象
del_auther_obj = models.Auther.objects.filter(auther_name="zhouyongbo").first()
# del_auther_obj.auther_book.remove(14)
# del_auther_obj.auther_book.set([18,14])
del_auther_obj.auther_book.clear()
上面讲的正向操作,反向操作按照下面方法在试一下
# 反向操作
# obj = models.Book.objects.get(id=1)
# obj.author_set.add(1)
# obj.author_set.add(1,2,3,4)
# ...
下面我们在来看下下第三种表由我们自己创建的情况
自己创建第三张表:
class Book(models.Model):
name = ..
class Author(models.Model):
name = ..
class A_to_B(models):
bid = ForeignKey(Book)
aid = ForeignKey(Author)
class Meta
uniqe_together = (
'bid','nid'
)
class Meta
uniqe_together = (
('bid1','nid1'),
('bid2','nid2'),
('bid3','nid3'),
)