前言: 朋友知道我是学安全的(辣鸡一个),他写了一个网站,想让我日一下,看有什么漏洞吗?( ̄▽ ̄)"当时就想这个傻冒写的东西肯定很好日,所以当时就想到了用sqlmap跑一下,看能不能把它的裤子给脱了。但是跑完之后。。。。。。。。什么了没有。然后我静下心一下怎么没有注入点呢?或者看一下他的网站有没有子域名。所以就想到了看能不能写一个子域名枚举的脚本。所以就写了下面的脚本。下面是程序的流程图。有必要说一下为什么这里选择使用bing 而没有使用baidu。因为bing在搜索的过程中url更好构造,而百度的相对难构造一点。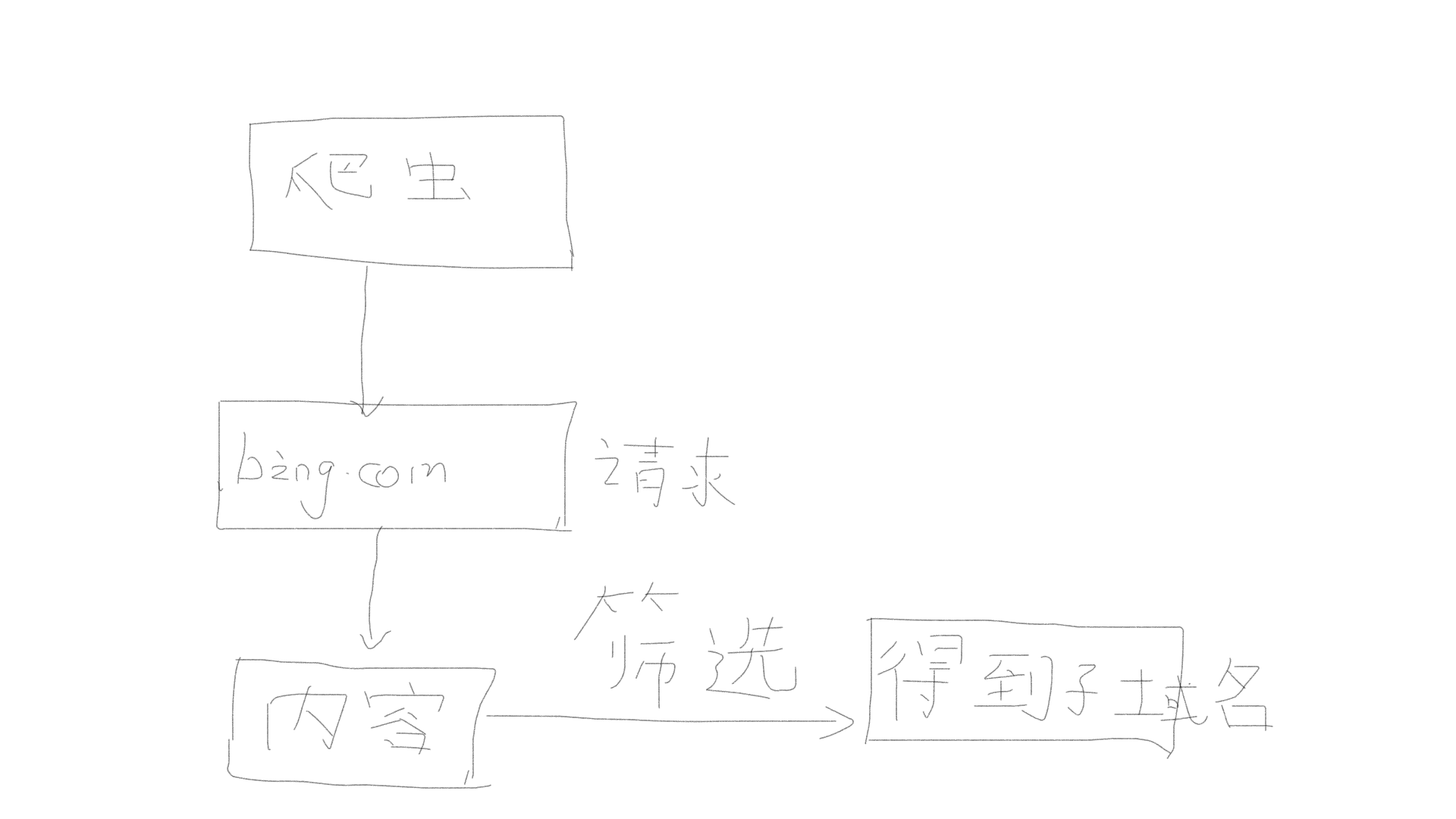
此脚本需要的一些库,如果没有的话需要安装一下。
import requests
import re
import requests
from bs4 import BeautifulSoup
import lxml
我们还要用到Google的搜索语法,下面我总结了一些最常见的语法:
site:freeitjc.com 搜索站点及其host或url 例:site:qq.com搜索引擎会将qq.com的所有子域名罗列出来 今天我们主要用到的就是这个
inurl:在url中是否存在该关键字 例 inur:asp?id= 这时候搜索引擎会将所有带有asp?id=的url罗列出来
intext:搜索网页正文内容 例: intext:中国 搜索引擎会将所有网页内容中有中国的uel罗列出来
intitle:在网页标题中搜索关键字 intitle:PRC 搜索引擎会将所有标题带有PRC的url罗列出来
filetype:获取目标的文件类型。如:filetype:doc|bak|mdb|inc 将返回所有以doc,bak,mdb,inc结尾的文件URL 例如 filetype:doc 这时候展现的全部是以.doc结尾的url
link:返回所有与目标url做了链接的url。如搜索:link:www.freeitjc.com可以返回所有和www.freeitjc.com有链接的url
cache:搜索google里关于某些内容的缓存。
下面呢就是脚本的源码:
# -- coding: utf-8 -- #!/usr/bin/python3 import requests import re import requests from bs4 import BeautifulSoup import lxml header={ 'User_Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0' } def getSonDomains(domain): temp ='www'+domain fileName = domain+'子域名信息'+'.txt' f = open(fileName,'w+') print('成功创建'+fileName) for i in range(1000): index1 = i * 10 + 8 if i ==1: url = 'https://cn.bing.com/search?q=site%3a{domain}&qs=n&sp=-1&pq=site%3a{domain}&sc=0-6&sk=&cvid=1D4ED39374994EFC9F3948071CC07465&first={index}&FORM=PERE'.format(index=1,domain=domain) else: url = 'https://cn.bing.com/search?q=site%3a{domain}&qs=n&sp=-1&pq=site%3a{domain}&sc=0-6&sk=&cvid=1D4ED39374994EFC9F3948071CC07465&first={index}&FORM=PERE'.format(index=index1,domain=domain) response = requests.get(url,headers=header) html = response.content soup = BeautifulSoup(html,"lxml") #利用BeautifulSuop直接可以获得某个标签下面的内容 urls = soup.find_all('cite') for i in urls: if i.contents[0][:5] =='https': #由于会出现类似与www.https://item.qq.com这种域名所以要判断i.contents[0][:5]是否是https sonDomain = '{pre}{domain}'.format(pre=i.contents[0],domain=domain) sonDomain = 'www.{pre}{domain}'.format(pre=i.contents[0],domain=domain) if sonDomain != temp: temp = sonDomain print(temp) f.write(temp) f.write('\n') f.close() if __name__=='__main__': domain = input('请输入您想查询的母域名:') getSonDomains(domain)
附上程序运行图