文章转自:https://zhuanlan.zhihu.com/p/154356033侵删
字典合并
一个非常优雅的特性,当我们想将两个字典进行合并时,只需要使用操作符“|”:
a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}
c = a | b
print(c)
输出结果:
[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
不仅如此,我们还可以使用合并更新操作符“|=”直接对原始字典进行更新:
a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}
a |= b
print(a)
输出结果:
[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
这里需要注意的是,如果两个字典都包含相同的Key,运算结果将直接采用第二个字典的键值对:
a = {1: 'a', 2: 'b', 3: 'c', 6: 'in both'}
b = {4: 'd', 5: 'e', 6: 'but different'}
print(a | b)
输出结果:
[Out]: {1: 'a', 2: 'b', 3: 'c', 6: 'but different', 4: 'd', 5: 'e'}
可迭代对象的字典更新
“|=”操作符还具有另一个非常棒的功能,就是使用一个可迭代对象的键值对更新字典:
a = {'a': 'one', 'b': 'two'}
b = ((i, i**2) for i in range(3))
a |= b
print(a)
输出结果:
[Out]: {'a': 'one', 'b': 'two', 0: 0, 1: 1, 2: 4}
这里需要注意的是,如果你使用标准的合并操作符“|”来取代上面的“|=”操作服,这会直接导致TypeError。
TypeError:unsupported opprand type(s) for |:'dict' and 'generator'
类型提示
Python作为动态类型的编程语言,这意味着在使用中我们并不需要给变量指定数据类型。然而虽然可以这样做,但是这让我们在维护代码时常常感到困惑,并且灵活性也成了缺点。
在3.5版本后,虽然我们可以指定数据类型了,但是使用起来仍然非常麻烦。这次新版本就对此进行了更新:没有类型提示vs有类型提示
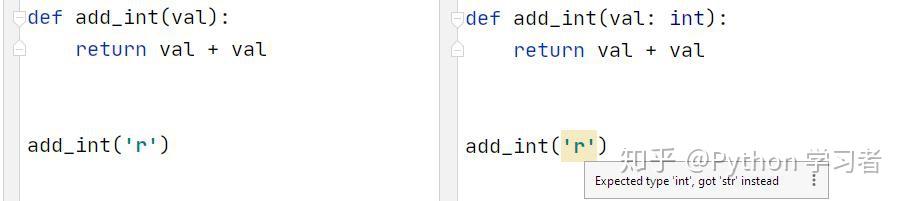
上图中我们想通过add_int函数将两个相同的数字想加到一起,然而编译器并没有很好的理解我们的意图,由于两个字符串也可以使用+进行连接,所以这里并没有给出警告。
现在当我们可以指定函数的参数类型时,在参数类型为int时,编译器就能够立即识别上述的问题。
新增字符串函数
虽然字符串函数没有其他新特性那么强大,但字符串作为开发中使用最频繁的数据类型,这里也需要提一下他的改变。新版本中添加了移除前缀和后缀的两个字符串函数:
"Hello world".removeprefix("He")
Hello world".removesuffix("ld")
输出结果:
[Out]: "llo world"
[Out]: "Hello wor"
新的解析器
为一个普通的开发者,语法解析器的变化可能不易被察觉,但它的变化有可能成为Python演变中的一个重要转折点。
我们所知,目前Python主要是用的是一种基于LL(1)的语法,这种语法可以通过LL(1)解析器进行解析,该解析器从上到下、从左到右地解析代码,只需要从词法分析器中取出一个 token 就可以正确地解析下去。
然而LL(1) 存在的一些问题:
- Python 中包含非 LL(1) 语法,正因如此,当前语法采用了一些曲线救国的办法,带来了很多不必要的复杂性。
- LL(1) 给 Python 语法造成了很多限制。某个相关话题提到了下面代码无法用当前的解析器进行解析(会造成 SyntaxError)。
with (open("a_really_long_foo") as foo,
open("a_really_long_bar") as bar):
pass
- LL(1) 不能处理左递归。特定的递归语法意味着解析树时可能出现无限循环。Python 的缔造者 Guido van Rossum 在这篇文章[1]中给出了解释。
毫无疑问,这些因素以及更多无法理解的其他问题影响着Python的发展,而新版本的解析器是基于PEG,它将给 Python 开发者提供更大的灵活性,从 Python 3.10开始我们将能够感受到这一点。
到这里 Python 3.9的版本几个重要的特性就讲解完毕,我们已经迫不及待的希望正式版的到来。