前情提要:
今天继续学习Django 的内容, 今天主要和渲染相关
1>配置路由
>2:写函数
>3 指向url
一:路由层
1:配置静态支持文件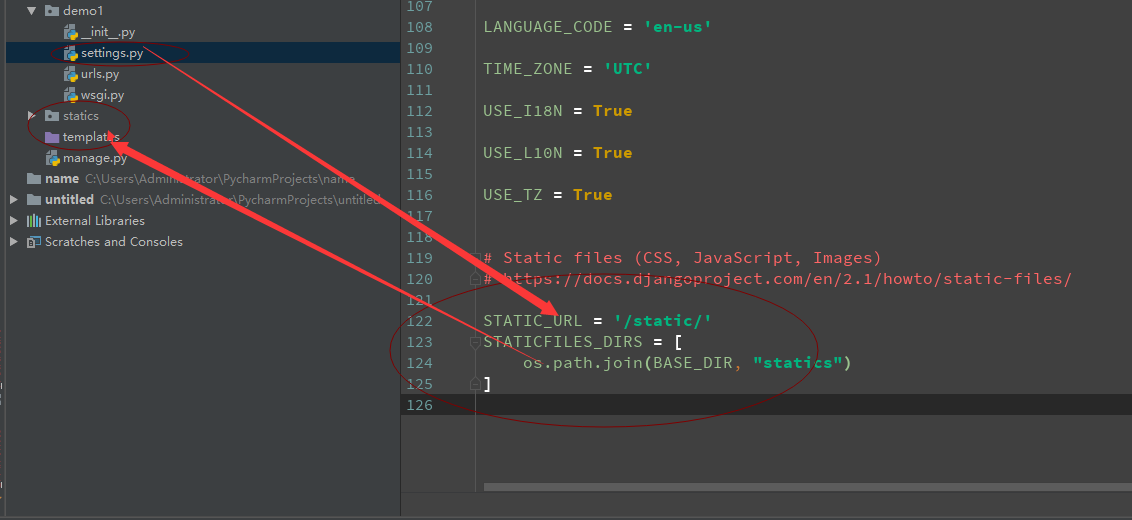
1:路由层的简单配置
>django 1 版本


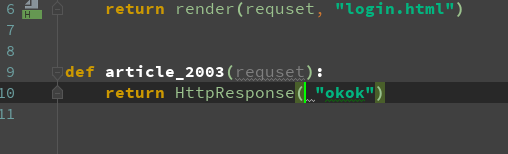
>django 2 版本
用path
2:无名分组

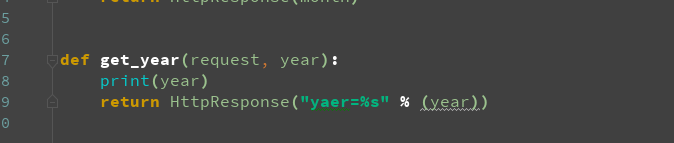
注意:
-
-
- 若要从URL 中捕获一个值,只需要在它周围放置一对圆括号。
- 不需要添加一个前导的反斜杠,因为每个URL 都有。例如,应该是
^articles而不是^/articles。 - 每个正则表达式前面的'r' 是可选的但是建议加上。它告诉Python 这个字符串是“原始的” —— 字符串中任何字符都不应该转义
-
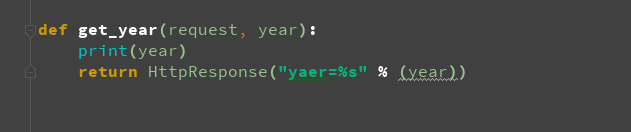
3:有名分组
上面的示例使用简单的、没有命名的正则表达式组(通过圆括号)来捕获URL 中的值并以位置 参数传递给视图。在更高级的用法中,可以使用命名的正则表达式组来捕获URL 中的值并以关键字 参数传递给视图。
在Python 正则表达式中,命名正则表达式组的语法是(?P<name>pattern),其中name 是组的名称,pattern 是要匹配的模式。
下面是以上URLconf 使用命名组的重写:

urlpatterns = [
path('admin/', admin.site.urls),
path('articles/2003/', views.special_case_2003),
re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive),
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]+)/$', views.article_detail),
]
这个实现与前面的示例完全相同,只有一个细微的差别:捕获的值作为关键字参数而不是位置参数传递给视图函数。例如:
/articles/2005/03/ 请求将调用views.month_archive(request, year='2005', month='03')函数,而不是views.month_archive(request, '2005', '03')。 /articles/2003/03/03/ 请求将调用函数views.article_detail(request, year='2003', month='03', day='03')。
在实际应用中,这意味你的URLconf 会更加明晰且不容易产生参数顺序问题的错误 —— 你可以在你的视图函数定义中重新安排参数的顺序。当然,这些好处是以简洁为代价。
>>路由
// path 会和当前ip自动拼接 故 不需要写前面的 /

>>视图
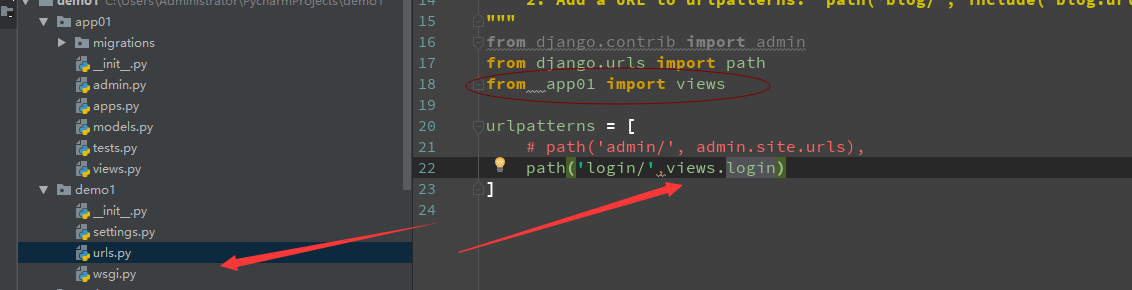
4: 路由分发:
>b1:在对应的app中创建urls ;该导的包都导入
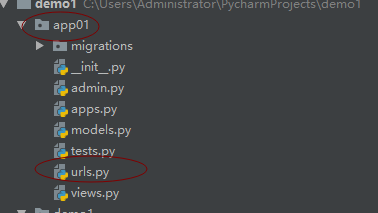
>b2:在新创建的urls 中写 路由规则 ,反射的views
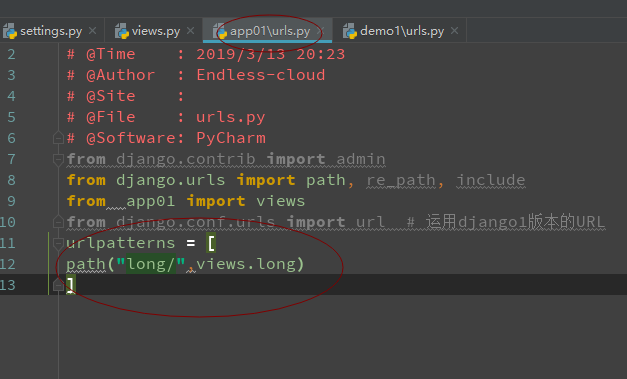
>b3 在根目录的urls 中设置分发路由

>b4 设置对应app中的view 视图函数
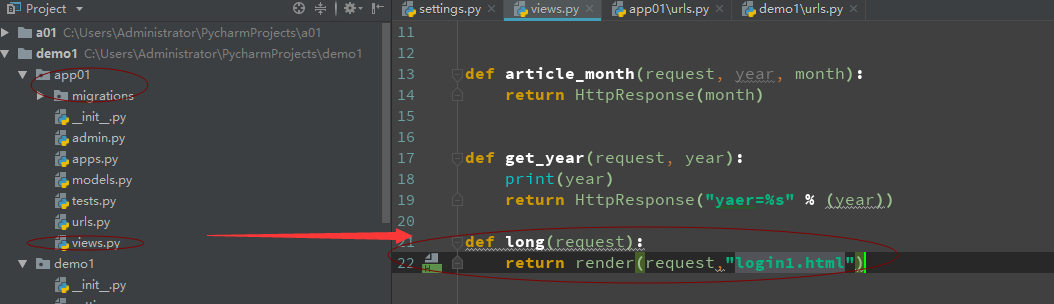
-
简单使用
-
项目最顶级的URL配置
from django.conf.urls import url # 运用django1版本的URL
from django.urls import path, re_path, include
urlpatterns = [
url(r'^app01/', include("app01.urls")),
url(r'^app02/', include("app02.urls"))
] -
每个APP应用里面新建urls.py文件
from django.conf.urls import url
from app01 import views
urlpatterns = [
url(r'^login/$', views.login)
]注意事项:
-
项目顶级URL,结尾不要加$;
-
include参数字符串路径,必须要写正确。
-
-
-
URL、path、re_path区别:
-
URL
-
自己定制匹配规则
-
path
-
自动带开头和结尾匹配规则
-
include,自动去掉后面的$,进行URL拼接
-
-
-
-
-
re_path
-
等同于django1版本的URL。
-
二:视图层
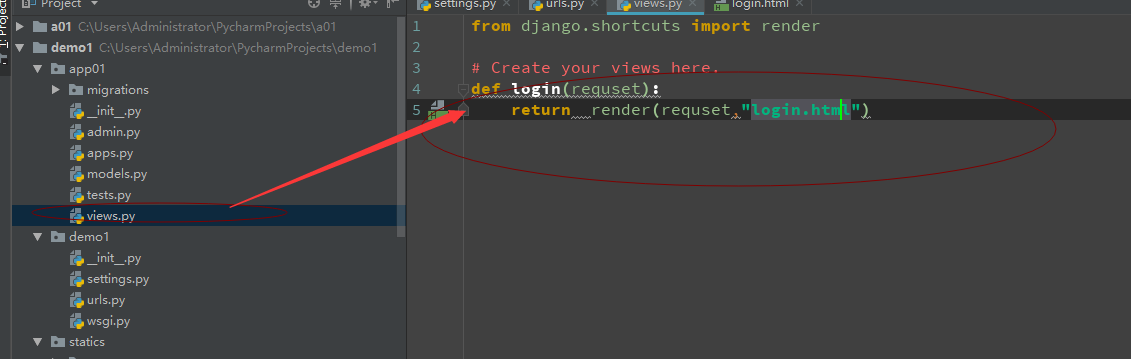
一个视图函数,简称视图,是一个简单的Python 函数,它接受Web请求并且返回Web响应。响应可以是一张网页的HTML内容,一个重定向,一个404错误,一个XML文档,或者一张图片. . . 是任何东西都可以。无论视图本身包含什么逻辑,都要返回响应。代码写在哪里也无所谓,只要它在你的Python目录下面。除此之外没有更多的要求了——可以说“没有什么神奇的地方”。为了将代码放在某处,约定是将视图放置在项目或应用程序目录中的名为views.py的文件中。
1 :request 对象
>1 request 属性
>>1:request.GET #注意大写
!!>B1 :
$1.首先html 中的表单要求是 get
$2.表单中需要有对应的name 属性

!!>B2:写路由
!!>B3:对应视图通过字典的方式获取key 对应的value
#>1 :推荐写法
request.GET.get("key") #
request.GET.getlist("key") #适用于多个值时 ,返回的是list
#>2 : 不推荐写法
request.GET["key"]


>>2:requset.POST #注意大写
!!>B1:
$1:表单要求是madth 为post
$2:表单是有对应的name 属性内容


>>3:requset.body #获取请求的原生字节


>>4:request.path #获取请求的地址



>>5: request.macth # 返回请求方式


#>1:可以利用此性质进行分流
判断返回 get 还是post


print(request.method) # 大写的请求方式 if request.method == "GET": print(request.path) print(request.get_full_path()) print("is_ajax", request.is_ajax()) return render(request, "login1.html") else: # print(request.POST.getlist('user'), type(request.POST.getlist('user'))) print(request.POST['user']) "aV50CvRQZV6mE6Ia9itYxX2qBSm1XRLQE1uSAL9soOERSuxs8KrssZv9E2sPEWzH" print(request.POST.get("csrfmiddlewaretoken")) return HttpResponse("<h2>登陆成功!</h2>") # return redirect("http://jandan.net/ooxx/page-56#comments") # return redirect("/test/")
>2 requset 方法
-
-
is_ajax() # 返回布尔值,判断当前请求是否是ajax。
1、HttpRequest对象
a、request属性
django将请求报文中的请求行、首部信息、内容主体封装成 HttpRequest 类中的属性。 除了特殊说明的之外,其他均为只读的。
/*
1.HttpRequest.GET
一个类似于字典的对象,包含 HTTP GET 的所有参数。详情请参考 QueryDict 对象。
2.HttpRequest.POST
一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成 QueryDict 对象。
POST 请求可以带有空的 POST 字典 —— 如果通过 HTTP POST 方法发送一个表单,但是表单中没有任何的数据,QueryDict 对象依然会被创建。
因此,不应该使用 if request.POST 来检查使用的是否是POST 方法;应该使用 if request.method == "POST"
另外:如果使用 POST 上传文件的话,文件信息将包含在 FILES 属性中。
注意:键值对的值是多个的时候,比如checkbox类型的input标签,select标签,需要用:
request.POST.getlist("hobby")
3.HttpRequest.body
一个字符串,代表请求报文的主体。在处理非 HTTP 形式的报文时非常有用,例如:二进制图片、XML,Json等。
但是,如果要处理表单数据的时候,推荐还是使用 HttpRequest.POST 。
4.HttpRequest.path
一个字符串,表示请求的路径组件(不含域名)。
例如:"/music/bands/the_beatles/"
5.HttpRequest.method
一个字符串,表示请求使用的HTTP 方法。必须使用大写。
例如:"GET"、"POST"
6.HttpRequest.encoding
一个字符串,表示提交的数据的编码方式(如果为 None 则表示使用 DEFAULT_CHARSET 的设置,默认为 'utf-8')。
这个属性是可写的,你可以修改它来修改访问表单数据使用的编码。
接下来对属性的任何访问(例如从 GET 或 POST 中读取数据)将使用新的 encoding 值。
如果你知道表单数据的编码不是 DEFAULT_CHARSET ,则使用它。
7.HttpRequest.META
一个标准的Python 字典,包含所有的HTTP 首部。具体的头部信息取决于客户端和服务器,下面是一些示例:
CONTENT_LENGTH —— 请求的正文的长度(是一个字符串)。
CONTENT_TYPE —— 请求的正文的MIME 类型。
HTTP_ACCEPT —— 响应可接收的Content-Type。
HTTP_ACCEPT_ENCODING —— 响应可接收的编码。
HTTP_ACCEPT_LANGUAGE —— 响应可接收的语言。
HTTP_HOST —— 客服端发送的HTTP Host 头部。
HTTP_REFERER —— Referring 页面。
HTTP_USER_AGENT —— 客户端的user-agent 字符串。
QUERY_STRING —— 单个字符串形式的查询字符串(未解析过的形式)。
REMOTE_ADDR —— 客户端的IP 地址。
REMOTE_HOST —— 客户端的主机名。
REMOTE_USER —— 服务器认证后的用户。
REQUEST_METHOD —— 一个字符串,例如"GET" 或"POST"。
SERVER_NAME —— 服务器的主机名。
SERVER_PORT —— 服务器的端口(是一个字符串)。
从上面可以看到,除 CONTENT_LENGTH 和 CONTENT_TYPE 之外,请求中的任何 HTTP 首部转换为 META 的键时,
都会将所有字母大写并将连接符替换为下划线最后加上 HTTP_ 前缀。
所以,一个叫做 X-Bender 的头部将转换成 META 中的 HTTP_X_BENDER 键。
8.HttpRequest.FILES
一个类似于字典的对象,包含所有的上传文件信息。
FILES 中的每个键为<input type="file" name="" /> 中的name,值则为对应的数据。
注意,FILES 只有在请求的方法为POST 且提交的<form> 带有enctype="multipart/form-data" 的情况下才会
包含数据。否则,FILES 将为一个空的类似于字典的对象。
9.HttpRequest.COOKIES
一个标准的Python 字典,包含所有的cookie。键和值都为字符串。
10.HttpRequest.session
一个既可读又可写的类似于字典的对象,表示当前的会话。只有当Django 启用会话的支持时才可用。
完整的细节参见会话的文档。
11.HttpRequest.user(用户认证组件下使用)
一个 AUTH_USER_MODEL 类型的对象,表示当前登录的用户。
如果用户当前没有登录,user 将设置为 django.contrib.auth.models.AnonymousUser 的一个实例。你可以通过 is_authenticated() 区分它们。
例如:
if request.user.is_authenticated():
# Do something for logged-in users.
else:
# Do something for anonymous users.
user 只有当Django 启用 AuthenticationMiddleware 中间件时才可用。
-------------------------------------------------------------------------------------
匿名用户
class models.AnonymousUser
django.contrib.auth.models.AnonymousUser 类实现了django.contrib.auth.models.User 接口,但具有下面几个不同点:
id 永远为None。
username 永远为空字符串。
get_username() 永远返回空字符串。
is_staff 和 is_superuser 永远为False。
is_active 永远为 False。
groups 和 user_permissions 永远为空。
is_anonymous() 返回True 而不是False。
is_authenticated() 返回False 而不是True。
set_password()、check_password()、save() 和delete() 引发 NotImplementedError。
New in Django 1.8:
新增 AnonymousUser.get_username() 以更好地模拟 django.contrib.auth.models.User。
*/
b、request常用方法
/*
1.HttpRequest.get_full_path()
返回 path,如果可以将加上查询字符串。
例如:"/music/bands/the_beatles/?print=true"
2.HttpRequest.is_ajax()
如果请求是通过XMLHttpRequest 发起的,则返回True,方法是检查 HTTP_X_REQUESTED_WITH 相应的首部是否是字符串'XMLHttpRequest'。
大部分现代的 JavaScript 库都会发送这个头部。如果你编写自己的 XMLHttpRequest 调用(在浏览器端),你必须手工设置这个值来让 is_ajax() 可以工作。
如果一个响应需要根据请求是否是通过AJAX 发起的,并且你正在使用某种形式的缓存例如Django 的 cache middleware,
你应该使用 vary_on_headers('HTTP_X_REQUESTED_WITH') 装饰你的视图以让响应能够正确地缓存。
*/
2、HttpResponse对象
响应对象主要有三种形式(响应三剑客):
-
-
- HttpResponse()
- render()
- redirect()
-
HttpResponse()括号内直接跟一个具体的字符串作为响应体,比较直接很简单,所以这里主要介绍后面两种形式。
a、render方法
render(request, template_name[, context])
结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的 HttpResponse 对象。
参数: request: 用于生成响应的请求对象。 template_name:要使用的模板的完整名称,可选的参数 context:添加到模板上下文的一个字典。默认是一个空字典。如果字典中的某个值是可调用的,视图将在渲染模板之前调用它。
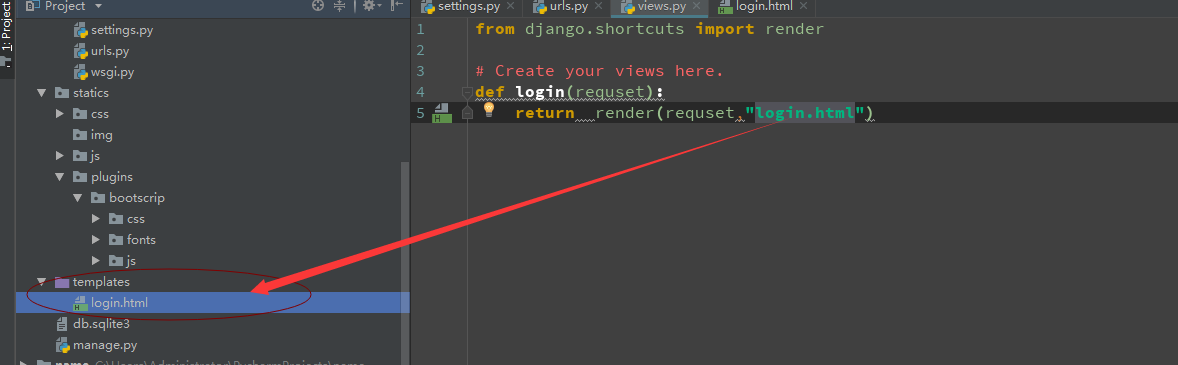
render方法就是将一个模板页面中的模板语法进行渲染,最终渲染成一个html页面作为响应体。
b、redirect方法
传递要重定向的一个硬编码的URL
|
1
2
3
|
def my_view(request): ... return redirect('/some/url/') |
也可以是一个完整的URL
|
1
2
3
|
def my_view(request): ... return redirect('http://example.com/') |
ps:两次请求
对应的html 的action 中可以 写 / 模板 名字 /
三:模板层
1:变量
语法:{{name}}
>1 :模板层 操作
用{{ "内容" }} 在html 中表示 ,对应视图层中的 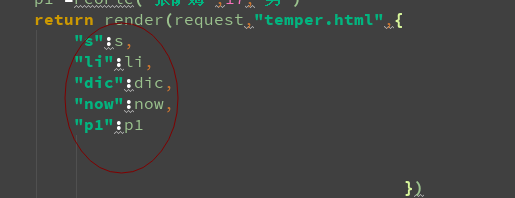
的 内容, 注意 视图层中的 "key" 要和 html 中的 {{"key"}}
注意: 调用方式是 . 的方式调用 属性和方法
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <p>{{s}}</p><br> <p>{{li}}</p><hr> <p>{{li.0}}</p><hr> <p>{{dic}}</p> <p>{{dic.user}}</p> <hr> <p>{{p1.name}}</p> <hr> <p>{{p1.age}}</p> <hr> <p>{{p1.sex}}</p> <hr> <p>{{p1.sing}}</p> </body> </html>
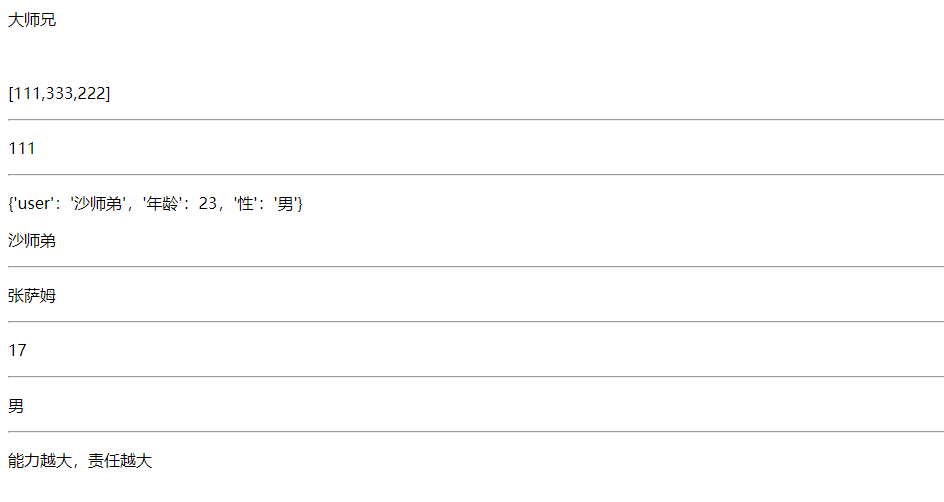
>2:视图层 操作
定义变量常量
可以内容是字符创类型,数字,类,函数等
返回的三个参数 :
1:request 请求
2:对应得html 模板
3:字典 {"key":"value"}
key ---> 对应模板层 的{{key}}
value --->对应上面的变量
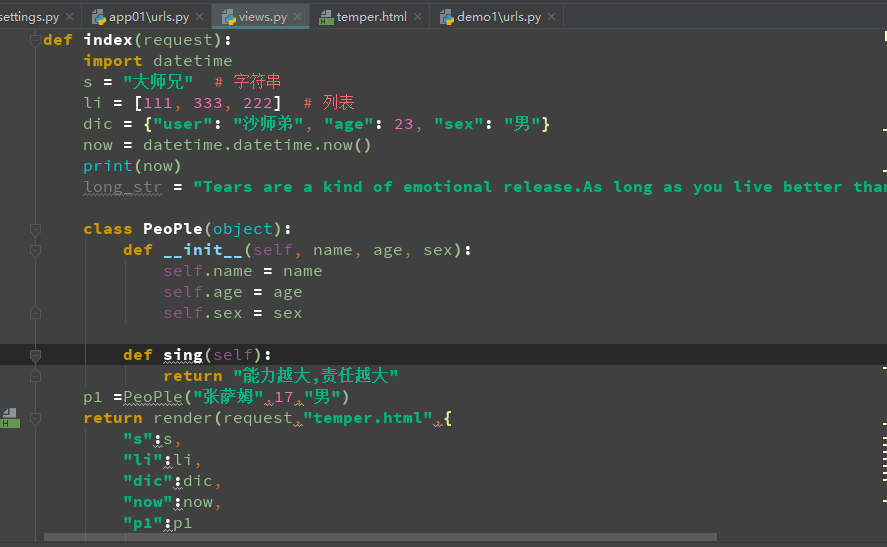
>3 : 路由层操作:
.. 正常配置路由

四: 过滤器和标签
1:过滤器 # 过滤器是在 模板层操作 ,即 写在html 中
>1:{{obj|filter__name:param}}


>2: {{ value|length }}

>3:{{ value|filesizeformat }}
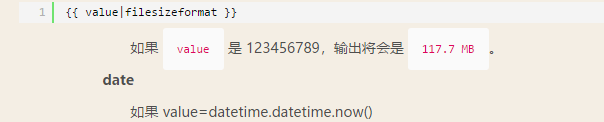
>4:{{ value|date:"Y-m-d" }}

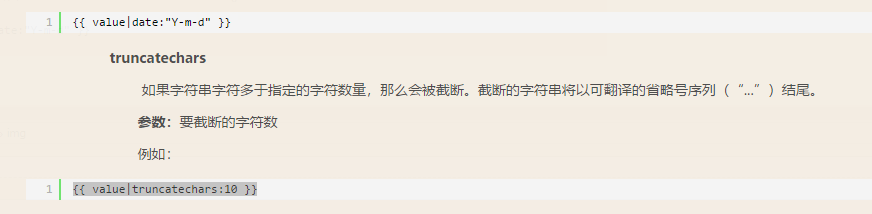
>5:{{ value|truncatechars:10 }}
综合:


特殊 的safe -->> 类似 python 中的 eval 如果写了 那个就执行原来 代码所含有的意思
例如
>1 视图层:

>2 模板层:
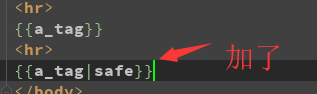
>3 效果

safe
Django的模板中会对HTML标签和JS等语法标签进行自动转义,原因显而易见,这样是为了安全。但是有的时候我们可能不希望这些HTML元素被转义,比如我们做一个内容管理系统,后台添加的文章中是经过修饰的,这些修饰可能是通过一个类似于FCKeditor编辑加注了HTML修饰符的文本,如果自动转义的话显示的就是保护HTML标签的源文件。为了在Django中关闭HTML的自动转义有两种方式,如果是一个单独的变量我们可以通过过滤器“|safe”的方式告诉Django这段代码是安全的不必转义。比如:
|
1
2
3
|
value="<a href="">点击</a>"{{ value|safe }} |
2:标签
模板之标签
标签看起来像是这样的: {% tag %}。标签比变量更加复杂:一些在输出中创建文本,一些通过循环或逻辑来控制流程,一些加载其后的变量将使用到的额外信息到模版中。一些标签需要开始和结束标签 (例如{% tag %} ...标签 内容 ... {% endtag %})。
>1: for 标签
{% for i in list %}
{{i}}
{%endfor %}
遍历元素

 >>>> 这个相当于python 中的for ..else 循环中没有的执行这个
>>>> 这个相当于python 中的for ..else 循环中没有的执行这个
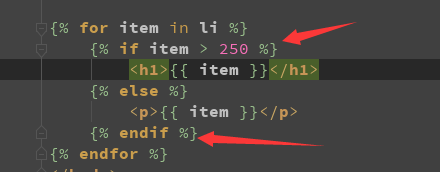
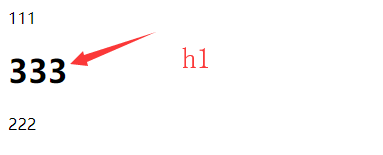
>2:if 标签
判断,从而影响,与页面的展示效果
>3:with 标签
定义一个中间变量
{% with sing=p1.sing %}
{{ sing }}
{% endwith %}
利用 sing 当中间变量, 如果变量名太长,可以 用此减少单词长度
>4:csrf_token 标签
用于跨站伪造保护
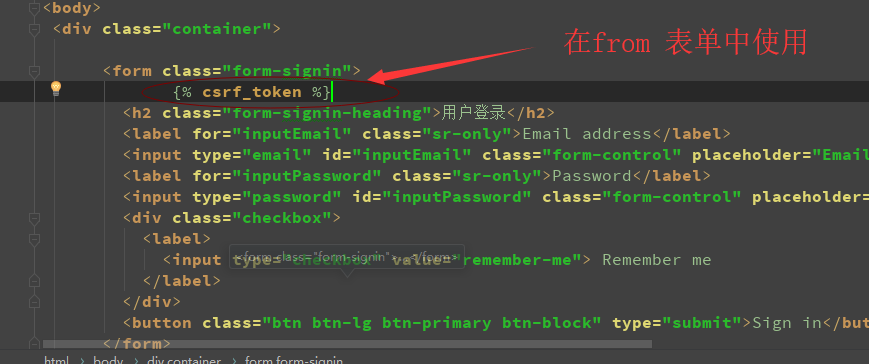
如图: 添加标签的地方,自动生成了input 标签并且有对应的参数
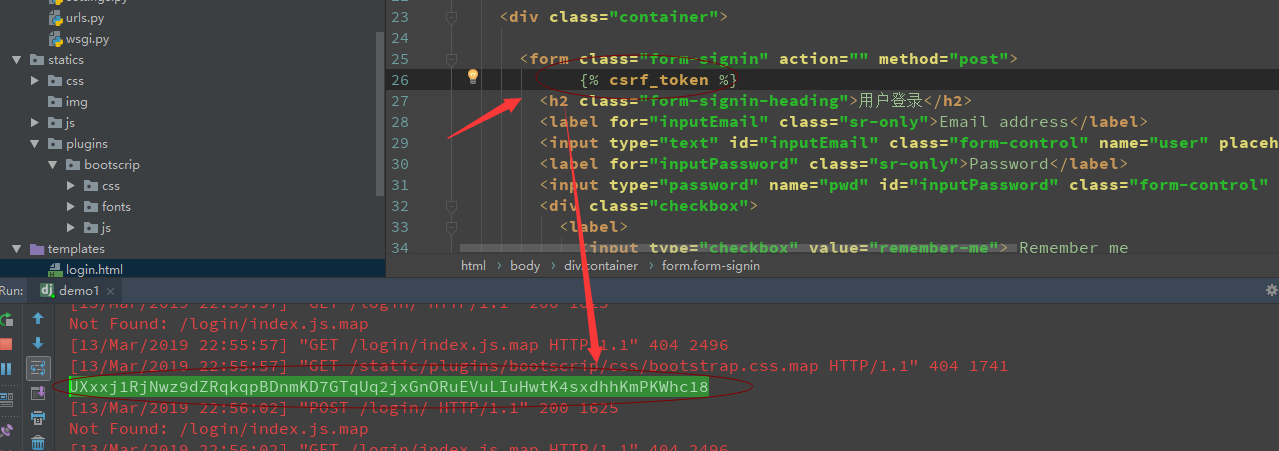

五: 自定义标签
自定义标签和过滤器
1、在settings中的INSTALLED_APPS配置当前app,不然django无法找到自定义的simple_tag.
2、在app中创建templatetags模块(模块名只能是templatetags)
3、创建任意 .py 文件,如:my_tags.py
from django import template from django.utils.safestring import mark_safe register = template.Library() #register的名字是固定的,不可改变 @register.filter def filter_multi(v1,v2): return v1 * v2 <br> @register.simple_tag def simple_tag_multi(v1,v2): return v1 * v2 <br> @register.simple_tag def my_input(id,arg): result = "<input type='text' id='%s' class='%s' />" %(id,arg,) return mark_safe(result)
4、在使用自定义simple_tag和filter的html文件中导入之前创建的 my_tags.py
|
1
|
{% load my_tags %} |
5、使用simple_tag和filter(如何调用)
|
1
2
3
4
5
6
7
8
9
10
|
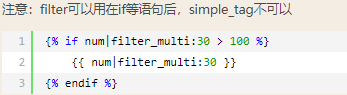
-------------------------------.html{% load xxx %} # num=12{{ num|filter_multi:2 }} #24{{ num|filter_multi:"[22,333,4444]" }}{% simple_tag_multi 2 5 %} 参数不限,但不能放在if for语句中{% simple_tag_multi num 5 %} |
注意:filter可以用在if等语句后,simple_tag不可以