三路快速排序算法分析
双路快速排序算法把等于v的数据分为两部分,方式了数据量一边倒的情况,三路排序算法把排序的数据分为三部分,分别为小于v,等于v,大于v,这样三部分的数据中,等于v的数据在下次递归中不再需要排序,小于v和大于v的数据也不会出现某一个特别多的情况(如下图所示),通过此方式三路快速排序算法的性能更优。
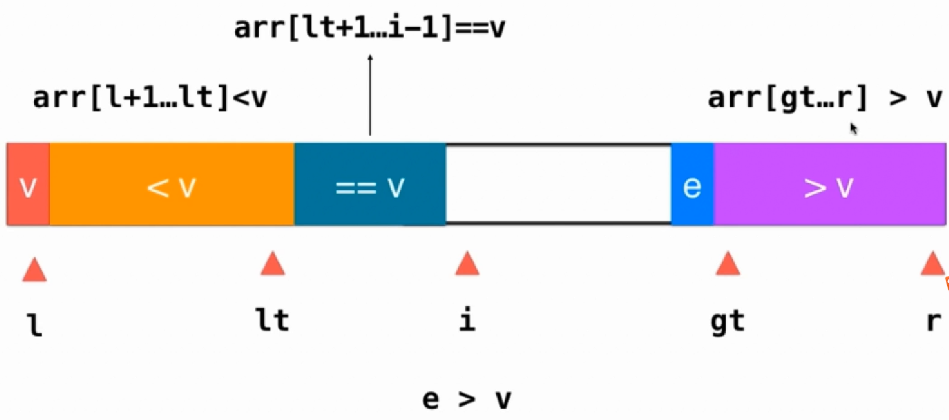
三路快速排序主要关注三个标志,分别为lt,i,gt,这三个标志会把数据分为四部分,arr[l+1...lt]的数据全部小于v,arr[lt+1...i-1]的数据等于v,arr[i...gt-1]的为待排序的数据,arr[gt...r]的数据大于v,具体的代码实现如下:
template<typename T>
void _quickSort3Ways(T arr[], int l, int r)
{
//小规模数据使用插入排序
if(r-l <= 15)
{
insertionSort(arr, l, r);
return;
}
// 随机在arr[l...r]的范围中, 选择一个数值作为标定点pivot
swap( arr[l], arr[rand()%(r-l+1)+l ] );
T v = arr[l];
int lt = l; //arr[l+1...lt] < v
int gt = r+1; //arr[gt...r] > v
int i = l+1; //arr[lt+1...gt-1] == v
while(i < gt)
{
if(arr[i] < v)
{
swap(arr[i], arr[lt+1]);
i++;
lt++;
}
else if(arr[i] > v)
{
swap(arr[i], arr[gt-1]);
gt--;
}
else //arr[i] == v
i++;
}
swap(arr[l], arr[lt]);
_quickSort3Ways(arr, l, lt-1);
_quickSort3Ways(arr, gt, r);
}
template<typename T>
void quickSort3Ways(T arr[], int n)
{
srand(time(NULL));
_quickSort3Ways(arr, 0, n-1);
}
三路快速排序算法对具有大量重复的数据排序性能很好。
排序算法性能对比
下边对比相同数据量下,几乎有序的数据、大量重复的数据情况下,归并排序、希尔排序、不同快速排序、双路快速排序、三路快速排序的性能:
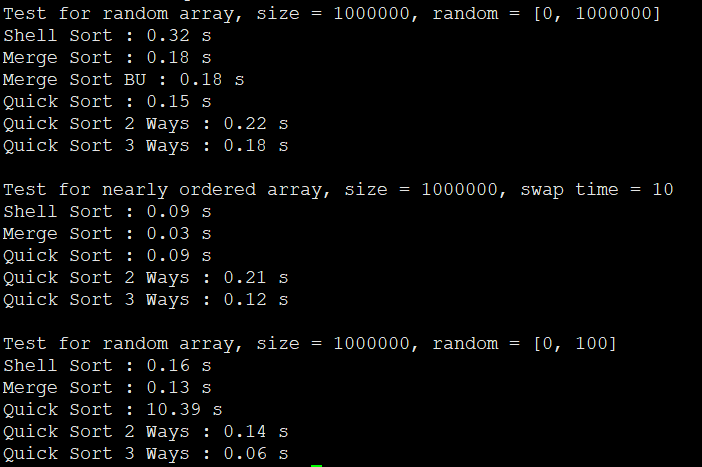
通过初步对比百万数据量的排序得出以下几点结论:
1、随机的百万数据量排序中,快速排序算法性能相对较好。
2、对于百万几乎有序的数据量(不存在重复数据) ,希尔排序和归并排序性能最好,快速排序性能也不差。
3、对于百万具有大量重复数据的情况,之前未优化过的普通快速排序性能很差,三路快速排序算法性能最好。
以上是粗略测试,不同的数据可能具体结果会有差异,但是如果通过大量数据进行多轮测试,快速排序算法性能会最优,毕竟快速排序算法的时间复杂度为O(nlog(n))。