决策树在商品购买能力预测案例中的算法实现
作者:白宁超
2016年12月24日22:05:42
摘要:随着机器学习和深度学习的热潮,各种图书层出不穷。然而多数是基础理论知识介绍,缺乏实现的深入理解。本系列文章是作者结合视频学习和书籍基础的笔记所得。本系列文章将采用理论结合实践方式编写。首先介绍机器学习和深度学习的范畴,然后介绍关于训练集、测试集等介绍。接着分别介绍机器学习常用算法,分别是监督学习之分类(决策树、临近取样、支持向量机、神经网络算法)监督学习之回归(线性回归、非线性回归)非监督学习(K-means聚类、Hierarchical聚类)。本文采用各个算法理论知识介绍,然后结合python具体实现源码和案例分析的方式(本文原创编著,转载注明出处:决策树在商品购买力能力预测案例中的算法实现(3))
目录
- 【Machine Learning】Python开发工具:Anaconda+Sublime(1)
- 【Machine Learning】机器学习及其基础概念简介(2)
- 【Machine Learning】决策树在商品购买力能力预测案例中的算法实现(3)
- 【Machine Learning】KNN算法虹膜图片识别实战(4)
1 决策树/判定树(decision tree)
1 决策树(Dicision Tree)是机器学习有监督算法中分类算法的一种,有关机器学习中分类和预测算法的评估主要体现在:
- 准确率:预测的准确与否是本算法的核心问题,其在征信系统,商品购买预测等都有应用。
- 速度:一个好的算法不仅要求具备准确性,其运行速度也是衡量重要标准之一。
- 强壮行:具备容错等功能和扩展性等。
- 可规模性:能够应对现实生活中的实际案例
- 可解释性:运行结果能够说明其含义。
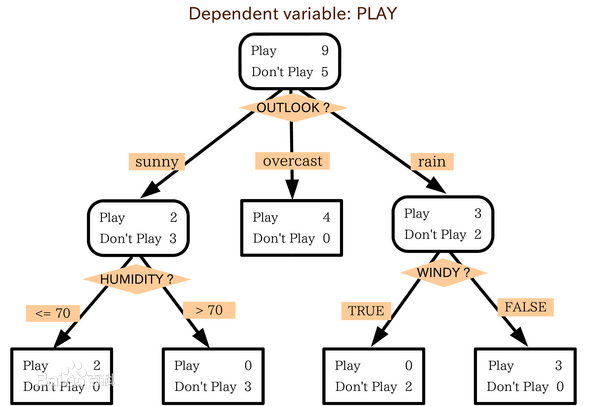
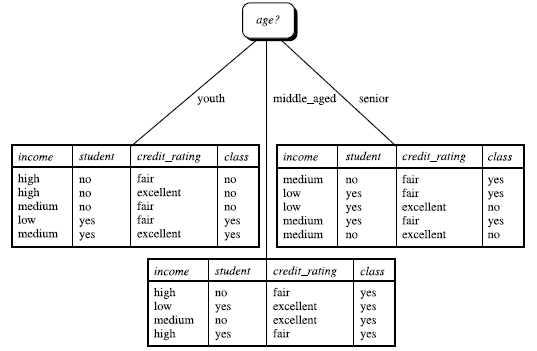
2 构造决策树的基本算法:判定顾客对商品购买能力
2.1 算法结果图:
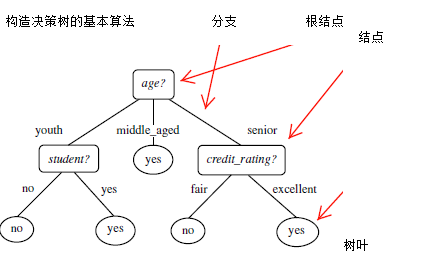
根据决策树分析如下客户数据,判定新客户购买力。其中
客户年龄age:青年、中年、老年
客户收入income:低、中、高
客户身份student:是学生,不是学生
客户信用credit_rating:信用一般,信用好
是否购买电脑buy_computer:购买、不购买

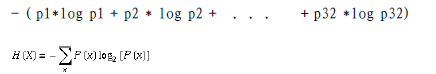
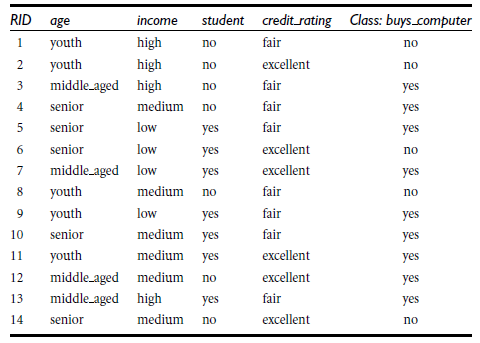
详解:
信息获取量/信息增益(Information Gain):Gain(A) = Info(D) - Infor_A(D),例如age的信息增益,Gain(age) = Info(buys_computer) - Infor_age(buys_computer)。
Info(buys_computer)是这14个记录中,购买的概率9/14,不购买的5/14,带入到信息熵公式。
Infor_age(buys_computer)是age属性中,青年5/14购买概率是2/5,不购买3/5;中年4/14购买概率是1,不购买概率是0,老年5/14购买概率3/5,不购买概率是2/5.分别代入信息熵公式
Info(buys_computer)与Infor_age(buys_computer)做差,即是age的信息增益,具体如下:
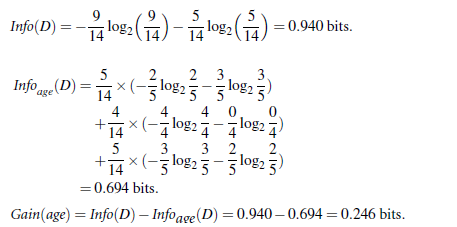
类似,Gain(income) = 0.029, Gain(student) = 0.151, Gain(credit_rating)=0.048
- 树以代表训练样本的单个结点开始(步骤1)。
- 如果样本都在同一个类,则该结点成为树叶,并用该类标号(步骤2 和3)。
- 否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性(步骤6)。该属性成为该结点的“测试”或“判定”属性(步骤7)。在算法的该版本中,
- 所有的属性都是分类的,即离散值。连续属性必须离散化。
- 对测试属性的每个已知的值,创建一个分枝,并据此划分样本(步骤8-10)。
- 算法使用同样的过程,递归地形成每个划分上的样本判定树。一旦一个属性出现在一个结点上,就不必该结点的任何后代上考虑它(步骤13)。
- 递归划分步骤仅当下列条件之一成立停止:
- (a) 给定结点的所有样本属于同一类(步骤2 和3)。
- (b) 没有剩余属性可以用来进一步划分样本(步骤4)。在此情况下,使用多数表决(步骤5)。
- 这涉及将给定的结点转换成树叶,并用样本中的多数所在的类标记它。替换地,可以存放结
- 点样本的类分布。
- (c) 分枝
- test_attribute = a i 没有样本(步骤11)。在这种情况下,以 samples 中的多数类
- 创建一个树叶(步骤12)
在决策树ID3基础上,又进行了算法改进,衍生出 其他算法如:C4.5: (Quinlan) 和Classification and Regression Trees (CART): (L. Breiman, J. Friedman, R. Olshen, C. Stone)。这些算法
共同点:都是贪心算法,自上而下(Top-down approach)
3 基于python代码的决策树算法实现:预测顾客购买商品的能力
3.1 机器学习的库:scikit-learnPython
scikit-learnPython,其特性简单高效的数据挖掘和机器学习分析,简单高效的数据挖掘和机器学习分析,对所有用户开放,根据不同需求高度可重用性,基于Numpy, SciPy和matplotlib,开源,商用级别:获得 BSD许可。scikit-learn覆盖分类(classification), 回归(regression), 聚类(clustering), 降维(dimensionality reduction),模型选择(model selection), 预处理(preprocessing)等领域。
- 安装scikit-learn: pip, easy_install, windows installer,安装必要package:numpy, SciPy和matplotlib, 可使用Anaconda (包含numpy, scipy等科学计算常用package)
- 安装注意问题:Python解释器版本(2.7 or 3.4?), 32-bit or 64-bit系统
商品购买例子:
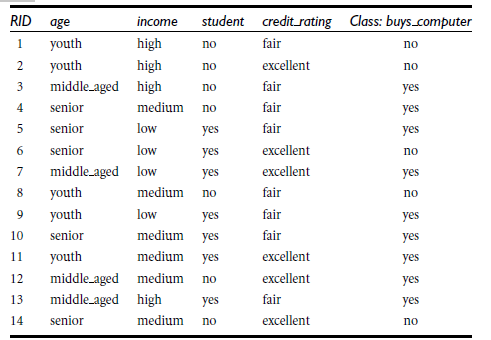
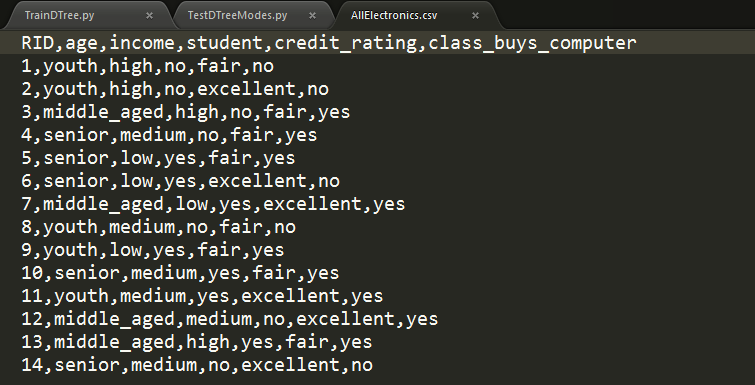
3.3 运行效果如下:

其中,datafile存放模型训练数据集和测试数据集,TarFile是算法生成文本形式的dot文件和转化后的pdf图像文件,两个py文件,一个是训练算法一个是测试训练结果。右侧预测值【0 1 1】代表三条测试数据,其中后两条具备购买能力。具体算法和细节下节详解。
3.4 具体算法和细节
python中导入决策树相关包文件,然后通过对csv格式转化为sklearn工具包中可以识别的数据格式,再调用决策树算法,最后将模型训练的结果以图形形式展示。
from sklearn.feature_extraction import DictVectorizer import csv from sklearn import tree from sklearn import preprocessing from sklearn.externals.six import StringIO
读取csv文件,将其特征值存储在列表featureList中,将预测的目标值存储在labelList中
'''
Description:python调用机器学习库scikit-learn的决策树算法,实现商品购买力的预测,并转化为pdf图像显示
Author:Bai Ningchao
DateTime:2016年12月24日14:08:11
Blog URL:http://www.cnblogs.com/baiboy/
'''
def trainDicisionTree(csvfileurl):
'读取csv文件,将其特征值存储在列表featureList中,将预测的目标值存储在labelList中'
featureList = []
labelList = []
#读取商品信息
allElectronicsData=open(csvfileurl)
reader = csv.reader(allElectronicsData) #逐行读取信息
headers=str(allElectronicsData.readline()).split(',') #读取信息头文件
print(headers)
运行结果:

存储特征数列和目标数列
'存储特征数列和目标数列'
for row in reader:
labelList.append(row[len(row)-1]) #读取最后一列的目标数据
rowDict = {} #存放特征值的字典
for i in range(1, len(row)-1):
rowDict[headers[i]] = row[i]
# print("rowDict:",rowDict)
featureList.append(rowDict)
print(featureList)
print(labelList)
运行结果:
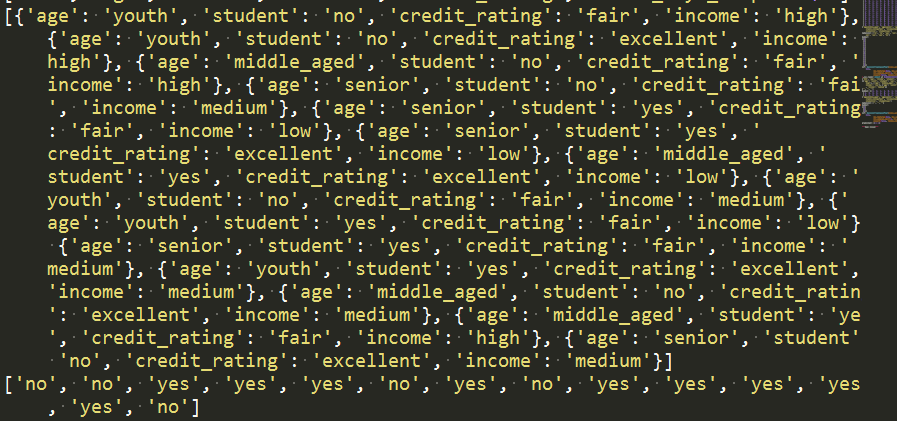
将特征值数值化
'Vetorize features:将特征值数值化'
vec = DictVectorizer() #整形数字转化
dummyX = vec.fit_transform(featureList) .toarray() #特征值转化是整形数据
print("dummyX: " + str(dummyX))
print(vec.get_feature_names())
print("labelList: " + str(labelList))
# vectorize class labels
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY:
" + str(dummyY))
运行结果:
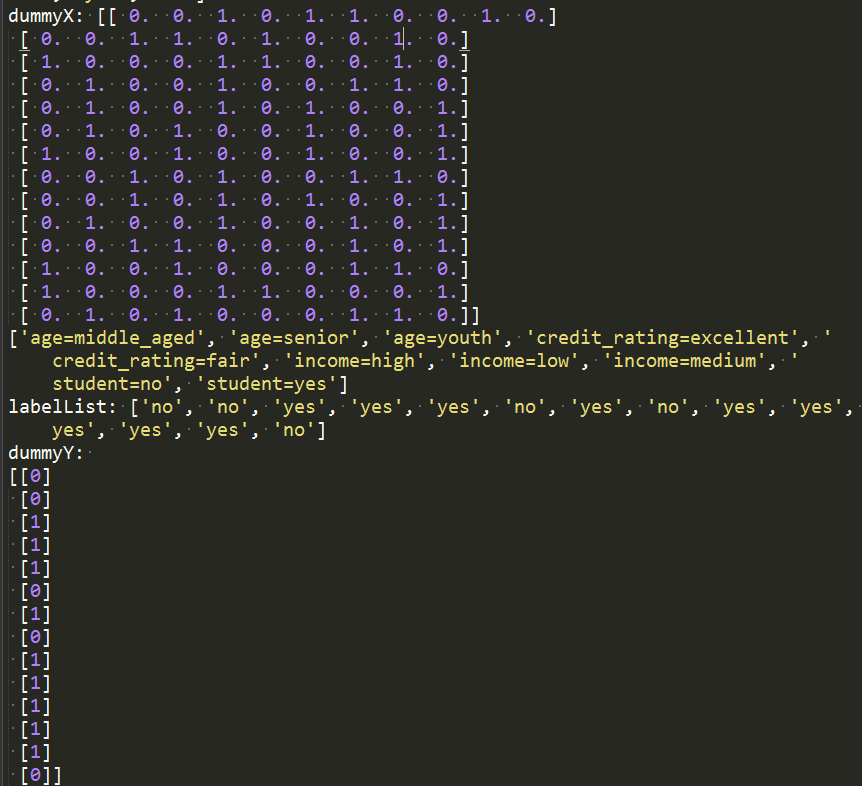
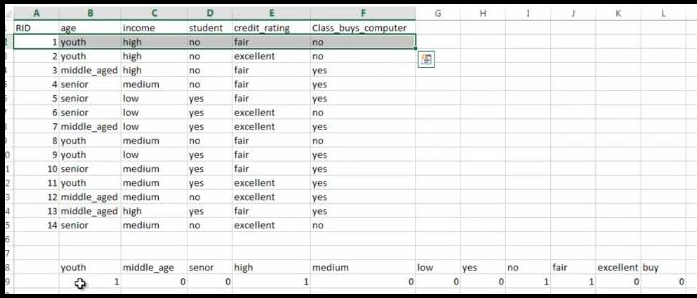
如上算法就是将商品信息转化为机器学习决策树库文件可以识别的形式,即如下形式:
使用决策树进行分类预测处理
'使用决策树进行分类预测处理'
# clf = tree.DecisionTreeClassifier()
#自定义采用信息熵的方式确定根节点
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf))
# Visualize model
with open("../Tarfile/allElectronicInformationGainOri.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
运行结果:

将其转化为图像形式展示,需要下载插件:安装 下载Graphviz:

一路安装下来,然后打开cmd进入dos环境下,并进入../Tarfile/Tname.dot路径下;#2 输入dot -Tname.dot -o name.pdf命令,将dos转化为pdf格式
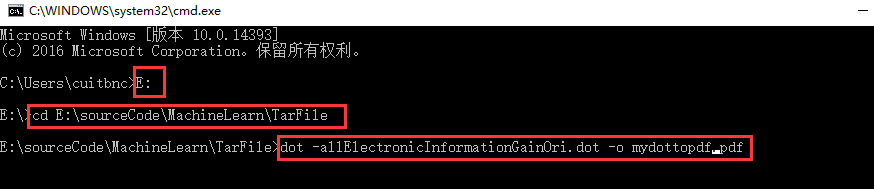
打开文件可见:

4 完整项目下载
扩展:银行信用自动评估系统