图片文字识别-问题描述和流程图
针对识别图片中的文本信息识别,分为文本区域检测,之后是将文本区域的字符分割,分割以后开始进行字符识别。

滑动窗口
滑动窗口是用来定位文字位置、行人位置等。
以行人检测为例子:
1.做滑动窗口前,首先进行预训练(训练样本为固定大小的图片),获得一个能识别行人的模型。
2.然后使用该模型,在原始图片上按照一定步长,尺寸,在图片中进行窗口滑动,剪裁取块。
3.将取块的图片放缩到模型使用的大小,输入该模型,判断有行人的地方图片与滑动位置做好标记,处理后得到行人可能位置。
4.换用不同的步长、尺寸,重复2-4过程直到检测完毕,得到全部位置。

不仅可以用于行人检测,在字符检测、字符分割方面,也有应用。
字符位置检测的方法和行人检测相同,但是仍然需要将位置进行一些噪声过滤,以确定真实的字符位置信息。
得到字符位置信息后,也再预训练一个模型,用于判定是否为字符分割点。使用滑动窗口的方案,得到分割点,得到分割后的字符。
然后再使用一个预训练好的模型,识别字符即可。

获取大量数据和手工数据合成
在训练模型获得的结果不够好,而通过绘制曲线等方法,分析出是数据量不够导致的问题,那么需要制作数据集了。
1.制作数据集可以从0开始,使用一些方法自己制作,然后ps,剪裁等等。
2.如果本身具有数据集,也可以使用将原始数据集进行扭曲,旋转,加噪声,液化等方法,得到新的样本,作为数据集。
3.雇人做数据集,这就算了吧。
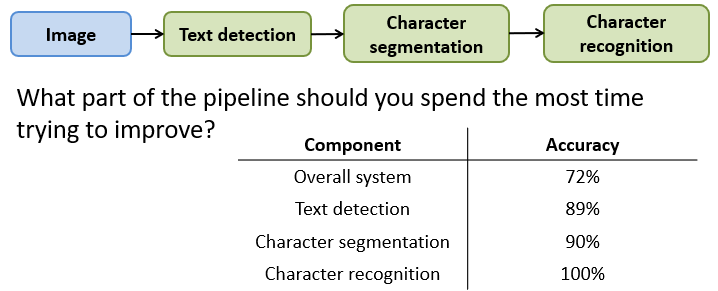
上限分析-流程图中哪部分需要提升
上限分析用于确定哪部分的算法进行优化后,整体系统性能具有较大提升。
在下图中,图像中文字识别有三步操作,对应不同的模型方法,最终得到了整个系统,得到了72%的准确率。
现在,使用手工的方法,让文本位置检测的模型正确率为100%(比如采用那些该部分识别率100%的特定数据集输入系统中),然后再评价一下系统,得到了89%的准确率,即如果优化了文本位置检测模型,整个系统有较大的提升。
在以上基础上,如果再调整字符分割模型为100%,整体模型只提升1%,则该部分对整体影响不大,不太需要花费精力去优化。
在前面基础上,再调整字符识别部分,而最终系统准确率提升到100%,那么该整体模型中的字符识别模型,也是需要进行优化的。
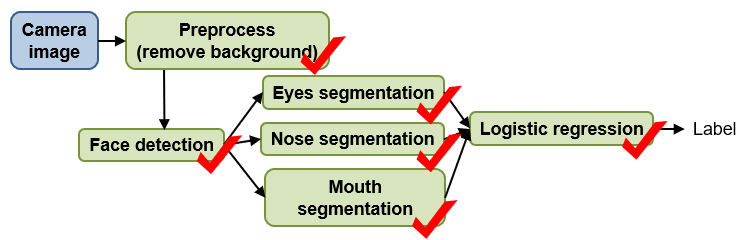
在人脸识别的过程中,也是有这样的步骤。进行每个模块的100%手工调制,判断该部分对整体性能的影响,从而判断该部分是否需要花费精力优化。下图为6部分的验证工作。
完
全剧终