大规模机器学习-学习大数据集
数据越多,自然训练效果越好,在训练过程中,过拟合与欠拟合的指标通过绘图确定,据此调整超参数。
在此前的批梯度下降法的过程中,当数据集过大时候,由于如下计算式子中要求遍历所有数据得到一次更新,其计算成本过于昂贵。因此,如果裁剪数据集的大小,如果也能够达到相同的训练效果,则不需要使用原始数据集。
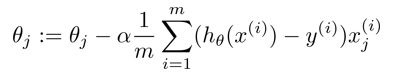
随机梯度下降
随机梯度下降,将数据进行随机洗牌,然后在更新theta参数时,只使用其中一个样本。训练时重复遍历样本多次,最终结果仍然会收敛到一个较好的局部最优。


小批量梯度下降
小批量梯度下降,介于批梯度下降和随机梯度下降之间。当样本数量m=1000时,而小批量数量b=10,则有如下算法。其中i 进行遍历到数据集末尾m-b+1,计算梯度过程中求均方差过程求导以后使用的除数为b,遍历的小批量为i+b-1。
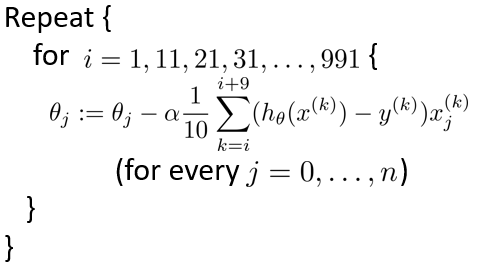
随机梯度下降收敛
收敛性检查,使用的批梯度下降方法和随机梯度下降方法如下图,批梯度下降方案过于耗时,而随机梯度下降,通过收集一定步数的cost值,然后求得平均,得到一个近似的误差J,作为参考,通过绘图,用于判断梯度下降的效果,模型是否错误等。

另外,梯度下降过程中的学习率alpha,可以随着迭代次数的增大而减小,但是其额外引入的两个超参数又是一个问题。

在线学习
在线学习基本使用的是随机梯度下降的方案吧,因为数据集是实时更新的,所以在如下的包裹运送示例中,当用户做出一次决定,则产生一个或者一批的数据量,将这些数据进行学习,并丢弃数据,循环往复,获得一个动态的定价模型,以最大化购买量(收益吧)。

映射化简和数据并行
该部分的主要思想是,将一个小批量的数据(如400),分为数份(如4份),分别通过数个机器(如4个),计算梯度值,然后将所有的计算结果,结合到一个模型中,以加速神经网络的训练过程。
一些高级的函数库也已经能够使用单个机器多CPU的方案,也就是并行化在一个多核的机器上运行,以加速训练过程。
