推荐系统-问题公式化
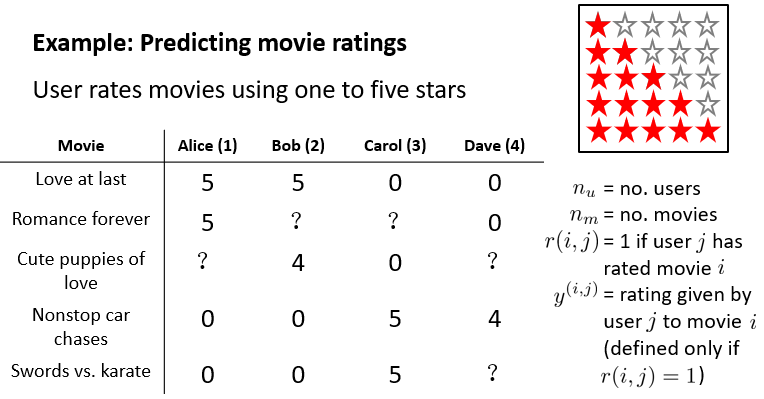
如下是一个电影评分系统。某个用户没有看过某电影时,通过得到预测评分来判断是否推荐该电影给该用户。
其中?表示没有看过,对应的r=0。其它表示在图中给出。从常识上看,电影列表中前三个为爱情片,后两个为动作片,这为评分预测提供了线索。可以进行针对每个用户将电影分类,求得该用户对某类电影的平均评分,作为评价,如第一列中?为5,第二列为4.5。
基于内容的推荐系统
假设使用x手动设置了每个电影中的,爱情片成分和动作片成分,并添加偏置项1,则x为三行一列的向量。

假定已经针对每个用户,学习到了一个theta,theta的大小是和x相同的。使用thetaT*x,其中x和电影有关,theta和用户有关,得到预测值。
![]()
theta的习得方式为,通过线性回归,最小化目标函数得到。最小化目标为预测值和真实值的方差和最小,并添加正则化项。
下图中第一行为只考虑单个用户的情况,习得一个theta。但是拥有多个用户,则将多个用户组成的theta进行均衡,使得整个系统的目标函数最小化,求得所有的theta。

然后使用梯度下降法,初始化theta后,通过迭代,得到最后的theta值。其中每个用户当k=0,theta0为常数吧,所有就有第一行。第二行中括号内为正常的求导梯度。
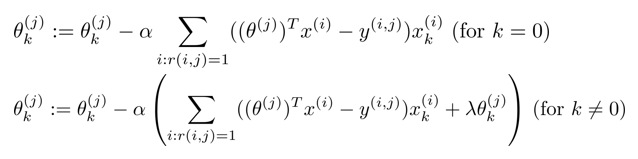
协同过滤
之前的系统中是已知了每个电影的向量x,通过构建目标函数,使用梯度下降的方法求得theta。但是在实际的系统中,x是未知的。
假设已经知道了theta的值,针对不同用户与同一电影的问题,theta做常量,x作为变量,使用方法求得x。
如第一行,当x为[1,1,0]列向量,通过thetaT*x,求得的结果和第一行的实际值相同,则该x为应该求得的x。

具体的方法和求theta相同,只是如下图中,第一行是根据不同用户同一电影,加上正则项,得x。
第二行求和过程中是所有电影的误差求和。
在计算的过程中,不使用协同的,则随机化theta和x,先通过x求得theta,再使用theta得到x,如此循环计算。

协同过滤算法
协同过滤算法将theta和x的目标函数写在了一起,而对不同的变量(用户,电影)求导,一次计算得到两个梯度,然后迭代求出theta和x。
下图中第一行为求theta的目标函数,第二行为求x的目标函数,第三行将由前两行求和得到,其中的i和j需要遍历。

在计算过程中,第二行为使用梯度下降法,针对目标函数使用不同的量作为变量,求得梯度,进行迭代。

向量化:低秩矩阵分解
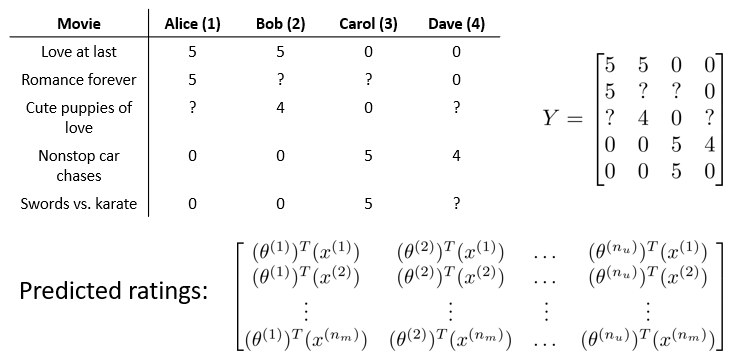
地址矩阵分解实质上是协同过滤算法,在表示形式上,使用梯度下降求得theta和x以后,使用Y矩阵表示最终的预测结果,使用theta和x的乘积,表示出Y的每一个值。
通过以上求得的theta,是和用户有关的,x是和电影有关的。当两个电影的x相近时,用户喜欢其中一个电影,则可以将另一个电影进行推荐。
计算的方法使用欧式距离即可。如下是通过用户喜欢电影i 以后,通过xi,遍历其他x,得到距离最近的5个电影xj。
![]()
实现细节-均值归一化
当某个用户所有电影都没有看过,则通过目标函数中,第一项求和过程theta5不参与,而theta5只是参与了第三项的正则化。根据最小化目标函数,在theta5负责的部分中,theta5最终为0。
当theta5为0,则通过thetaT*x求得的所有电影预测评分都为0,这是不合理的。

在计算过程中,首先将目标预测矩阵Y中,所有已知值求得平均数,将Y归一化处理如下图。通过该矩阵的已知值作为目标y,求得theta和x。将求得的结果再加上均值mu,作为最后的输出。
虽然在计算过程中,第五个用户因为仍然没有看过任何电影,但是通过添加了mu以后,得到了平均分数,通过该平均分数作为依据,给该用户推荐电影。

![]()