梯度下降的高级优化
三种高级算法的优点:

这些高级算法,有对应的库实现。使用方法如:

其中的fminunc函数提供了优化算法。参考:https://www.zhihu.com/question/45955668?sort=created
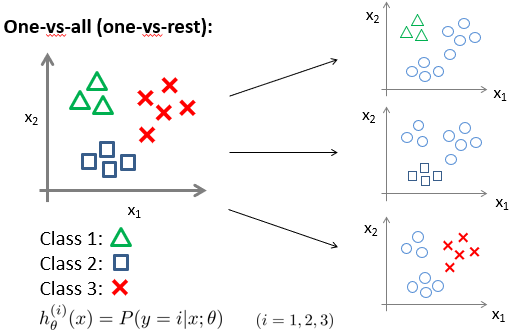
多类别分类
多类别分类,使用多个分类器进行分类,当输入一个样本x,输入到所有的分类器,选择一个最大的h(x),作为对应的预测类别。
过拟合问题的处理
如图所示,
特征减少:丢弃特征,手工保留特征,使用模型算法等。正则化:保留所有特征,但降低参数的量级。

正则化线性回归
正则化在损失函数J中,添加了theta项,并使用lambda调节theta的大小。
目标是使得损失函数最小化,则更大的lambda意味着得出更小的theta,而在线回归中,theta是作用在输入变量x上的,因此使得输入特征x对输出预测值的影响减少,实现正则化。

在实现过程中,偏移项x0,应该是不属于特征的一部分,因此不对theta0做正则化了。
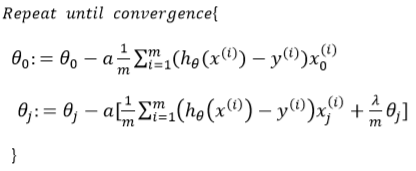
变化形式可以发现,认为学习率alpha,控制theta大小的lambda,数据条目m,与1之间的组合表达式结果基本为0.99,那可以说是theta每次更新是使用其折扣和梯度的共同作用,以防止过拟合。
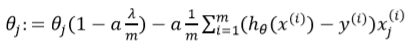
对应的之前和之后的正规方程如下:
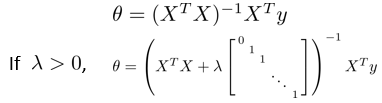
正则化逻辑回归
给出相似的代价函数:
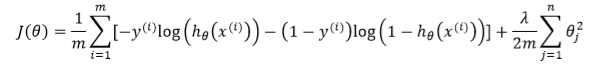
类似,对其求导,结合之前的theta,进行梯度下降,更新theta:
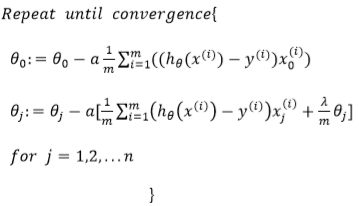
但是h(x)的值和线性回归不同,使用了sigmoid对线性做了变换。如下:
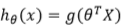
在实现过程中,仍然可以采用fminunc函数,传入按照要求的自定义的costFunction,和其它参数,进行高级优化。
只是现在使用的costFunction中,含有了正则化部分,用于降低过拟合。
一个costFunction的实例如下:

神经网络
在线性回归,逻辑回归等的线性过程中,根据数据特征,有时候可能需要构建更复杂的模型,如构建二次,三次等的表达式模型,来拟合具体的数据,但是这样引入了更高的计算负荷。如下的公式,进行高次方的排列组合,将很大的加重数据计算量,以便正确的得到模型:
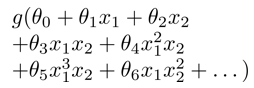
所以使用神经网络,能更通用的表示模型吧。。