场景
业务场景:
需要记录大量定位数据,形成轨迹回放功能。
此时不能将所有的点位数据存储进一个表中,需要进行分表操作,涉及如下几个步骤
1、一个建立一个新表,表名以日期结尾。
2、每天的点位数据存储进对应日期的表中。
3、按照时间区间参数查询点位表时,关联多个表的查询结果并返回。
若依前后端分离版本地搭建开发环境并运行项目的教程:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/108465662
在上面的框架的使用基础上,在定时任务中执行固定的代码,在代码中获取某个表的建表语句,然后以时间
为后缀新建新的一个表。
比如新建表:
CREATE TABLE `bus_badao_record` ( `id` int NOT NULL AUTO_INCREMENT, `x` varchar(255) DEFAULT NULL, `y` varchar(255) DEFAULT NULL, `record_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT charset=utf8mb3
需要每天新建一个表并以时间为后缀,比如明天需要新建一个表bus_badao_record20220805,后天需要新建一个表bus_badao_record20220806
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
关注公众号
霸道的程序猿
获取编程相关电子书、教程推送与免费下载。
实现
1、按照日期实现每天创建一个带时间后缀的新表。
具体实现思路参考下文
SpringBoot+Mybatis实现代码获取建表语句并实现动态建表:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/126161849
通过上面的流程设置定时任务定时执行,这里设置12小时执行一次,则实现了每天会新建一个第二天日期结尾的新表。
2、然后存储数据的实现较为简单,在插入数据库之前获取当前日期并且格式与上面建表时一致,
然后将表名以及要插入的数据传递到动态sql中 。
获取当前日期的后缀
new SimpleDateFormat("yyyyMMdd").format(new Date());
然后在批量插入数据库时传递表名和要插入的数据
mapper接口:
int addBatch(@Param("tableName") String tableName, @Param("list") List<BusBadaoRecord> list);
mapperxml:
<insert id="addBatch"> INSERT INTO ${tableName} (`x`, `y`, `record_time`) VALUES <foreach collection="list" item="item" index="index" separator=","> ( #{item.x}, #{item.y}, #{item.recordTime} ) </foreach> </insert>
3、关联查询多表。
这里使用union all 进行连接,union all代表联合所有的查询结果。
比如在04表和05表中分别插入两条数据
04表
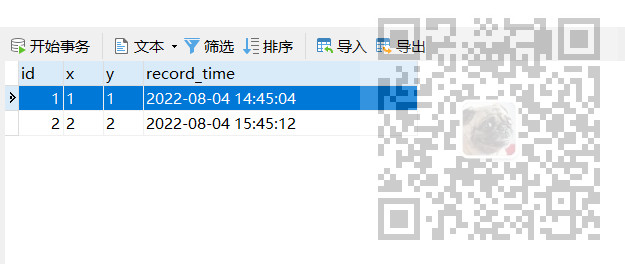
05表
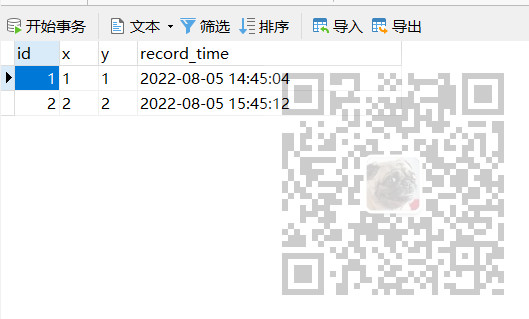
此时使用union all 关联两个表的查询语句
SELECT * FROM bus_badao_record20220804 UNION ALL SELECT * FROM bus_badao_record20220805
关联查询会将两个表的查询结果全部查询关联

所以根据时间区间跨表查询的思路就是,根据查询的时间区间获取要查询哪些表的表名,然后每个表都筛选出这个
时间区间内的数据,最后使用union all 关联返回。
比如这里要查询介于2022-08-04 15:45:12到2022-08-05 14:45:04之间的数据,首先根据开始时间和结束时间格式化处理并追加上
表名前缀可以获取到数据库中要开始的表名为bus_badao_record20220804和bus_badao_record20220805。
然后筛选这两个表之间的表名。
List<String> tableList = busTableMapper.selectTableList("bus_badao_record20220804","bus_badao_record20220805");
具体实现为
List<String> selectTableList(@Param("beginTime") String beginTime , @Param("endTime") String endTime);
xml为
<select id="selectTableList" resultType="java.lang.String"> SELECT table_name FROM information_schema.TABLES WHERE table_schema = (select database()) AND table_name BETWEEN #{beginTime} AND #{endTime} </select>
根据传递的开始时间和结束时间的参数,获取要查询哪些表的表名
然后就遍历这些表名,每个表名都查询位于2022-08-04 15:45:12到2022-08-05 14:45:04之间的数据然后最后用
sreingBuffer和union all拼接成查询语句:
List<String> tableList = busTableMapper.selectTableList("bus_badao_record20220804","bus_badao_record20220805"); StringBuffer stringBuffer = new StringBuffer(); for (int i = 0; i < tableList.size(); i++) { stringBuffer.append("select * from " + tableList.get(i) ); stringBuffer.append(" where record_time between '2022-08-04 15:45:12' and '2022-08-05 14:45:04'"); if (i + 1 < tableList.size()) { stringBuffer.append(" union all "); } } List<BusBadaoRecord> busBadaoRecordList = busBadaoRecordMapper.executeSQL(stringBuffer.toString());
需要注意的是这里的where 和 union all 字符串的前后都有空格,最后要验证下执行的sql是否正确
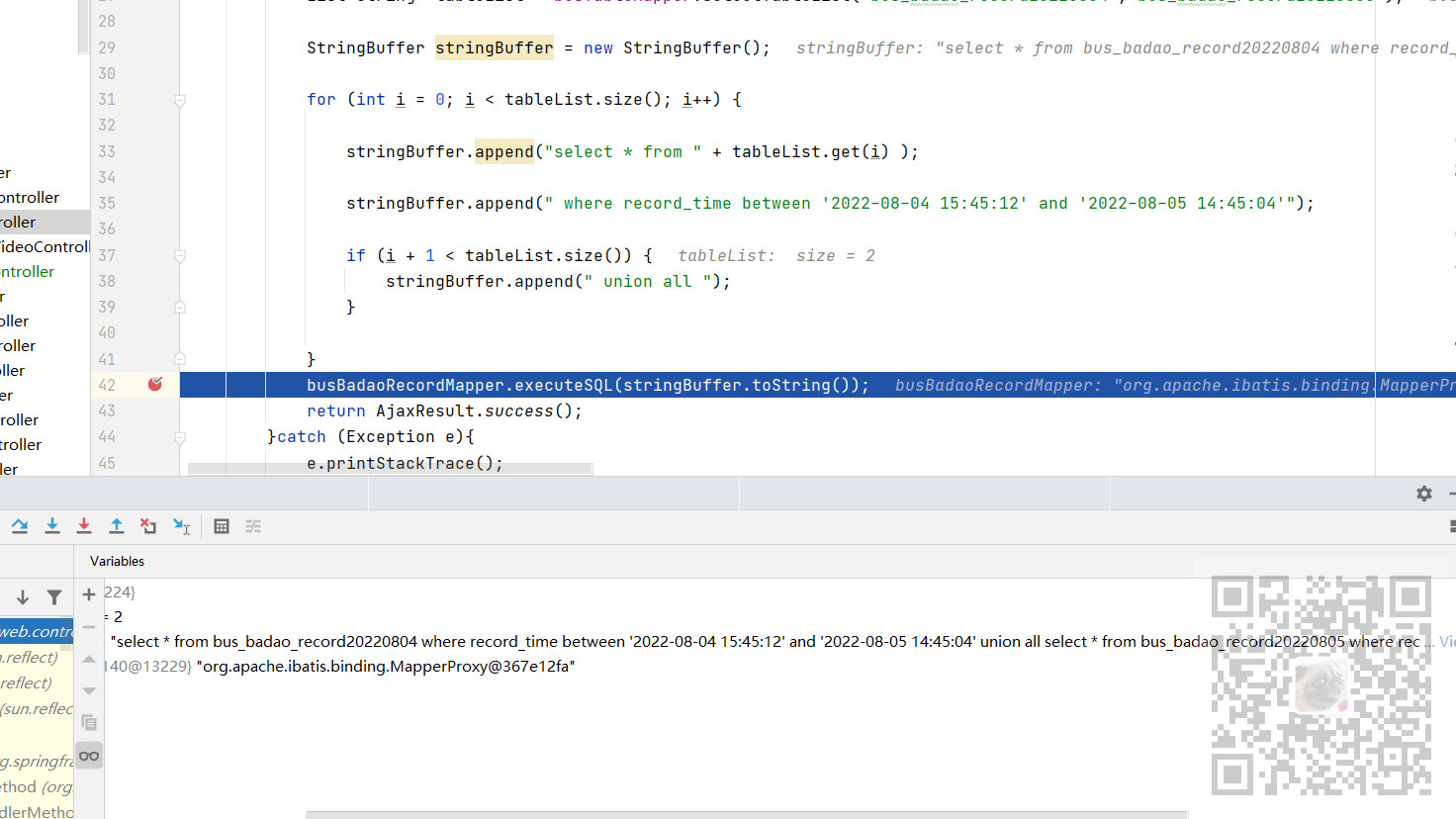
拿到拼接之后的sql在数据库中查询
SELECT * FROM bus_badao_record20220804 WHERE record_time BETWEEN '2022-08-04 15:45:12' AND '2022-08-05 14:45:04' UNION ALL SELECT * FROM bus_badao_record20220805 WHERE record_time BETWEEN '2022-08-04 15:45:12' AND '2022-08-05 14:45:04'
没有问题,并且代码中返回结果也正确:

4、需要注意上面的executeSQL中
List<BusBadaoRecord> executeSQL(String sql);
mapper
<select id="executeSQL" resultMap="BusBadaoRecordResult" fetchSize="10000"> ${sql} </select>
这里加了一个fetchSize
因为这里数据量比较大,为了提高查询响应时间,所以设置为10000
Fetch相当于读缓存,如果使用setFetchSize设置FetchSize为10000,本地缓存10000条记录,每次执行rs.next,只是内存操作,不会有数据库
网络消耗,效率会搞,但是fetchSize越高则内存占用越高,要避免出现OOM错误。