MySQL之4---SQL基础
名词认识
SQL_MODE
SQL_MODE:设置约束检查,可分别进行全局设置或当前会话设置
作用:使数据准确,符合常识
5.7 版本之后默认启用SQL92严格模式,通过sql_mode参数来控制
查看
mysql> select @@sql_mode;
+-----------------------------------------------------------------------------------------------------------------------+
| @@sql_mode |
+-----------------------------------------------------------------------------------------------------------------------+
| ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION |
+-----------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
- NO_AUTO_CREATE_USER:禁止GRANT创建密码为空的用户
- NO_ZERO_DATE:不允许使用‘0000-00-00’的时间
- ONLY_FULL_GROUP_BY:对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么将认为这个SQL是不合法的
- NO_BACKSLASH_ESCAPES:反斜杠“”作为普通字符而非转义字符
- PIPES_AS_CONCAT:将"||"视为连接操作符而非“或运算符”
清空
mysql> set global sql_mode='';
字符集
作用:字符转换
查看支持的所有字符集
mysql> show charset;
8.0 默认:utf8mb4
8.0 之前默认:latin1
面试问题:
utf8:最大存储3字节字符, 一个中文占3字节, 一个数据/字母/特殊符号占1字节
utf8mb4:最大存储4字节字符, 一个中文占3字节, 一个数据/字母/特殊符号占1字节, 可以存储emoji
校对规则
校对规则 = 排序规则 = collation
作用:影响排序
1.3.2 查询
mysql> show collation;
+----------------------------+----------+-----+---------+----------+---------+---------------+
| Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute |
+----------------------------+----------+-----+---------+----------+---------+---------------+
... ...
| utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD |
| utf8mb4_0900_as_cs | utf8mb4 | 278 | | Yes | 0 | NO PAD |
... ...
*_ci 大小写不敏感
*_cs 大小写敏感
列属性
约束(一般建表时添加)
PK:primary key :主键约束
列值非空且唯一,主键在一个表中有且只有一个,但是可以有多个列一起构成。
NN:not null :非空约束
列值不能为空,也是表设计的规范,尽可能将所有的列设置为非空。可以设置默认值为0。
UK:unique key :唯一键
列值不能重复。
FK:
建议:
- 每张表设置主键,建议是数字自增列
- 尽量对每个列设置非空
其他属性
default:默认值
列中没有录入值时,会自动使用default的值填充。
auto_increment: 自增长
针对数字列(常用于主键),顺序的自动填充数据(默认是从1开始,将来可以设定起始点和偏移量)。
unsigned :无符号
针对数字列,非负数。
comment:注释
key:索引
可以在某列上建立索引,来优化查询,一般是根据需要后添加。
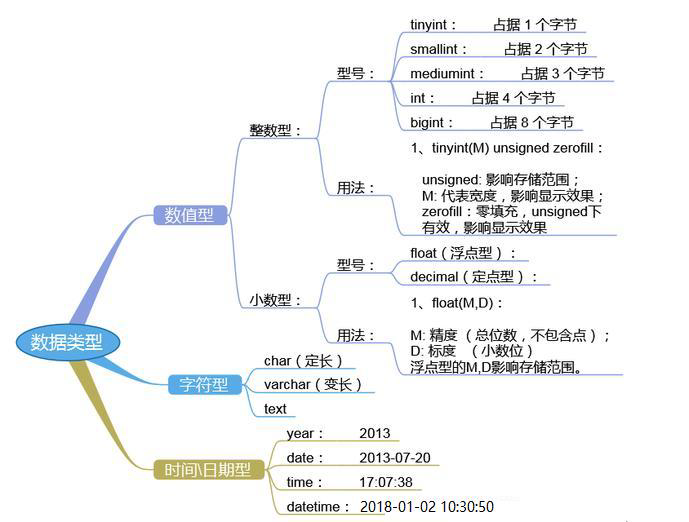
数据类型
作用:控制存储数据的"格式"和规范,保证数据的准确性和标准性。
选择正确的数据类型对于获得高性能至关重要,三大原则:
更小的通常更好,尽量使用可正确存储数据的最小数据类型
简单就好,简单数据类型的操作通常需要更少的CPU周期
尽量避免NULL,包含为NULL的列,对MySQL更难优化
种类:
- 数值类型
- 字符类型
- 时间类型
- 二进制类型
- JSON
整型
数值类型
| 类 | 类型 | 说明 |
|---|---|---|
| 整数 | TINYINT | 极小整数数据类型(-128~127)1bytes |
| 整数 | SMALLINT | 较小整数数据类型(-3276832767)(-2^152^15-1)2bytes |
| 整数 | MEDIUMINT | 中型整数数据类型(-8388608~8388607)3bytes |
| 整数 | INT | 常规(平均)大小的整数数据类型(-231~231-1)4bytes |
| 整数 | BIGINT | 较大整数数据类型(-263~263-1)8bytes |
| 浮点数 | FLOAT | 小型单精度(4字节)浮点数(非准确小数值) |
| 浮点数 | DOUBLE | 常规单精度(8字节)浮点数(非准确小数值) |
| 定点数 | DECIMAL | 具有小数点而且数值确定的数值(-65位.30位~65位.30位) |
| BIT | BIT | 二进制位字段值(长度1-64位) |
tinyint :1bytes :0~255 :-128~127 :3位
int :4bytes :0~2^32-1 :-2^31~2^31-1 :10位
bigint :8bytes :0~2^64-1 :-2^63~2^63-1 :20位
特别说明:
- 手机号是11位的,再加区号更长,一般是使用char类型。
- MySQL中无 BOOL 值,使用 TINYINT(1) 构造,zero值被视为假,非zero值视为真。
- 后加unsigned(无符号),则最大值翻倍,如:tinyint unsigned 取值范围 (0~255)。
- INT(m)里的m是表示SELECT查询结果集中的显示字符的个数,并不影响实际的取值范围。对于存储和计算来说,INT(1)和INT(20)是相同的。
浮点数你们公司怎么存储的?
- 金钱(精度要求高)有关的使用DECIMAL类型,其内部按照字符串存储
- 精度要求不高的,放到N倍,用整数类型,查询性能好
字符类型
| 类 | 类型 | 说明 |
|---|---|---|
| 文本 | CHAR | 固定长度字符串, 最多为255个字符 |
| 文本 | VARCHAR | 可变长度字符串,最多为65,535个字符 |
| 文本 | TINYTEXT | 可变长度字符串,最多为255个字符 |
| 文本 | TEXT | 可变长度字符串,最多为65,535个字符 |
| 文本 | MEDIUMTEXT | 可变长度字符串,最多为16,777,215个字符 |
| 文本 | LONGTEXT | 可变长度字符串,最多为4,294,967,295个字符 |
| 整数 | ENUM | 由一组固定的合法值组成的枚举,最多65,535个不同元素(实际小于3000) |
| 整数 | SET | 由一组固定的合法值组成的集,最多不同成员64个 |
char(10):
最大字符长度10个,定长的字符串类型。处理速度快,在存储字符串时,立即分配10个字符长度的存储空间,如果存不满,空格填充。
varchar(10):
最大字符长度10个,变长的字符串类型。处理速度慢,在存储字符串时,自动判断字符长度,按需分配存储空间,额外占用1-2bytes存储字符长度。例如:人名。
enum('bj','tj','sh'):
枚举类型,适合于存储固定的值,可以很大程度的优化我们的索引结构。例如:城市, 性别。
SET('a', 'b', 'c', 'd')
集合,可设置的值为一个或多个成员的组合。
时间类型
| 类型 | 格式 | 示例 |
|---|---|---|
| DATE | YYYY-MM-DD(1000-01-01/9999-12-31) | 2020 |
| TIME | hh:mm:ss[.uuuuuu]('-838:59:59'/'838:59:59') | 00:00:00.000000 |
| DATETIME | YYYY-MM-DD hh:mm:ss[.uuuuuu] | 1000-01-01 00:00:00.000000 |
| TIMESTAMP | YYYY-MM-DD hh:mm:ss[.uuuuuu] | 1970-01-01 00:00:00.000000 |
| YEAR | YYYY(1901/2155) | 2020 |
DATETIME 8字节
范围为从 1000-01-01 00:00:00.000000 至 9999-12-31 23:59:59.999999。
TIMESTAMP 4字节 会受到时区的影响
1970-01-01 00:00:00.000000 至 2038-01-19 03:14:07.999999。
二进制类型
| 类 | 类型 | 说明 |
|---|---|---|
| 二进制 | BINARY | 类似于CHAR(固定长度)类型,但存储的是二进制字节字符串,而不是非二进制字符串 |
| 二进制 | VARBINARY | 类似于VARCHAR(可变长度)类型,但存储的是二进制字节字符串,而不是非二进制字符串 |
| BLOB | TINYBLOB | 最大长度为255个字节的BLOB列 |
| BLOB | BLOB | 最大长度为65,535个字节的BLOB列 |
| BLOB | MEDIUDMBLOB | 最大长度为16,777,215个字节的BLOB列 |
| BLOB | LONGBLOB | 最大长度为4,294,967,295个字节的BLOB列 |
JSON
5.7.8 版本新增 官方文档
类似 varchar,不能设置长度,可以是 NULL ,但不能有默认值。
SQL介绍
简介
结构化查询语言,在RMBMS中通用的一类语言,符号SQL89 SQL92 SQL99 等国际标准。
分类
-
DDL: Data Defination Language 数据定义语言
列如: CREATE,DROP,ALTER -
DML: Data Manipulation Language 数据操纵语言
列如: INSERT,DELETE,UPDATE -
DCL:Data Control Language 数据控制语言
列如: GRANT,REVOKE,COMMIT,ROLLBACK -
DQL:Data Query Language 数据查询语言
列如: SELECT
规范
-
在数据库中,SQL语句不区分大小写(建议用大写)
-
SQL语句可单行或多行书写,以
;结尾 -
关键词不能跨多行或简写
-
用空格和缩进来提高语句的可读性
-
子句通常位于独立行,便于编辑,提高可读性
-
注释:
-
MySQL注释:
#注释内容 -
SQL标准:
-
多行注释
/*注释内容*/ -
单行注释
-- 注释内容
-
-
SQL语句构成
Keyword组成clause,多条clause组成语句
SELECT * # SELECT子句
FROM products # FROM子句
WHERE price>400 # WHERE子句
DDL
库定义
- 创建
-- CREATE DATABASE 库名 CHARSET 字符集 COLLATE 排序规则;
-- 创建一个数据库
CREATE DATABASE wordpress;
-- 创建一个数据库并指定字符集
CREATE DATABASE wordpress CHARSET utf8;
-- 创建一个数据库并指定字符集和排序规则
CREATE DATABASE wordpress CHARSET utf8 COLLATE utf8_bin;
-- CREATE SCHEMA 库名;
-- 创建模式(数据库对象的集合)在MySQL中等同于创建数据库
CREATE SCHEMA wordpress;
- 删除(生产中禁止使用)
-- DROP DATABASE 库名;
DROP DATABASE wordpress;
- 修改
-- ALTER DATABASE 库名 CHARSET 字符集;
ALTER DATABASE wordpress CHARSET utf8mb4;
注意:修改字符集,修改后的字符集一定是原字符集的严格超集,只影响之后存入的数据,修改前存入的数据还是原字符集编码方式,可能乱码
- 查询库相关信息(DQL)
-- 查看所有数据库名
SHOW DATABASES;
-- 查看建库标准语句
SHOW CREATE DATABASE 库名;
-- 查看字符集
SHOW CHARSET;
-- 查看排序规则
SHOW COLLATION;
表定义
- 创建
CREATE TABLE 表名(
列名 列属性
)表属性
CREATE TABLE 表名(
列名1 属性(数据类型、约束、其他属性),
列名2 属性,
列名3 属性
)数据引擎、字符集、注释
-- 列属性(修饰符)
PRIMARY KEY : 主键约束,表中只能有一个,非空且唯一。如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一。
NOT NULL : 非空约束,不允许空值
UNIQUE KEY : 唯一键约束,不允许重复值
DEFAULT : 默认值,当插入数据时如果未主动设置,则自动添加默认值。一般配合 NOT NULL 一起使用.
UNSIGNED : 无符号,一般是配合数字列,非负数
COMMENT : 注释
AUTO_INCREMENT : 自增列,插入数据时无需设置此列,默认将自增(表中只能有一个自增列),注意:必须是索引(含主键)。可以设置步长和起始值。
CHARACTER SET name : 指定一个字符集
USE test;
CREATE TABLE stu(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(64) NOT NULL COMMENT '姓名',
age TINYINT UNSIGNED NOT NULL DEFAULT 99 COMMENT '年龄',
gender ENUM('M','F','N') NOT NULL DEFAULT 'N' COMMENT '性别' ,
telnum CHAR(15) NOT NULL DEFAULT 0 COMMENT '电话',
intime TIMESTAMP NOT NULL DEFAULT NOW() COMMENT '入学时间'
) ENGINE=INNODB CHARSET=utf8 COMMENT '学生表';
-- 克隆一个空表
CREATE TABLE 新表名 LIKE 原表名;
-- 复制一个和原表除表名外完全一样的新表
CREATE TABLE 新表名 SELECT * FROM 原表名;
- 删除(生产中禁止使用)
-- 删表
DROP TABLE 表名;
-- 删列
ALTER TABLE 表名 DROP 列名;
-- 删主键
ALTER TABLE 表名 DROP primary key;
-- 删默认值
ALTER TABLE 表名 ALTER 列名 DROP DEFAULT;
-- 删外键
ALTER TABLE 表名 DROP foreign key 外键名;
- 修改
-- 修改默认值
ALTER TABLE stu ALTER sname SET DEFAULT 1000;
-- 添加外键
ALTER TABLE 从表名 add constraint 外键名(形如:FK_从表_主表) foreign key 从表的外键字段 references 主表的主键字段;
-- ALTER TABLE 表名 ADD 列名 属性 位置;
-- 在stu表中添加addr列, 默认添加到最后
ALTER TABLE stu ADD COLUMN addr VARCHAR(100) NOT NULL COMMENT '地址';
-- 在sname后加wechat列
ALTER TABLE stu ADD wechat VARCHAR(64) NOT NULL UNIQUE COMMENT '微信号' AFTER sname;
-- 在最前添加num列
ALTER TABLE stu ADD num INT NOT NULL COMMENT '数字' FIRST;
注意:8.0 之前,不要在业务繁忙时进行DDL操作,需要申请元数据锁,可能会全局夯住
-- ALTER TABLE 表名 MODIFY 列名 属性;
-- 修改sname数据类型的属性
ALTER TABLE stu MODIFY sname VARCHAR(128) NOT NULL COMMENT 'xm';
-- ALTER TABLE 表名 CHANGE 原列名 新列名 属性;
-- 修改sname列名改为sn, 数据类型改为CHAR
ALTER TABLE stu CHANGE sname sn CHAR(8) NOT NULL DEFAULT 'n';
注意:不要在业务繁忙时操作,修改数据类型影响更大
- 表属性查询(DQL)
-- 查看数据库所有表名①
USE 库名;
SHOW TABLES;
-- 查看数据库所有表名②
SHOW TABLES FROM 库名;
-- 查看表结构①
DESC 表名;
-- 查看表结构②
SHOW COLUMNS FROM 表名;
-- 查看建表语句
SHOW CREATE TABLE 表名;
DDL规范
库规范
- 禁止线上业务系统出现DROP操作
- 库名:不能有大写字母(Linux区分大小写),不能是关键字,不能重名,不能有数字开头,要和业务相关
- 建库建库是显示的设置字符集
表规范
- 表名小写字母,不能有数字开头和大写字母,不能是关键字,不能重名,要和业务相关,建议格式:wp_user
- 显式的设置存储引擎和字符集和表的注释
- 每个表必须要有主键,是数字的 自增的 无关的
- 列名要和业务相关
- 每个列要有注释,设置为非空,无法保证非空,填充默认值,对于数据填充0,对于字符填充有效字符串
- 列的数据类型,讲究:完整 简短 合适
- 变长列一般选择varchar类型,定长列一般选择char类型
- 精度不高的浮点数,放大N倍到整数
- 大字段,可以选择附件形式或ES数据库
- 8.0版本后,Online-DDL除了追加列,添加删除索引外,其他操作,请在数据库低谷时间点去做,如果很紧急,请使用pt-osc或者gh-ost
- enum类型不要使用数字作为枚举值(容易混淆值和索引),只能是字符串类型;
DCL
数据控制语言,权限管理
grant
revoke
DML
作用:对表中的数据行进行增、删、改
INSERT
-- INSERT INTO 表名(列名,列名...) VALUES (值,值...),(值,值...);
-- 标准
INSERT INTO stu(id,sn,age,gender,addr,intime)
VALUES (1,'zs',18,'M','bj',NOW());
-- 简写
INSERT INTO stu
VALUES (1,'zs',18,'M','bj',NOW());
-- 针对性的录入数据
INSERT INTO stu(sn,addr)
VALUES ('w1','bj');
-- 同时录入多行数据
INSERT INTO stu(sn,addr)
VALUES
('w1','bj'),
('w2','bj'),
('w3','bj');
-- 查看表所有内容
SELECT * FROM stu;
-- 将 stu 表所有内容复制到 student 表内,两张表格结构必须一致
insert student select * from stu;
UPDATE
-- UPDATE 表名 SET 列名x=值 WHERE 列N 操作符 条件;
-- 更新指定行
UPDATE stu SET sn='w4' WHERE id=2;
-- 更新所有行
UPDATE stu SET sn='w4';
注意:实际生产中,UPDATE必须加WHERE条件,防止误更新,配置UPDATE不加WHERE条件报错
- 立即生效,重连生效,重启失效
mysql> show variables like '%safe%'; +----------------------------------+-------+ | Variable_name | Value | +----------------------------------+-------+ | log_statements_unsafe_for_binlog | ON | | sql_safe_updates | OFF | +----------------------------------+-------+ 2 rows in set (0.00 sec) mysql> set sql_safe_updates=1; Query OK, 0 rows affected (0.00 sec) mysql> set global sql_safe_updates=1; Query OK, 0 rows affected (0.00 sec) mysql> show variables like '%safe%'; +----------------------------------+-------+ | Variable_name | Value | +----------------------------------+-------+ | log_statements_unsafe_for_binlog | ON | | sql_safe_updates | ON | +----------------------------------+-------+ 2 rows in set (0.00 sec) mysql> use test; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> UPDATE stu SET sname='w4'; ERROR 1175 (HY000): You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column.
- 永久生效
sed -i '/[mysqld]/a sql_safe_updates=1' /etc/my.cnf
DELETE(生产中禁止使用)
-- 删除指定行
DELETE FROM 表名 WHERE 列名x=值;
-- 清空表内容
DELETE FROM 表名;
TRUNCATE TABLE 表名;
-- 删除表
Drop TABLE 表名;
删除表区别:
| 操作 | 范围 | 表现 | 介绍 |
|---|---|---|---|
| DELETE FROM 表名; | 全表数据 | 新插入行自增id断节 | DML操作,逻辑性质删除,逐行"删除"(只是打一个标记)表中每行数据,速度慢,不会立即释放磁盘,HWM(高水位线)没有降低 |
| TRUNCATE TABLE 表名; | 全表数据 | 新插入行自增id从1开始 | DDL操作,整表所有数据全部删除,清空数据页,立即释放磁盘空间,速度快,不记入日志 |
| Drop TABLE 表名; | 全表数据 + 表定义 | 表没了 | 立即释放磁盘空间 |
伪删除:用update来替代delete,最终保证业务中查(select)不到即可
-- 1. 添加状态列
ALTER TABLE stu ADD state TINYINT NOT NULL DEFAULT 1 COMMENT '状态:1为存在;0为不存在';
-- 2. 使用 UPDATE 替代 DELETE
UPDATE stu SET state=0 WHERE id=1;
-- 3. 业务查询语句
SELECT * FROM stu WHERE state=1;
DQL(select )
单独使用
-- select @@变量名;
-- 查询系统变量
SELECT @@port;
SELECT @@basedir;
SELECT @@datadir;
SELECT @@socket;
SELECT @@server_id;
-- SHOW VARIABLES LIKE '%关键字%';
-- 模糊查询
show variables like '%trx%';
-- select 函数();
-- 调用函数
SELECT NOW();
SELECT SYSDATE();
SELECT DATABASE();
SELECT USER();
SELECT CONCAT("hello world");
SELECT CONCAT(USER,"@",HOST) FROM mysql.user;
SELECT GROUP_CONCAT(USER,"@",HOST) FROM mysql.user;
关闭没用/高占用线程
mysql> use information_schema;
mysql> select * from processlist;
mysql> select * from processlist where command='sleep'G
*************************** 1. row ***************************
ID: 8
USER: root
HOST: 10.0.0.1:6610
DB: information_schema
COMMAND: Sleep
TIME: 105
STATE:
INFO: NULL
1 row in set (0.00 sec)
mysql> kill 10;
标准 SELECT 单表语法
select 列
from 表
where 列 操作符 条件
group by 列
having 列 操作符 条件
order by 列
limit 行;
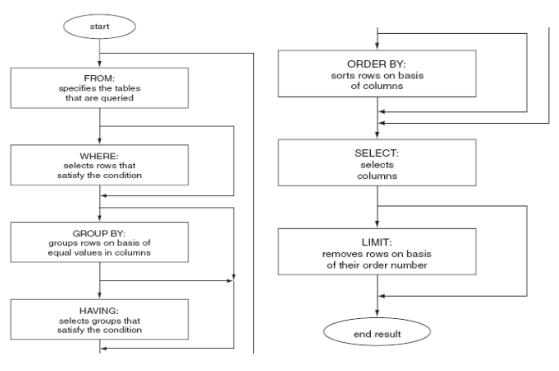
FROM
SELECT 列名1,列名2 FROM 表名;
SELECT * FROM 表名;
-- select + from
-- 查询表中所有的数据(不要对大表进行操作)
SELECT * FROM city;
-- 查询表中部分数据
SELECT `Name`,`Population` FROM city;
WHERE
SELECT 列1,列2,... FROM 表名 WHERE 列N 操作符 条件;
-- select + from + where
-- where + 等值查询
-- 查询中国(CHN)所有城市信息
SELECT * FROM city WHERE `CountryCode`='CHN';
-- 查询中国(CHN)所有城市名称和人口
SELECT `Name`,`Population` FROM city WHERE `CountryCode`='CHN';
-- 查询北京市的信息
SELECT * FROM city WHERE NAME='peking';
-- 查询甘肃省所有城市信息
SELECT * FROM city WHERE district='gansu';
比较操作符
-- where + 比较操作符(< > <= >= !=)
-- 查询世界上少于100人的城市信息
SELECT * FROM city WHERE `Population`<100;
逻辑运算符
-- where + 逻辑运算符
-- 查询中国人口数大于500万的城市信息
SELECT * FROM city WHERE `CountryCode`='CHN' AND `Population`>5000000;
-- 查询中国或美国的城市信息
SELECT * FROM city WHERE `CountryCode`='CHN' OR `CountryCode`='USA';
BETWEEN AND
-- where + between and
-- 查询世界上人口数在100万到200万之间的城市信息
SELECT * FROM city WHERE `Population` BETWEEN 1000000 AND 2000000;
SELECT * FROM city WHERE `Population`>='1000000' AND `Population`<='2000000';
IN 和 NOT IN
-- IN (val1,val2,…) 离散值显示
-- where + in
-- 查询中国或美国的城市信息
SELECT * FROM city WHERE `CountryCode` IN ('CHN' ,'USA');
SELECT * FROM city WHERE `CountryCode`='CHN' OR `CountryCode`='USA';
-- where + not in
-- 查询除了中国或美国外的其他所有城市信息
SELECT * FROM city WHERE `CountryCode` NOT IN ('CHN' ,'USA');
NOT IN 不走索引
LIKE 和 RLIKE 和 REGEXP
LIKE:常用通配符:
-
%:匹配0个或任意多个字符。 -
_:匹配任意一个字符。 -
escape:转义字符,可匹配%和_。-
例如: SELECT * FROM table_name WHERE column_name LIKE '/%/_%_' ESCAPE'/'
-
RLIKE和REGEXP:常用通配符:
.:匹配任意单个字符。*:匹配0个或多个前一个得到的字符[]:匹配任意一个[]内的字符,[ab]*可匹配空串、a、b、或者由任意个a和b组成的字符串。^:匹配开头,如^s匹配以s或者S开头的字符串。$:匹配结尾,如s$匹配以s结尾的字符串。{n}:匹配前一个字符n次。
注意:
- 在MySQL中,
LIKE、RLIKE和REGEXP都不区分大小写,如果需要区分,可以在WHERE后添加关键字段binary。- LIKE是完全匹配。
RLIKE和REGEXP是不完全匹配,只要不同时匹配^和$, 其他的包含即可。例如:^ba可以匹配baaa和baab,a也可以匹配baaa和baab,但是^bab$不能匹配baab。%不能放在最前面,因为不走索引。RLIKE支持正则表达式,但影响服务器性能,尽量不要用,最好精确匹配。
-- WHERE + LIKE 模糊查询
-- 查询国家代号是C开头的城市信息
SELECT * FROM city WHERE `CountryCode` LIKE 'C%';
SELECT * FROM city WHERE `CountryCode` LIKE 'C__';
IS NULL 和 IS NOT NULL
判断字段的值是否为空值(NULL)。空值不同于 0,也不同于空字符串。
注意:IS NULL 是一个整体,如果将 IS 换成=将不能查询出任何结果,数据库系统会出现“Empty set(0.00 sec)”这样的提示。同理,IS NOT NULL 中的 IS NOT 不能换成!=或<>。
-- WHERE + IS NULL
-- 查询国家代号为空的城市信息
SELECT * FROM city WHERE CountryCode IS NULL;
-- WHERE + IS NOT NULL
-- 查询国家代号不为空的城市信息
SELECT * FROM city WHERE CountryCode IS NOT NULL;
GROUP BY + 聚合函数
作用:根据 GROUP BY 后面的条件进行分组,再使用聚合函数统计,BY 后面跟一个列或多个列
先分组(GROUP BY),后去重统计(count()),类似于shell的
cat FILENAME | sort | uniq -c注意:
- GROUP BY 必须在 where 之后,ORDER BY 之前
- GROUP BY 后面条件尽量使用主键,防止列值重复
- GROUP BY 多表连接查询可同时使用多表主键,防止列值重复
常用聚合函数:
max() :最大值
min() :最小值
avg() :平均值
sum() :总和
count() :个数
group_concat() :列转行
5.7版本后SQL92严格模式
sql_mode=ONLY_FULL_GROUP_BY使用 GROUP BY 时, SELECT后的列,要么是 GROUP BY 的条件或主键,要么是用聚合函数进行处理,否则报错:
Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'world.city.Name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
-- 统计世界上每个国家的总人口数
SELECT countrycode,SUM(population) FROM city GROUP BY countrycode;
-- 统计中国每个省的总人口数
SELECT district,SUM(Population) FROM city WHERE countrycode='CHN' GROUP BY district;
-- 统计中国每个省的城市数
SELECT district,COUNT(id) FROM city WHERE countrycode='CHN' GROUP BY district;
-- 统计中国每个省的城市个数,城市名列表
SELECT district,COUNT(id),GROUP_CONCAT(NAME) FROM city WHERE countrycode='CHN' GROUP BY district;
HAVING
作用:在 GROUP BY 后条件判断
尽量少用,不走索引,必须使用时,请在业务低谷期或从库或拿出来使用其他方式判断
-- 统计中国每个省的城市数,只打印城市数大于10的省
SELECT district,COUNT(id) FROM city WHERE countrycode='CHN'
GROUP BY district HAVING COUNT(id) > 10;
ORDER BY
作用:排序(默认升序)
-- 查看中国所有城市信息,并按人口数从小到大进行排序
SELECT * FROM city WHERE countrycode='CHN' ORDER BY population;
ASC 和 DESC
作用:升序和降序排序
-- 查看中国所有城市信息,并按人口数从大到小进行排序
SELECT * FROM city WHERE countrycode='CHN' ORDER BY population DESC;
-- 查看世界上所有城市的名称,代码,人口数,并按城市代码从小到大进行排序,如果城市代码相同则按人口数从大到小排序
SELECT `Name`,`CountryCode`,population
FROM city
ORDER BY `CountryCode` ASC, `Population` DESC;
LIMIT
作用:显示指定行数
-- 统计中国每个省的总人口数,找出总人口大于500w的,并按总人口从大到小排序,只显示前三名
SELECT district, SUM(population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 3;
OFFSET
作用:指定行数偏移
-- LIMIT N,M
-- LIMIT M OFFSET N;
-- 跳过 N ,显示一共 M 行
-- 统计中国每个省的总人口数,找出总人口大于500w的,并按总人口从大到小排序,显示6-10名
SELECT district, SUM(population) FROM city
WHERE countrycode='CHN'
GROUP BY district
HAVING SUM(population)>5000000
ORDER BY SUM(population) DESC
LIMIT 5,5;
DISTINCT
作用:去重
SELECT countrycode FROM city;
SELECT DISTINCT(countrycode) FROM city;
UNION 和 UNION ALL
作用:联合查询,取两个结果集的并集
- UNION 去重
- UNION ALL 不去重
-- 中国或美国城市信息
SELECT * FROM city
WHERE countrycode IN ('CHN' ,'USA');
SELECT * FROM city WHERE countrycode='CHN'
UNION ALL
SELECT * FROM city WHERE countrycode='USA';
将 IN 或 OR 语句改写成 UNION ALL,来提高性能
JOIN
作用:多表连接查询
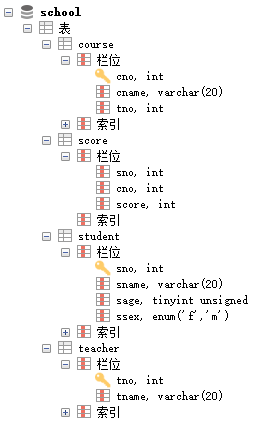
准备表
use school
student:学生表
sno: 学号
sname: 学生姓名
sage: 学生年龄
ssex: 学生性别
teacher:教师表
tno: 教师编号
tname: 教师名字
course: 课程表
cno: 课程编号
cname: 课程名字
tno: 教师编号
score: 成绩表
sno: 学号
cno: 课程编号
score: 成绩
-- 项目构建
DROP DATABASE school;
CREATE DATABASE school CHARSET utf8;
USE school;
CREATE TABLE student(
sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(20) NOT NULL COMMENT '学生姓名',
sage TINYINT UNSIGNED NOT NULL COMMENT '学生年龄',
ssex ENUM('f','m') NOT NULL DEFAULT 'm' COMMENT '学生性别'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE teacher(
tno INT NOT NULL PRIMARY KEY COMMENT '教师编号',
tname VARCHAR(20) NOT NULL COMMENT '教师名字'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE course(
cno INT NOT NULL PRIMARY KEY COMMENT '课程编号',
cname VARCHAR(20) NOT NULL COMMENT '课程名字',
tno INT NOT NULL COMMENT '教师编号'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE score(
sno INT NOT NULL COMMENT '学号',
cno INT NOT NULL COMMENT '课程编号',
score INT NOT NULL DEFAULT 0 COMMENT '成绩'
)ENGINE=INNODB CHARSET=utf8;
INSERT INTO student
VALUES
(1,'zhang3',18,'m'),
(2,'zhang4',18,'m'),
(3,'li4',18,'m'),
(4,'wang5',19,'f'),
(5,'zh4',18,'m'),
(6,'zhao4',18,'m'),
(7,'ma6',19,'f'),
(8, 'oldboy', 20, 'm'),
(9, 'oldgirl', 20, 'f'),
(10, 'oldp', 25, 'm');
INSERT INTO teacher VALUES
(101,'oldboy'),
(102,'hesw'),
(103,'oldguo'),
(104, 'oldx'),
(105, 'oldw');
INSERT INTO course VALUES
(1001,'linux',101),
(1002,'python',102),
(1003,'mysql',103),
(1004, 'k8s', 108);
INSERT INTO score VALUES
(1,1001,80),
(1,1002,59),
(2,1002,90),
(2,1003,100),
(3,1001,99),
(3,1003,40),
(4,1001,79),
(4,1002,61),
(4,1003,99),
(5,1003,40),
(6,1001,89),
(6,1003,77),
(7,1001,67),
(7,1003,82),
(8,1001,70),
(9,1003,80),
(10,1003,96);
SELECT * FROM student;
SELECT * FROM teacher;
SELECT * FROM course;
SELECT * FROM score;
内连接
SELECT 列名 FROM 表名1 JOIN 表名2 ON 相关条件
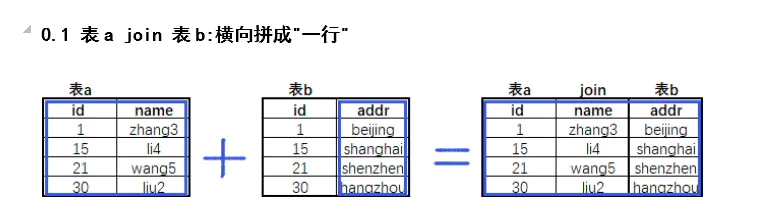
-- 查询张三的家庭住址
SELECT A.name,B.address
FROM A
JOIN B
ON A.id=B.id
WHERE A.name='zhangsan';
编写方法
-
分析题意, 找出所需相关表
A B -
选择数据行少的表为驱动表, 找到以上表的直接或间接关联列(尽量是主键或唯一键)
FROM A JOIN B ON A.id=B.id -
可执行测试关联表是否正确
SELECT * FROM A JOIN B ON A.id=B.id; -
添加你要查询的列条件, 可执行测试
SELECT * FROM A JOIN B ON A.id=B.id WHERE A.name='zhangsan'; -
添加要显示的列, 可执行测试
SELECT A.name,B.address FROM A JOIN B ON A.id=B.id WHERE A.name='zhangsan';
示例
-- 统计每个学生平均成绩
SELECT student.sname,AVG(score.score)
FROM student JOIN score ON student.sno=score.sno
GROUP BY student.sno;
-- 每位学生学习的课程门数
SELECT student.sname,COUNT(score.score)
FROM student
JOIN score
ON student.sno=score.sno
GROUP BY student.sno;
-- 每位老师所教的课程门数
SELECT teacher.tname,COUNT(course.cname)
FROM teacher JOIN course ON teacher.tno=course.tno
GROUP BY teacher.tno;
-- 每位老师所教的课程门数和名称
SELECT teacher.tname,COUNT(course.cname),GROUP_CONCAT(course.cname)
FROM teacher JOIN course ON teacher.tno=course.tno
GROUP BY teacher.tno;
-- 每位学生学习的课程门数和名称
SELECT student.sname,COUNT(course.cname),GROUP_CONCAT(course.cname)
FROM student JOIN score ON student.sno=score.sno
JOIN course ON score.cno=course.cno
GROUP BY student.sno;
-- 统计zhang3学习了几门课
SELECT student.sname , COUNT(score.cno)
FROM student JOIN score ON student.sno=score.sno
WHERE student.sname='zhang3';
-- 查询zhang3,学习的课程名称有哪些?
SELECT student.sname, GROUP_CONCAT(course.cname)
FROM student JOIN score ON student.sno=score.sno
JOIN course ON score.cno=course.cno
WHERE student.sname='zhang3'
GROUP BY student.sno;
-- 查询oldguo老师教的学生名.
SELECT teacher.tname, GROUP_CONCAT(student.sname)
FROM teacher JOIN course ON teacher.tno=course.tno
JOIN score ON course.cno=score.cno
JOIN student ON score.sno=student.sno
WHERE teacher.tname='oldguo'
GROUP BY teacher.tno;
-- 查询oldguo所教课程的平均分数
SELECT teacher.tname,AVG(score.score)
FROM teacher JOIN course ON teacher.tno=course.tno
JOIN score ON course.cno=score.cno
WHERE teacher.tname='oldguo'
GROUP BY teacher.tno;
-- 每位老师所教课程的平均分,并按平均分排序
SELECT teacher.tname,AVG(score.score)
FROM teacher JOIN course ON teacher.tno=course.tno
JOIN score ON course.cno=score.cno
GROUP BY teacher.tno, course.cno ORDER BY AVG(score.score);
-- 查询oldguo所教的不及格的学生姓名
SELECT teacher.tname, GROUP_CONCAT(student.sname)
FROM teacher JOIN course ON teacher.tno=course.tno
JOIN score ON course.cno=score.cno
JOIN student ON score.sno=student.sno
WHERE teacher.tname='oldguo' AND score.score<60
GROUP BY teacher.tno;
-- 查询所有老师所教学生不及格的信息
SELECT teacher.tname, GROUP_CONCAT(student.sname)
FROM teacher JOIN course ON teacher.tno=course.tno
JOIN score ON course.cno=score.cno
JOIN student ON score.sno=student.sno
WHERE score.score<60
GROUP BY teacher.tno;
-- 查询平均成绩大于60分的同学的学号和平均成绩;
SELECT student.sno, AVG(score.score)
FROM student JOIN score ON student.sno=score.sno
JOIN course ON score.cno=course.cno
GROUP BY student.sno
HAVING AVG(score.score)>60;
-- 查询平均成绩大于85的所有学生的学号、姓名和平均成绩
SELECT student.`sno`, student.`sname`, AVG(`score`.`score`)
FROM student JOIN score ON student.sno=score.sno
GROUP BY student.sno
HAVING AVG(`score`.`score`)>85;
-- 查询所有同学的学号、姓名、选课数、总成绩;
SELECT student.sno, student.sname, COUNT(*),SUM(score.score)
FROM student JOIN score ON student.sno=score.sno
JOIN course ON score.cno=course.cno
GROUP BY student.sno;
-- 查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分
SELECT score.cno AS '课程ID', MAX(`score`.`score`) AS '最高分', MIN(`score`.`score`) AS '最低分'
FROM score GROUP BY score.cno;
-- 查询每门课程被选修的学生数
SELECT course.cname, COUNT(score.sno) AS '学生数'
FROM course JOIN score ON course.cno=score.cno
GROUP BY course.cno;
-- 查询只选修了一门课程的全部学生的学号和姓名
SELECT student.sno, student.sname
FROM student JOIN score ON student.sno=score.sno
GROUP BY student.sno
HAVING COUNT(score.cno)=1;
-- 查询选修课程门数超过1门的学生信息
SELECT student.sno, student.sname, COUNT(*) AS '选修课程门数'
FROM student JOIN score ON student.`sno`=score.`sno`
GROUP BY student.sno
HAVING COUNT(*)>1;
-- 查询每门课程被选修的学生的学号和姓名
SELECT course.cname, GROUP_CONCAT(CONCAT(student.sno,":",student.sname)) AS '学号:姓名'
FROM course JOIN score ON course.cno=score.cno
JOIN student ON score.sno=student.sno
GROUP BY course.cno
左连接
左外连接又称为左连接,使用 LEFT OUTER JOIN 关键字连接两个表,并使用 ON 子句来设置连接条件。
语法:
SELECT 列名 FROM 表名1 LEFT JOIN 表名2 ON 相关条件
“表名1”为驱动表,“表名2”为参考表。查询时,可以查询出“表1”中的所有记录和“表2”中匹配连接条件的记录,没有为空值(NULL)。
-- tb_students_info 表中的数据
mysql> SELECT * FROM tb_students_info;
+----+--------+------+------+--------+-----------+
| id | name | age | sex | height | course_id |
+----+--------+------+------+--------+-----------+
| 1 | Dany | 25 | 男 | 160 | 1 |
| 2 | Green | 23 | 男 | 158 | 2 |
| 3 | Henry | 23 | 女 | 185 | 1 |
| 4 | Jane | 22 | 男 | 162 | 3 |
| 5 | Jim | 24 | 女 | 175 | 2 |
| 6 | John | 21 | 女 | 172 | 4 |
| 7 | Lily | 22 | 男 | 165 | 4 |
| 8 | Susan | 23 | 男 | 170 | 5 |
| 9 | Thomas | 22 | 女 | 178 | 5 |
| 10 | Tom | 23 | 女 | 165 | 5 |
| 11 | LiMing | 22 | 男 | 180 | 7 |
+----+--------+------+------+--------+-----------+
11 rows in set (0.00 sec)
-- tb_course 表中的数据
mysql> SELECT * FROM tb_course;
+----+-------------+
| id | course_name |
+----+-------------+
| 1 | Java |
| 2 | MySQL |
| 3 | Python |
| 4 | Go |
| 5 | C++ |
| 6 | HTML |
+----+-------------+
6 rows in set (0.00 sec)
-- 左外连接查询所有课程,包括没有学生的课程
mysql> SELECT s.name,c.course_name FROM tb_students_info s LEFT OUTER JOIN tb_course c ON s.course_id=c.id;
+--------+-------------+
| name | course_name |
+--------+-------------+
| Dany | Java |
| Henry | Java |
| Green | MySQL |
| Jim | MySQL |
| Jane | Python |
| John | Go |
| Lily | Go |
| Susan | C++ |
| Thomas | C++ |
| Tom | C++ |
| LiMing | NULL |
+--------+-------------+
11 rows in set (0.00 sec)
右连接
右外连接又称为右连接,右连接是左连接的反向连接。使用 RIGHT OUTER JOIN 关键字连接两个表,并使用 ON 子句来设置连接条件。
语法:
SELECT 列名 FROM 表名1 RIGHT JOIN 表名2 ON 相关条件
“表2”为驱动表,“表1”为参考表。查询时,可以查询出“表2”中的所有记录和“表1”中匹配连接条件的记录,没有为空值(NULL)。
-- 右外连接查询所有课程,包括没有学生的课程
mysql> SELECT s.name,c.course_name FROM tb_students_info s RIGHT OUTER JOIN tb_course c ON s.course_id=c.id;
+--------+-------------+
| name | course_name |
+--------+-------------+
| Dany | Java |
| Green | MySQL |
| Henry | Java |
| Jane | Python |
| Jim | MySQL |
| John | Go |
| Lily | Go |
| Susan | C++ |
| Thomas | C++ |
| Tom | C++ |
| NULL | HTML |
+--------+-------------+
11 rows in set (0.00 sec)
多个表左/右连接时,在 ON 子句后连续使用 LEFT/RIGHT OUTER JOIN 或 LEFT/RIGHT JOIN 即可。
在where后的列都有索引时,使用小结果集(
SELECT COUNT(*) FROM 表名 WHERE 条件;)的表驱动大表,优化器通常会自动判断查询语句在的谁作为驱动表更合适,有时可能出现选择错误,此时我们可以使用左(右)外连接强制指定驱动表干预执行计划,最终结果由压测决定。
子查询
查询语句嵌套查询语句,基于某语句的查询结果再次进行的查询,性能较差,尽量不要使用,改为多表连接查询。
-
用在WHERE子句中的子查询
- 比较表达式中的子查询:子查询仅能返回单个值
SELECT Name,Age FROM students WHERE Age>(SELECT avg(Age)FROM students);IN | NOT IN:子查询应该单键查询并返回一个或多个值从构成列表
SELECT Name,Age FROM students WHERE Age IN (SELECT Age FROM teachers);EXISTS | NOT EXISTS运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
SELECT column_name(s) FROM table_name WHERE EXISTS (SELECT column_name FROM table_name WHERE condition); -
用在FROM子句中的子查询
SELECT s.aage,s.ClassID FROM (SELECT avg(Age) AS aage,ClassID FROM students WHERE ClassID IS NOT NULL GROUP BY ClassID) AS s WHERE s.aage>30;
注意事项:
子查询语句可以嵌套在 SQL 语句中任何表达式出现的位置
只出现在子查询中,而没有出现在父查询中的表,不能包含在输出列中
AS
作用:设置表别名,列别名,AS可选
- 表别名定义后处处都可以被调用
SELECT中设置的列别名, 可以在HAVING和ORDER BY中被调用
-- 查询世界上人口数量小于100人的城市名和国家名
SELECT b.name ,a.name ,a.population
FROM city AS a
JOIN country AS b
ON b.code=a.countrycode
WHERE a.Population<100;
-- 查询城市shenyang,城市人口,所在国家名(name)及国土面积(SurfaceArea)
SELECT a.name cityname,
a.population pp,
b.name country,
b.SurfaceArea sa
FROM city a
JOIN country b
ON a.countrycode=b.code
WHERE a.name='shenyang';
CASE
-
简单函数:
枚举
case_expression字段所有可能的值。
CASE [case_expression] WHEN [when_expression_1] THEN [commands]… ELSE [default] END
case_expression可以是任何有效的表达式。
将case_expression的值与每个WHEN子句中的when_expression进行比较,例如when_expression_1,when_expression_2等。如果case_expression和when_expression_n的值相等,则执行相应的WHEN分支中THEN的命令commands,否则ELSE子句中的命令将被执行。如果省略ELSE子句,并且找不到匹配项,MySQL将引发错误。
SELECT
NAME '英雄',
CASE NAME
WHEN '德莱文' THEN
'斧子'
WHEN '德玛西亚-盖伦' THEN
'大宝剑'
WHEN '暗夜猎手-VN' THEN
'弩'
ELSE
'无'
END '装备'
FROM
user_info;
-
搜索函数
可以写判断,只会返回第一个符合条件的值,其他case被忽略。
CASE WHEN [condition_1 ] THEN [commands]… ELSE [default] END
MySQL评估求值WHEN子句中的每个条件,直到找到一个值为TRUE的条件,然后执行THEN子句中的相应命令(commands)。
如果没有一个条件为TRUE,则执行ELSE子句中的命令(commands)。如果省略ELSE子句,并且没有一个条件为TRUE,MySQL将引发错误。
不允许在THEN或ELSE子句中使用空命令。 如果您不想处理ELSE子句中的逻辑,同时又要防止MySQL引发错误,则可以在ELSE子句中放置一个空的BEGIN END块。
# when 表达式中可以使用 and 连接条件
SELECT
NAME '英雄',
age '年龄',
CASE
WHEN age < 18 THEN
'少年'
WHEN age < 30 THEN
'青年'
WHEN age >= 30 AND age < 50 THEN
'中年'
ELSE
'老年'
END '状态'
FROM
user_info;
-- 统计各位老师,所教课程的及格率
SELECT teacher.tname,
COUNT(
CASE WHEN score.score>60
THEN 1
END
)/COUNT(*) AS '及格率'
FROM teacher JOIN course ON teacher.tno=course.tno
JOIN score ON course.cno=score.cno
GROUP BY teacher.tno;
-- 统计每门课程:优秀(85分以上),良好(70-85),一般(60-70),不及格(小于60)的学生列表
SELECT course.cname,
GROUP_CONCAT(
CASE WHEN score.score>85
THEN student.sname
END
) AS '优秀(85分以上)',
GROUP_CONCAT(
CASE WHEN score.score BETWEEN 70 AND 85
THEN student.sname
END
) AS '良好(70-85)',
GROUP_CONCAT(
CASE WHEN score.score BETWEEN 60 AND 70
THEN student.sname
END
) AS '一般(60-70)',
GROUP_CONCAT(
CASE WHEN score.score<60
THEN student.sname
END
) AS '不及格(小于60)'
FROM student JOIN score ON student.sno=score.sno
JOIN course ON score.cno=course.cno
GROUP BY course.cno
元数据
MySQL8.0 之前 InnoDB 元数据是存储在ibdata(系统)和.frm(每表)文件中
MySQL8.0 之后 InnoDB 元数据是存储在mysql.ibd文件中
- 通过专用的DDL语句,DCL语句进行修改
SHOW命令是封装好功能,提供元数据查询基础功能
- 通过专用视图和命令进行元数据的查询
- information_schema 库中保存了大量元数据查询的视图,而不是实际的表,所以也没有对应的ibd文件
SHOW
SHOW databases; 查看所有数据库名
SHOW TABLES; 查看当前库的所有表名
SHOW TABLES FROM 库名; 查看某个指定库下的表
SHOW create database 库名; 查看建库语句
SHOW create table 表名; 查看建表语句
SHOW processlist; 查看所有数据库用户连接情况
SHOW charset; 查看支持的字符集
SHOW collation; 查看所有支持的校对规则
SHOW privileges; 查看支持的权限
SHOW grants for 用户@host; 查看用户权限信息
SHOW VARIABLES; 查看所有参数信息
SHOW variables like '%lock%'; 模糊查询参数信息
SHOW engines; 查看支持的存储引擎类型
SHOW index from 表名; 查看表的索引信息
SHOW engine innodb statusG 查看innoDB引擎详细状态信息
SHOW binary logs; 查看二进制日志的列表信息
SHOW binlog events in '' 查看二进制日志的事件信息
SHOW master status; 查看二进制日志位置点(主库状态信息)
SHOW slave statusG 查看从库状态信息
SHOW slave hosts; 查看从库地址
SHOW RELAYLOG EVENTS in '' 查看中继日志的事件信息
SHOW STATUS; 查看数据库状态
SHOW STATUS like ''; 查看数据库整体状态信息
SHOW STATUS LIKE '%lock%'; 模糊查询数据库某些状态
SHOW plugins; 查看插件信息
mysql> status
--------------
mysql Ver 8.0.20 for Linux on x86_64 (MySQL Community Server - GPL)
Connection id: 11
Current database:
Current user: root@localhost
SSL: Not in use
Current pager: stdout
Using outfile: ''
Using delimiter: ;
Server version: 8.0.20 MySQL Community Server - GPL
Protocol version: 10
Connection: Localhost via UNIX socket
Server characterset: utf8mb4
Db characterset: utf8mb4
Client characterset: utf8mb4
Conn. characterset: utf8mb4
UNIX socket: /tmp/mysql.sock
Binary data as: Hexadecimal
Uptime: 2 days 21 hours 31 min 38 sec
Threads: 2 Questions: 291 Slow queries: 0 Opens: 246 Flush tables: 3 Open tables: 162 Queries per second avg: 0.001
--------------
information_schema
查看视图信息
mysql > SHOW information_schema.TABLES;
mysql > DESC information_schema.TABLES;
TABLE_SCHEMA 表所在的库名
TABLE_NAME 表名
ENGINE 存储引擎
TABLE_ROWS 表的行数(粗略统计)
AVG_ROW_LENGTH 表中平均行长度(字节)(粗略统计)
INDEX_LENGTH 索引长度(字节)(粗略统计)
DATA_FREE 碎片数量
TABLE_COMMENT 表注释
mysql> DESC COLUMNS;
TABLE_SCHEMA 表所在的库名
TABLE_NAME 表名
COLUMN_NAME 列名
DATA_TYPE 数据类型
COLUMN_KEY 索引
COLUMN_COMMENT
示例
-- 统计所有库,显示库名,表个数和表名
SELECT table_schema, COUNT(*), GROUP_CONCAT(table_name)
FROM information_schema.TABLES
GROUP BY table_schema;
-- 统计world下的city表占用空间大小
-- 表的数据量=平均行长度*行数+索引长度
-- AVG_ROW_LENGTHTABLE_ROWS+INDEX_LENGTH
SELECT table_name,(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)/1024
FROM information_schema.TABLES
WHERE table_schema='world' AND table_name='city';
-- 统计world库数据量总大小
SELECT table_schema,SUM((AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH))/1024
FROM information_schema.TABLES
WHERE table_schema='world';
-- 统计每个库的数据量大小(粗略统计),并按数据量从大到小排序
SELECT table_schema,SUM((AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH))/1024 AS total_KB
FROM information_schema.TABLES
GROUP BY table_schema
ORDER BY total_KB DESC ;
-- 查询所有innodb引擎的表
SELECT table_schema,table_name ,ENGINE
FROM information_schema.tables
WHERE ENGINE='innodb';
-- 查询所有业务数据库中,非innodb引擎的表
SELECT table_schema,table_name,ENGINE
FROM information_schema.TABLES
WHERE table_schema
NOT IN ('mysql','sys','information_schema','performance_schema')
AND ENGINE<>'innodb';
CONCAT() 字符串拼接
语法
CONCAT(str1,str2,…)
返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。
示例
SELECT CONCAT(USER,";",HOST) FROM mysql.`user`;
-- 创建非innodb引擎的表
CREATE TABLE t1 (i INT) ENGINE=MYISAM;
-- 查询所有业务数据库中,非innodb引擎的表,生成批量替换为innodb引擎的SQL语句
SELECT CONCAT("ALTER TABLE ", table_schema, ".", table_name, " ENGINE=innodb")
FROM information_schema.TABLES
WHERE table_schema
NOT IN ('mysql','sys','information_schema','performance_schema')
AND ENGINE<>'innodb';
-- 模仿以下语句,批量生成数据库分库分表备份shell语句
mysqldump -uroot -p123 world city >/bak/world_city.sql
SELECT CONCAT("mysqldump -uroot -p123 ",table_schema," ", table_name, " > /bak/",table_schema,"_",table_name,".sql")
FROM information_schema.tables;
-- 模仿以下语句,批量生成对world库下所有表进行操作
ALTER TABLE world.city DISCARD TABLESPACE;
SELECT CONCAT("ALTER TABLE ",table_schema,".",table_name," DISCARD TABLESPACE;")
FROM information_schema.tables
WHERE table_schema='world';
INTO OUTFILE
将表的内容导出成一个文本文件,目标文件不能是一个已经存在的文件
SELECT 列名 FROM table [WHERE 语句] INTO OUTFILE '目标文件'[OPTIONS]
[OPTIONS] 为可选参数选项,语法包括 FIELDS 和 LINES 子句,常用取值:
FIELDS TERMINATED BY '字符串':设置字符串为字段之间的分隔符,可以为单个或多个字符,默认情况下为制表符‘ ’。FIELDS [OPTIONALLY] ENCLOSED BY '字符':设置字符来括上 CHAR、VARCHAR 和 TEXT 等字符型字段。如果使用了 OPTIONALLY 则只能用来括上 CHAR 和 VARCHAR 等字符型字段。FIELDS ESCAPED BY '字符':设置如何写入或读取特殊字符,只能为单个字符,即设置转义字符,默认值为。LINES STARTING BY '字符串':设置每行开头的字符,可以为单个或多个字符,默认情况下不使用任何字符。LINES TERMINATED BY '字符串':设置每行结尾的字符,可以为单个或多个字符,默认值为
注意:FIELDS 和 LINES 两个子句都是自选的,但是如果两个都被指定了,FIELDS 必须位于 LINES的前面。
-- 查询所有业务数据库中,非innodb引擎的表,生成批量替换为innodb引擎的SQL语句
SELECT CONCAT("ALTER TABLE ", table_schema, ".", table_name, " ENGINE=innodb")
FROM information_schema.TABLES
WHERE table_schema
NOT IN ('mysql','sys','information_schema','performance_schema')
AND ENGINE<>'innodb' INTO OUTFILE '/tmp/alter.sql';
报错:
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement处理:
sed -i '/[mysqld]/a secure-file-priv=/tmp' /etc/my.cnf systemctl restart mysqld
MySQL 运算符
本章节我们主要介绍 MySQL 的运算符及运算符的优先级。 MySQL 主要有以下几种运算符:
- 算术运算符
- 比较运算符
- 逻辑运算符
- 位运算符
算术运算符
MySQL 支持的算术运算符包括:
| 运算符 | 作用 |
|---|---|
| + | 加法 |
| - | 减法 |
| * | 乘法 |
| / 或 DIV | 除法 |
| % 或 MOD | 取余 |
在除法运算和模运算中,如果除数为0,将是非法除数,返回结果为NULL。
1、加
mysql> select 1+2;
+-----+
| 1+2 |
+-----+
| 3 |
+-----+
2、减
mysql> select 1-2;
+-----+
| 1-2 |
+-----+
| -1 |
+-----+
3、乘
mysql> select 2*3;
+-----+
| 2*3 |
+-----+
| 6 |
+-----+
4、除
mysql> select 2/3;
+--------+
| 2/3 |
+--------+
| 0.6667 |
+--------+
5、商
mysql> select 10 DIV 4;
+----------+
| 10 DIV 4 |
+----------+
| 2 |
+----------+
6、取余
mysql> select 10 MOD 4;
+----------+
| 10 MOD 4 |
+----------+
| 2 |
+----------+
比较运算符
SELECT 语句中的条件语句经常要使用比较运算符。通过这些比较运算符,可以判断表中的哪些记录是符合条件的。比较结果为真,则返回 1,为假则返回 0,比较结果不确定则返回 NULL。
| 符号 | 描述 | 备注 |
|---|---|---|
| = | 等于 | |
| <>, != | 不等于 | |
| > | 大于 | |
| < | 小于 | |
| <= | 小于等于 | |
| >= | 大于等于 | |
| BETWEEN | 在两值之间 | >=min&&<=max |
| NOT BETWEEN | 不在两值之间 | |
| IN | 在集合中 | |
| NOT IN | 不在集合中 | |
| <=> | 严格比较两个NULL值是否相等 | 两个操作码均为NULL时,其所得值为1;而当一个操作码为NULL时,其所得值为0 |
| LIKE | 模糊匹配 | |
| REGEXP 或 RLIKE | 正则式匹配 | |
| IS NULL | 为空 | |
| IS NOT NULL | 不为空 |
1、等于
mysql> select 2=3;
+-----+
| 2=3 |
+-----+
| 0 |
+-----+
mysql> select NULL = NULL;
+-------------+
| NULL = NULL |
+-------------+
| NULL |
+-------------+
2、不等于
mysql> select 2<>3;
+------+
| 2<>3 |
+------+
| 1 |
+------+
3、安全等于
与 = 的区别在于当两个操作码均为 NULL 时,其所得值为 1 而不为 NULL,而当一个操作码为 NULL 时,其所得值为 0而不为 NULL。
mysql> select 2<=>3;
+-------+
| 2<=>3 |
+-------+
| 0 |
+-------+
mysql> select null=null;
+-----------+
| null=null |
+-----------+
| NULL |
+-----------+
mysql> select null<=>null;
+-------------+
| null<=>null |
+-------------+
| 1 |
+-------------+
4、小于
mysql> select 2<3;
+-----+
| 2<3 |
+-----+
| 1 |
+-----+
5、小于等于
mysql> select 2<=3;
+------+
| 2<=3 |
+------+
| 1 |
+------+
6、大于
mysql> select 2>3;
+-----+
| 2>3 |
+-----+
| 0 |
+-----+
7、大于等于
mysql> select 2>=3;
+------+
| 2>=3 |
+------+
| 0 |
+------+
8、BETWEEN
mysql> select 5 between 1 and 10;
+--------------------+
| 5 between 1 and 10 |
+--------------------+
| 1 |
+--------------------+
9、IN
mysql> select 5 in (1,2,3,4,5);
+------------------+
| 5 in (1,2,3,4,5) |
+------------------+
| 1 |
+------------------+
10、NOT IN
mysql> select 5 not in (1,2,3,4,5);
+----------------------+
| 5 not in (1,2,3,4,5) |
+----------------------+
| 0 |
+----------------------+
11、IS NULL
mysql> select null is NULL;
+--------------+
| null is NULL |
+--------------+
| 1 |
+--------------+
mysql> select 'a' is NULL;
+-------------+
| 'a' is NULL |
+-------------+
| 0 |
+-------------+
12、IS NOT NULL
mysql> select null IS NOT NULL;
+------------------+
| null IS NOT NULL |
+------------------+
| 0 |
+------------------+
mysql> select 'a' IS NOT NULL;
+-----------------+
| 'a' IS NOT NULL |
+-----------------+
| 1 |
+-----------------+
13、LIKE
mysql> select '12345' like '12%';
+--------------------+
| '12345' like '12%' |
+--------------------+
| 1 |
+--------------------+
mysql> select '12345' like '12_';
+--------------------+
| '12345' like '12_' |
+--------------------+
| 0 |
+--------------------+
14、REGEXP
mysql> select 'beijing' REGEXP 'jing';
+-------------------------+
| 'beijing' REGEXP 'jing' |
+-------------------------+
| 1 |
+-------------------------+
mysql> select 'beijing' REGEXP 'xi';
+-----------------------+
| 'beijing' REGEXP 'xi' |
+-----------------------+
| 0 |
+-----------------------+
逻辑运算符
逻辑运算符用来判断表达式的真假。如果表达式是真,结果返回 1。如果表达式是假,结果返回 0。
| 运算符号 | 作用 |
|---|---|
| NOT 或 ! | 逻辑非 |
| AND | 逻辑与 |
| OR | 逻辑或 |
| XOR | 逻辑异或 |
1、与
mysql> select 2 and 0;
+---------+
| 2 and 0 |
+---------+
| 0 |
+---------+
mysql> select 2 and 1;
+---------+
| 2 and 1 |
+---------+
| 1 |
+---------+
2、或
mysql> select 2 or 0;
+--------+
| 2 or 0 |
+--------+
| 1 |
+--------+
mysql> select 2 or 1;
+--------+
| 2 or 1 |
+--------+
| 1 |
+--------+
mysql> select 0 or 0;
+--------+
| 0 or 0 |
+--------+
| 0 |
+--------+
mysql> select 1 || 0;
+--------+
| 1 || 0 |
+--------+
| 1 |
+--------+
3、非
mysql> select not 1;
+-------+
| not 1 |
+-------+
| 0 |
+-------+
mysql> select !0;
+----+
| !0 |
+----+
| 1 |
+----+
4、异或
mysql> select 1 xor 1;
+---------+
| 1 xor 1 |
+---------+
| 0 |
+---------+
mysql> select 0 xor 0;
+---------+
| 0 xor 0 |
+---------+
| 0 |
+---------+
mysql> select 1 xor 0;
+---------+
| 1 xor 0 |
+---------+
| 1 |
+---------+
mysql> select null or 1;
+-----------+
| null or 1 |
+-----------+
| 1 |
+-----------+
mysql> select 1 ^ 0;
+-------+
| 1 ^ 0 |
+-------+
| 1 |
+-------+
位运算符
位运算符是在二进制数上进行计算的运算符。位运算会先将操作数变成二进制数,进行位运算。然后再将计算结果从二进制数变回十进制数。
| 运算符号 | 作用 |
|---|---|
| & | 按位与 |
| | | 按位或 |
| ^ | 按位异或 |
| ! | 取反 |
| << | 左移 |
| >> | 右移 |
1、按位与
mysql> select 3&5;
+-----+
| 3&5 |
+-----+
| 1 |
+-----+
2、按位或
mysql> select 3|5;
+-----+
| 3|5 |
+-----+
| 7 |
+-----+
3、按位异或
mysql> select 3^5;
+-----+
| 3^5 |
+-----+
| 6 |
+-----+
4、按位取反
mysql> select ~18446744073709551612;
+-----------------------+
| ~18446744073709551612 |
+-----------------------+
| 3 |
+-----------------------+
5、按位右移
mysql> select 3>>1;
+------+
| 3>>1 |
+------+
| 1 |
+------+
6、按位左移
mysql> select 3<<1;
+------+
| 3<<1 |
+------+
| 6 |
+------+
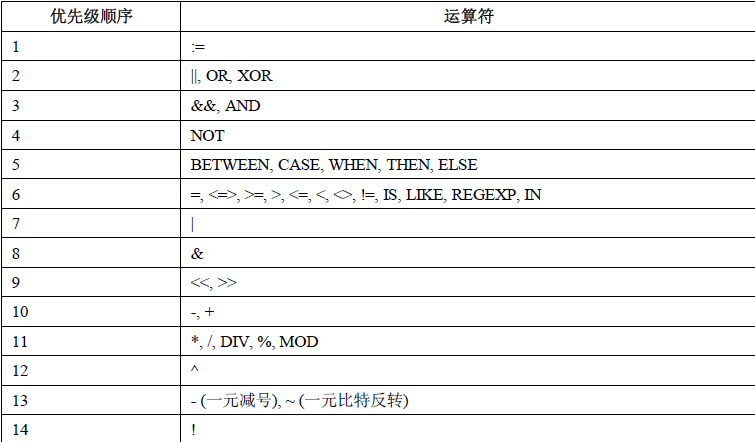
运算符优先级
最低优先级为: :=。
最高优先级为: !、BINARY、 COLLATE。