总述
三周的时间一晃而过,也到了和表达式说再见的时候了。想起来,现在已经能够优雅地在互测“攻击”别人,然后笑对被别人“攻击”,就觉得OO这三周还是很有意义,也多多少少改变了我。周六已经快习惯早上背着包,找个自习室做题,然后晚上回宿舍,和同学交流。三周的三次作业强度一次都比一次大,但我个人而言,觉得尚且还能够适应,可能是课下时间充足所以会不是很紧张。反正一句话,再遇见表达式计算,咱不怂。最后关于解题思路,值得一提的是,由于自身惰性,和题目内容的偶然性,最终三次作业的解题思路从大方向上而言是一样的:因子级处理,先处理乘号再处理加号(不使用表达式树之类的,就是简单的判断一下优先级---遇见加法存进结果并更新缓存,遇见乘法添加进缓存)
第一次作业
写第一次作业的时候,关于OO就是个小白啊,又加上第一次作业难度不大,所以我只是简单的建了一个Node类(事后发现大家都是Poly,感觉数据结构之后就只会Node了.....),如下是第一次作业的类图。

当时的解题思路很简单,觉得一个通用的Node应该能够表示完几种因子类型(事实上讲,也确实可以)。但是现在回过头来看,Node类要做的事情太多了,程序的主功能“qd”求导也封装在Node里面了,这使得如果程序的主体功能全部依赖于Node类。这对数据保护不是很友好,一旦后期有对功能需求有所修改,则必将影响Node类内部其他属性和方法,但事实上Node类作为一个因子类,其本身的内容应当是随因子变换而变换而非是内容。
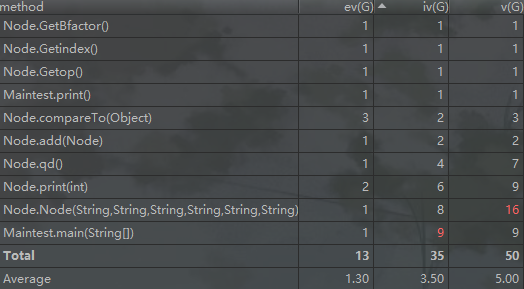
上图是相关的类方法复杂度分析,从里面可以发现,Node本身的构造方法的设计复杂度和实际复杂度都很高。我个人认为这是因为我需要用一个Node去匹配所有的因子情况所造成的。大量的参数其实本身就是一种设计不良的体现。不过还是由于懒等原因,当时并没有决定去进一步地优化设计。从这里也可以看出Node类作为一个因子类其实有一些"勉强"了,现在觉得最好的可行方法就是Nqde类作为父类,然后新建各个因子自己的子类,这样解决可能要好一些。
第二次作业
第二次作业相较之第一次作业多了三角函数,实际上只是多了一个因子类而已,所以当时我觉得(现在也是)解题大方向不需要有什么变换,只是在输入上下一些功夫,写一个新的pattern能够匹配出三角函数这个因子,并对Node类进行修改,使得其能够支持三角函数。说到这里又不得不说,其实在第二次作业的时候,我就察觉到Node类有些臃肿,可是由于舍不得(懒)还是决定复用结构,所以我的第二次作业类图就成了这个样子:

由上面的类图可以基本看出,Node1与第一次的Node在方法上并没有太多的换,在属性上多出了关于三角函数相关的属性。至于Poly2这个类似与第一次作业的Maintest,相当于Main。最大的变换还是在于把求导方法给挪到了Main里面,算是一个初步的功能与数据的分离吧。下面是相关的类方法复杂度分析:
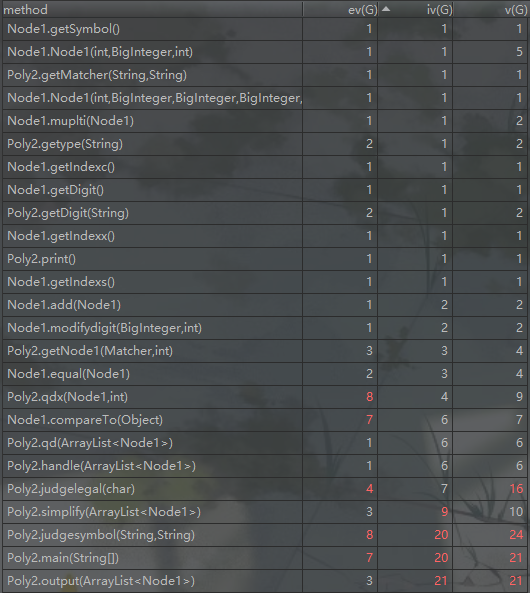
从类方法复杂度来看,judgesymbol、main、output、simplify个方法的复杂度比较高。main方法的复杂度主要是由于我没有封装输入,所以基本所有的输入提前任务全都是由main负责了,所以其复杂度较高。对于judgesymbol而言,这一直是我三次作业的一个bug点,因为符号判断实际上是一个很重要的WF点,同时这个符号判断也是非常灵活、变式非常多的一个点。由于我在正则表达式上的设计存在缺陷(偷懒了),所以这让我在符号判断的时候相当难受,大量的if判断让我都觉得尴尬,有此复杂度不意外。至于simplify和output的复杂,我觉得是合理的(相对于我的设计思路而言),许多不同的因子,他们的输出其实不尽相同,这就要求output有强大的适应力。至于simplify的复杂,这是显而易见的。
第三次作业

如果你细心地看完了,前面所有的内容,到这里肯定会感慨:居然不是Node3?终于把各个因子类都分割出来了吗?。在做第三次作业的时候,我实在是忍无可忍,终于决定重新构建我的整个代码结构而不采用复用第二次作业的现有框架(其实要复用的话难度也挺大的)。当重新把整体结构重构优化之后,我发现这个过程其实并不复杂,反而非常省心,所以这次可谓是用亲身经历去实践了一个好的思路和框架是能让许多事情都简单起来的。以下是相关类方法的复杂度分析

不难发现,Main类中的SpecialPattern、isPoly和getItem方法在复杂度上都比较高。是设计的问题吗?设计的问题肯定有的,但是我觉得主要是它们要承担的功能太过复杂才是主要因素。SpecialPattern是个格式提取的方法、其内封装了表达式因子和非标准三角函数的三角函数的格式提取。isPoly是对于表达式因子和非标准三角函数的三角函数的WF判断。getItem是对求导结果的获取,也就是说, 对输入的参数,返回求导的结果,它内部的复杂性主要是其内部调用了基本所有的主要功能函数。
总结
OO搞我啊。每次我在看到新发的作业指导书之后,总是喜欢这么说。但是我也喜欢讲,其实OO没那么难的,真的。
希望能够在OO上面收获一段难忘的编程回忆,也希望互测的时候手下留情(苦笑)。