
人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
引言
最近小编工作比较忙,每天能拿来写内容的时间都比较短。
刚更新完成的 urllib 基础内容太干了,跟牛肉干一样,咬着牙疼。

今天稍微空一点,决定好好放浪一下形骸,写点不正经的内容。

目标准备
看了标题各位同学应该知道小编今天要干啥了,没毛病,小编要掏出自己多年的珍藏分享给大家。

首先,我们要确定自己的目标,我们本次实战的目标网站是:https://www.mzitu.com/ 。
随便找张图给大家感受下:

小编要是上班看这个,估计是要被老板吊起来打的。
如果是进来找网址的,可以直接出去了,下面的内容已经无关紧要。
抓取分析
先使用 Chrome 浏览器打开网站 https://www.mzitu.com/ ,按 F12 打开开发者工具,查看网页的源代码:
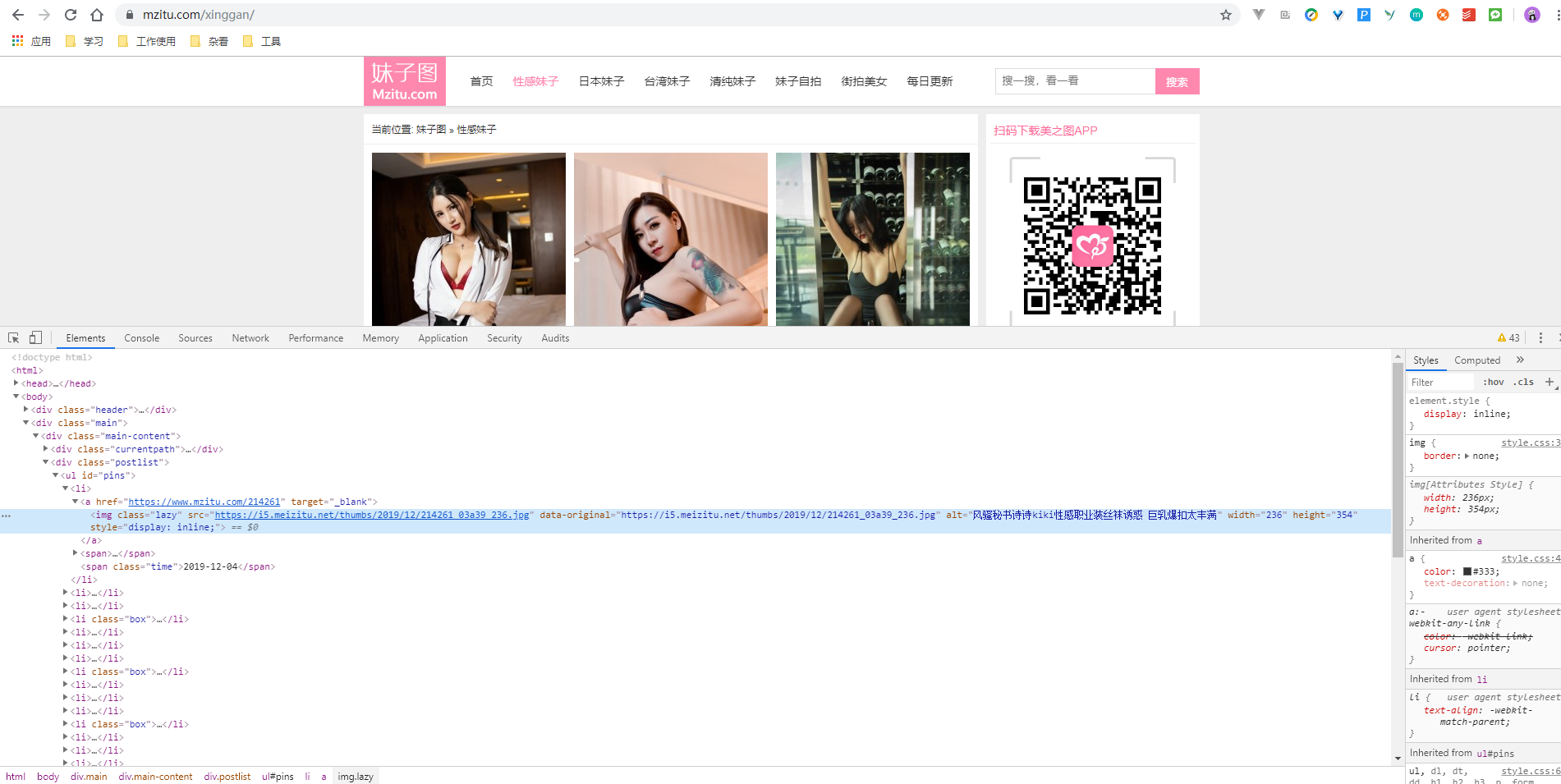
可以看到,这里是一个 a 标签包裹了一个 img 标签,这里图片的显示是来源于 img 标签,而点击后的跳转则是来源于 a 标签。
将页面滚动到最下方,看到分页组件,点击下一页,我们观察页面 URL 的变化。
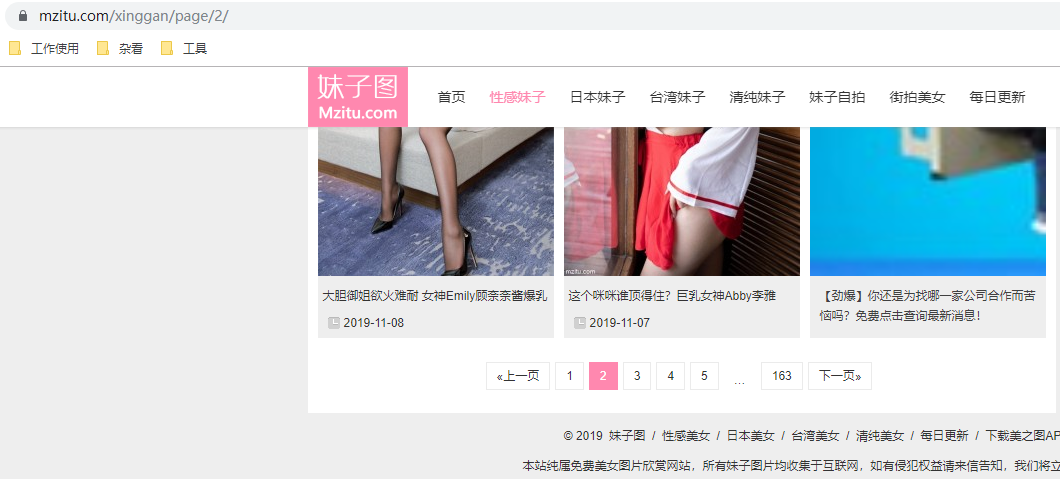
可以发现,页面 URL 变化成为 https://www.mzitu.com/xinggan/page/2/ ,多翻几页,发现只是后面的数字在增加。
当前页面上的图片只是缩略图,明显不是我们想要的图片,随便点击一个图片,进入内层页面:https://www.mzitu.com/214337/ ,可以发现,这里图片才是我们需要的图片:
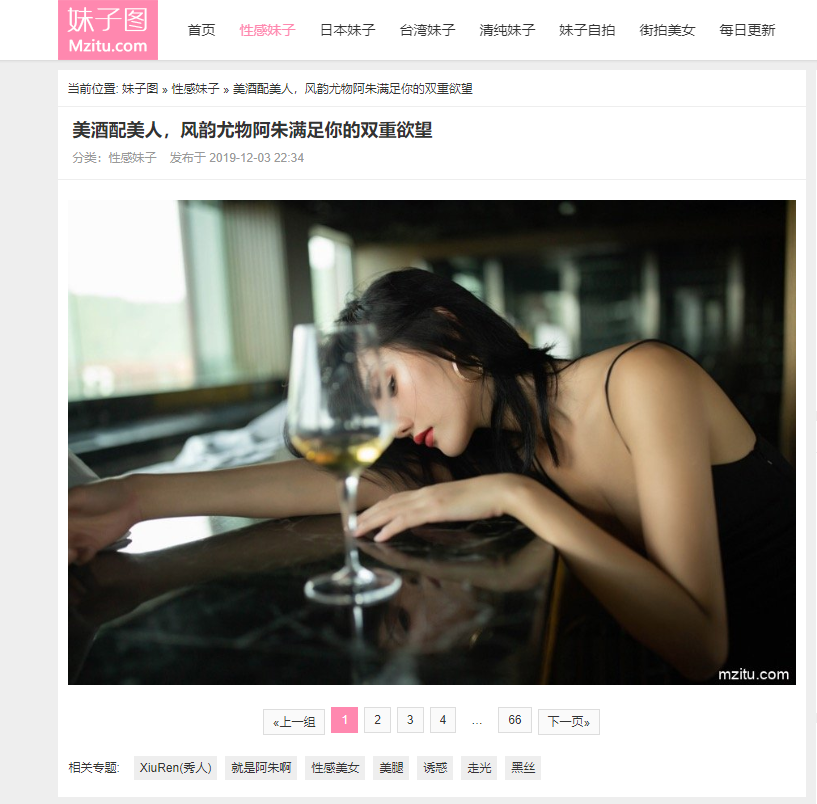
和前面的套路一样,我们往下翻几页,可以发现 URL 的变化规律。
URL 由第一页的 https://www.mzitu.com/214337/ 变化成为 https://www.mzitu.com/214337/2 ,同样是最后一位的数字增加,尝试当前页面最大值 66 ,发现依然可以正常打开,如果变为 67 ,则可以看到当前页面的标题已经显示为 404 (页面无法找到)。
爬取首页
上面我们找到了页面变化的规律,那么我们肯定是要从首页开始爬取数据。
接下来我们开始用代码实现这个过程,使用的请求类库为 Python 自带的 urllib ,页面信息提取采用 xpath 方式,类库使用 lxml 。
关于 xpath 和 lxml 是什么东西,小编后续会慢慢讲,感兴趣的同学可以先行百度学习。
下面我们开始写代码。
首先是构建请求头:
# 请求头添加 UA
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'referer': 'https://www.mzitu.com/'
}
# 保存路径
save_path = 'D:\spider_file'
如果不加请求头 UA,会被拒绝访问,直接返回 403 状态码,在获取图片的时候,如果不加 referer ,则会被认为是盗链,同样也无法获取图片。
保存路径小编这里保存在本地的 D 盘的 spider_file 这个目录中。
接下来增加一个创建文件夹的方法:
import os
# 创建文件夹
def createFile(file_path):
if os.path.exists(file_path) is False:
os.makedirs(file_path)
# 切换路径至上面创建的文件夹
os.chdir(file_path)
这里需要引入 os 模块。
然后是重头戏,抓取首页数据并进行解析:
import urllib.request
from lxml import etree
# 抓取外页数据
def get_outer(outer_url):
req = urllib.request.Request(url=outer_url, headers=headers, method='GET')
resp = urllib.request.urlopen(req)
html = etree.HTML(resp.read().decode('utf-8'))
# 获取文件夹名称列表
title_list = html.xpath('//*[@id="pins"]/li/a/img/@alt')
# 获取跳转链接列表
src_list = html.xpath('//*[@id="pins"]/li/a/@href')
print('当前页面' + outer_url + ', 共计爬取' + str(len(title_list)) + '个文件夹')
for i in range(len(title_list)):
file_path = save_path + '\' + title_list[i]
img_url = src_list[i]
# 创建对应文件夹
createFile(file_path)
# 写入对应文件
get_inner(img_url, file_path)
具体每行代码是做什么,小编就不一一详细介绍了,注释已经写得比较清楚了。
爬取内页
我们爬取完外页的信息后,需要通过外页提供的信息来爬取内页的数据,这也是我们真正想要爬取的数据,具体的爬取思路已经在上面讲过了,这里直接贴代码:
import urllib.request
import os
from lxml import etree
import time
# 抓取内页数据并写入文件
def get_inner(url, file_path):
req = urllib.request.Request(url=url, headers=headers, method='GET')
resp = urllib.request.urlopen(req)
html = etree.HTML(resp.read().decode('utf-8'))
# 获取当前页面最大页数
max_num = html.xpath('/html/body/div[2]/div[1]/div[4]/a[5]/span/text()')[0]
print('当前页面url:', url, ', 最大页数为', max_num)
for i in range(1, int(max_num)):
# 访问过快会被限制,增加睡眠时间
time.sleep(1)
inner_url = url + '/' + str(i)
inner_req = urllib.request.Request(url=inner_url, headers=headers, method='GET')
inner_resp = urllib.request.urlopen(inner_req)
inner_html = etree.HTML(inner_resp.read().decode('utf-8'))
# 获取图片 url
img_src = inner_html.xpath('/html/body/div[2]/div[1]/div[3]/p/a/img/@src')[0]
file_name = str(img_src).split('/')[-1]
# 下载图片
try:
request = urllib.request.Request(url=img_src, headers=headers, method='GET')
response = urllib.request.urlopen(request)
get_img = response.read()
file_os_path = file_path + '\' + file_name
if os.path.isfile(file_os_path):
print('图片已存在:', file_os_path)
pass
else:
with open(file_os_path, 'wb') as fp:
fp.write(get_img)
print('图片保存成功:', file_os_path)
fp.close()
except Exception as e:
print('图片保存失败')
因为该网站对访问速度有限制,所以小编在这里增加了程序的睡眠时间,这只是一种解决方案,还可以使用代理的方式突破限制,稳定高速代理都挺贵的,小编还是慢一点慢慢爬比较省钱。
整合代码
整体的代码到这一步,主体框架逻辑已经完全确定了,只需要对代码做一个大致简单的整理即可,所以,完整的代码如下:
import urllib.request
import os
from lxml import etree
import time
# 请求头添加 UA
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'referer': 'https://www.mzitu.com/'
}
# 保存路径
save_path = 'D:\spider_file'
# 创建文件夹
def createFile(file_path):
if os.path.exists(file_path) is False:
os.makedirs(file_path)
# 切换路径至上面创建的文件夹
os.chdir(file_path)
# 抓取外页数据
def get_outer(outer_url):
req = urllib.request.Request(url=outer_url, headers=headers, method='GET')
resp = urllib.request.urlopen(req)
html = etree.HTML(resp.read().decode('utf-8'))
# 获取文件夹名称列表
title_list = html.xpath('//*[@id="pins"]/li/a/img/@alt')
# 获取跳转链接列表
src_list = html.xpath('//*[@id="pins"]/li/a/@href')
print('当前页面' + outer_url + ', 共计爬取' + str(len(title_list)) + '个文件夹')
for i in range(len(title_list)):
file_path = save_path + '\' + title_list[i]
img_url = src_list[i]
# 创建对应文件夹
createFile(file_path)
# 写入对应文件
get_inner(img_url, file_path)
# 抓取内页数据并写入文件
def get_inner(url, file_path):
req = urllib.request.Request(url=url, headers=headers, method='GET')
resp = urllib.request.urlopen(req)
html = etree.HTML(resp.read().decode('utf-8'))
# 获取当前页面最大页数
max_num = html.xpath('/html/body/div[2]/div[1]/div[4]/a[5]/span/text()')[0]
print('当前页面url:', url, ', 最大页数为', max_num)
for i in range(1, int(max_num)):
# 访问过快会被限制,增加睡眠时间
time.sleep(1)
inner_url = url + '/' + str(i)
inner_req = urllib.request.Request(url=inner_url, headers=headers, method='GET')
inner_resp = urllib.request.urlopen(inner_req)
inner_html = etree.HTML(inner_resp.read().decode('utf-8'))
# 获取图片 url
img_src = inner_html.xpath('/html/body/div[2]/div[1]/div[3]/p/a/img/@src')[0]
file_name = str(img_src).split('/')[-1]
# 下载图片
try:
request = urllib.request.Request(url=img_src, headers=headers, method='GET')
response = urllib.request.urlopen(request)
get_img = response.read()
file_os_path = file_path + '\' + file_name
if os.path.isfile(file_os_path):
print('图片已存在:', file_os_path)
pass
else:
with open(file_os_path, 'wb') as fp:
fp.write(get_img)
print('图片保存成功:', file_os_path)
fp.close()
except Exception as e:
print('图片保存失败')
def main():
url = 'https://www.mzitu.com/xinggan/page/'
for i in range(1, 163):
get_outer(url + str(i))
if __name__ == '__main__':
main()
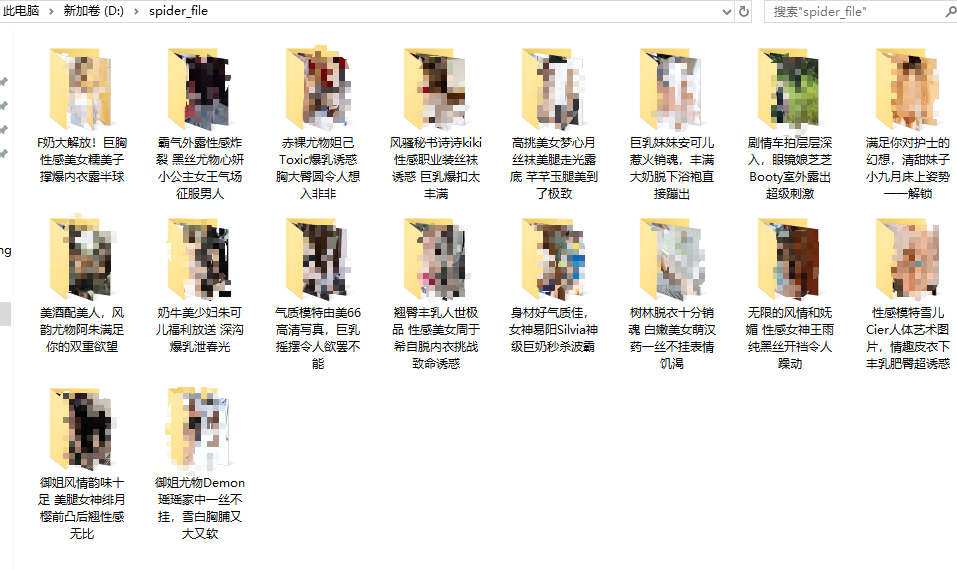
最后看一下小编大致用 20 分钟左右爬取的数据:
小结
做爬虫比较重要的部分是需要在网页上分析我们所需要提取的数据的数据来源,需要我们清晰的了解清楚页面的 URL 的具体变化,而这些变化一定是遵循某种规则的,找到这种规则就可以达成自动化的目的。
一些网站会对爬虫做一些防御,这些防御并不是完全无解的,其实就像矛和盾的故事。本次爬取数据的过程中遇到的防御方式有限制 ip 一定时间的访问次数,防止非本网站的请求请求图片(防盗链,referer 检测),以及 UA 头检测(防止非浏览器访问)。但是正所谓上有 x 策下有 x 策,防御并不是无解的,只是解决代价的大小而已。
小编这只爬虫还是希望能起到抛砖引玉的作用,希望大家能自己亲自动手试试看。
多动手才能学好代码哦~~~
示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。