
人生苦短,我选Python
前文传送门
绝对路径和相对路径
在介绍文件操作之前,我们先介绍两个概念,绝对路径和相对路径。
先百度下看下百度的解释:
- 绝对路径:是指目录下的绝对位置,直接到达目标位置,通常是从盘符开始的路径。完整的描述文件位置的路径就是绝对路径。
- 相对路径:相对路径就是指由这个文件所在的路径引起的跟其它文件(或文件夹)的路径关系。
不知各位同学看懂了没,没看懂我再举个栗子给各位加深下理解。
绝对路径
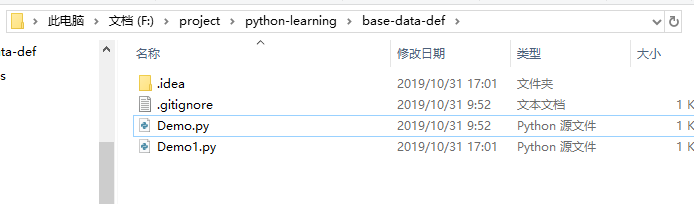
比如我们要描述 Demo.py 的绝对路径,那么就是: F:/project/python-learning/base-data-def/Demo.py 。
相对路径
相对路径是描述当前位置相对于目标位置的路径,比如当前我们存在的路径是 F:/project/python-learning/ ,我们还是要描述上面的那个 Demo.py ,那么它的相对路径是 ./base-data-def/Demo.py 。
打开文件
Python 为我们提供了打开文件的内置函数 open() 。
常用语法:
open(file, mode='r')
完整语法:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用 utf-8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
mode 参数常用值:
| 模式 | 描述 |
|---|---|
t |
文本模式 (默认)。 |
x |
写模式,新建一个文件,如果该文件已存在则会报错。 |
b |
二进制模式。 |
+ |
打开一个文件进行更新(可读可写)。 |
r |
以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
rb |
以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
r+ |
打开一个文件用于读写。文件指针将会放在文件的开头。 |
rb+ |
以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
w |
打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
wb |
以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
w+ |
打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
wb+ |
以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
a |
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
ab |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
a+ |
打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
ab+ |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
光说不练假把式,下面开启我们第一个示例:
str1 = open('F:/project/python-learning/base-data-def/Demo.py', mode='r').read()
print(str1)
打印结果我就不贴出来了,正常打印了我们前几篇文章的示例代码。
编码格式
根据编码格式的不同,可以将文件分为文本字符和二进制字节。
我们日常看到的都是文本字符,但是文本字符在保存计算机的时候都会转变成二进制字节,这时候,就要考虑到编码的问题了。
我们看下转换的示例图:
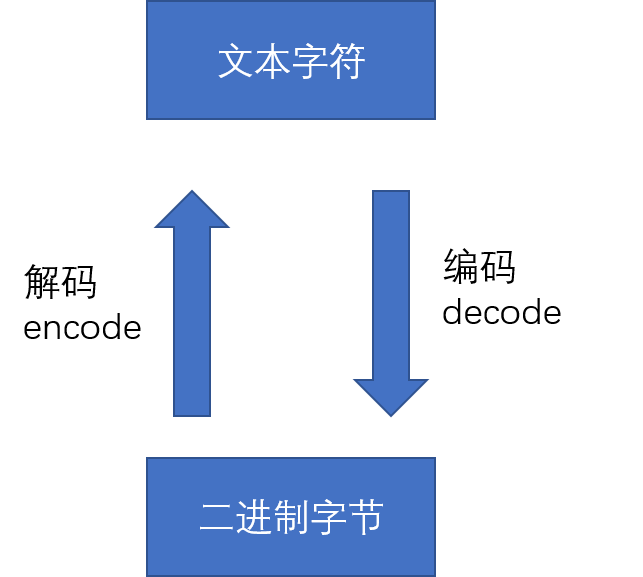
值得注意的是,在 Python3 中,文件默认的编码方式是 UTF-8 ,文本字符的常用的编码有 ASCII 和 Unicode 。
说了这么多,还是看一个示例代码吧:
str2 = '好好学习,天天向上'
print(type(str2))
a = str2.encode('utf-8')
print(type(a))
print(a.decode('utf-8'))
打印结果如下:
<class 'str'>
<class 'bytes'>
好好学习,天天向上
可以看到,我们将字符串 encode() 编码以后,类型变成了 byte 。
如果我们使用编码 gbk 的方式解码上面的 a 会怎么样呢?
print(a.decode('gbk'))
结果如下:
Traceback (most recent call last):
File "F:/project/python-learning/base-file/Demo.py", line 10, in <module>
print(a.decode('gbk'))
UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 26: incomplete multibyte sequence
告诉我们不能使用 gbk 来进行解码操作。
这个其实很好理解,好比我们将中文翻译成为了英文(编码),然后我们通过日文翻译想要将英文翻译回中文(解码),那么这个日文翻译肯定会骂你脑子有病。
OS 模块
前面我们介绍了通过内置函数来操作文件,我们还可以通过 OS 模块更简单的l哎操作文件。
OS 模块是和操作系统相关的模块。
为了演示,先建立一个 test.txt 文件。
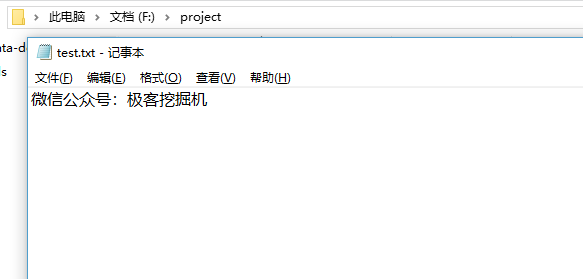
首先,我们打开这个文件:
import os
os.chdir('F:/project')
file = open('test.txt')
读取这个文件并打印:
print(file.read())
结果如下:
微信公众号:极客挖掘机
然后我们在下面再加一些内容:
file.write('关注公众号,好好学习,天天向上')
然后发现执行报错了:
Traceback (most recent call last):
File "F:/project/python-learning/base-file/Demo.py", line 17, in <module>
file.write('关注公众号,好好学习,天天向上')
io.UnsupportedOperation: not writable
从报错信息可以看出,是我们当前读取权限的问题,因为我们读取时是只读权限,无法写入,所以稍微修改下上面读取文件的代码:
import os
os.chdir('F:/project')
file = open('test.txt', mode='a+')
file.write('
关注公众号,好好学习,天天向上')
执行完成后我们再看下我们的测试文件:
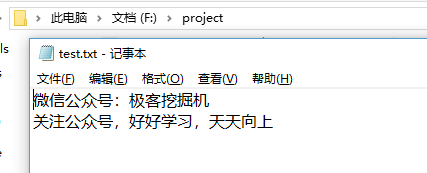
写入成功。
我们测试一个有意思的事情,如果同一个文件我们读取两次会怎么样?
import os
os.chdir('F:/project')
file = open('test.txt')
print(file.read())
print(file.read())
打印结果如下:
微信公众号:极客挖掘机
关注公众号,好好学习,天天向上
我们明明在代码中打印了两次,为什么只显示了一次呢?
因为 read() 读取所有内容,读取完后,游标是指在最后的,再往后读取肯定就读不到内容了。
好了,本篇的内容就到此为止了,希望各位同学能动手练习下示例代码。
示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。