推荐引擎所需要的数据源
- 要推荐物品或内容的元数据
- 系统用户的基本信息
- 用户对物品或者信息的偏好
- 显示的用户反馈
- 隐式的用户反馈

根据推荐引擎的数据源分为:
- 基于人口统计学的推荐 --- 根据用户的基本信息发现用户的相关度、

对每个用户都有一个用户 Profile 的建模
根据用户的基本信息,A和C是相似用户,可以成为邻居,基于“邻居”用户群的喜好推荐给当前用户一些物品
- 基于内容的推荐 --- 根据推荐物品或内容的元数据,发现物品或内容的相关性
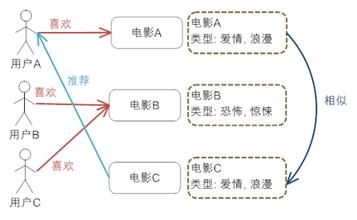
对电影的元数据有一个建模
电影A和C被认为是相似的,用户A喜欢电影A,那电影C也可以推荐给用户A
- 基于协同过滤
根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐
-
- 基于用户的
- 先使用统计技术寻找与目标用户有相同喜好的邻居,然后根据目标用户的邻居的喜好产生向目标用户的推荐
- 基于用户的
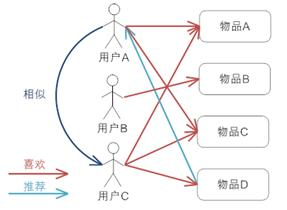
用户A喜欢A、C
用户B喜欢B
用户C喜欢A、C、D
所以用户A和C偏好类似,所以把D推荐给用户A
-
- 基于项目的
- 根据所有用户对物品或者信息的评价,发现物品和物品之间的相似度,然后根据用户的历史偏好信息将类似的物品推荐给该用户
- 基于项目的
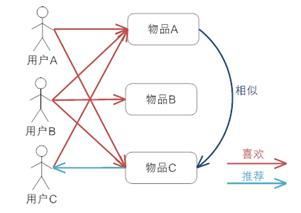
用户A喜欢A、C
用户B喜欢A、B、C
用户C喜欢A
物品A、C比较相似,喜欢A的应该喜欢C,所以,将C推荐给用户C
-
- 基于模型的
- 基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测推荐
- 基于模型的
参考:https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/index.html