0.Advertising数据集
Advertising数据集是关于广告收益与广告在不同的媒体上投放的相关数据,分别是在TV,Radio,Newspaper三种媒体上投放花费与,投放所产生的收益的数据,数据共有200条,数据的格式如下:
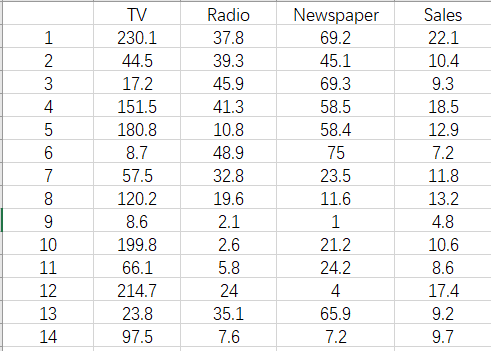
1.数据的载入
- 导入相关的包
1 import csv 2 import numpy as np 3 import matplotlib.pyplot as plt 4 import pandas as pd 5 from sklearn.model_selection import train_test_split 6 from sklearn.linear_model import LinearRegression
- 手写读取数据
1 path = 'Advertising.csv' 2 data = open(path) 3 f = open(path) 4 x = [] 5 y = [] 6 for i, d in enumerate(f): 7 if i == 0: 8 continue 9 d = d.strip() 10 if not d: 11 continue 12 d = list(map(float, d.split(','))) 13 x.append(d[1:-1]) 14 y.append(d[-1]) 15 print(x) 16 print(y) 17 x = np.array(x) 18 y = np.array(y)
- 文件路径表示
在python中,文件路径的表示有两种形式,既可以使用绝对路径,也可以使用相对路径。绝对路径为从盘符到文件所在目录的路径。相对路径即为相对于当前工作路径的位置,当前目录表示为: ./ ,当前目录的上一级目录表示为:../ 。在文件的路径表示时,python的当前工作路径是当前py文件所在的目录,并不是项目的根路径为当前工作路径,这一点区别与Java项目中的当前工作路径。所以在项目中表示文件路径需要注意这一点。
- enumerate()函数
enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。当参数是文件可迭代对象时,返回的i当前迭代的序号,d为第i行的数据,数据类型是字符串。
strip()函数为去除字符串首位的空格。
1 # Python自带库 2 f = file(path, 'rb') 3 d = csv.reader(f) 4 for line in d: 5 print line 6 f.close() 7 8 # numpy读入 9 p = np.loadtxt(path, delimiter=',', skiprows=1) 10 print(p) 11 12 # pandas读入 13 data = pd.read_csv(path) # TV、Radio、Newspaper、Sales 14 x = data[['TV', 'Radio', 'Newspaper']] 15 y = data['Sales']
np.loadtxt(path, delimiter=',', skiprows=1)函数,delimiter为指定数据的分割符,skiprows指定忽略读取的行数目。
2.绘制散点图分析相关性
1 plt.figure(figsize=(9,12)) 2 plt.subplot(311) 3 plt.plot(data['TV'], y, 'ro') 4 plt.title('TV') 5 plt.grid() 6 plt.subplot(312) 7 plt.plot(data['Radio'], y, 'g^') 8 plt.title('Radio') 9 plt.grid() 10 plt.subplot(313) 11 plt.plot(data['Newspaper'], y, 'b*') 12 plt.title('Newspaper') 13 plt.grid() 14 plt.tight_layout() 15 plt.show()
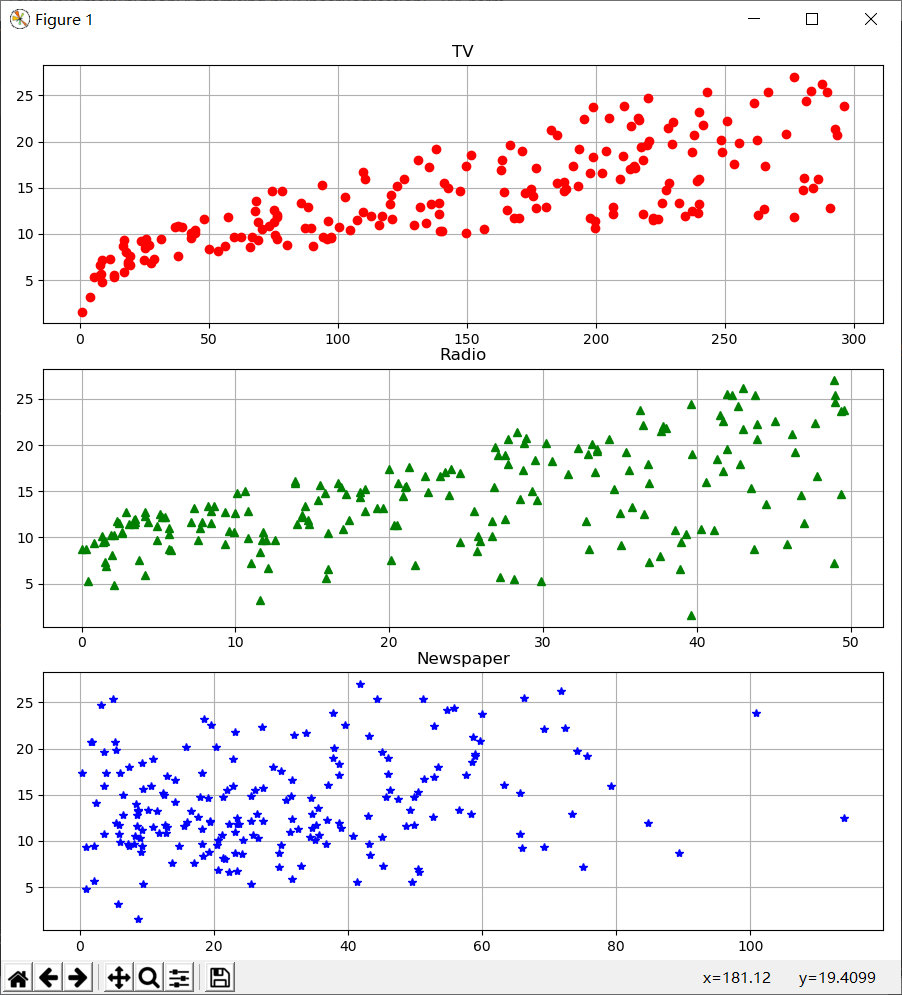
结合上述散点图,我们不难发现,Newspaper与Sales之间的相关性是不明显的。
3.构建线性回归模型
1 x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1) 2 linreg = LinearRegression() 3 model = linreg.fit(x_train, y_train) 4 print(model) 5 print(linreg.coef_) 6 print(linreg.intercept_)
train_test_split()函数
train_test_split()函数的作用为对数据集进行划分,返回的是训练数据与预测数据,函数的参数如下:
arrays:可以是列表、numpy数组、scipy稀疏矩阵或pandas的数据框
test_size:可以为浮点、整数或None,默认为None
①若为浮点时,表示测试集占总样本的百分比 ②若为整数时,表示测试样本样本数 ③若为None时,test size自动设置成0.25
train_size:可以为浮点、整数或None,默认为None
①若为浮点时,表示训练集占总样本的百分比 ②若为整数时,表示训练样本的样本数 ③若为None时,train_size自动被设置成0.75
random_state:可以为整数、RandomState实例或None,默认为None
①若为None时,每次生成的数据都是随机,可能不一样 ②若为整数时,每次生成的数据都相同
stratify:可以为类似数组或None
①若为None时,划分出来的测试集或训练集中,其类标签的比例也是随机的 ②若不为None时,划分出来的测试集或训练集中,其类标签的比例同输入的数组中类标签的比例相同,可以用于处理不均衡的数据集
linreg.coef_多元变量前的系数,
linreg.intercept_回归模型的截距
4.模型的预测及评价
1 y_hat = linreg.predict(np.array(x_test)) 2 mse = np.average((y_hat - np.array(y_test)) ** 2) # Mean Squared Error 3 rmse = np.sqrt(mse) # Root Mean Squared Error 4 print(mse, rmse) 5 6 t = np.arange(len(x_test)) 7 plt.plot(t, y_test, 'r-', linewidth=2, label='Test') 8 plt.plot(t, y_hat, 'g-', linewidth=2, label='Predict') 9 plt.legend(loc='upper right') 10 plt.grid() 11 plt.show()
模型的输出结果:

使用均方差函数进行模型的评价:MSE:1.973.4,RMSE:1.404
绘制预测值与实际值曲线:
