此作业要求参见https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206
词频统计
老五在寝室吹牛他熟读过《鲁滨逊漂流记》,在女生面前吹牛热爱《呼啸山庄》《简爱》和《飘》,在你面前说通读了《战争与和平》。但是,他的四级至今没过。你们几个私下商量,这几本大作的单词量怎么可能低于四级,大家听说你学习《构建之法》,一致推举你写个程序名字叫wf,统计英文作品的单词量并给出每个单词出现的次数,准备用于打脸老五。
希望实现以下效果。以下效果中数字纯属编造。
功能1 小文件输入。为表明程序能跑,结果真实而不是迫害老五,请他亲自键盘在控制台下输入命令。
>type test.txt
My English is very very pool.
>wf -s test.txt
total 5
very 2
my 1
english 1
is 1
pool 1
为了评估老五的词汇量而不是阅读量,total一项中相同的单词不重复计数数,出现2
次的very计数1次。因为用过控制台和命令行,你早就知道,上面的">"叫做命令提示符,是操作系统的一部分,而不是你的程序的一部分。
此功能完成后你的经验值+10.
效果图如下:

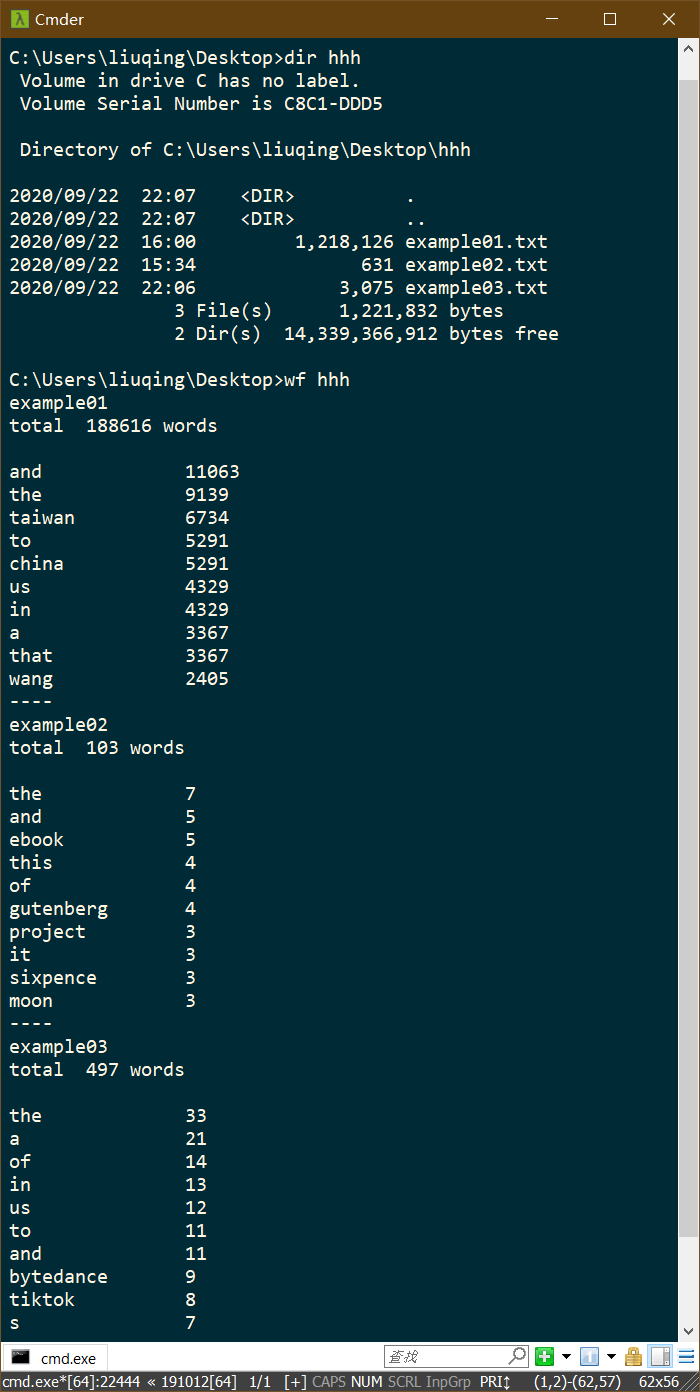
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
>wf gone_with_the_wand
total 1234567 words
the 5023
a 4783
love 4572
fire 4322
run 3822
cheat 3023
girls 2783
girl 2572
slave 1322
buy 822
此功能完成后你的经验值+30. 输入文件最大不超过40MB. 如果你的程序中途崩了,会被老五打脸,不增加经验值。
效果图如下:

功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
>dir folder
gone_with_the_wand
runbinson
janelove
>wf folder
gone_with_the_wand
total 1234567 words
the 5023
a 4783
love 4572
fire 4322
run 3822
cheat 3023
girls 2783
girl 2572
slave 1322
buy 822
----
runbinson
total 1234567 words
friday 5023
sea 4783
food 4572
dog 4322
run 3822
hot 3023
cood 2783
cool 2572
bible 1322
eat 822
----
janelove
total 1234567 words
love 5023
chat 4783
lie 4572
run 4322
money 3822
inheritance 3023
class 2783
attribute 2572
data 1322
method 822
因为单词量巨大,只列出出现次数最多的10个单词。
此功能完成后你的经验值+8.
效果图如下:
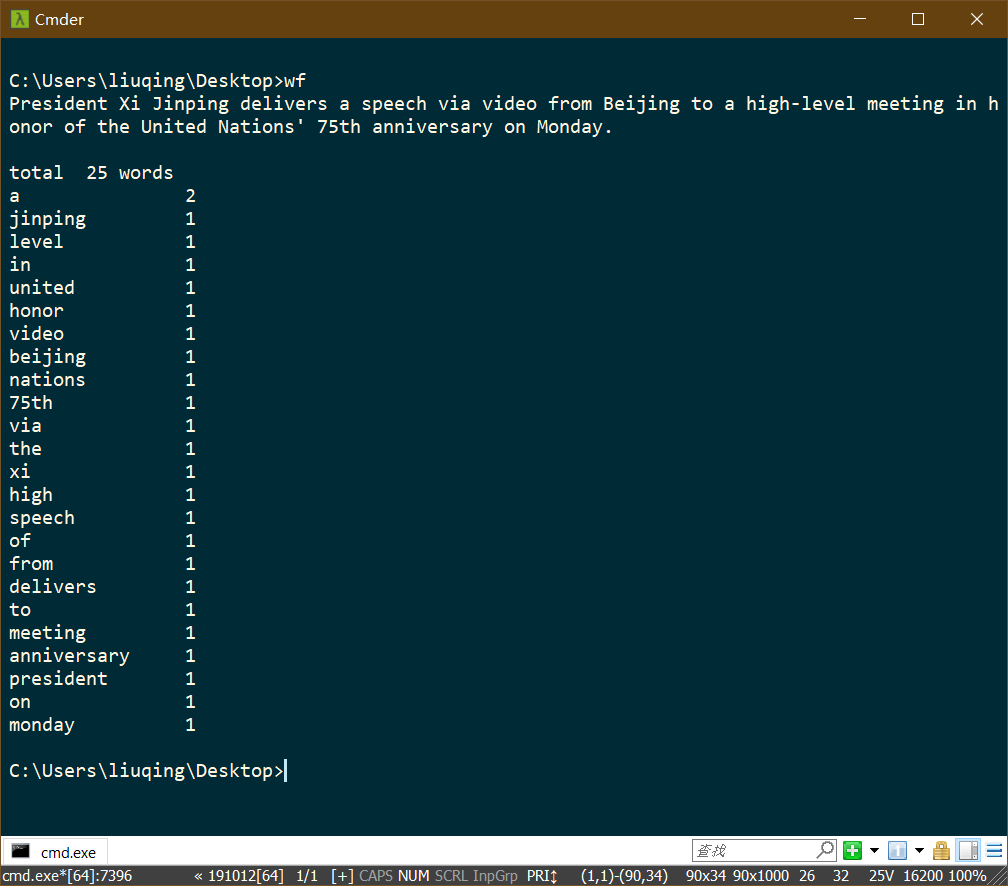
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
>wf -s < the_show_of_the_ring
total 176
the 6
a 3
festival 2
dead 2
for 2
...
或
>wf
A festival for the dead is held once a year in Japan. The festival is
a cheerful occation, for the dead are said to return to their homes
and they are welcomed by the living.
total 176
the 6
a 3
festival 2
dead 2
for 2
...
效果图如下:
功能5 此功能为选做题,如果完成正确得30经验值,如果不做得0经验值,不会倒扣分数。
你完成了所有功能,后面的博客、PSP等也都精心准备了,去食堂的路上心情大悦。坐下挠了挠手机访问cnblogs上的班级,却发现大家的作业也都非常优秀,自己并不突出,心下黯然。怎么才能更加杰出呢?一抬头,看到老杨老师和和邹欣老师正坐桌对面吃饭,你说出了自己的困惑。
老杨说,“精益求精,一步步榨出自己的潜力来,正是走向杰出的开始啊。”
你说,“老师你具体点呗。”
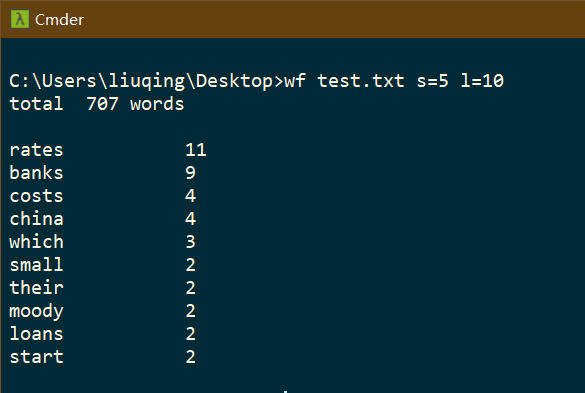
邹欣老师说,“这样,我想知道5个字母的单词中最频繁出现的是哪10个单词,top10,你怎么办呢?”
你一下就想到了,说了思路,应该blablabla。邹欣老师又问,“6个字母的单词中最频繁出现的是哪10个单词呢,top10?”
老杨追问,“6个字母的字母的单词中最频繁出现的是哪100个单词呢,top100?”
你问,“算法我想好了,性能估计也没问题,命令行参数老师怎么规定呢?”
老杨说,"你来规定,写个简单的文档,包括如何运行,给出运行实例的截图。"
"可变的参数就是(1)几个字母和(2)排行前多少是吧?没有问题。"
此时,你想起自己一直做作业还没有吃饭。肚子咕咕叫得声音如此之大,把你吵醒了。是赶紧去吃饭呢,还是做完这题再说?
效果图如下:
输入格式:wf xxx.xxx s=x l=x (s:单词字母个数 l:输出最大行数)
重点/难点
我用Java写的这五道题,一共写了184行,其中主类106行,主要是对命令行参数和控制台输入做分析判断,判断当前是需要使用哪个功能。工具类78行,主要是对传入的文件内容进行读取,字符串分割,单词统计,排序和控制输出。这五道题,整体来说难度不大,但是有点点复杂。
-
工具类:重点在于对字符串的分割和字符串出现次数统计/排序(这里用的是HashMap存放字符串,借助ArrayList进行排序)
-
功能一和功能二:这两个功能都是输入文件名,差别是带不带拓展名。重点是判断输入的
文件名是否带拓展名
-
功能三:输入文件夹名,重点是递归遍历文件夹下的所有文件/文件夹,然后对文件进行词频统计
-
功能四:读取控制台输入的文本,重点是生成一个临时文件,把控制台输入的文本输出到临时文件中,然后再从文件中读取。这样虽然多了两个步骤,但是可以少写一个方法,和其他功能共用一个方法实现词频统计。
-
方法五:命令行参数里多两个参数:单词字母个数和最大输出行数,重点是对命令行参数进行判断。
工具类代码:
/**
* Word frequency statistics utils
*/
public class WfcUtils {
public static void wfc(File file, Integer wordLength, Integer maxLineCount, String functionType) {
Map<String, Integer> map = new HashMap<>();
int wordSum = 0;
try {
Scanner sc = new Scanner(file);
while (sc.hasNextLine()) {
String line = sc.nextLine();
if (line.equals("")) {
continue;
}
String[] lineWords = line.split("\W+");
if (wordLength == null) {
for (String temp : lineWords) {
wordSum++;
//单词出现过,则数量加一
if (map.containsKey(temp.toLowerCase())) {
map.put(temp.toLowerCase(), map.get(temp.toLowerCase()) + 1);
} else {
//单词未出现过
map.put(temp.toLowerCase(), 1);
}
}
} else {
for (String temp : lineWords) {
wordSum++;
if (temp.length() == wordLength) {
//单词出现过,则数量加一
if (map.containsKey(temp.toLowerCase())) {
map.put(temp.toLowerCase(), map.get(temp.toLowerCase()) + 1);
} else {
//单词未出现过
map.put(temp.toLowerCase(), 1);
}
}
}
}
}
//排序
List<Map.Entry<String, Integer>> entryList = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
Collections.sort(entryList, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return o2.getValue().compareTo(o1.getValue());
}
});
System.out.println("total " + wordSum + " words
");
if (maxLineCount == null) {
//全部输出
for (Map.Entry entry : entryList) {
System.out.printf("%-15s %d
", entry.getKey(), entry.getValue());
}
} else {
//最多输出maxLineCount行
int printLineSum = entryList.size() >= maxLineCount ? maxLineCount : entryList.size();
for (int i = 0; i < printLineSum; i++) {
System.out.printf("%-15s %d
", entryList.get(i).getKey(), entryList.get(i).getValue());
}
}
if (functionType.equals("3")) {
System.out.println("----");
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
PSP
在同一篇博客中,参照教材第35页表2-2和表2-3,为上述“项目”制作PSP阶段表格。
PSP阶段表格第1列分类,如功能1、功能2、测试功能1等。
| 预计花费时间 | 实际花费时间 | 花费时间差距 | 原因 | |
|---|---|---|---|---|
| 准备工作 | 20min | 42min | 22min | 学习IntelliJ Idea打jar包和exe4j工具的使用,测试exe文件和命令行参数 |
| 功能一 | 60min | 83min | 23min | 对file,map等有点生疏,写起来比较慢。完成功能一后想到可以写一个通用的工具类,于是对代码进行重构 |
| 功能二 | 30min | 15min | -15min | 和功能一使用同一个工具类进行词频分析,不需要写太多代码 |
| 功能三 | 30min | 34min | 4min | 写完后发现要递归搜索文件,于是重写 |
| 功能四 | 30min | 27min | -3min | 使用通用的工具类进行词频分析,不需要写太多代码 |
| 功能五 | 30min | 31min | 1min | 一开始没发现要求一个程序实现所有功能,对多个类进行了合并 |
| 测试 | 30min | 79min | 49min | 发现bug,解决bug |
代码及版本控制
仓库地址:https://e.coding.net/ayuyu/software-engineering-coursework/software-engineering-coursework.git