个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。在正式开始使用XPath进行定位前,我们先了解下什么是 XPath。XPath是XML Path的简称,由于HTML文档本身就是一个标准的XML页面,所以我们可以使用XPath的语法来定位页面元素。
假设我们现在以图(2)所示HTML代码为例,要引用对应的对象,XPath语法如下:
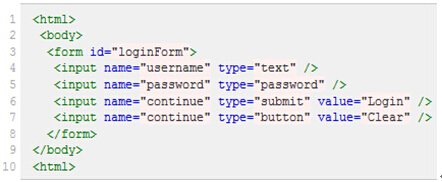
图(2)
绝对路径写法(只有一种),写法如下:
引用页面上的form元素(即源码中的第3行):/html/body/form[1]
注意:1. 元素的xpath绝对路径可通过firebug直接查询。2. 一般不推荐使用绝对路径的写法,因为一旦页面结构发生变化,该路径也随之失效,必须重新写。3. 绝 对路径以单/号表示,而下面要讲的相对路径则以//表示,这个区别非常重要。另外需要多说一句的是,当xpath的路径以/开头时,表示让Xpath解析 引擎从文档的根节点开始解析。当xpath路径以//开头时,则表示让xpath引擎从文档的任意符合的元素节点开始进行解析。而当/出现在xpath路 径中时,则表示寻找父节点的直接子节点,当//出现在xpath路径中时,表示寻找父节点下任意符合条件的子节点,不管嵌套了多少层级(这些下面都有例 子,大家可以参照来试验)。弄清这个原则,就可以理解其实xpath的路径可以绝对路径和相对路径混合在一起来进行表示,想怎么玩就怎么玩。
下面是相对路径的引用写法:
查找页面根元素://
查找页面上所有的input元素://input
查找页面上第一个form元素内的直接子input元素(即只包括form元素的下一级input元素,使用绝对路径表示,单/号)://form[1]/input
查找页面上第一个form元素内的所有子input元素(只要在form元素内的input都算,不管还嵌套了多少个其他标签,使用相对路径表示,双//号)://form[1]//input
查找页面上第一个form元素://form[1]
查找页面上id为loginForm的form元素://form[@id='loginForm']
查找页面上具有name属性为username的input元素://input[@name='username']
查找页面上id为loginForm的form元素下的第一个input元素://form[@id='loginForm']/input[1]
查找页面具有name属性为contiune并且type属性为button的input元素://input[@name='continue'][@type='button']
查找页面上id为loginForm的form元素下第4个input元素://form[@id='loginForm']/input[4]
Xpath功能很强大,所以也可以写得更加复杂一些,如下面图(3)的HTML源码。
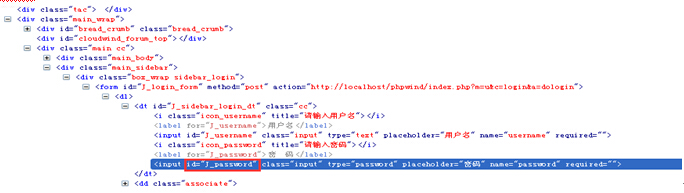
图(3)
如果我们现在要引用id为“J_password”的input元素,该怎么写呢?我们可以像下面这样写:
WebElement password = driver.findElement(By.xpath("//*[@id='J_login_form']/dl/dt/input[@id='J_password']"));
也可以写成:
WebElement password = driver.findElement(By.xpath("//*[@id='J_login_form']/*/*/input[@id='J_password']"));
这里解释一下,其中//*[@id=’ J_login_form’]这一段是指在根元素下查找任意id为J_login_form的元素,此时相当于引用到了form元素。后面的路径必须按照 源码的层级依次往下写。按照图(3)所示代码中,我们要找的input元素包含在一个dt标签内,而dt又包含在dl标签内,所以中间必须写上dl和dt 两层,才到input这层。当然我们也可以用*号省略具体的标签名称,但元素的层级关系必须体现出来,比如我们不能写成//* [@id='J_login_form']/input[@id='J_password'],这样肯定会报错的。
前面讲的都是xpath中基于准确元素属性的定位,其实xpath作为定位神器也可以用于模糊匹配。比如下面图(4)所示代码:
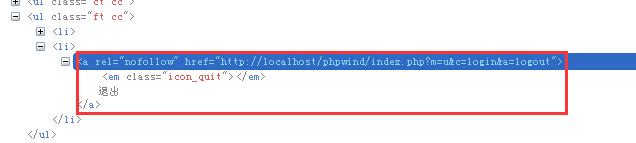
这段代码中的“退出”这个超链接,没有标准id元素,只有一个rel和href,不是很好定位。不妨我们就用xpath的几种模糊匹配模式来定位它吧,主要有三种方式,举例如下。
a. 用contains关键字,定位代码如下:
1 driver.findElement(By.xpath(“//a[contains(@href, ‘logout’)]”));
这句话的意思是寻找页面中href属性值包含有logout这个单词的所有a元素,由于这个退出按钮的href属性里肯定会包含logout,所以这种方式是可行的,也会经常用到。其中@后面可以跟该元素任意的属性名。
b. 用start-with,定位代码如下:
1 driver.findElement(By.xpath(“//a[starts-with(@rel, ‘nofo’)]));
这句的意思是寻找rel属性以nofo开头的a元素。其中@后面的rel可以替换成元素的任意其他属性。
c. 用Text关键字,定位代码如下:
1 driver.findElement(By.xpath(“//*[text()=’退出’]));
这个方法可谓相当霸气啊。直接查找页面当中所有的退出二字,根本就不用知道它是个a元素了。这种方法也经常用于纯文字的查找。
另外,如果知道超链接元素的文本内容,也可以用
1 driver.findElement(By.xpath(“//a[contains(text(), ’退出’)]));
这种方式一般用于知道超链接上显示的部分或全部文本信息时,可以使用。
最后,关于xpath这种定位方式,webdriver会将整个页面的所有元素进行扫描以定位我们所需要的元素,所以这是一个非常费时的操作,如果你的脚本中大量使用xpath做元素定位的话,将导致你的脚本执行速度大大降低,所以请慎用。