作业一
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
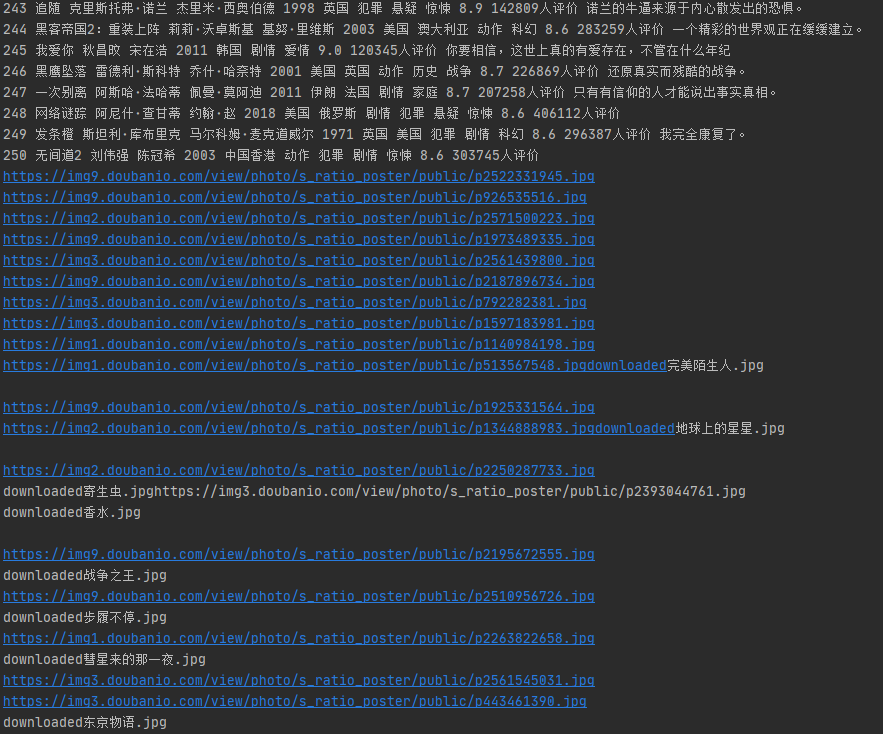
成果截图
代码
import re
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import request
import threading
import urllib.request
import pymysql
class Douban():
def start_up(self):
try:
self.con = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='axx123123', charset='utf8',
db='mydb')
self.cursor = self.con.cursor()
try:
# 如果有表就删除
self.cursor.execute("drop table Douban")
except:
pass
try:
sql = "create table Douban (排名 varchar(4),电影名称 varchar(256),导演 varchar(256),主演 varchar(256)"
",上映时间 varchar(256),国家 varchar(256),电影类型 varchar(256),评分 int,评价人数 int ,引用 varchar(512),文件路径 varchar(512))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
def closeUp(self):
try:
self.con.commit()
self.con.close()
except Exception as err:
print(err)
def insertDB(self, rank, name, director, mainactor, time, country, type, score, rateCount, quote,path):
try:
self.cursor.execute("insert into Douban (排名,电影名称,导演,主演,上映时间,国家,电影类型,评分,评价人数,引用,文件路径) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(rank, name, director, mainactor, time, country, type, score, rateCount, quote,path))
except Exception as err:
print(err)
def DouBanSpider(self,start_url):
global threads
try:
urls = []
r = request.get(start_url, headers=headers)
html = r.text
soup = BeautifulSoup(html, 'html.parser')
movielist = soup.select("ol li")
for movie in movielist:
rank = movie.select("em")[0].text
name = movie.select("div[class='hd'] span")[0].text
detailurl = movie.select("div[class='hd'] a")[0]['href']
req = request.get(detailurl, headers=headers)
html_1 = req.text
soup_1 = BeautifulSoup(html_1, 'html.parser')
director = soup_1.select("div[id='info'] a[rel='v:directedBy']")[0].text
mainactor = soup_1.select("div[id='info'] a[rel='v:starring']")[0].text
time = re.findall(r'd+.+', movie.select("div[class='bd'] p")[0].text.strip())[0].split("/")[0].strip()
country = re.findall(r'd+.+', movie.select("div[class='bd'] p")[0].text.strip())[0].split("/")[1].strip()
type = re.findall(r'd+.+', movie.select("div[class='bd'] p")[0].text.strip())[0].split("/")[2].strip()
score = movie.select("div[class='star'] span[class='rating_num']")[0].text
rateCount = movie.select("div[class='star'] span")[3].text
rateCount=re.findall(r'd+',rateCount)[0]
if movie.select("p[class='quote'] span"):
quote = movie.select("p[class='quote'] span")[0].text
else:
quote = ''
print(rank, name, director, mainactor, time, country, type, score, rateCount, quote,name+'jpg')
self.insertDB(rank, name, director, mainactor, time, country, type, score, rateCount, quote,name+'jpg')
images = soup.select("img")
for image in images:
try:
url = image['src']
jpgname = image['alt']
if url not in urls:
print(url)
T = threading.Thread(target=self.download, args=(url, jpgname))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(self,url, name):
try:
if (url[len(url) - 4] == '.'):
ext = url[len(url) - 4:]
else:
ext = ''
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
with open('./images/' + name + ext, 'wb') as f:
f.write(data)
f.close()
print("downloaded" + name + ext)
except Exception as err:
print(err)
headers = {
'cookie': 'bid=MVprhlNrC9g; douban-fav-remind=1; __yadk_uid=XLbeJ2b65whlEmF7XR2tyJzVjnr0e7lx; ll="108300"; _vwo_uuid_v2=D2CBDAAF0CB60468FE6426EF13E90F383|a7dcf5048e170aa20a86966b60bd5c21; push_noty_num=0; push_doumail_num=0; __utmv=30149280.22726; __gads=ID=7cf2842854f39a40-22818e09ebc4009c:T=1606274137:RT=1606274137:S=ALNI_Mbwadx0Pb_JPKO7BASVfooEmVTUPQ; dbcl2="227263608:srZZtUzuoiY"; ck=TtEH; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1606296668%2C%22https%3A%2F%2Faccounts.douban.com%2F%22%5D; _pk_id.100001.8cb4=1bae15819dcbb00a.1600416620.6.1606296668.1606271160.; _pk_ses.100001.8cb4=*; __utma=30149280.1094101319.1600416624.1606273588.1606296668.8; __utmc=30149280; __utmz=30149280.1606296668.8.6.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt=1; __utmb=30149280.2.10.1606296668','user-agent': 'Mozilla/5,0'}
threads = []
a=Douban()
a.start_up()
for page in range(0,11):
a.DouBanSpider("https://movie.douban.com/top250?start="+str(page*25)+"&filter=")
for t in threads:
t.join()
a.closeUp()心得体会
太久没用了,完全忘光,正则表达式还是有点不熟练,导演主演之类的还得点进去网页获取,xpath用多了css的用法也忘了,[attr=value],搜子节点用空格分隔
作业二
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
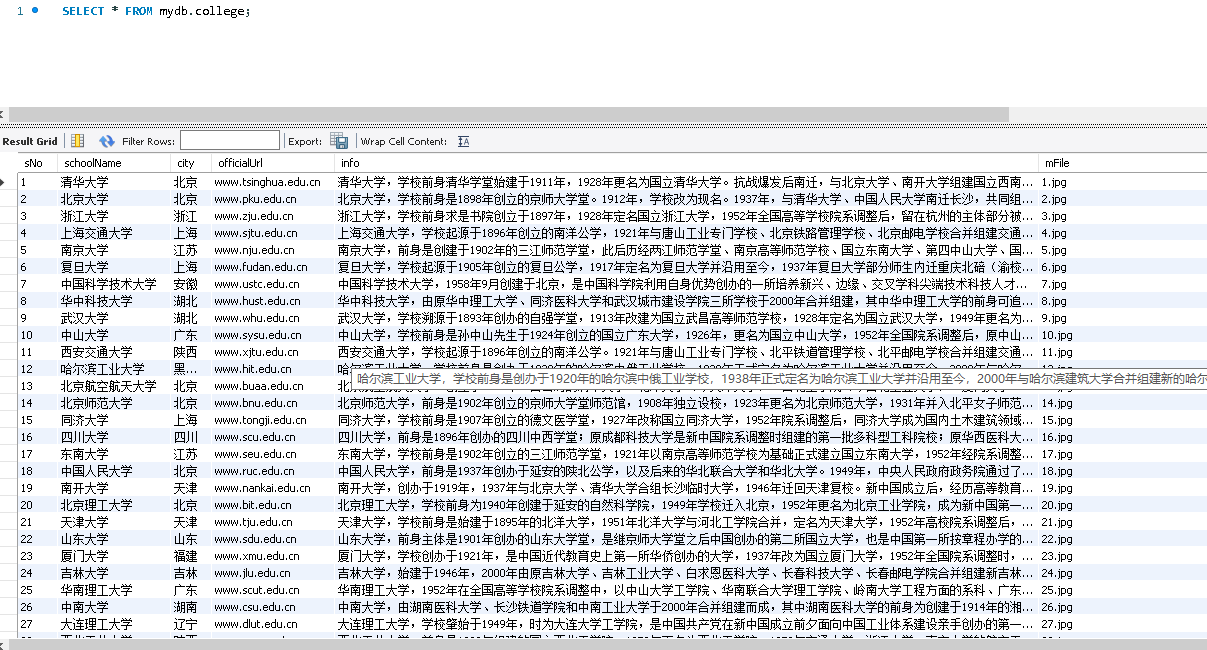
成果截图

代码
Myspider.py
import scrapy
from ..items import GetcollegeItem
from bs4 import UnicodeDammit
import request
class MySpider(scrapy.Spider):
name='mySpider'
def start_requests(self):
url = 'https://www.shanghairanking.cn/rankings/bcur/2020'
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector=scrapy.Selector(text=data)
collegelist=selector.xpath("//table[@class='rk-table']/tbody/tr")
for college in collegelist:
#载入电影详情页
detailUrl="https://www.shanghairanking.cn"+college.xpath("./td[@class='align-left']/a/@href").extract_first()
print(detailUrl)
req = request.get(detailUrl)
req.encoding='utf-8'
text=req.text
selector_1=scrapy.Selector(text=text)
#抓取数据
sNo=college.xpath("./td[position()=1]/text()").extract_first().strip()
print(sNo)
schoolName=selector_1.xpath("//div[@class='univ-name']/text()").extract_first()
print(schoolName)
city=college.xpath("./td[position()=3]/text()").extract_first().strip()
print(city)
officialUrl=selector_1.xpath("//div[@class='univ-website']/a/text()").extract_first()
print(officialUrl)
info=selector_1.xpath("//div[@class='univ-introduce']/p/text()").extract_first()
print(info)
mFile=sNo+'.jpg'
#获取并下载图片
src = selector_1.xpath("//td[@class='univ-logo']/img/@src").extract_first()
req_1 = request.get(src)
image=req_1.content
picture=open("D:/PycharmProjects/爬虫6/getCollege/getCollege/image/"+str(sNo)+'.png',"wb")
picture.write(image)
picture.close()
#存入item
item=GetcollegeItem()
item['sNo']=sNo if sNo else ""
item['schoolName']=schoolName if schoolName else ""
item['city']=city if city else ""
item['officialUrl']=officialUrl if officialUrl else ""
item['info']=info if info else ""
item['mFile']=mFile if mFile else ""
yield item
except Exception as err:
print(err)piplines.py
import pymysql
class GetcollegePipeline:
def open_spider(self,spider):
try:
self.con = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='axx123123', charset='utf8',
db='mydb')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("drop table college")
except:
pass
try:
sql = "create table college (sNo int,schoolName varchar(256),city varchar(256),officialUrl varchar(256)"
",info varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
def close_spider(self,spider):
self.con.commit()
self.con.close()
print("closed")
def process_item(self, item, spider):
try:
self.cursor.execute("insert into college (sNo,schoolName,city,officialUrl,info,mFile) values (%s,%s,%s,%s,%s,%s)",
(item['sNo'],item['schoolName'],item['city'],item['officialUrl'],item['info'],item['mFile']))
except Exception as err:
print(err)
return item心得体会
scrapy也没怎么复习,测试的时候settings都没改,Myspider用来抓取数据和下载图片,pipelines存入数据库,xpath获取文本内容要在xpath语句里面加text,用法和selenium的也有所区别
作业三
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
成果截图
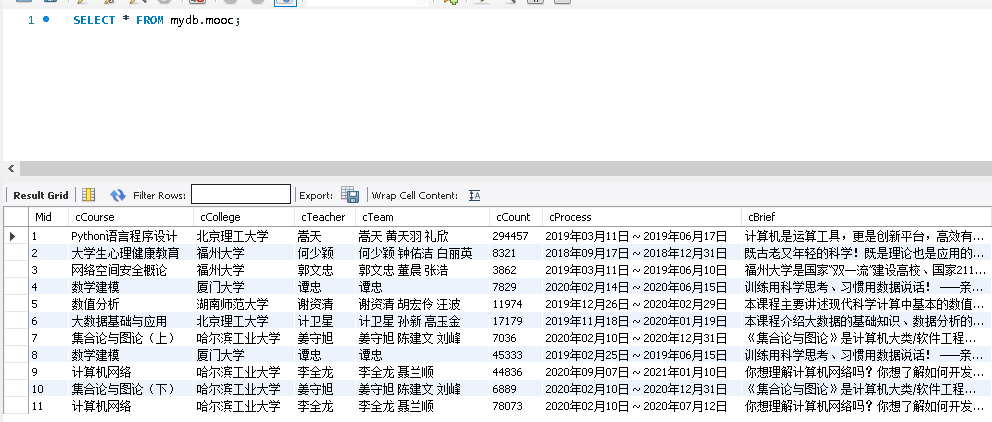
代码
from selenium import webdriver from selenium.webdriver.chrome.options import Options import pymysql import time import selenium import datetime import sqlite3 class MySpider(): def startUp(self, url): # # Initializing Chrome browser chrome_options = Options() # chrome_options.add_argument('--headless') # chrome_options.add_argument('--disable-gpu') self.driver = webdriver.Chrome(chrome_options=chrome_options) self.No=1 # Initializing database try:self.con = pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='axx123123',charset='utf8',db='mydb') self.cursor = self.con.cursor() try: # 如果有表就删除 self.cursor.execute("drop table Mooc") except: pass try: sql = "create table mooc (Mid int,cCourse varchar(256),cCollege varchar(256),cTeacher varchar(256)" ",cTeam varchar(256),cCount varchar(256),cProcess varchar(256),cBrief varchar(256))" self.cursor.execute(sql) except: pass except Exception as err: print(err) time.sleep(3) self.driver.get(url) def closeUp(self): try: self.con.commit() self.con.close() self.driver.close() except Exception as err: print(err) def insertDB(self, Mid, cCourse, cCollege,cTeacher, cTeam, cCount, cProcess, cBrief): try: self.cursor.execute("insert into mooc (Mid, cCourse,cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) " "values(%s,%s,%s,%s,%s,%s,%s,%s)", (Mid, cCourse, cCollege,cTeacher, cTeam, cCount, cProcess, cBrief)) except Exception as err: print(err) def showDB(self): try: con = sqlite3.connect("Mooc.db") cursor = con.cursor() print("%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s" % ( "Mid", "cCourse", "cCollege","cTeacher", "cTeam", "cCount", "cProcess", "cBrief")) cursor.execute("select * from Mooc order by Mid") rows = cursor.fetchall() for row in rows: print("%-16s %-16s %-16s %-16s %-16s %-16s %-16s %-16s" % ( row[0], row[1], row[2], row[3], row[4], row[5], row[6], row[7])) con.close() except Exception as err: print(err) def login(self): self.driver.maximize_window() # login try: #点击登录 self.driver.find_element_by_xpath("//div[@id='g-body']/div[@id='app']/div[@class='_1FQn4']" "/div[@class='_2g9hu']/div[@class='_2XYeR']/div[@class='_2yDxF _3luH4']" "/div[@class='_1Y4Ni']/div[@role='button']").click() time.sleep(3) #其他登录方式 self.driver.find_element_by_xpath("//span[@class='ux-login-set-scan-code_ft_back']").click() time.sleep(3) #手机登录 self.driver.find_element_by_xpath("//ul[@class='ux-tabs-underline_hd']/li[position()=2]").click() time.sleep(3) #切换到frame窗口输入账号信息 zx = self.driver.find_elements_by_tag_name("iframe")[1].get_attribute("id") self.driver.switch_to.frame(zx) #输入账号 self.driver.find_element_by_xpath("//div[@class='u-input box']/input[@type='tel']").send_keys("xxxxxxxx") time.sleep(1) #输入密码 self.driver.find_element_by_xpath( "//div[@class='u-input box']/input[@class='j-inputtext dlemail']").send_keys("xxxxxxxx") time.sleep(1) #点击登录 self.driver.find_element_by_xpath("//a[@class='u-loginbtn btncolor tabfocus ']").click() time.sleep(3) # 点击我的课程 self.driver.find_element_by_xpath("//div[@class='_3uWA6']").click() time.sleep(3) except Exception as err: print(err) def processSpider(self): try: list=self.driver.find_elements_by_xpath("//div[@class='course-panel-body-wrapper']/div") print(list) for li in list: #点击课程 li.click() time.sleep(2) new_tab=self.driver.window_handles[-1] self.driver.switch_to.window(new_tab) time.sleep(2) #点击课程详细 self.driver.find_element_by_xpath("//h4[@class='f-fc3 courseTxt']").click() time.sleep(2) new_new_tab=self.driver.window_handles[-1] self.driver.switch_to.window(new_new_tab) id=self.No #print(id) Course=self.driver.find_element_by_xpath("//*[@id='g-body']/div[1]/div/div[3]/div/div[1]/div[1]/span[1]").text #print(Course) College=self.driver.find_element_by_xpath("//*[@id='j-teacher']/div/a/img").get_attribute("alt") #print(College) Teacher=self.driver.find_element_by_xpath("//*[@id='j-teacher']/div/div/div[2]/div/div/div/div/div/h3").text #print(Teacher) Teamlist=self.driver.find_elements_by_xpath("//*[@id='j-teacher']/div/div/div[2]/div/div[@class='um-list-slider_con']/div") Team='' for name in Teamlist: main_name=name.find_element_by_xpath("./div/div/h3[@class='f-fc3']").text Team+=str(main_name)+" " #print(Team) Count=self.driver.find_element_by_xpath("//*[@id='course-enroll-info']/div/div[2]/div[1]/span").text Count=Count.split(" ")[1] #print(Count) Process=self.driver.find_element_by_xpath('//*[@id="course-enroll-info"]/div/div[1]/div[2]/div[1]/span[2]').text #print(Process) Brief=self.driver.find_element_by_xpath('//*[@id="j-rectxt2"]').text #print(Brief) time.sleep(2) #关闭课程详细界面 self.driver.close() pre_tab=self.driver.window_handles[1] self.driver.switch_to.window(pre_tab) time.sleep(2) #关闭课程界面 self.driver.close() pre_pre_tab=self.driver.window_handles[0] self.driver.switch_to.window(pre_pre_tab) time.sleep(2) self.No+=1 self.insertDB(id, Course, College, Teacher, Team, Count, Process, Brief) try: time.sleep(2) #下一页 nextpage = self.driver.find_element_by_xpath("//a[@class='th-bk-main-gh']") time.sleep(2) nextpage.click() self.processSpider() except: self.driver.find_element_by_xpath("//a[@class='th-bk-disable-gh']") except Exception as err: print(err) def executeSpider(self, url): starttime = datetime.datetime.now() print("Spider starting......") self.startUp(url) print("Spider processing......") self.login() self.processSpider() print("Spider closing......") self.closeUp() print("Spider completed......") endtime = datetime.datetime.now() elapsed = (endtime - starttime).seconds print("Total ", elapsed, " seconds elapsed")
url = "https://www.icourse163.org/"
spider = MySpider()
spider.executeSpider(url)
心得体会
和上次作业基本相同,课程详情页的xpath都没怎么变,需要注意的是登录以后点击我的课程是直接在当前页跳转不需要switch,点击课程还要再点开详情页,关闭的时候也要close两次,switch两次