作业1
单线程
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request def imageSpider(start_url): try: urls=[] req=urllib.request.Request(start_url,headers=headers) data=urllib.request.urlopen(req) data=data.read() dammit=UnicodeDammit(data,["utf-8","gbk"]) data=dammit.unicode_markup soup=BeautifulSoup(data,'lxml') images=soup.select('img') for image in images: try: src=image['src'] url=urllib.request.urljoin(start_url,src) if url not in urls: urls.append(url) print(url) download(url) except Exception as err: print(err) except Exception as err: print(err) def download(url): global count try: count+=1 if(url[len(url)-4]=='.'): ext=url[len(url)-4:] else: ext='' req=urllib.request.Request(url,headers=headers) data=urllib.request.urlopen(req,timeout=100) data=data.read() with open('./images/'+str(count)+ext,'wb') as f: f.write(data) f.close() print("downloaded"+str(count)+ext) except Exception as err: print(err) start_url="http://www.weather.com.cn"
headers={"User-Agent":"Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count=0
imageSpider(start_url)

多线程
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request import threading def imageSpider(start_url): global threads global count try: urls=[] req=urllib.request.Request(start_url,headers=headers) data=urllib.request.urlopen(req) data=data.read() dammit=UnicodeDammit(data,["utf-8","gbk"]) data=dammit.unicode_markup soup=BeautifulSoup(data,'lxml') images=soup.select('img') for image in images: try: src=image['src'] url=urllib.request.urljoin(start_url,src) if url not in urls: print(url) count+=1 T=threading.Thread(target=download,args=(url,count)) T.setDaemon(False) T.start() threads.append(T) except Exception as err: print(err) except Exception as err: print(err) def download(url,count): try: if(url[len(url)-4]=='.'): ext=url[len(url)-4:] else: ext='' req = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj=open("images/"+str(count)+ext,'wb') fobj.write(data) fobj.close() print("downloaded" + str(count) + ext) except Exception as err: print(err) start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36e"}
count=0
threads=[]
imageSpider(start_url)
for t in threads:
t.join()
print("The End")

心得体会
复现书上代码,复习了多线程的单线程代码实现的框架,加深印象
作业2


items.py
import scrapy
class DemoItem(scrapy.Item):
src=scrapy.Field()
passMySpider.py
import scrapy
from ..items import DemoItem
class MySpider(scrapy.Spider):
name="MySpider"
def start_requests(self):
url='http://www.weather.com.cn'
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
data=response.body.decode()
selector=scrapy.Selector(text=data)
images=selector.xpath("//img/@src")
images=images.extract()
for image in images:
item=DemoItem()
item['src']=image
print(image)
yield itempipelines.py
from itemadapter import ItemAdapter
import urllib
class DemoPipeline:
count=0
def process_item(self, item, spider):
DemoPipeline.count=DemoPipeline.count+1
try:
src=item['src']
if(src[len(src)-4]=='.'):
Suffix=src[len(src)-4:]
else:
Suffix=''
req = urllib.request.Request(src)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
with open('C:/Users/Mechrevo/PycharmProjects/爬虫3/venv/demo/demo/image/'+str(DemoPipeline.count)+Suffix,'wb') as f:
f.write(data)
f.close()
print("downloaded"+str(DemoPipeline.count)+Suffix)
except Exception as err:
print(err)
return itemsettings.py
BOT_NAME = 'demo'
SPIDER_MODULES = ['demo.spiders']
NEWSPIDER_MODULE = 'demo.spiders'
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
'demo.pipelines.DemoPipeline': 300,
}run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl MySpider -s LOG_ENABLED=False".split())心得体会
照着书上的例子里面的结构写,写出来比光看感觉很不一样
作业3
items.py
import scrapy
class DemoItem(scrapy.Item):
count=scrapy.Field()
number=scrapy.Field()
name=scrapy.Field()
newestPrice=scrapy.Field()
changeRate=scrapy.Field()
changePrice=scrapy.Field()
turnover=scrapy.Field()
turnoverPrice=scrapy.Field()
amplitude=scrapy.Field()
highest=scrapy.Field()
lowest=scrapy.Field()
today=scrapy.Field()
yesterday=scrapy.Field()
passMySpider.py
import scrapy
from ..items import DemoItem
from ..pipelines import DemoPipeline
import re
class MySpider(scrapy.Spider):
name="MySpider"
def start_requests(self):
url = 'http://79.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406672352204467267_1603174082147&pn=1&pz=60&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18&_=1603174082162'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self,response):
try:
count=1
data = response.body.decode()
data = re.findall(r'"diff":[(.*?)]',data)
datas = data[0].split("},{") # 分割
datas[0] = datas[0].replace("{", "") # 去除开头的{
datas[len(datas) - 1] = datas[len(datas) - 1].replace("}", "") # 去除结尾的}
for i in range(len(datas)):
item=DemoItem()
datas[i].split(",")
item["count"]=count
item["number"]=datas[i].split(",")[6].split(":")[1]
item["name"]=datas[i].split(",")[7].split(":")[1]
item["newestPrice"]=datas[i].split(",")[0].split(":")[1]
item["changeRate"]=datas[i].split(",")[1].split(":")[1]
item["changePrice"]=datas[i].split(",")[2].split(":")[1]
item["turnover"]=datas[i].split(",")[3].split(":")[1]
item["turnoverPrice"]=datas[i].split(",")[4].split(":")[1]
item["amplitude"]=datas[i].split(",")[5].split(":")[1]
item["highest"]=datas[i].split(",")[8].split(":")[1]
item["lowest"]=datas[i].split(",")[9].split(":")[1]
item["today"]=datas[i].split(",")[10].split(":")[1]
item["yesterday"]=datas[i].split(",")[11].split(":")[1]
count+=1
yield item
print(DemoPipeline.tb)
except Exception as err:
print(err)pipelines.py
from itemadapter import ItemAdapter
import prettytable as pt
class DemoPipeline:
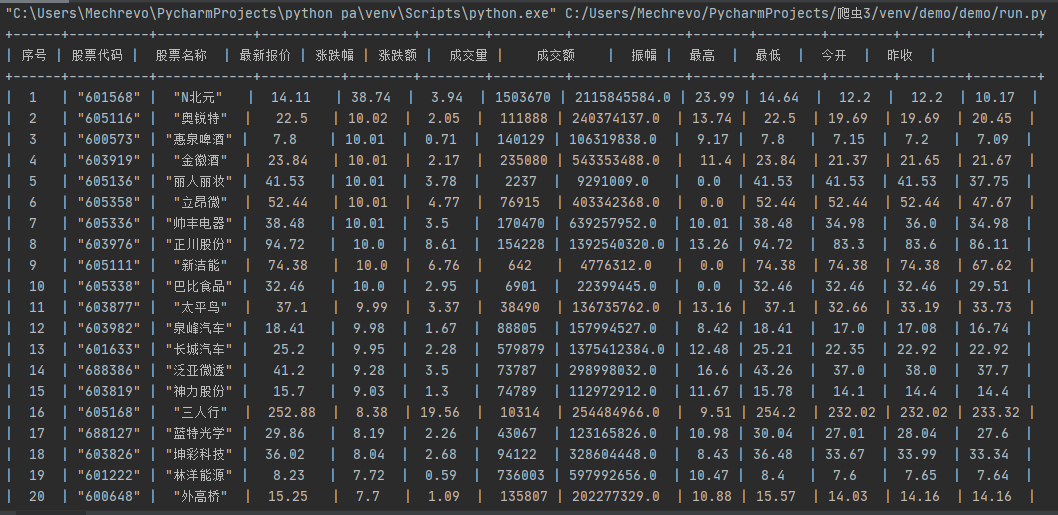
tb=pt.PrettyTable(["序号","股票代码","股票名称","最新报价","涨跌幅","涨跌额","成交量","成交额","振幅","最高","最低","今开","昨收"])
def process_item(self, item, spider):
DemoPipeline.tb.add_row([item["count"],item["number"],item["name"],item["newestPrice"],item["changeRate"],item["changePrice"],item["turnover"],item["turnoverPrice"],item["amplitude"],item["highest"],item["lowest"],item["today"],item["yesterday"]])
return item心得体会
用scrapy框架再次实现之前做过的股票爬取,用法有些许不同,大体原理一样。(要把settings里面的ROBOTSTXT_OBEY改为False)