No.1——WeatherForecast
题目要求
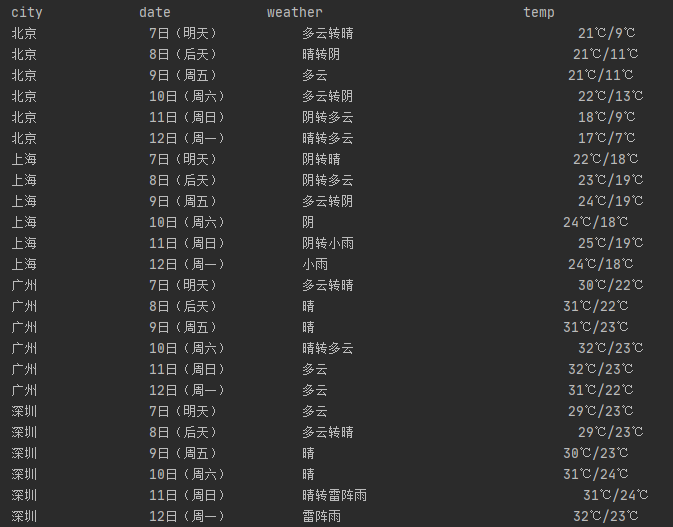
在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
代码部分
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class weatherDB:
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table weathers (wcity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key(wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values(?,?,?,?)",(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class weatherforecast():
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre) Gecko/200807242 Minefield/3.0.2pre"}
self.citycode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastcity(self, city):
if city not in self.citycode.keys():
print(city + "code not found")
return
url = "http://www.weather.com.cn/weather/" + self.citycode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, 'lxml')
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp= li.select('p[class="tem"] span')[0].text + "/" + li.select("p[class='tem'] i")[0].text
#print(city,date,weather,temp)
self.db.insert(city,date,weather,temp)
except Exception as err:
pass
except Exception as err:
print(err)
def process(self, cities):
self.db = weatherDB()
self.db.openDB()
for city in cities:
self.forecastcity(city)
self.db.show()
self.db.closeDB()
ws = weatherforecast()
ws.process(["北京", "上海", "广州", "深圳"])运行结果
心得体会
复现一次天气预报,加强巩固了数据库的使用,也复习了html获取和select的方法,虽然是照抄复现,感觉还是又学到一些东西
No.2——抓取股票
题目要求
用requests和BeautifulSoup库方法爬取股票相关信息
候选网站:东方财富网https://www.eastmoney.com/
代码部分
import urllib
import urllib.request
import re
from bs4 import UnicodeDammit, BeautifulSoup
import prettytable as pt
import sys
tb = pt.PrettyTable(["序号", "代码", "名称", "最新价", "涨跌幅", "跌涨额", "成交量", "成交额", "涨幅"])#建表
def getHtml(page,fs,fields):
#防止反爬
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"}
#获取html文档
url='http://13.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124001030397983465936_1601816496595&pn='+str(page)+'&pz=20&po=1&np=1'
'&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs='+fs+
'&fields='+fields+'&_=1601816496603'
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
#装载html
soup = BeautifulSoup(data, 'lxml')
#用正则表达式获取所需的模块
data = re.findall(r'"diff":[(.*?)]', soup.text)
print(soup)
return data
def getOnePageStock(count,page,fs,fields):
data=getHtml(page,fs,fields)
datas=data[0].split("},{")#分割
datas[0]=datas[0].replace("{","")#去除开头的{
datas[len(datas)-1]=datas[len(datas)-1].replace("}","")#去除结尾的}
for i in range(len(datas)):
#用re的split方法通过正则匹配可以实现以多个分割关键字分割字符串
stock=re.split('[:,]',datas[i].replace('"',""))
#加入到表格的行
tb.add_row([count,stock[13],stock[15],stock[1],stock[3],stock[5],stock[7],stock[9],stock[11]])
count=count+1 #序号自加
return count
def main():
count=1
page=1
fields = "f12,f14,f2,f3,f4,f5,f6,f7"#(f12:代码,f14:名称,f2:最新价,f3:涨跌幅,f4:涨跌额,f5:成交量,f6:成交额,f7:涨幅)
fs = {
"沪深A股": "m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23",
"上证A股": "m:1+t:2,m:1+t:23",
"深证A股": "m:0+t:6,m:0+t:13,m:0+t:80",
}
for i in fs.keys():
count = getOnePageStock(count,page,fs[i],fields)
print(tb)
main()
运行结果

心得体会
根据参考链接上的教程去找对应的js文件真的很需要耐心,然后对比json和网站的数据从field字典去找所需的数据,蛮伤眼神的,不过算是实现了从0到1的过程,收获还算蛮大的
No.3——抓取自定义代码股票
题目要求
根据自选3位数+学号后3位选取股票,屏幕打印股票信息
代码部分
import urllib
import urllib.request
import re
from bs4 import UnicodeDammit, BeautifulSoup
import prettytable as pt
import sys
tb = pt.PrettyTable(["股票代码号", "名称", "今日开", "今日最高", "今日最低"])
def getHtml(number,fields):
# 防止反爬
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"}
# 获取html文档
url='http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&invt=2&fltt=2&'
'fields='+fields+'&secid=0.'+str(number)+'&cb=jQuery1124012344986700569804_1601825123071&_=1601825123079'
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
# 装载html
soup = BeautifulSoup(data, 'lxml')
# 用正则表达式获取所需的模块
data = re.findall(r'{"f.*?}', soup.text)
return data
def getOnePageStock(number,fields):
data=getHtml(number,fields)
datas=data[0].split("},{")#分割
datas[0]=datas[0].replace("{","")#去除开头的{
datas[0]=datas[0].replace("}","")#去除结尾的}
stocks=[]
for i in range(len(datas)):
# 用re的split方法通过正则匹配可以实现以多个分割关键字分割字符串
stock=re.split('[:,]',datas[i].replace('"',""))
tb.add_row([stock[7],stock[9],stock[5],stock[1],stock[3]])
stocks.append(stock)
def main():
number=300140 #自定义查询的股票代码
fields = "f44,f45,f46,f57,f58"# f44:今日最高,f45:今日最低,f45:今开,f57:股票代码,f58:股票名称
try:
getOnePageStock(number,fields)
print(tb)
except:
print("目标不存在")
main()运行结果

心得体会
实现这个内容只要在第二题基础上稍作修改即可,原本的fs选定股票的字典也可以删除,寻找动态js和field的方法与上题相同,还可以在做一些优化,url的一些参数感觉还是影响到查询结果,但是没观察出来。