作业
No.1——UniversitiesRanking
题目要求
用requests和BeautifulSoup库爬取网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
代码部分
import bs4
import urllib.request
Url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
#获取指定网站的html并编码
req=urllib.request.urlopen(Url)
data=req.read()
html=data.decode()
#装载html
s=bs4.BeautifulSoup(html,'html.parser')
#定位到大学的名字
tags=s.select("a[href$='university']")#匹配href以university为结尾的a节点
print("排名 学校名称 省市 类型 总分")
for i in tags:
name=i.parent
print(i)
ranking=name.previous_sibling #寻找前一个兄弟结点
city=name.next_sibling #寻找下一个兄弟节点
typing=city.next_sibling
score=typing.next_sibling
print(ranking.text.strip()+' '+i.text.strip()+' '+city.text.strip()+' '+typing.text.strip()+' '+score.text.strip())最终部分结果如下图
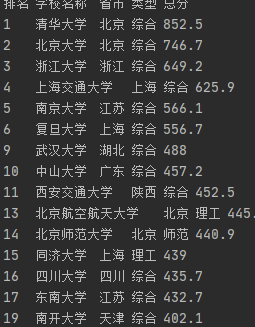
心得体会
解题过程
1.格式提取
获取html以后观察其中一个大学的html格式如图
Url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
tar=urllib.request.urlopen(Url)
html=tar.read().decode() 发现大学名字前面总是有大学的英文拼写,且都以university结尾,想到可以用[attName$=value]来匹配attName属性以value结尾的结点来定位学校名称,并调用select方法查找符合表达式的结点。
发现大学名字前面总是有大学的英文拼写,且都以university结尾,想到可以用[attName$=value]来匹配attName属性以value结尾的结点来定位学校名称,并调用select方法查找符合表达式的结点。
2.获取兄弟节点
利用previous_sibling()和next_sibling()获取前后兄弟结点,也就是学校的排名、省市、类型、总分等结点,但是在测试的时候出现了错误,测试代码如下
tags=s.select("a[href$='university']")
for i in tags:
ranking=i.previous_sibling
print(ranking)但是却输出了

于是查看了tags(也就是上面select出来的html)
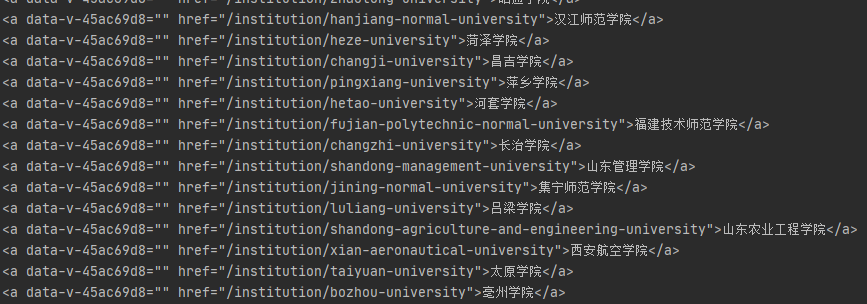
预期中想定位到前面排名的值的结点,然而这与上上图的i并不是兄弟关系,而与i的父节点是兄弟关系
于是修改了测试代码
tags=s.select("a[href$='university']")
for i in tags:
ranking=i.parent.previous_sibling
print(ranking)成功获取到了排名所在的结点
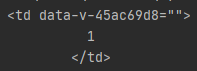
之后的排名等属性值也按照这样获取即可
3.输出结果
对ranking调用text方法获取结点的文本内容,但是问题又出现了

获取文本内容以后保留了原本的格式,影响输出,查询资料以后使用strip()方法可以清除格式

No.2——GoodsPrice
题目要求
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码部分
import requests
import re
from bs4 import BeautifulSoup
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
keyword = "键盘"
#获取html文件
url = 'https://search.jd.com/Search?keyword='+keyword
r = requests.get(url, headers=headers)
html = r.text
#载入html文档
soup = BeautifulSoup(html, 'html.parser')
allItem=soup.select("div[class='gl-i-wrap']")
#格式筛选与输出
print("{:4} {:10}".format("价格", "商品名称"))
for i in range(30):
productPrice = allItem[i].select("div[class='p-price'] i") #获取商品价格的结点 productPrice是一个列表
price=productPrice[0].text
producttitle = allItem[i].select("div[class='p-name p-name-type-2'] em")#获取商品名称的结点
title=producttitle[0].text.replace('
','')
print("{:4} {:10}".format(price, title))
最终部分结果如下图
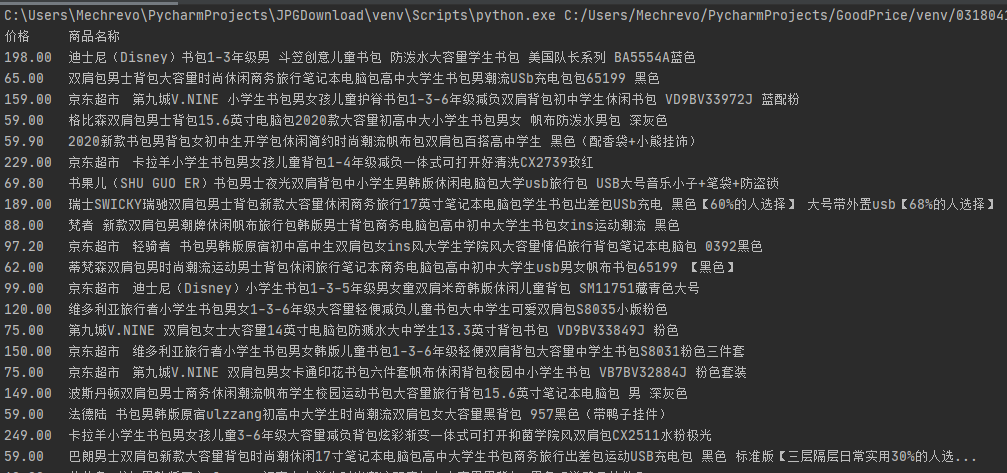
心得体会
解题过程
1.格式提取
获取的html源代码如下图
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
keyword = "书包"
url = 'https://search.jd.com/Search?keyword='+keyword
r = requests.get(url, headers=headers)
html = r.text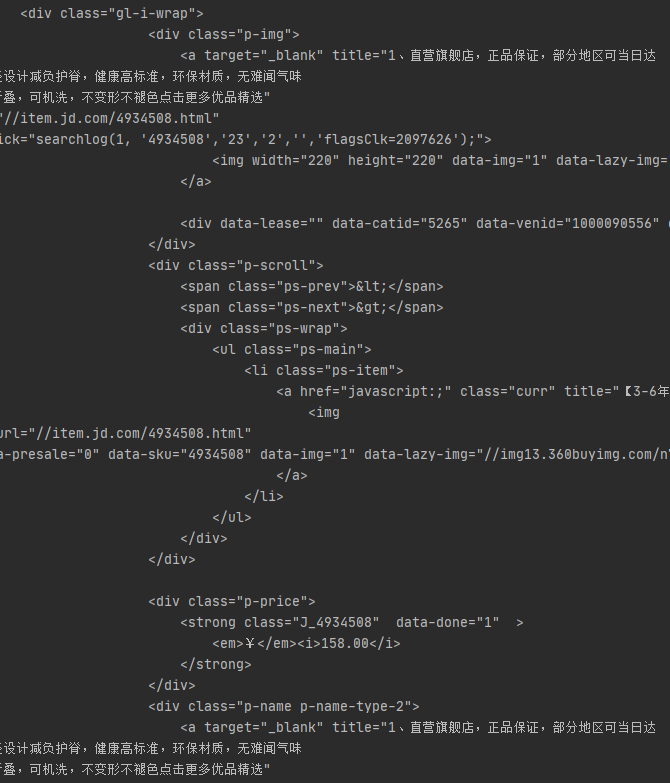
找到了价格和商品名称对应的div结点,class分别为p-price和p-name p-name-type-2,而他们的父节点的class名为gl-i-wrap,所以用select方法将class名为gl-i-wrap的div结点选择出来
soup = BeautifulSoup(html, 'html.parser')
allItem=soup.select("div[class='gl-i-wrap']")2.获取子节点
价格所在的div class=p-price结点的html如图

根据属性语法规则,选择class属性为p-price的div结点选择器为"div[class='p-price']",然后直接定位到价格的结点i,查找子孙结点的格式为"div[class='p-price'] i",就可以直接定位到价格
productPrice = allItem[i].select("div[class='p-price'] i")
print(productPrice[0])
获取商品名称也与上相似,只是匹配内容改一下而已
3.结果输出
还是调用text方法获取结点内的文本,在测试输出商品名称的时候,发现有些商品前缀有写明室隶属于京东超市或者京品数码等所属,在输出的时候有换行符,导致格式不正确

于是用replace方法,将换行符替换为空
replace('
','')之后就按形式输出表头
print("{:4} {:10}".format("价格", "商品名称"))print("{:4} {:10}".format(price, title))No.3——JPGFileDownload
题目要求
爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
代码部分
import requests
import bs4
import os
#获取html文件
url=requests.get("http://xcb.fzu.edu.cn")
html=url.text
#加载html文档
soup = bs4.BeautifulSoup(html,'html.parser')
imgList=soup.select("img[src$='jpg']") #存储img结点
srcList=[] #用于存储src
#获取src的值
for i in imgList:
srcList.append(i.get("src"))
for src in srcList:
#src链接格式化
if src[0]=='/':
src='http://xcb.fzu.edu.cn'+src
#写入图片
with open("./File/"+os.path.basename(src),'wb') as f:
f.write(requests.get(src).content)
print(os.path.basename(src)+"下载成功")
代码运行结果如下
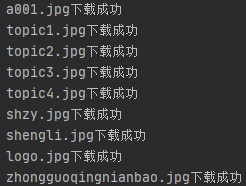
下载结果

心得体会
解题过程
1.格式提取
url=requests.get("http://xcb.fzu.edu.cn")
html=url.text
soup = bs4.BeautifulSoup(html,'html.parser')获取了福州大学宣传部的html,其中一部分jpg图片的格式如下图

发现只要select img结点就可以获取所有图片的结点了
imgList=soup.select("img")获取以后发现,网站内不止有jpg的图片,也有png和gif

于是用属性匹配规则,只选取以jpg为结尾的结点
imgList=soup.select("img[src$='jpg']")2.下载文件
创建一个File文件夹,用于存储图片
下载图片需要用到src,于是用get方法将上面imgList中吧src提取出来加入到srcList里面
srcList=[]
for i in imgList:
srcList.append(i.get("src"))结果如下图

使用basename方法从src获取文件的名字
下载图片有许多方式,这里参考了https://blog.csdn.net/weixin_43715458/article/details/101283489里面的方案2
for src in srcList:
with open("./File/"+os.path.basename(src),'wb') as f:
f.write(requests.get(src).content)但是出现了错误,无效的url

与同学交流以后发现需要在这类src前面加上源网址才可以获取图片
于是修改为,并添加保存成功的标识
for src in srcList:
if src[0]=='/':
src='http://xcb.fzu.edu.cn'+src
with open("./File/"+os.path.basename(src),'wb') as f:
f.write(requests.get(src).content)
print(os.path.basename(src)+"下载成功")