一、Java基础
1、Java面向对象的三个特征与含义
三大特征是:封装、继承和多态。
封装是指将某事物的属性和行为包装到对象中,这个对象只对外公布需要公开的属性和行为,而这个公布也是可以有选择性的公布给其它对象。在Java中能使用private、protected、public三种修饰符或不用(即默认defalut)对外部对象访问该对象的属性和行为进行限制。
继承是子对象可以继承父对象的属性和行为,亦即父对象拥有的属性和行为,其子对象也就拥有了这些属性和行为。这非常类似大自然中的物种遗传。
多态不是很好解释:更倾向于使用java中的固定用法,即overriding(覆盖)和overload(过载)。多态则是体现在overriding(覆盖)上,而overload(过载)则不属于面向对象中多态的范畴,因为overload(过载)概念在非面向对象中也存在。overriding(覆盖)是面向对象中的多态,因为overriding(覆盖)是与继承紧密联系,是面向对象所特有的。多态是指父对象中的同一个行为能在其多个子对象中有不同的表现。也就是说子对象可以使用重写父对象中的行为,使其拥有不同于父对象和其它子对象的表现,这就是overriding(覆盖)。
2、super 和 this 关键字
在子类构造器中使用super()显示调用父类的构造方法,super()必须写在子类构造方法的第一行,否则编译不通过;
this
属性:this属性表示找到本类的属性,如果本类没有找到则继续查找父类;
方法:this方法表示找到本类的方法,如果本类没有找到则继续查找父类;
构造:必须放在构造方法的首行,不能与super关键字同时出现;
特殊:表示当前对象;
super:
属性:super属性直接在子类之中查找父类中的指定属性,不再查找子类本身属性;
方法:super方法直接在子类之中查找父类中的指定方法,不再查找子类本身方法;
构造:必须放在构造方法首行,不能与this关键字同时出现。
super 和 this 关键字:
(1)调用super()必须写在子类构造方法的第一行,否则编译不通过。每个子类构造方法的第一条语句,都是隐含地调用super(),如果父类没有这种形式的构造函数,那么在编译的时候就会报错。
(2)super从子类中调用父类的构造方法,this()在同一类内调用其它方法。
(3)super()和this()均需放在构造方法内第一行。
(4)尽管可以用this调用一个构造器,但却不能调用两个。
(5)this和super不能同时出现在一个构造函数里面,因为this必然会调用其它的构造函数,其它的构造函数必然也会有super语句的存在,所以在同一个构造函数里面有相同的语句,就失去了语句的意义,编译器也不会通过。
(6)this()和super()都指的是对象,所以,均不可以在static环境中使用。包括:static变量,static方法,static语句块。
(7)从本质上讲,this是一个指向本对象的指针, 然而super是一个Java关键字。
3、访问权限
(1)访问权限修饰词
1)public(公共的):表明该成员变量或方法对所有类或对象都是可见的,所有类或对象都可以直接访问;
2)protected(受保护的):表明成员变量或方法对该类本身&与它在同一个包中的其它类&在其它包中的该类的子类都可见;
3)default(默认的,不加任何访问修饰符):表明成员变量或方法只有自己&其位于同一个包内的类可见;
4)private(私有的):表明该成员变量或方法是私有的,只有当前类对其具有访问权限。
由大到小:public(接口访问权限)、protected(继承访问权限)、包访问权限(没有使用任何访问权限修饰词)、private(私有无法访问)。
protected表示就类用户而言,这是private的,但对于任何继承于此类的导出类或其他任何位于同一个包内的类来说,却是可以访问的(protected也提供了包内访问权限)。
private和protected一般不用来修饰外部类,而public、abstract或final可以用来修饰外部类(如果用private和protected修饰外部类,会使得该类变得访问性受限)。
(2)访问权限注意点:
1)类的访问权限,只能是包访问权限(默认无访问修饰符即可)或者public。若把一个类中的构造器指定为private,则不能访问该类,若要创建该类的对象,则需要在该类的static成员内部创建,如单例模式。
2)如果没能为类访问权限指定一个访问修饰符,默认得到包访问权限,则该类的对象可以由包内任何其他类创建,但是包外不可以。
3)访问权限的控制,也称为具体实现的隐藏。制定规则(如使用访问权限,设定成员所遵守的界限),是防止客户端程序员对类随心所欲而为。
(3)控制对成员的访问权限的两个原因:
使用户不要碰触那些不该碰触的部分,对类内部的操作是必要的,不属于客户端程序员所需接口的一部分;
让类库设计者可以更改类的内部工作方式,而不会对客户端程序员产生重大影响;访问权限控制可以确保不会有任何客户端程序员依赖于类的底层实现的任何部分。
(4)对某成员的访问权的唯一途径:
1)该成员为public;
2)通过不加访问权限修饰词并将其他类放置在同一个包内的方式给成员赋予包访问权;
3)继承技术,访问protected成员;
4)提供访问器和变异器(get/set方法),以读取和改变数值。
4、抽象类
(1)抽象类不能被实例化,实例化的工作应该交由它的子类来完成,它只需要有一个引用即可。
(2)抽象方法必须由子类来进行重写。
(3)只要包含一个抽象方法的类,该类必须要定义成抽象类,不管是否还包含有其他方法。
(4)抽象类中可以包含具体的方法,当然也可以不包含抽象方法。
(5)子类中的抽象方法不能与父类的抽象方法同名。
(6)abstract不能与final并列修饰同一个类。(abstract需要子类去实现,而final表示不能被继承,矛盾。)
(7)abstract 不能与private、static、final或native并列修饰同一个方法。
注意:
A、final修饰的类为终态类,不能被继承,而抽象类是必须被继承的才有其意义的,因此,final是不能用来修饰抽象类的。
B、final修饰的方法为终态方法,不能被重写。而继承抽象类,必须重写其方法。
C、抽象方法是仅声明,并不做实现的方法。
5、值传递与引用传递
值传递:Java中原始数据类型都是值传递,传递的是值的副本,形参的改变不会影响实际参数的值;
引用传递:传递的是引用类型数据,包括String,数组,列表,map,类对象等类型,形参与实参指向的是同一内存地址,因此形参改变会影响实参的值。
6、继承
定义:按照现有类的类型来创建新类 ,无需改变现有类的形式,采用现有类的形式并在其增加新代码,称为继承。通过关键字extends实现。
特点:
(1)当创建一个类时,总在继承。(除非明确指明继承类,否则都是隐式第继承根类Object);
(2)为了继承,一般将所有的数据成员都指定为private,将所有的方法指定为public;
(3)可以将继承视作是对类的复用;
(4)is-a关系用继承;
(5)继承允许对象视为自身的类型或其基类型加以处理;
(6)如果向上转型,不能调用那些新的方法(如Animal an = new Cat(),an是不能调用Cat中有的而Animal中没有的方法,会返回一条编译时出错消息),所以向上转型会丢失具体的类型信息。
注意:
(1)构造方法不能被继承;方法和属性可以被继承;
(2)子类的构造方法隐式地调用父类的不带参数的构造方法;
(3)当父类没有不带参数的构造方法时,子类需要使用super来显示调用父类的构造方法,super指的是对父类的引用;
(4)super关键字必须是构造方法中的第一行语句。特例如下:
当两个方法形成重写关系时,可在子类方法中通过super.run() 形式调用父类的run()方法,其中super.run()不必放在第一行语句,因此此时父类对象已经构造完毕,先调用父类的run()方法还是先调用子类的run()方法是根据程序的逻辑决定的。
7、是否可以继承String类?
答:String 类是final类,不可以被继承。
补充:继承String本身就是一个错误的行为,对String类型最好的重用方式是关联关系(Has-A)和依赖关系(Use-A)而不是继承关系(Is-A)。
8、final关键字
1)使用范围:数据、方法和类。
2)final关键字:final可以修饰属性、方法、类。
3)final修饰类:当一个类被final所修饰时,表示该类是一个终态类,即不能被继承。
4)final修饰方法:当一个方法被final所修饰时,表示该方法是一个终态方法,即不能被重写(Override)。
5)final修饰属性:当一个属性被final所修饰时,表示该属性不能被改写。
(1)final数据:
1)编译时常量:是使用static和 final修饰的常量,全用大写字母命名,且字与字之间用下划线隔开。(不能因为数据是final的就认为在编译时就知道值,在运行时也可以用某数值来初始化某一常量)
2)final修饰基本数据类型和对象引用:对于基本类型,final修饰的数值是恒定不变;而final修饰对象引用,则引用恒定不变(一旦引用被初始化指向一个对象,就不能改为指向另一个对象),但是对象本身的内容可以修改。
3)空白final:空白final是指被声明为final但又未给定初值的域,无论什么情况,编译器都保证空白final在使用被初始化。必须在域的定义处或每个构造器中用表达式对final进行赋值。
4)final参数:final修饰参数后,在方法体中不允许对参数进行更改,只可以读final参数。主要用于向匿名类传递数据。
(2)final方法:
1)使用final修饰方法原因:将方法锁定以及效率问题。将方法锁定:防止任何继承类修改final方法的含义,确保该方法行为保持不变,且不会被覆盖;效率:早期Java实现中同意编译器将针对该方法的所有调用转为内嵌调用。
2)类中所有的private方法都隐式地指定为final的。
(3)final类:
将某个类整体定义为final时,则不能继承该类,不能有子类。
9、static关键字是什么意思?Java中是否可以覆盖(override)一个private或者是static的方法?
static表示静态的意思,可用于修饰成员变量和成员函数,被静态修饰的成员函数只能访问静态成员,不可以访问非静态成员。静态是随着类的加载而加载的,因此可以直接用类进行访问。 重写是子类中的方法和子类继承的父类中的方法一样(函数名,参数,参数类型,返回值类型),但是子类中的访问权限要不低于父类中的访问权限。重写的前提是必须要继承,private修饰不支持继承,因此被私有的方法不可以被重写。静态方法形式上可以被重写,即子类中可以重写父类中静态的方法。但是实际上从内存的角度上静态方法不可以被重写。
①static可以修饰内部类,但是不能修饰普通类。静态内部类的话可以直接调用静态构造器(不用对象)。
②static修饰方法,static 方法就是没有 this 的方法。在static方法内部不能调用非静态方法,反过来是可以的。而且可以在没有创建任何对象的前提下,仅仅通过类本身来调用 static 方法。这实际上正是 static 方法的主要用途,方便在没有创建对象的情况下来进行调用(方法/变量)。
最常见的static方法就是main,因为所有对象都是在该方法里面实例化的,而main是程序入口,所以要通过类名来调用。还有就是main中需要经常访问随类加载的成员变量。
③static修饰变量,就变成了静态变量,随类加载一次,可以被多个对象共享。
④static修饰代码块,形成静态代码块,用来优化程序性能,将需要加载一次的代码设置成随类加载,静态代码块可以有多个。
Java中static方法不能被覆盖,因为方法覆盖是基于运行时动态绑定的,而static方法是编译时静态绑定的。还有私有的方法不能被继承,子类就没有访问权限,肯定也是不能别覆盖的。
10、static方法能否被重写
在Java中,子类可继承父类中的方法,而不需要重新编写相同的方法。但有时子类并不想原封不动地继承父类的方法,而是想作一定的修改,这就需要采用方法的重写(Override)。方法重写又称方法覆盖。 在《Java编程思想》中提及到:“覆盖”只有在某方法是基类的接口的一部分时才会出现。即,必须能将一个对象向上转型为它的基本类型并调用相同的方法。那么,我们便可以据此来对static方法能否被重写的问题进行验证。
例子:

class StaticSuper{
public static String staticGet(){
return "Base staticGet()";
}
public String dynamicGet(){
return "Base dynamicGet()";
}
}
class StaticSub extends StaticSuper{
public static String staticGet(){
return "Derived staticGet()";
}
public String dynamicGet(){
return "Derived dynamicGet()";
}
}
public class StaticPolyMorphism {
public static void main(String[] args) {
StaticSuper sup = new StaticSub();
System.out.println(sup.staticGet());
System.out.println(sup.dynamicGet());
}
}
在例子中,如果基类StaticSuper中的static方法staticGet()在子类StaticSub中被重写了,那么sup.staticGet()返回的结果应该是“Derived staticGet()”,实际上结果是如何呢?运行程序后,我们看到输出是:
Base staticGet() Derived dynamicGet()
这说明,非静态方法dynamicGet()的确在子类中被重写了,而静态方法staticGet()却没有。对于这一点,我们也可以通过在子类方法上添加@Overide注解进行验证:
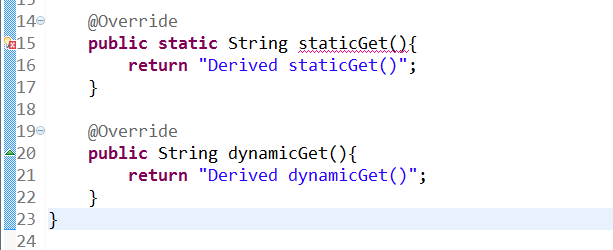
如图所示,在子类中的静态方法staticGet()上添加@Override注解会导致编译报错:The method staticGet() of type StaticSub must override or implement a supertype method(StaticSub类的staticGet()方法必须覆盖或者实现一个父型的方法),而非静态方法dynamicGet()则无此报错信息,这也就印证了我们上面的推论。其实,在Java中,如果父类中含有一个静态方法,且在子类中也含有一个返回类型、方法名、参数列表均与之相同的静态方法,那么该子类实际上只是将父类中的该同名方法进行了隐藏,而非重写。换句话说,父类和子类中含有的其实是两个没有关系的方法,它们的行为也并不具有多态性。正如同《Java编程思想》中所说:“一旦你了解了多态机制,可能就会认为所有事物都可以多态地发生。然而,只有普通方法的调用可以是多态的。”这也很好地理解了,为什么在Java中,static方法和final方法(private方法属于final方法)是前期绑定,而其他所有的方法都是后期绑定了。
11、静态方法和实例方法的区别
(1)在外部调用静态方法时,可以使用"类名.方法名"的方式,也可以使用"对象名.方法名"的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。
(2)静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。
例子1:调用静态方法示例
package com.demo;
public class hasStaticMethod {
//定义一个静态方法
public static void callMe(){
System.out.println("This is a static method.");
}
}
package com.demo;
public class invokeStaticMethod {
//下面这个程序使用两种形式来调用静态方法。
public static void main(String args[]){
hasStaticMethod.callMe(); //不创建对象,直接调用静态方法
hasStaticMethod oa = new hasStaticMethod(); //创建一个对象
oa.callMe(); //利用对象来调用静态方法}
}
}
程序两次调用静态方法,都是允许的,程序的输出如下:
This is a static method. This is a static method.
例子2:静态方法访问成员变量示例
package com.demo;
public class accessMember {
private static int sa; //定义一个静态成员变量
private int ia; //定义一个实例成员变量
//下面定义一个静态方法
static void statMethod(){
int i = 0; //正确,可以有自己的局部变量
sa = 10; //正确,静态方法可以使用静态变量
otherStat(); //正确,可以调用静态方法
ia = 20; //错误,不能使用实例变量
insMethod(); //错误,不能调用实例方法
}
static void otherStat(){}
//下面定义一个实例方法
void insMethod(){
int i = 0; //正确,可以有自己的局部变量
sa = 15; //正确,可以使用静态变量
ia = 30; //正确,可以使用实例变量
statMethod(); //正确,可以调用静态方法
}
}
本例其实可以概括成一句话:静态方法只能访问静态成员,实例方法可以访问静态和实例成员。之所以不允许静态方法访问实例成员变量,是因为实例成员变量是属于某个对象的,而静态方法在执行时,并不一定存在对象。同样,因为实例方法可以访问实例成员变量,如果允许静态方法调用实例方法,将间接地允许它使用实例成员变量,所以它也不能调用实例方法。基于同样的道理,静态方法中也不能使用关键字this。
main()方法是一个典型的静态方法,它同样遵循一般静态方法的规则,所以它可以由系统在创建对象之前就调用。
12、阐述静态变量和实例变量的区别
答:静态变量是被static修饰符修饰的变量,也称为类变量,它属于类,不属于类的任何一个对象,一个类不管创建多少个对象,静态变量在内存中有且仅有一个拷贝;实例变量必须依存于某一实例,需要先创建对象然后通过对象才能访问到它。静态变量可以实现让多个对象共享内存。
13、是否可以从一个静态(static)方法内部发出对非静态(non-static)方法的调用?
答:不可以,静态方法只能访问静态成员,因为非静态方法的调用要先创建对象,在调用静态方法时可能对象并没有被初始化。
14、抽象的(abstract)方法是否可同时是静态的(static),是否可同时是本地方法(native),是否可同时被synchronized修饰?
答:都不能。抽象方法需要子类重写,而静态的方法是无法被重写的,因此二者是矛盾的。本地方法是由本地代码(如C代码)实现的方法,而抽象方法是没有实现的,也是矛盾的。synchronized和方法的实现细节有关,抽象方法不涉及实现细节,因此也是相互矛盾的。
15、阐述final、finally、finalize的区别
- final:修饰符(关键字)有三种用法:如果一个类被声明为final,意味着它不能再派生出新的子类,即不能被继承,因此它和abstract是反义词。将变量声明为final,可以保证它们在使用中不被改变,被声明为final的变量必须在声明时给定初值,而在以后的引用中只能读取不可修改。被声明为final的方法也同样只能使用,不能在子类中被重写。
- finally:通常放在try…catch…的后面构造总是执行代码块,这就意味着程序无论正常执行还是发生异常,这里的代码只要JVM不关闭都能执行,可以将释放外部资源的代码写在finally块中。
- finalize:Object类中定义的方法,Java中允许使用finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在销毁对象时调用的,通过重写finalize()方法可以整理系统资源或者执行其他清理工作。
16、== 与 equals() 方法的区别
(1)基本数据类型与引用数据类型
1)基本数据类型的比较:只能用==;
2)引用数据类型的比较:==是比较栈内存中存放的对象在堆内存地址,equals是比较对象的内容是否相同。
(2)特殊:String作为一个对象
例子一:通过构造函数创建对象时。对象不同,内容相同,"=="返回false,equals返回true。
String s1 = newString("java");
String s2 = new String("java");
System.out.println(s1==s2); //false
System.out.println(s1.equals(s2)); //true
例子二:同一对象,"=="和equals结果相同。
String s1 = new String("java");
String s2 = s1; //两个不同的引用变量指向同一个对象
System.out.println(s1==s2); //true
System.out.println(s1.equals(s2)); //true
String s1 = "java"; String s2 = "java"; //此时String常量池中有java对象,直接返回引用给s2; System.out.println(s1==s2); //true System.out.println(s1.equals(s2)); //true
字面量形式创建对象时:
如果String缓冲池内不存在与其指定值相同的String对象,那么此时虚拟机将为此创建新的String对象,并存放在String缓冲池内。
如果String缓冲池内存在与其指定值相同的String对象,那么此时虚拟机将不为此创建新的String对象,而直接返回已存在的String对象的引用。
(3)String的字面量形式和构造函数创建对象
String s = "aaa"; //采用字面值方式赋值
1)查找StringPool中是否存在“aaa”这个对象,如果不存在,则在String Pool中创建一个“aaa”对象,然后将String Pool中的这个“aaa”对象的地址返回来,赋给引用变量s,这样s会指向String Pool中的这个“aaa”字符串对象;
2)如果存在,则不创建任何对象,直接将String Pool中的这个“aaa”对象地址返回来,赋给s引用。
String s = new String("aaa");
1)首先在String Pool中查找有没有"aaa"这个字符串对象,如果有,则不在String Pool中再去创建"aaa"这个对象,直接在堆中创建一个"aaa"字符串对象,然后将堆中的这个"aaa"对象的地址返回来,赋给s引用,导致s指向了堆中创建的这个"aaa"字符串对象;
2)如果没有,则首先在String Pool中创建一个"aaa"对象,然后再去堆中创建一个"aaa"对象,然后将堆中的这个"aaa"对象的地址返回来,赋给s引用,导致s指向了堆中所创建的这个"aaa"对象。
总结来说:
1)对于==,如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等;如果作用于引用类型的变量,则比较的是所指向的对象的地址。
2)对于equals方法,注意:equals方法不能作用于基本数据类型的变量。如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。
17、初始化及类的加载
(1)加载的含义:通常,加载发生在创建类的第一个对象时,但访问static域或static方法时,也会发生加载。static的东西只会初始化一次。
(2)加载过程:加载一个类的时候,首先去加载父类的静态域,然后再加载自身的静态域,之后去初始化父类的成员变量,后加载父类的构造方法,最后初始化自身的成员变量,后加载自身的构造方法。(先初始化成员变量,后加载构造函数的原因是,构造函数中可能要用到这些成员变量)
父类静态块——子类静态块——父类块——父类构造器——子类块——子类构造器
最终版本:父类静态域——父类静态块——子类静态域——子类静态块——父类成员变量及代码块——父类构造器——子类成员变量及代码块——子类构造器。
(3)加载次数:加载的动作只会加载一次,该类的静态域或第一个实体的创建都会引起加载。
(4)变量的初始化:变量的初始化总是在当前类构造器主体执行之前进行的,且static的成员比普通的成员变量先初始化。
指出下面程序的运行结果
class A {
static {
System.out.print("1");
}
public A() {
System.out.print("2");
}
}
class B extends A{
static {
System.out.print("a");
}
public B() {
System.out.print("b");
}
}
public class Hello {
public static void main(String[] args) {
A ab = new B();
ab = new B();
}
}
答:执行结果:1a2b2b。创建对象时构造器的调用顺序是:先初始化静态成员,然后调用父类构造器,再初始化非静态成员,最后调用自身构造器。
18、多态
(1)多态只发生在普通方法中,对于域和static方法,不发生多态。子类对象转化为父类型引用时,对于任何域的访问都是由编译器解析。静态方法是与类相关联,而不与单个对象相关联;
(2)在继承时,若被覆写的方法不是private,则父类调用方法时,会调用子类的方法,常用的多态性就是当父类引用指向子类对象时。
(3)多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
(4)多态是同一个行为具有多个不同表现形式或形态的能力。
(5)多态就是同一个接口,使用不同的实例而执行不同操作,多态性是对象多种表现形式的体现。
19、基本数据类型与包装类
所有的包装类(8个)都位于java.lang包下,分别是Byte,Short,Integer,Long,Float,Double,Character,Boolean。
基本数据类型:byte:8位;short:16位;int:32位;long:64位;float:32位;double:64位;char:16位;boolean:8位。
20、Object类的公有方法
clone()(protected的)、toString()、equals(Object obj)、hashCode()、getClass()、finialize()(protected的)、notify()/notifyAll()、wait()/wait(long timeout)、wait(long timeout,intnaos)
(1)clone方法
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
主要是JAVA里除了8种基本类型传参数是值传递,其他的类对象传参数都是引用传递,我们有时候不希望在方法里讲参数改变,这是就需要在类中复写clone方法。
(2)getClass方法
final方法,获得运行时类型。
(3)toString方法
该方法用得比较多,一般子类都有覆盖。
(4)finalize方法
该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。
(5)equals方法
该方法是非常重要的一个方法。一般equals和==是不一样的,但是在Object中两者是一样的。子类一般都要重写这个方法。
(6)hashCode方法
该方法用于哈希查找,可以减少在查找中使用equals的次数,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到。
一般必须满足obj1.equals(obj2)==true,可以推出obj1.hashCode()==obj2.hashCode(),但是hashCode相等不一定就满足equals。不过为了提高效率,应该尽量使上面两个条件接近等价。
如果不重写hashcode(),在HashSet中添加两个equals的对象,会将两个对象都加入进去。
(7)wait方法
wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
(7.1)其他线程调用了该对象的notify方法。
(7.2)其他线程调用了该对象的notifyAll方法。
(7.3)其他线程调用了interrupt中断该线程。
(7.4)时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
(8)notify方法
该方法唤醒在该对象上等待的某个线程。
(9)notifyAll方法
该方法唤醒在该对象上等待的所有线程。
21、Hashcode的作用
Hash是散列的意思,就是把任意长度的输入,通过散列算法变换成固定长度的输出,该输出就是散列值。关于散列值,有以下几个关键结论:
(1)、如果散列表中存在和散列原始输入K相等的记录,那么K必定在f(K)的存储位置上。
(2)、不同关键字经过散列算法变换后可能得到同一个散列地址,这种现象称为碰撞。
(3)、如果两个Hash值不同(前提是同一Hash算法),那么这两个Hash值对应的原始输入必定不同。
HashCode
然后讲下什么是HashCode,总结几个关键点:
(1)、HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的。
(2)、如果两个对象equals相等,那么这两个对象的HashCode一定也相同。
(3)、如果对象的equals方法被重写,那么对象的HashCode方法也尽量重写。
(4)、如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置。
HashCode有什么用
回到最关键的问题,HashCode有什么用?不妨举个例子:
(1)、假设内存中有0 1 2 3 4 5 6 7 8这8个位置,如果我有个字段叫做ID,那么我要把这个字段存放在以上8个位置之一,如果不用HashCode而任意存放,那么当查找时就需要到8个位置中去挨个查找。
(2)、使用HashCode则效率会快很多,把ID的HashCode%8,然后把ID存放在取得余数的那个位置,然后每次查找该类的时候都可以通过ID的HashCode%8求余数直接找到存放的位置了。
(3)、如果ID的 HashCode%8算出来的位置上本身已经有数据了怎么办?这就取决于算法的实现了,比如ThreadLocal中的做法就是从算出来的位置向后查找第一个为空的位置,放置数据;HashMap的做法就是通过链式结构连起来。反正,只要保证放的时候和取的时候的算法一致就行了。
(4)、如果ID的 HashCode%8相等怎么办(这种对应的是第三点说的链式结构的场景)?这时候就需要定义equals了。先通过HashCode%8来判断类在哪一个位置,再通过equals来在这个位置上寻找需要的类。对比两个类的时候也差不多,先通过HashCode比较,假如HashCode相等再判断 equals。如果两个类的HashCode都不相同,那么这两个类必定是不同的。
举个实际的例子Set。我们知道Set里面的元素是不可以重复的,那么如何做到?Set是根据equals()方法来判断两个元素是否相等的。比方说Set里面已经有1000个元素了,那么第1001个元素进来的时候,最多可能调用1000次equals方法,如果equals方法写得复杂,对比的东西特别多,那么效率会大大降低。使用HashCode就不一样了,比方说HashSet,底层是基于HashMap实现的,先通过HashCode取一个模,这样一下子就固定到某个位置了,如果这个位置上没有元素,那么就可以肯定HashSet中必定没有和新添加的元素equals的元素,就可以直接存放了,都不需要比较;如果这个位置上有元素了,逐一比较,比较的时候先比较HashCode,HashCode都不同接下去都不用比了,肯定不一样,HashCode相等,再equals比较,没有相同的元素就存,有相同的元素就不存。如果原来的Set里面有相同的元素,只要HashCode的生 成方式定义得好(不重复),不管Set里面原来有多少元素,只需要执行一次的equals就可以了。这样一来,实际调用equals方法的次数大大降低,提高了效率。
22、两个对象值相同(x.equals(y) == true),但却可有不同的hashcode,这句话对不对?
答:不对,如果两个对象x和y满足x.equals(y) == true,它们的哈希码(hashcode)应当相同。Java对于eqauls方法和hashCode方法是这样规定的:
(1) 如果两个对象相同(equals方法返回true),那么它们的hashCode值一定要相同;
(2) 如果两个对象的hashCode相同,它们并不一定相同。
当然,你未必要按照要求去做,但是如果你违背了上述原则就会发现在使用容器时,相同的对象可以出现在Set集合中,同时增加新元素的效率会大大下降(对于使用哈希存储的系统,如果哈希码频繁的冲突将会造成存取性能急剧下降)。
23、重写equals()方法为什么要重写hashcode()方法?
object对象中的 public boolean equals(Object obj),对于任何非空引用值 x 和 y,当且仅当 x 和 y 引用同一个对象时,此方法才返回 true;
注意:当此方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。如下:
(1)当obj1.equals(obj2)为true时,obj1.hashCode() == obj2.hashCode()必须为true
(2)当obj1.hashCode() == obj2.hashCode()为false时,obj1.equals(obj2)必须为false
如果不重写equals,那么比较的将是对象的引用是否指向同一块内存地址,重写之后目的是为了比较两个对象的value值是否相等。特别指出利用equals比较八大包装对象(如int,float等)和String类(因为该类已重写了equals和hashcode方法)对象时,默认比较的是值,在比较其它自定义对象时都是比较的引用地址。
hashcode是用于散列数据的快速存取,如利用HashSet/HashMap/Hashtable类来存储数据时,都是根据存储对象的hashcode值来进行判断是否相同的。
这样如果我们对一个对象重写了equals,意思是只要对象的成员变量值都相等那么equals就等于true,但不重写hashcode,那么我们再new一个新的对象,当原对象.equals(新对象)等于true时,两者的hashcode却是不一样的,由此将产生了理解的不一致,如在存储散列集合时(如Set类),将会存储了两个值一样的对象,导致混淆,因此,就也需要重写hashcode()。
24、Override 和 Overload的含义和区别
(1)、Override 特点
1)、覆盖的方法的标志必须要和被覆盖的方法的标志完全匹配,才能达到覆盖的效果;
2)、覆盖的方法的返回值必须和被覆盖的方法的返回一致;
3)、覆盖的方法所抛出的异常必须和被覆盖方法的所抛出的异常一致,或者是其子类;
4)、方法被定义为final不能被重写。
5)、对于继承来说,如果某一方法在父类中是访问权限是private,那么就不能在子类对其进行重写覆盖,如果定义的话,也只是定义了一个新方法,而不会达到重写覆盖的效果。(通常存在于父类和子类之间。)
(2)、Overload 特点
1)、在使用重载时只能通过不同的参数样式。例如,不同的参数类型,不同的参数个数,不同的参数顺序(当然,同一方法内的几个参数类型必须不一样,例如可以是fun(int, float), 但是不能为fun(int, int));
2)、不能通过访问权限、返回类型、抛出的异常进行重载;
3)、方法的异常类型和数目不会对重载造成影响;
4)、重载事件通常发生在同一个类中,不同方法之间的现象。
其具体实现机制:
overload是重载,重载是一种参数多态机制,即代码通过参数的类型或个数不同而实现的多态机制。是一种静态的绑定机制(在编译时已经知道具体执行的是哪个代码段)。
override是覆盖。覆盖是一种动态绑定的多态机制。即在父类和子类中同名元素(如成员函数)有不同的实现代码。执行的是哪个代码是根据运行时实际情况而定的。
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载;重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。重载对返回类型没有特殊的要求。
25、重载(Overload)与覆盖(Override)
重载(overload):对于类的方法(包括从父类中继承的方法),方法名相同,参数列表不同的方法之间就构成了重载关系。这里有两个问题需要注意:
(1)什么叫参数列表?参数列表又叫参数签名,指三样东西:参数的类型,参数的个数,参数的顺序。这三者只要有一个不同就叫做参数列表不同。
(2)重载关系只能发生在同一个类中吗?非也。这时候你要深刻理解继承,要知道一个子类所拥有的成员除了自己显式写出来的以外,还有父类遗传下来的。所以子类中的某个方法和父类中继承下来的方法也可以发生重载的关系。例如,父类中有一个方法是 func(){ ... },子类中有一个方法是 func(int i){ ... },就构成了方法的重载。
大家在使用的时候要紧扣定义,看方法之间是否是重载关系,不用管方法的修饰符和返回类型以及抛出的异常,只看方法名和参数列表。而且要记住,构造器也可以重载。
返回值和异常以及访问修饰符,不能作为重载的条件(因为对于匿名调用,会出现歧义,eg:void a ()和int a() ,如果调用a(),出现歧义)
覆盖(override):如果在子类中定义一个方法,其名称、返回类型及参数签名正好与父类中某个方法的名称、返回类型及参数签名相匹配,那么可以说,子类的方法覆盖了父类的方法。
覆盖 (override):也叫重写,就是在当父类中的某些方法不能满足要求时,子类中改写父类的方法。当父类中的方法被覆盖了后,除非用super关键字,否则就无法再调用父类中的方法了。
发生覆盖的条件:
(1)、“三同一不低” 子类和父类的方法名称,参数列表,返回类型必须完全相同,而且子类方法的访问修饰符的权限不能比父类低。
(2)、子类方法不能抛出比父类方法更多的异常。即子类方法所抛出的异常必须和父类方法所抛出的异常一致,或者是其子类,或者什么也不抛出;
(3)、被覆盖的方法不能是final类型的。因为final修饰的方法是无法覆盖的。
(4)、被覆盖的方法不能为private。否则在其子类中只是新定义了一个方法,并没有对其进行覆盖。
(5)、被覆盖的方法不能为static。所以如果父类中的方法为静态的,而子类中的方法不是静态的,但是两个方法除了这一点外其他都满足覆盖条件,那么会发生编译错误。反之亦然。即子类实例方法不能覆盖父类的静态方法;子类的静态方法也不能覆盖父类的实例方法(编译时报错),总结为方法不能交叉覆盖。即使父类和子类中的方法都是静态的,并且满足覆盖条件,但是仍然不会发生覆盖,因为静态方法是在编译的时候把静态方法和类的引用类型进行匹配。
(6)、父类的抽象方法可以被子类通过两种途径覆盖(即实现和覆盖)。
(7)、父类的非抽象方法可以被覆盖为抽象方法。
方法的覆盖和重载具有以下相同点:
都要求方法同名
都可以用于抽象方法和非抽象方法之间
方法的覆盖和重载具有以下不同点:
方法覆盖要求参数列表(参数签名)必须一致,而方法重载要求参数列表必须不一致。
方法覆盖要求返回类型必须一致,方法重载对此没有要求。
方法覆盖只能用于子类覆盖父类的方法,方法重载用于同一个类中的所有方法(包括从父类中继承而来的方法)
方法覆盖对方法的访问权限和抛出的异常有特殊的要求,而方法重载在这方面没有任何限制。
父类的一个方法只能被子类覆盖一次,而一个方法可以在所有的类中可以被重载多次。
另外,对于属性(成员变量)而言,是不能重载的,只能覆盖。
抽象类和普通类的区别
包含抽象方法的类称为抽象类,但并不意味着抽象类中只能有抽象方法,它和普通类一样,同样可以拥有成员变量和普通的成员方法。注意,抽象类和普通类的主要有三点区别:
1)抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public。
2)抽象类不能用来创建对象;
3)如果一个类继承于一个抽象类,则子类必须实现父类的抽象方法。如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。
26、Interface 与 abstract 类的区别
(1)、abstract class 在Java中表示的是一种继承关系,一个类只能使用一次继承关系。但是,一个类却可以实现多个interface。
(2)、在abstract class 中可以有自己的数据成员,也可以有非abstarct的方法,而在interface中,只能够有静态的不能被修改的数据成员(也就是必须是static final的,不过在 interface中一般不定义数据成员),所有的方法都是public abstract的。
(3)、抽象类中的变量默认是 friendly 型,其值可以在子类中重新定义,也可以重新赋值。接口中定义的变量默认是public static final 型,且必须给其赋初值,所以实现类中不能重新定义,也不能改变其值。
(4)、abstract class和interface所反映出的设计理念不同。其实abstract class表示的是"is-a"关系,interface表示的是"like-a"关系。
(5)、实现抽象类和接口的类必须实现其中的所有方法。抽象类中可以有非抽象方法。接口中则不能有实现方法。
abstract class 和 interface 是 Java语言中的两种定义抽象类的方式,它们之间有很大的相似性。但是对于它们的选择却又往往反映出对于问题领域中的概念本质的理解、对于设计意图的反映是否正确、合理,因为它们表现了概念间的不同的关系。
1、语法层面上的区别
1)抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
2)抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
3)接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
4)一个类只能继承一个抽象类,而一个类却可以实现多个接口。
2、设计层面上的区别
1)抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。举个简单的例子,飞机和鸟是不同类的事物,但是它们都有一个共性,就是都会飞。那么在设计的时候,可以将飞机设计为一个类Airplane,将鸟设计为一个类Bird,但是不能将 飞行 这个特性也设计为类,因此它只是一个行为特性,并不是对一类事物的抽象描述。此时可以将 飞行 设计为一个接口Fly,包含方法fly( ),然后Airplane和Bird分别根据自己的需要实现Fly这个接口。然后至于有不同种类的飞机,比如战斗机、民用飞机等直接继承Airplane即可,对于鸟也是类似的,不同种类的鸟直接继承Bird类即可。从这里可以看出,继承是一个 "是不是"的关系,而 接口 实现则是 "有没有"的关系。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系,比如鸟是否能飞(或者是否具备飞行这个特点),能飞行则可以实现这个接口,不能飞行就不实现这个接口。
2)设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。什么是模板式设计?最简单例子,大家都用过ppt里面的模板,如果用模板A设计了ppt B和ppt C,ppt B和ppt C公共的部分就是模板A了,如果它们的公共部分需要改动,则只需要改动模板A就可以了,不需要重新对ppt B和ppt C进行改动。而辐射式设计,比如某个电梯都装了某种报警器,一旦要更新报警器,就必须全部更新。也就是说对于抽象类,如果需要添加新的方法,可以直接在抽象类中添加具体的实现,子类可以不进行变更;而对于接口则不行,如果接口进行了变更,则所有实现这个接口的类都必须进行相应的改动。
27、try catch finally
(1)finally里面的代码一定会执行的;
(2)当try和catch中有return时,先执行return中的运算结果但是先不返回,然后保存下来计算结果,接着执行finally,最后再返回return的值。
(3)finally中最好不要有return,否则,直接返回,而先前的return中计算后保存的值得不到返回。
28、try 里有return,finally还执行么?
(1)、不管有木有出现异常,finally块中代码都会执行;
(2)、当try和catch中有return时,finally仍然会执行;
(3)、在try语句中,try要把返回的结果放置到不同的局部变量当中,执行finaly之后,从中取出返回结果,因此,即使finaly中对变量进行了改变,但是不会影响返回结果,因为使用栈保存返回值,即使在finaly当中进行数值操作,但是影响不到之前保存下来的具体的值,所以return影响不了基本类型的值,这里使用的栈保存返回值。而如果修改list,map,自定义类等引用类型时,在进入了finaly之前保存了引用的地址, 所以在finaly中引用地址指向的内容改变了,影响了返回值。
总结:
1.影响返回结果的前提是在非 finally 语句块中有 return 且非基本类型
2.不影响返回结果的前提是 非 finally 块中有return 且为基本类型
究其本质 基本类型在栈中存储,返回的是真实的值,而引用类型返回的是其浅拷贝堆地址,所以才会改变。
return的若是对象,则先把对象的副本保存起来,也就是说保存的是指向对象的地址。若对原来的对象进行修改,对象的地址仍然不变,return的副本仍然是指向这个对象,所以finally中对对象的修改仍然有作用。而基本数据类型保存的是原原本本的数据,return保存副本后,在finally中修改都是修改原来的数据。副本中的数据还是不变,所以finally中修改对return无影响。
(4)、finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值。
29、String、StringBuffer 与 StringBuilder的区别
String 类型和StringBuffer的主要性能区别:String是不可变的对象,因此在每次对String 类型进行改变的时候,都会生成一个新的String 对象,然后将指针指向新的String 对象,所以经常改变内容的字符串最好不要用 String ,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,性能就会降低。
使用 StringBuffer 类时,每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。所以多数情况下推荐使用 StringBuffer ,特别是字符串对象经常改变的情况下。
StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder并没有对方法进行加同步锁,所以是非线程安全的。
StringBuilder与StringBuffer有公共父类AbstractStringBuilder(抽象类)。
Java平台提供了两种类型的字符串:String和StringBuffer/StringBuilder,它们可以储存和操作字符串。其中String是只读字符串,也就意味着String引用的字符串内容是不能被改变的。而StringBuffer/StringBuilder类表示的字符串对象可以直接进行修改。StringBuilder是Java 5中引入的,它和StringBuffer的方法完全相同,区别在于它是在单线程环境下使用的,因为它的所有方面都没有被synchronized修饰,因此它的效率也比StringBuffer要高。
30、不可变对象
如果一个对象,在它创建完成之后,不能再改变它的状态,那么这个对象就是不可变的。不能改变状态的意思是,不能改变对象内的成员变量,包括基本数据类型的值不能改变,引用类型的变量不能指向其他的对象,引用类型指向的对象的状态也不能改变。 如何创建不可变类?
(1)将类声明为final,所以它不能被继承。
(2)将所有的成员声明为私有的,这样就不允许直接访问这些成员。
(3)对变量不要提供setter方法。
(4)将所有可变的成员声明为final,这样只能对它们赋值一次。
(5)通过构造器初始化所有成员,进行深拷贝(deep copy):如果某一个类成员不是原始变量(primitive)或者不可变类,必须通过在成员初始化(in)或者get方法(out)时通过深度clone方法,来确保类的不可变。
(6)在getter方法中,不要直接返回对象本身,而是克隆对象,并返回对象的拷贝。
31、为什么String 要设计成不可变的?
在Java中将String设计成不可变的是综合考虑到各种因素的结果。如内存,同步,数据结构以及安全等方面的考虑。
(1)字符串常量池的需要。字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。但如果字符串是可变的,那么String interning将不能实现(译者注:String interning是指对不同的字符串仅仅只保存一个,即不会保存多个相同的字符串。),因为这样的话,如果变量改变了它的值,那么其它指向这个值的变量的值也会一起改变。
字符串常量池是方法区中一块特殊的存储区域,当创建一个字符串常量的时候,判断该字符串在字符串常量池中是否已经存在。如果存在,返回已经存在的字符串的引用;如果不存在,则创建一个新的字符串常量,并返回其引用。
String string1 = "abcd";
String string2 = "abcd";
变量string1,string2指向常量池中的同一个字符串常量对象;如果String是可变的,给一个变量重新赋值一个引用,将会指向错误的值。
(2)线程安全考虑。 同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。
因为不可变的对象不能被改变,他们可以在多个线程中共享,就不需要使用线程的同步操作。
(3)类加载器要用到字符串,不可变性提供了安全性,以便正确的类被加载。譬如你想加载java.sql.Connection类,而这个值被改成了myhacked.Connection,那么会对你的数据库造成不可知的破坏。
(4)支持hash映射和缓存。 因为字符串是不可变的,所以在它创建的时候hashcode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
在Java中字符串的哈希值会经常被使用到。例如在HashMap中,String的不可变总能保证哈希值总是相等的,并且缓存起来,不用担心会改变,那意味着不需要每次都计算哈希值,这样会提高效率。
总之,把String设计为不可变,是为了提高效率和安全性。在广泛的设计开发中,不可变类是首要选择。
String类不可变性的好处
(1)只有当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字 符串。但如果字符串是可变的,那么String interning将不能实现(译者注:String interning是指对不同的字符串仅仅只保存一个,即不会保存多个相同的字符串。),因为这样的话,如果变量改变了它的值,那么其它指向这个值的变量 的值也会一起改变。
(2)如果字符串是可变的,那么会引起很严重的安全问题。譬如,数据库的用户名、密码都是以字符串的形式传入来获得数据库的连 接,或者在socket编程中,主机名和端口都是以字符串的形式传入。因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变字符 串指向的对象的值,造成安全漏洞。
(3)因为字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。
(4)类加载器要用到字符串,不可变性提供了安全性,以便正确的类被加载。譬如你想加载java.sql.Connection类,而这个值被改成了myhacked.Connection,那么会对你的数据库造成不可知的破坏。
(5)因为字符串是不可变的,所以在它创建的时候hashcode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
32、内部类可以引用它的包含类(外部类)的成员吗?有没有什么限制?
答:一个内部类对象可以访问创建它的外部类对象的成员,包括私有成员。
33、静态嵌套类(Static Nested Class)和内部类(Inner Class)的不同?
Static Nested Class是被声明为静态(static)的内部类,它可以不依赖于外部类实例被实例化。而通常的内部类需要在外部类实例化后才能实例化。
看下面的代码哪些地方会产生编译错误?
package com.demo;
public class Outer {
class Inner {}
public static void foo() { new Inner(); }
public void bar() { new Inner(); }
public static void main(String[] args) {
new Inner();
}
}
注意:Java中非静态内部类对象的创建要依赖其外部类对象,上面的面试题中foo和main方法都是静态方法,静态方法中没有this,也就是说没有所谓的外部类对象,因此无法创建内部类对象,如果要在静态方法中创建内部类对象,可以这样做:
package com.demo;
public class Outer {
class Inner {}
public static void foo() { new Outer().new Inner(); }
public void bar() { new Inner(); }
public static void main(String[] args) {
new Outer().new Inner();
}
}
34、错误和异常的区别(Error vs Exception)
java.lang.Error:Throwable 的子类,用于标记严重错误,表示系统级的错误和程序不必处理的异常。合理的应用程序不应该去 try/catch 这种错误。是恢复不是不可能但很困难的情况下的一种严重问题;比如内存溢出,不可能指望程序能处理这样的情况; java.lang.Exception:Throwable 的子类,表示需要捕捉或者需要程序进行处理的异常,是一种设计或实现问题;也就是说,它表示如果程序运行正常,从不会发生的情况。并且鼓励用户程序去 catch 它。
35、IO 和 NIO的主要区别
(1)面向流与面向缓冲。Java IO和NIO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。
(2)阻塞与非阻塞IO。Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
(3)选择器(Selectors)。Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
Java内存模型
Java虚拟机规范中试图定义一种Java内存模型(Java Memory Model,JMM)来屏蔽掉各种硬件和操作系统的访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果。在此之前,主流程序语言(如C/C++等)直接使用物理硬件和操作系统的内存模型,因此,会由于不同平台上内存模型的差异,有可能导致程序在一套平台上并发完全正常,而在另外一套平台上并发访问却经常出错,因此在某些场景下就不许针对不同的平台来编写程序。
Java内存模型的主要目的是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。注意一下,此处的变量并不包括局部变量与方法参数,因为它们是线程私有的,不会被共享,自然也不会存在竞争,此处的变量应该是实例字段、静态字段和构成数组对象的元素。
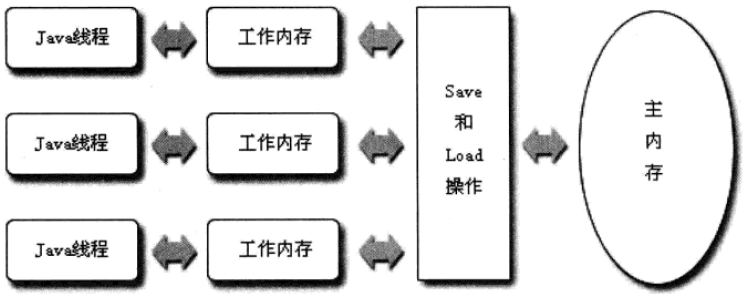
Java内存模型中规定了所有的变量都存储在主内存中(如虚拟机物理内存中的一部分),每条线程还有自己的工作内存(如CPU中的高速缓存),线程的工作内存中保存了该线程使用到的变量到主内存的副本拷贝,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成,线程、主内存和工作内存的交互关系如下图所示:
二、Java集合
36、ArrayList、LinkedList、Vector的区别
ArrayList,Vector底层是由数组实现,LinkedList底层是由双向链表实现,从底层的实现可以得出它们的性能问题,ArrayList,Vector插入速度相对较慢,查询速度相对较快,而LinkedList插入速度较快,而查询速度较慢。再者由于Vevtor使用了线程安全锁,所以ArrayList的运行效率高于Vector。
37、Map、Set、List、Queue、Stack的特点与用法
Collection 接口的接口 对象的集合
├ List 子接口 按进入先后有序保存 可重复
│├ LinkedList 接口实现类 链表 插入删除 没有同步 线程不安全
│├ ArrayList 接口实现类 数组 随机访问 没有同步 线程不安全
│└ Vector 接口实现类 数组 同步 线程安全
│ └ Stack
└ Set 子接口 仅接收一次,并做内部排序
├ HashSet
│ └ LinkedHashSet
└ TreeSet
对于List ,关心的是顺序,它保证维护元素特定的顺序(允许有相同元素),使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在 List 中的位置,类似于数组下标)来访问 List 中的元素。
对于 Set ,只关心某元素是否属于 Set (不允许有相同元素 ),而不关心它的顺序。
Map 接口 键值对的集合
├ Hashtable 接口实现类 同步 线程安全
├ HashMap 接口实现类 没有同步 线程不安全
│├ LinkedHashMap
│└ WeakHashMap
├ TreeMap
└ IdentifyHashMap
对于 Map ,最大的特点是键值映射,且为一一映射,键不能重复,值可以,所以是用键来索引值。方法 put(Object key, Object value) 添加一个“值” ( 想要得东西 ) 和与“值”相关联的“键” (key) ( 使用它来查找 ) 。方法 get(Object key) 返回与给定“键”相关联的“值”。
Map 同样对每个元素保存一份,但这是基于 " 键 " 的, Map 也有内置的排序,因而不关心元素添加的顺序。如果添加元素的顺序对你很重要,应该使用 LinkedHashSet 或者 LinkedHashMap.
对于效率, Map 由于采用了哈希散列,查找元素时明显比 ArrayList 快。
更为精炼的总结:
Collection 是对象集合, Collection 有两个子接口 List 和 Set。List 可以通过下标 (1,2..) 来取得值,值可以重复。而 Set 只能通过游标来取值,并且值是不能重复的。ArrayList , Vector , LinkedList 是 List 的实现类。ArrayList 是线程不安全的, Vector 是线程安全的,这两个类底层都是由数组实现的。LinkedList 是线程不安全的,底层是由链表实现的。
Map 是键值对集合。HashTable 和 HashMap 是 Map 的实现类。HashTable 是线程安全的,不能存储 null 值。HashMap 不是线程安全的,可以存储 null 值。
Stack类:继承自Vector,实现一个后进先出的栈。提供了几个基本方法,push、pop、peak、empty、search等。
Queue接口:提供了几个基本方法,offer、poll、peek等。已知实现类有LinkedList、PriorityQueue等。
38、HashMap 和 HashTable的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
39、HashMap的工作原理
1)存储:
当程序试图将多个 key-value 放入 HashMap 中时,以如下代码片段为例:
HashMap<String , Double> map = new HashMap<String , Double>();
map.put("语文" , 80.0);
map.put("数学" , 89.0);
map.put("英语" , 78.2);
HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置。
当程序执行 map.put("语文" , 80.0); 时,系统将调用"语文"的 hashCode() 方法得到其 hashCode 值——每个 Java 对象都有 hashCode() 方法,都可通过该方法获得它的 hashCode 值。得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置。我们可以看 HashMap 类的 put(K key , V value) 方法的源代码:
public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的keyCode重新计算hash值。
int hash = hash(key.hashCode());
// 搜索指定hash值在对应table中的索引。
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引处的Entry为null,表明此处还没有Entry。
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return null;
}
从上面的源代码中可以看出:当我们往HashMap中put元素的时候,先根据key的hashCode重新计算hash值,根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
上面程序中用到了一个重要的内部接口:Map.Entry,每个 Map.Entry 其实就是一个 key-value 对。从上面程序中可以看出:当系统决定存储 HashMap 中的 key-value 对时,完全没有考虑 Entry 中的 value,仅仅只是根据 key 来计算并决定每个 Entry 的存储位置。我们完全可以把 Map 集合中的 value 当成 key 的附属,当系统决定了 key 的存储位置之后,value 随之保存在那里即可。
上面方法提供了一个根据 hashCode() 返回值来计算 Hash 码的方法:hash(),这个方法是一个纯粹的数学计算,其方法如下:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用 hash(int h) 方法所计算得到的 Hash 码值总是相同的。接下来程序会调用 indexFor(int h, int length) 方法来计算该对象应该保存在 table 数组的哪个索引处。indexFor(int h, int length) 方法的代码如下:
static int indexFor(int h, int length) {
return h & (length-1);
}
这个方法非常巧妙,它总是通过 h &(table.length -1) 来得到该对象的保存位置——而 HashMap 底层数组的长度总是 2 的 n 次方,这一点可参看后面关于 HashMap 构造器的介绍。
当 length 总是 2 的倍数时,h & (length-1) 将是一个非常巧妙的设计:假设 h=5,length=16, 那么 h & length - 1 将得到 5;如果 h=6,length=16, 那么 h & length - 1 将得到 6 ……如果 h=15,length=16, 那么 h & length - 1 将得到 15;但是当 h=16 ,length=16 时,那么 h & length - 1 将得到 0 了;当 h=17 ,length=16 时,那么 h & length - 1 将得到 1 了……这样保证计算得到的索引值总是位于 table 数组的索引之内。
根据上面 put 方法的源代码可以看出,当程序试图将一个 key-value 对放入 HashMap 中时,程序首先根据该 key 的 hashCode() 返回值决定该 Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry 的 value,但 key 不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部——具体说明继续看 addEntry() 方法的说明。
当向 HashMap 中添加 key-value 对,由其 key 的 hashCode() 返回值决定该 key-value 对(就是 Entry 对象)的存储位置。当两个 Entry 对象的 key 的 hashCode() 返回值相同时,将由 key 通过 eqauls() 比较值决定是采用覆盖行为(返回 true),还是产生 Entry 链(返回 false)。
上面程序中还调用了 addEntry(hash, key, value, i); 代码,其中 addEntry 是 HashMap 提供的一个包访问权限的方法,该方法仅用于添加一个 key-value 对。下面是该方法的代码:
void addEntry(int hash, K key, V value, int bucketIndex) {
// 获取指定 bucketIndex 索引处的 Entry
Entry<K,V> e = table[bucketIndex]; // ①
// 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 如果 Map 中的 key-value 对的数量超过了极限
if (size++ >= threshold)
// 把 table 对象的长度扩充到原来的2倍。
resize(2 * table.length); // ②
}
上面方法的代码很简单,但其中包含了一个非常优雅的设计:系统总是将新添加的 Entry 对象放入 table 数组的 bucketIndex 索引处——如果 bucketIndex 索引处已经有了一个 Entry 对象,那新添加的 Entry 对象指向原有的 Entry 对象(产生一个 Entry 链),如果 bucketIndex 索引处没有 Entry 对象,也就是上面程序①号代码的 e 变量是 null,也就是新放入的 Entry 对象指向 null,也就是没有产生 Entry 链。
2)读取:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
有了上面存储时的hash算法作为基础,理解起来这段代码就很容易了。从上面的源代码中可以看出:从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
3) 归纳起来简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。
40、List、Set、Map是否继承自Collection接口?
答:List、Set 是,Map 不是。Map是键值对映射容器,与List和Set有明显的区别,而Set存储的零散的元素且不允许有重复元素(数学中的集合也是如此),List是线性结构的容器,适用于按数值索引访问元素的情形。
41、Collection和Collections的区别?
答:Collection是一个接口,它是Set、List等容器的父接口;Collections是一个工具类,提供了一系列的静态方法来辅助容器操作,这些方法包括对容器的搜索、排序、线程安全化等等。
42、List、Map、Set三个接口存取元素时,各有什么特点?
答:List以特定索引来存取元素,可以有重复元素。Set不能存放重复元素(用对象的equals()方法来区分元素是否重复)。Map保存键值对(key-value pair)映射,映射关系可以是一对一或多对一。Set和Map容器都有基于哈希存储和排序树的两种实现版本,基于哈希存储的版本理论存取时间复杂度为O(1),而基于排序树版本的实现在插入或删除元素时会按照元素或元素的键(key)构成排序树从而达到排序和去重的效果。
43、HashMap、HashTable、LinkedHashMap、TreeMap的区别
Map主要用于存储键值对,根据键得到值,因此不允许键重复(重复了覆盖了),但允许值重复。
Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。HashMap最多只允许一条记录的键为Null,允许多条记录的值为 Null。HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。
Hashtable与 HashMap类似,它继承自Dictionary类,不同的是:它不允许记录的键或者值为空,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了 Hashtable在写入时会比较慢。
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
一般情况下,我们用的最多的是HashMap,HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。
三、Spring相关
44、IOC(Inversion of Control)的理解
(1)、IoC(Inversion of Control)是指容器控制程序对象之间的关系,而不是传统实现中,由程序代码直接操控。控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。 对于Spring而言,就是由Spring来控制对象的生命周期和对象之间的关系;IoC还有另外一个名字——“依赖注入(Dependency Injection)”。从名字上理解,所谓依赖注入,即组件之间的依赖关系由容器在运行期决定,即由容器动态地将某种依赖关系注入到组件之中。
(2)、在Spring的工作方式中,所有的类都会在spring容器中登记,告诉spring这是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
(3)、在系统运行中,动态的向某个对象提供它所需要的其他对象。
(4)、依赖注入的思想是通过反射机制实现的,在实例化一个类时,它通过反射调用类中set方法将事先保存在HashMap中的类属性注入到类中。 总而言之,在传统的对象创建方式中,通常由调用者来创建被调用者的实例,而在Spring中创建被调用者的工作由Spring来完成,然后注入调用者,即所谓的依赖注入or控制反转。 注入方式有两种:依赖注入和设置注入; IoC的优点:降低了组件之间的耦合,降低了业务对象之间替换的复杂性,使之能够灵活的管理对象。
IOC的实现原理
Spring中的IOC的实现原理就是工厂模式加反射机制。 我们首先看一下不用反射机制时的工厂模式:
interface fruit{
public abstract void eat();
}
class Apple implements fruit{
public void eat(){
System.out.println("Apple");
}
}
class Orange implements fruit{
public void eat(){
System.out.println("Orange");
}
}
//构造工厂类
//也就是说以后如果我们在添加其他的实例的时候只需要修改工厂类就行了
class Factory{
public static fruit getInstance(String fruitName){
fruit f=null;
if("Apple".equals(fruitName)){
f=new Apple();
}
if("Orange".equals(fruitName)){
f=new Orange();
}
return f;
}
}
class hello{
public static void main(String[] a){
fruit f=Factory.getInstance("Orange");
f.eat();
}
}
上面写法的缺点是当我们再添加一个子类的时候,就需要修改工厂类了。如果我们添加太多的子类的时候,改动就会很多。下面用反射机制实现工厂模式:
interface fruit{
public abstract void eat();
}
class Apple implements fruit{
public void eat(){
System.out.println("Apple");
}
}
class Orange implements fruit{
public void eat(){
System.out.println("Orange");
}
}
class Factory{
public static fruit getInstance(String ClassName){
fruit f=null;
try{
f=(fruit)Class.forName(ClassName).newInstance();
}catch (Exception e) {
e.printStackTrace();
}
return f;
}
}
class hello{
public static void main(String[] a){
fruit f=Factory.getInstance("Reflect.Apple");
if(f!=null){
f.eat();
}
}
}
现在就算我们添加任意多个子类的时候,工厂类都不需要修改。使用反射机制实现的工厂模式可以通过反射取得接口的实例,但是需要传入完整的包和类名。而且用户也无法知道一个接口有多少个可以使用的子类,所以我们通过属性文件的形式配置所需要的子类。
下面编写使用反射机制并结合属性文件的工厂模式(即IoC)。首先创建一个fruit.properties的资源文件:
apple=Reflect.Apple orange=Reflect.Orange
然后编写主类代码:
interface fruit{
public abstract void eat();
}
class Apple implements fruit{
public void eat(){
System.out.println("Apple");
}
}
class Orange implements fruit{
public void eat(){
System.out.println("Orange");
}
}
//操作属性文件类
class init{
public static Properties getPro() throws FileNotFoundException, IOException{
Properties pro=new Properties();
File f=new File("fruit.properties");
if(f.exists()){
pro.load(new FileInputStream(f));
}else{
pro.setProperty("apple", "Reflect.Apple");
pro.setProperty("orange", "Reflect.Orange");
pro.store(new FileOutputStream(f), "FRUIT CLASS");
}
return pro;
}
}
class Factory{
public static fruit getInstance(String ClassName){
fruit f=null;
try{
f=(fruit)Class.forName(ClassName).newInstance();
}catch (Exception e) {
e.printStackTrace();
}
return f;
}
}
class hello{
public static void main(String[] a) throws FileNotFoundException, IOException{
Properties pro=init.getPro();
fruit f=Factory.getInstance(pro.getProperty("apple"));
if(f!=null){
f.eat();
}
}
}
运行结果:Apple
IOC容器的技术剖析
IOC中最基本的技术就是“反射(Reflection)”编程,通俗来讲就是根据给出的类名(字符串方式)来动态地生成对象,这种编程方式可以让对象在生成时才被决定到底是哪一种对象。只是在Spring中要生产的对象都在配置文件中给出定义,目的就是提高灵活性和可维护性。
目前C#、Java和PHP5等语言均支持反射,其中PHP5的技术书籍中,有时候也被翻译成“映射”。有关反射的概念和用法,大家应该都很清楚。反射的应用是很广泛的,很多的成熟的框架,比如像Java中的Hibernate、Spring框架,.Net中NHibernate、Spring.NET框架都是把”反射“做为最基本的技术手段。
反射技术其实很早就出现了,但一直被忽略,没有被进一步的利用。当时的反射编程方式相对于正常的对象生成方式要慢至少得10倍。现在的反射技术经过改良优化,已经非常成熟,反射方式生成对象和通常对象生成方式,速度已经相差不大了,大约为1-2倍的差距。
我们可以把IOC容器的工作模式看做是工厂模式的升华,可以把IOC容器看作是一个工厂,这个工厂里要生产的对象都在配置文件中给出定义,然后利用编程语言提供的反射机制,根据配置文件中给出的类名生成相应的对象。从实现来看,IOC是把以前在工厂方法里写死的对象生成代码,改变为由配置文件来定义,也就是把工厂和对象生成这两者独立分隔开来,目的就是提高灵活性和可维护性。
IOC底层实现原理
底层实现使用的技术:
(1)xml配置文件
(2)dom4j解析xml
(3)工厂模式
(4)反射

首先,通过dom4j将我们的配置文件读取,这时我们就可以解析到所有相关的类的全路径了。然后,它再利用反射机制通过如下代码完成类的实例化:类1=Class.forName("类1的全路径")。这时,我们就得到了类1。(这也是为啥当我们的类的全路径写错了会导致出现classNotfind的错误。)
当我们得到了类1以后,通过调用类1的set方法,将属性给对象进行注入。而且,需要遵循首字母大写的set规范。例如:我们的类中有个字段的属性为name那么set方法必须写成setName(name 的首字母要大写)否则会报一个属性找不到的错误:
public void setName(String name){
this.name= name;
}
对象创建后,我们将我们的对象id和我们的对象物理地址,一起存入类似于HashMap的容器中,然后呢,我们是如何获得我们需要的对象,然后执行对象中的方法呢?我们通过getBean的方法,通过对象Id获得对象的物理地址,得到对象,然后调用对象的方法,完成对方法的调用。
45、AOP(Aspect Oriented Programming)的理解
AOP(Aspect-OrientedProgramming,面向方面编程),可以说是OOP(Object-Oriented Programing,面向对象编程)的补充和完善。说起AOP就不得不说下OOP了,OOP中引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。但是,如果我们需要为部分对象引入公共部分的时候,OOP就会引入大量重复的代码。例如:日志功能。
AOP技术利用一种称为“横切”的技术,解剖封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,这样就能减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处都基本相似。比如权限认证、日志、事务处理。Aop 的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。
Spring实现AOP:JDK动态代理和CGLIB代理。JDK动态代理:其代理对象必须是某个接口的实现,它是通过在运行期间创建一个接口的实现类来完成对目标对象的代理;其核心的两个类是InvocationHandler和Proxy。 CGLIB代理:实现原理类似于JDK动态代理,只是它在运行期间生成的代理对象是针对目标类扩展的子类。CGLIB是高效的代码生成包,底层是依靠ASM(开源的java字节码编辑类库)操作字节码实现的,性能比JDK强;需要引入包asm.jar和cglib.jar。 使用AspectJ注入式切面和@AspectJ注解驱动的切面实际上底层也是通过动态代理实现的。
AOP使用场景:
Authentication 权限检查
Caching 缓存
Context passing 内容传递
Error handling 错误处理
Lazy loading 延迟加载
Debugging 调试
logging, tracing, profiling and monitoring 日志记录,跟踪,优化,校准
Performance optimization 性能优化,效率检查
Persistence 持久化
Resource pooling 资源池
Synchronization 同步
Transactions 事务管理
另外Filter的实现和struts2的拦截器的实现都是AOP思想的体现。
AOP的实现原理
AOP的实现关键在于AOP框架自动创建的AOP代理。AOP代理主要分为两大类:
静态代理:使用AOP框架提供的命令进行编译,从而在编译阶段就可以生成AOP代理类,因此也称为编译时增强;静态代理一Aspectj为代表。
动态代理:在运行时借助于JDK动态代理,CGLIB等在内存中临时生成AOP动态代理类,因此也被称为运行时增强,Spring AOP用的就是动态代理。
AOP分为静态AOP和动态AOP。静态AOP是指AspectJ实现的AOP,他是将切面代码直接编译到Java类文件中。动态AOP是指将切面代码进行动态织入实现的AOP。AspectJ 采用编译时生成 AOP 代理类,因此具有更好的性能,但需要使用特定的编译器进行处理;而 Spring AOP 则采用运行时生成 AOP 代理类,因此无需使用特定编译器进行处理。由于 Spring AOP 需要在每次运行时生成 AOP 代理,因此性能略差一些。Spring的AOP为动态AOP,实现的技术为:JDK提供的动态代理技术 和 CGLIB(动态字节码增强技术)。尽管实现技术不一样,但都是基于代理模式,都是生成一个代理对象。
JDK动态代理
(1)JDK动态代理是面向接口的,必须提供一个委托类和代理类都要实现的接口,只有接口中的方法才能够被代理。
(2)JDK动态代理的实现主要使用java.lang.reflect包里的Proxy类和InvocationHandler接口。
InvocationHandler接口:
说明:每一个动态代理类都必须要实现InvocationHandler这个接口,并且每个代理类的实例都关联到了一个handler,当我们通过代理对象调用一个方法的时候,这个方法的调用就会被转发为由InvocationHandler这个接口的 invoke 方法来进行调用。同时在invoke的方法里 我们可以对被代理对象的方法调用做增强处理(如添加事务、日志、权限验证等操作)。
Proxy类:
Proxy类是专门完成代理的操作类,可以通过此类为一个或多个接口动态地生成实现类。
示例:
定义一个业务接口IUserService,如下:
package com.spring.aop;
public interface IUserService {
//添加用户
public void addUser();
//删除用户
public void deleteUser();
}
一个简单的实现类UserServiceImpl,如下:
package com.spring.aop;
public class UserServiceImpl implements IUserService{
public void addUser(){
System.out.println("新增了一个用户!");
}
public void deleteUser(){
System.out.println("删除了一个用户!");
}
}
现在我们要实现的是,在addUser和deleteUser之前和之后分别动态植入处理。JDK动态代理主要用到java.lang.reflect包中的两个类:Proxy和InvocationHandler。InvocationHandler是一个接口,通过实现该接口定义横切逻辑,并通过反射机制调用目标类的代码,动态的将横切逻辑和业务逻辑编织在一起。Proxy利用InvocationHandler动态创建一个符合某一接口的实例,生成目标类的代理对象。如下,我们创建一个InvocationHandler实例DynamicProxy:(当执行动态代理对象里的目标方法时,实际上会替换成调用DynamicProxy的invoke方法)
package com.spring.aop;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
public class DynamicProxy implements InvocationHandler{
//被代理对象(就是要给这个目标类创建代理对象)
private Object target;
//传递代理目标的实例,因为代理处理器需要,也可以用set等方法。
public DynamicProxy(Object target){
this.target=target;
}
/**
* 覆盖java.lang.reflect.InvocationHandler的方法invoke()进行织入(增强)的操作。
* 这个方法是给代理对象调用的,留心的是内部的method调用的对象是目标对象,可别写错。
* 参数说明:
* proxy是生成的代理对象,method是代理的方法,args是方法接收的参数
*/
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable{
//目标方法之前执行
System.out.println("do sth Before...");
//通过反射机制来调用目标类方法
Object result = method.invoke(target, args);
//目标方法之后执行
System.out.println("do sth After...
");
return result;
}
}
下面是测试:
package com.spring.aop;
//用java.lang.reflect.Proxy.newProxyInstance()方法创建动态实例来调用代理实例的方法
import java.lang.reflect.Proxy;
public class DynamicTest {
public static void main(String[] args){
//希望被代理的目标业务类
IUserService target = new UserServiceImpl();
//将目标类和横切类编织在一起
DynamicProxy handler= new DynamicProxy(target);
//创建代理实例,它可以看作是要代理的目标业务类的加多了横切代码(方法)的一个子类
//创建代理实例(使用Proxy类和自定义的调用处理逻辑(handler)来生成一个代理对象)
IUserService proxy = (IUserService)Proxy.newProxyInstance(
target.getClass().getClassLoader(),//目标类的类加载器
target.getClass().getInterfaces(), //目标类的接口
handler); //横切类
proxy.addUser();
proxy.deleteUser();
}
}
说明:上面的代码完成业务类代码和横切代码的编制工作,并生成了代理实例,newProxyInstance方法的第一个参数为类加载器,第二个参数为目标类所实现的一组接口,第三个参数是整合了业务逻辑和横切逻辑的编织器对象。
每一个动态代理实例的调用都要通过InvocationHandler接口的handler(调用处理器)来调用,动态代理不做任何执行操作,只是在创建动态代理时,把要实现的接口和handler关联,动态代理要帮助被代理执行的任务,要转交给handler来执行。其实就是调用invoke方法。(可以看到执行代理实例的addUser()和deleteUser()方法时执行的是DynamicProxy的invoke()方法。)
运行结果:
基本流程:用Proxy类创建目标类的动态代理,创建时需要指定一个自己实现InvocationHandler接口的回调类的对象,这个回调类中有一个invoke()用于拦截对目标类各个方法的调用。创建好代理后就可以直接在代理上调用目标对象的各个方法。
实现动态代理步骤:
A.创建一个实现接口InvocationHandler的类,他必须实现invoke方法。
B.创建被代理的类以及接口。
C.通过Proxy的静态方法newProxyInstance(ClassLoader loader, Class<?>[]interfaces, InvocationHandler handler)创建一个代理。
D.通过代理调用方法。
使用JDK动态代理有一个很大的限制,就是它要求目标类必须实现了对应方法的接口,它只能为接口创建代理实例。我们在上文测试类中的Proxy的newProxyInstance方法中可以看到,该方法第二个参数便是目标类的接口。如果该类没有实现接口,这就要靠cglib动态代理了。
CGLIB动态代理
CGLib采用非常底层的字节码技术,可以为一个类创建一个子类,并在子类中采用方法拦截的技术拦截所有父类方法的调用,并顺势植入横切逻辑。
字节码生成技术实现AOP,其实就是继承被代理对象,然后Override需要被代理的方法,在覆盖该方法时,自然是可以插入我们自己的代码的。因为需要Override被代理对象的方法,所以自然用CGLIB技术实现AOP时,就必须要求需要被代理的方法不能是final方法,因为final方法不能被子类覆盖。
a.使用CGLIB动态代理不要求必须有接口,生成的代理对象是目标对象的子类对象,所以需要代理的方法不能是private或者final或者static的。
b.使用CGLIB动态代理需要有对cglib的jar包依赖(导入asm.jar和cglib-nodep-2.1_3.jar)
CGLibProxy与JDKProxy的代理机制基本类似,只是其动态代理的代理对象并非某个接口的实现,而是针对目标类扩展的子类。换句话说JDKProxy返回动态代理类,是目标类所实现接口的另一个实现版本,它实现了对目标类的代理(如同UserDAOProxy与UserDAOImp的关系),而CGLibProxy返回的动态代理类,则是目标代理类的一个子类(代理类扩展了UserDaoImpl类)
cglib 代理特点:
CGLIB 是针对类来实现代理,它的原理是对指定的目标类生成一个子类,并覆盖其中方法。因为采用的是继承,所以不能对 finall 类进行继承。
我们使用CGLIB实现上面的例子:
代理的最终操作类:
package com.spring.aop;
import java.lang.reflect.Method;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
public class CglibProxy implements MethodInterceptor{
//增强器,动态代码生成器
Enhancer enhancer = new Enhancer();
/**
* 创建代理对象
* @param clazz
* @return 返回代理对象
*/
public Object getProxy(Class clazz){
//设置父类,也就是被代理的类(目标类)
enhancer.setSuperclass(clazz);
//设置回调(在调用父类方法时,回调this.intercept())
enhancer.setCallback(this);
//通过字节码技术动态创建子类实例(动态扩展了UserServiceImpl类)
return enhancer.create();
}
/**
* 拦截方法:在代理实例上拦截并处理目标方法的调用,返回结果
* obj:目标对象代理的实例;
* method:目标对象调用父类方法的method实例;
* args:调用父类方法传递参数;
* proxy:代理的方法去调用目标方法
*/
public Object intercept(Object obj,Method method,Object[] args,MethodProxy proxy)
throws Throwable{
System.out.println("--------测试intercept方法的四个参数的含义-----------");
System.out.println("obj:"+obj.getClass());
System.out.println("method:"+method.getName());
System.out.println("proxy:"+proxy.getSuperName());
if(args!=null&&args.length>0){
for(Object value : args){
System.out.println("args:"+value);
}
}
//目标方法之前执行
System.out.println("do sth Before...");
//目标方法调用
//通过代理类实例调用父类的方法,即是目标业务类方法的调用
Object result = proxy.invokeSuper(obj, args);
//目标方法之后执行
System.out.println("do sth After...
");
return result;
}
}
测试类:
package com.spring.aop;
public class CglibProxyTest {
public static void main(String[] args){
CglibProxy proxy=new CglibProxy();
//通过java.lang.reflect.Proxy的getProxy()动态生成目标业务类的子类,即是代理类,再由此得到代理实例
//通过动态生成子类的方式创建代理类
IUserService target=(IUserService)proxy.getProxy(UserServiceImpl.class);
target.addUser();
target.deleteUser();
}
}
基本流程:需要自己写代理类,它实现MethodInterceptor接口,有一个intercept()回调方法用于拦截对目标方法的调用,里面使用methodProxy来调用目标方法。创建代理对象要用Enhance类,用它设置好代理的目标类、由intercept()回调的代理类实例、最后用create()创建并返回代理实例。
运行结果:
我们看到达到了同样的效果。它的原理是生成一个父类enhancer.setSuperclass(clazz)的子类enhancer.create(),然后对父类的方法进行拦截enhancer.setCallback(this). 对父类的方法进行覆盖,所以父类方法不能是final的。
JDK动态代理和CGLIB字节码生成的区别:
(1)JDK动态代理只能对实现了接口的类生成代理,而不能针对类。CGLIB是针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法。因为是继承,所以该类或方法最好不要声明成final。
(2)JDK代理是不需要依赖第三方的库,只要JDK环境就可以进行代理,它有几个要求
* 实现InvocationHandler;
* 使用Proxy.newProxyInstance产生代理对象;
* 被代理的对象必须要实现接口。
CGLib 必须依赖于CGLib的类库,但是它需要类来实现任何接口代理的是指定的类生成一个子类,覆盖其中的方法,是一种继承。
(3)jdk的核心是实现InvocationHandler接口,使用invoke()方法进行面向切面的处理,调用相应的通知。cglib的核心是实现MethodInterceptor接口,使用intercept()方法进行面向切面的处理,调用相应的通知。
(4)如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP。 如果就是单纯的用IOC生成一个对象,也没有AOP的切入不会生成代理的,只会NEW一个实例,给Spring的Bean工厂。如果目标对象实现了接口,也可以强制使用CGLIB实现AOP。如果目标对象没有实现了接口,必须采用CGLIB库,spring会自动在JDK动态代理和CGLIB之间转换(没有实现接口的就用CGLIB代理,使用了接口的类就用JDK动态代理)
总结:
Spring默认使用 JDK 动态代理作为AOP的代理,缺陷是目标类的类必须实现接口,否则不能使用JDK动态代理。如果需要代理的是类而不是接口,那么Spring会默认使用CGLIB代理,关于两者的区别:jdk动态代理是通过java的反射机制来实现的,目标类必须要实现接口,cglib是针对类来实现代理的,他的原理是动态的为指定的目标类生成一个子类,并覆盖其中方法实现增强,但因为采用的是继承,所以不能对final修饰的类进行代理。
JDK动态代理:
代理类与委托类实现同一接口,主要是通过代理类实现InvocationHandler并重写invoke方法来进行动态代理的,在invoke方法中将对方法进行增强处理 优点:不需要硬编码接口,代码复用率高,缺点:只能够代理实现了接口的委托类
CGLIB动态代理:
AOP的实现方式有哪几种?如何选择?
JDK 动态代理实现和 cglib 实现。
选择:
(1)如果目标对象实现了接口,默认情况下会采用 JDK 的动态代理实现 AOP,也可以强制使用 cglib 实现 AOP;
(2)如果目标对象没有实现接口,必须采用 cglib 库,Spring 会自动在 JDK 动态代理和 cglib 之间转换。
SpringAOP 的具体加载步骤
(1)当 spring 容器启动的时候,加载了 spring 的配置文件。
(2)为配置文件中的所有 bean 创建对象。
(3)spring 容器会解析 aop:config 的配置
解析切入点表达式,用切入点表达式和纳入 spring 容器中的 bean 做匹配。如果匹配成功,则会为该 bean 创建代理对象,代理对象的方法=目标方法+通知,如果匹配不成功,不会创建代理对象。
(4)在客户端利用 context.getBean() 获取对象时,如果该对象有代理对象,则返回代理对象;如果没有,则返回目标对象。
说明:如果目标类没有实现接口,则 spring 容器会采用 cglib 的方式产生代理对象,如果实现了接口,则会采用 jdk 的方式
JDK动态代理如何实现?
JDK 动态代理,只能对实现了接口的类生成代理,而不是针对类,该目标类型实现的接口都将被代理。原理是通过在运行期间创建一个接口的实现类来完成对目标对象的代理。
(1)定义一个实现接口 InvocationHandler 的类;
(2)通过构造函数,注入被代理类;
(3)实现 invoke( Object proxy, Method method, Object[] args)方法;
(4)在主函数中获得被代理类的类加载器;
(5)使用 Proxy.newProxyInstance( ) 产生一个代理对象;
(6)通过代理对象调用各种方法。
46、BeanFactroy 与 ApplicationContext 的区别
BeanFactory是Spring框架最核心的接口,它提供了高级IOC的配置机制。ApplicationContext建立在BeanFactory基础之上,提供了更多面向应用的功能,它提供了国际化支持和框架事件体系,更易于创建实际应用。一般称BeanFactory为IOC容器,而称ApplicationContext为应用上下文。
BeanFactory是一个类工厂,可以创建并管理各种类的对象,Spring称这些创建和管理的Java对象为Bean。ApplicationContext由BeanFactory派生而来,提供了更多面向实际应用的功能。在BeanFactory中,很多功能需要以编程的方式方式实现,而在ApplicationContext中则可以通过配置的方式实现。
BeanFactory负责读取bean配置文档,管理bean的加载,实例化,维护bean之间的依赖关系,负责bean的声明周期。ApplicationContext除了提供上述BeanFactory所能提供的功能之外,还提供了更完整的框架功能:
a. MessageSource, 提供国际化的消息访问
b. 资源访问,如URL和文件
c. 事件传播特性,即支持aop特性
d. 载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层
(1)BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化,这样,我们就不能发现一些存在的Spring的配置问题。而ApplicationContext则相反,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误。 相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
BeanFacotry延迟加载,如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常;而ApplicationContext则在初始化自身是检验,这样有利于检查所依赖属性是否注入;所以通常情况下我们选择使用 ApplicationContext。
应用上下文则会在上下文启动后预载入所有的单实例Bean。通过预载入单实例bean,确保当你需要的时候,你就不用等待,因为它们已经创建好了。
(2)BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。(Applicationcontext比 beanFactory 加入了一些更好使用的功能。而且 beanFactory 的许多功能需要通过编程实现而 Applicationcontext 可以通过配置实现。比如后处理 bean , Applicationcontext 直接配置在配置文件即可而 beanFactory 这要在代码中显示的写出来才可以被容器识别。 )
(3)beanFactory主要是面对与 spring 框架的基础设施,面对 spring 自己。而 Applicationcontex 主要面对与 spring 使用的开发者。基本都会使用 Applicationcontex 并非 beanFactory 。
47、Bean的作用域
| 作用域 | 描述 |
|---|---|
| singleton |
在每个Spring IoC容器中一个bean定义对应一个对象实例。 (默认)在spring IOC容器中仅存在一个Bean实例,Bean以单实例的方式存在。 |
| prototype |
一个bean定义对应多个对象实例。 每次从容器中调用Bean时,都返回一个新的实例,即每次调用getBean()时,相当于执行new XxxBean()的操作。 |
|
request |
在一次HTTP请求中,一个bean定义对应一个实例;即每次HTTP请求将会有各自的bean实例,它们依据某个bean定义创建而成。该作用域仅在基于web的Spring |
|
session |
在一个HTTP 同一个HTTP session共享一个Bean,不同HTTP session使用不同的Bean,该作用域仅适用于webApplicationContext环境。 |
|
globalSession |
在一个全局的HTTP |
依赖注入方式
对于spring配置一个bean时,如果需要给该bean提供一些初始化参数,则需要通过依赖注入方式,所谓的依赖注入就是通过spring将bean所需要的一些参数传递到bean实例对象的过程,spring的依赖注入有3种方式:
·使用属性的setter方法注入 ,这是最常用的方式。属性注入即通过setXxx()方法注入Bean的属性值或依赖对象,由于属性注入方式具有可选择性和灵活性高的优点,因此属性注入是实际应用中最常采用的注入方式。
·使用构造器注入。在类中,不用为属性设置setter方法,但是需要生成该类带参的构造方法。同时,在配置文件中配置该类的bean,并配置构造器,在配置构造器中用到了<constructor-arg>节点,可以指定按类型匹配入参还是按索引匹配入参。
·使用Filed注入(用于注解方式)。使用注解注入依赖对象不用再在代码中写依赖对象的setter方法或者该类的构造方法,并且不用再配置文件中配置大量的依赖对象,使代码更加简洁,清晰,易于维护。在Spring IOC编程的实际开发中推荐使用注解的方式进行依赖注入。
自动装配
在应用中,我们常常使用<ref>标签为JavaBean注入它依赖的对象,同时也Spring为我们提供了一个自动装配的机制,在定义Bean时,<bean>标签有一个autowire属性,我们可以通过指定它来让容器为受管JavaBean自动注入依赖对象。
自动装配是在配置文件中实现的,如下:<bean id="***" class="***" autowire="byType">
只需要配置一个autowire属性即可完成自动装配,不用再配置文件中写<property>,但是在类中还是要生成依赖对象的setter方法。
<bean>的autowire属性有如下六个取值,他们的说明如下:
(1)No:即不启用自动装配。Autowire默认的值。默认情况下,需要通过"ref"来装配bean。
(2)byName:按名称装配。可以根据属性的名称在容器中查询与该属性名称相同的bean,如果没有找到,则属性值为null。假设Boss类中有一个名为car的属性,如果容器中刚好有一个名为car的Bean,Spring就会自动将其装配给Boss的car属性。
(3)byType:按类型装配。可以根据属性类型,在容器中寻找该类型匹配的bean,如有多个,则会抛出异常,如果没有找到,则属性值为null。假设Boss类中有一个Car类型的属性,如果容器中刚好有一个Car类型的Bean,Spring就会自动将其装配给Boss的这个属性。
(4)constructor:与byType方式相似,不同之处在与它应用于构造器参数,如果在容器中没有找到与构造器参数类型一致的bean,那么将抛出异常。(根据构造函数参数的数据类型,进行byType模式的自动装配。)
(5)autodetect:通过bean类的自省机制(introspection)来决定是使用constructor还是byType的方式进行自动装配。如果Bean有空构造器那么将采用“byType”自动装配方式,否则使用“constructor”自动装配方式。
(6)default:由上级标签<beans>的default-autowire属性确定。
注:不是所有类型都能自动装配,不能自动装配的数据类型:Object、基本数据类型(Date、CharSequence、Number、URI、URL、Class、int)等。
Spring常用注解
传统的Spring做法是使用.xml文件来对bean进行注入或者是配置aop、事物,这么做有两个缺点:
(1)如果所有的内容都配置在.xml文件中,那么.xml文件将会十分庞大;如果按需求分开.xml文件,那么.xml文件又会非常多。总之这将导致配置文件的可读性与可维护性变得很低。
(2)在开发中在.java文件和.xml文件之间不断切换,是一件麻烦的事,同时这种思维上的不连贯也会降低开发的效率。
为了解决这两个问题,Spring引入了注解,通过"@XXX"的方式,让注解与Java Bean紧密结合,既大大减少了配置文件的体积,又增加了Java Bean的可读性与内聚性。
Spring常用注解总结:
@Configuration把一个类作为一个IoC容器,它的某个方法头上如果注册了@Bean,就会作为这个Spring容器中的Bean。
@Configuration标注在类上,相当于把该类作为spring的xml配置文件中的<beans>,作用为:配置spring容器(应用上下文)。@Bean标注在方法上(返回某个实例的方法),等价于spring的xml配置文件中的<bean>,作用为:注册bean对象。用@Configuration注解类,等价于XML中配置beans;用@Bean标注方法等价于XML中配置bean。
@Component泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
@Controller用于标注控制层组件(如struts中的action)。
@Service用于标注业务层组件。
@Repository用于标注数据访问组件,即DAO组件。
@Autowired:顾名思义,就是自动装配,其作用是为了消除代码Java代码里面的getter/setter与bean属性中的property。当然,getter看个人需求,如果私有属性需要对外提供的话,应当予以保留。@Autowired默认按类型匹配的方式,在容器查找匹配的Bean,当有且仅有一个匹配的Bean时,Spring将其注入@Autowired标注的变量中。
@Qualifier:用来指定注入Bean的名称。如果容器中有一个以上匹配的Bean,则可以通过@Qualifier注解限定Bean的名称。通常@Qualifier可以结合@Autowired注解一起使用。如下:@Autowired @Qualifier("personDaoBean") 存在多个实例配合使用。
@Resource默认按名称装配,当找不到与名称匹配的bean才会按类型装配。
说一下@Resource的装配顺序:
(1)@Resource后面没有任何内容,默认通过name属性去匹配bean,找不到再按type去匹配。
(2)指定了name或者type则根据指定的类型去匹配bean。
(3)指定了name和type则根据指定的name和type去匹配bean,任何一个不匹配都将报错。
然后,区分一下@Autowired和@Resource两个注解的区别:
(1)@Autowired默认按照byType方式进行bean匹配,@Resource默认按照byName方式进行bean匹配。
(2)@Autowired是Spring的注解,@Resource是J2EE的注解,这个看一下导入注解的时候这两个注解的包名就一清二楚了。
Spring属于第三方的,J2EE是Java自己的东西,因此,建议使用@Resource注解,以减少代码和Spring之间的耦合。
Spring事务管理
spring支持编程式事务管理和声明式事务管理两种方式。
编程式事务管理使用TransactionTemplate或者直接使用底层的PlatformTransactionManager。对于编程式事务管理,spring推荐使用TransactionTemplate。
声明式事务管理建立在AOP之上的。其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。声明式事务最大的优点就是不需要通过编程的方式管理事务,这样就不需要在业务逻辑代码中掺杂事务管理的代码,只需在配置文件中做相关的事务规则声明(或通过基于@Transactional注解的方式),便可以将事务规则应用到业务逻辑中。
显然声明式事务管理要优于编程式事务管理,这正是spring倡导的非侵入式的开发方式。声明式事务管理使业务代码不受污染,一个普通的POJO对象,只要加上注解就可以获得完全的事务支持。和编程式事务相比,声明式事务唯一不足地方是,后者的最细粒度只能作用到方法级别,无法做到像编程式事务那样可以作用到代码块级别。但是即便有这样的需求,也存在很多变通的方法,比如,可以将需要进行事务管理的代码块独立为方法等等。
声明式事务管理也有两种常用的方式,一种是基于tx和aop名字空间的xml配置文件,另一种就是基于@Transactional注解。显然基于注解的方式更简单易用,更清爽。
spring事务回滚规则
指示spring事务管理器回滚一个事务的推荐方法是在当前事务的上下文内抛出异常。spring事务管理器会捕捉任何未处理的异常,然后依据规则决定是否回滚抛出异常的事务。
默认配置下,spring只有在抛出的异常为运行时unchecked异常时才回滚该事务,也就是抛出的异常为RuntimeException的子类(Errors也会导致事务回滚),而抛出checked异常则不会导致事务回滚。可以明确的配置在抛出哪些异常时回滚事务,包括checked异常。也可以明确定义哪些异常抛出时不回滚事务。还可以编程性的通过setRollbackOnly()方法来指示一个事务必须回滚,在调用完setRollbackOnly()后你所能执行的唯一操作就是回滚。
checked异常: 表示无效,不是程序中可以预测的。比如无效的用户输入,文件不存在,网络或者数据库链接错误。这些都是外在的原因,都不是程序内部可以控制的。 必须在代码中显式地处理。比如try-catch块处理,或者给所在的方法加上throws说明,将异常抛到调用栈的上一层。 继承自java.lang.Exception(java.lang.RuntimeException除外)。
unchecked异常: 表示错误,程序的逻辑错误。是RuntimeException的子类,比如IllegalArgumentException, NullPointerException和IllegalStateException。 不需要在代码中显式地捕获unchecked异常做处理。 继承自java.lang.RuntimeException(而java.lang.RuntimeException继承自java.lang.Exception)。
java里面将派生于Error或者RuntimeException(比如空指针,1/0)的异常称为unchecked异常,其他继承自java.lang.Exception的异常统称为Checked Exception,如IOException、TimeoutException等。那么再通俗一点:你写代码出现的空指针等异常,会被回滚,文件读写,网络出问题,spring就没法回滚了。
@Transactional注解
@Transactional属性
| 属性 | 类型 | 描述 |
|---|---|---|
| value | String | 可选的限定描述符,指定使用的事务管理器 |
| propagation | enum: Propagation | 可选的事务传播行为设置 |
| isolation | enum: Isolation | 可选的事务隔离级别设置 |
| readOnly | boolean | 读写或只读事务,默认读写 |
| timeout | int (in seconds granularity) | 事务超时时间设置 |
| rollbackFor | Class对象数组,必须继承自Throwable | 导致事务回滚的异常类数组 |
| rollbackForClassName | 类名数组,必须继承自Throwable | 导致事务回滚的异常类名字数组 |
| noRollbackFor | Class对象数组,必须继承自Throwable | 不会导致事务回滚的异常类数组 |
| noRollbackForClassName | 类名数组,必须继承自Throwable | 不会导致事务回滚的异常类名字数组 |
用法:
@Transactional 可以作用于接口、接口方法、类以及类方法上。当作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。
虽然 @Transactional 注解可以作用于接口、接口方法、类以及类方法上,但是 Spring 建议不要在接口或者接口方法上使用该注解,因为这只有在使用基于接口的代理时它才会生效。另外, @Transactional 注解应该只被应用到 public 方法上,这是由 Spring AOP 的本质决定的。如果你在 protected、private 或者默认可见性的方法上使用 @Transactional 注解,这将被忽略,也不会抛出任何异常。
默认情况下,只有来自外部的方法调用才会被AOP代理捕获,也就是,类内部方法调用本类内部的其他方法并不会引起事务行为,即使被调用方法使用@Transactional注解进行修饰。
Spring使用声明式事务处理,默认情况下,如果被注解的数据库操作方法中发生了unchecked异常,所有的数据库操作将rollback;如果发生的异常是checked异常,默认情况下数据库操作还是会提交的。
如何改变默认规则:
(1)让checked例外也回滚:在整个方法前加上 @Transactional(rollbackFor=Exception.class)
(2)让unchecked例外不回滚: @Transactional(notRollbackFor=RunTimeException.class)
(3)不需要事务管理的(只查询的)方法:@Transactional(propagation=Propagation.NOT_SUPPORTED)
在整个方法运行前就不会开启事务 ,还可以加上:@Transactional(propagation=Propagation.NOT_SUPPORTED,readOnly=true),这样就做成一个只读事务,可以提高效率。
@Autowired
private MyBatisDao dao;
@Transactional
@Override
public void insert(Test test) {
dao.insert(test);
throw new RuntimeException("test");//抛出unchecked异常,触发事物,回滚
}
noRollbackFor
@Transactional(noRollbackFor=RuntimeException.class)
@Override
public void insert(Test test) {
dao.insert(test);
//抛出unchecked异常,触发事物,noRollbackFor=RuntimeException.class,不回滚
throw new RuntimeException("test");
}
类,当作用于类上时,该类的所有 public 方法将都具有该类型的事务属性
@Transactional
public class MyBatisServiceImpl implements MyBatisService {
@Autowired
private MyBatisDao dao;
@Override
public void insert(Test test) {
dao.insert(test);
//抛出unchecked异常,触发事物,回滚
throw new RuntimeException("test");
}
}
propagation=Propagation.NOT_SUPPORTED
@Transactional(propagation=Propagation.NOT_SUPPORTED)
@Override
public void insert(Test test) {
//事物传播行为是PROPAGATION_NOT_SUPPORTED,以非事务方式运行,不会存入数据库
dao.insert(test);
}
例子:
@Service
public class SysConfigService {
@Autowired
private SysConfigRepository sysConfigRepository;
public SysConfigEntity getSysConfig(String keyName) {
SysConfigEntity entity = sysConfigRepository.findOne(keyName);
return entity;
}
public SysConfigEntity saveSysConfig(SysConfigEntity entity) {
if(entity.getCreateTime()==null){
entity.setCreateTime(new Date());
}
return sysConfigRepository.save(entity);
}
@Transactional
public void testSysConfig(SysConfigEntity entity) throws Exception {
//不会回滚
this.saveSysConfig(entity);
throw new Exception("sysconfig error");
}
@Transactional(rollbackFor = Exception.class)
public void testSysConfig1(SysConfigEntity entity) throws Exception {
//会回滚
this.saveSysConfig(entity);
throw new Exception("sysconfig error");
}
@Transactional
public void testSysConfig2(SysConfigEntity entity) throws Exception {
//会回滚
this.saveSysConfig(entity);
throw new RuntimeException("sysconfig error");
}
@Transactional
public void testSysConfig3(SysConfigEntity entity) throws Exception {
//事务仍然会被提交
this.testSysConfig4(entity);
throw new Exception("sysconfig error");
}
@Transactional(rollbackFor = Exception.class)
public void testSysConfig4(SysConfigEntity entity) throws Exception {
this.saveSysConfig(entity);
}
}
@Transactional事务使用总结:
(1)异常在A方法内抛出,则A方法就得加注解
(2)多个方法嵌套调用,如果都有 @Transactional 注解,则产生事务传递,默认 Propagation.REQUIRED
(3)如果注解上只写 @Transactional 默认只对 RuntimeException 回滚,而非 Exception 进行回滚。如果要对 checked Exceptions 进行回滚,则需要 @Transactional(rollbackFor = Exception.class),rollbackFor这属性指定了,即使你出现了checked这种例外,那么它也会对事务进行回滚。
解决@Transactional注解不回滚
(1)检查你方法是不是public的。
(2)你的异常类型是不是unchecked异常。如果我想check异常也想回滚怎么办,注解上面写明异常类型即可。
@Transactional(rollbackFor=Exception.class)
类似的还有norollbackFor,自定义不回滚的异常。
(3)数据库引擎要支持事务,如果是MySQL,注意表要使用支持事务的引擎,比如innodb,如果是myisam,事务是不起作用的。
(4)是否开启了对注解的解析。
<tx:annotation-driven transaction-manager="transactionManager" proxy-target-class="true"/>
(5)spring是否扫描到你这个包,如下是扫描到org.test下面的包。
<context:component-scan base-package="org.test" ></context:component-scan>
(6)检查是不是同一个类中的方法调用(如a方法调用同一个类中的b方法)。
(7)异常是不是被你catch住了。
SpringMVC工作流程
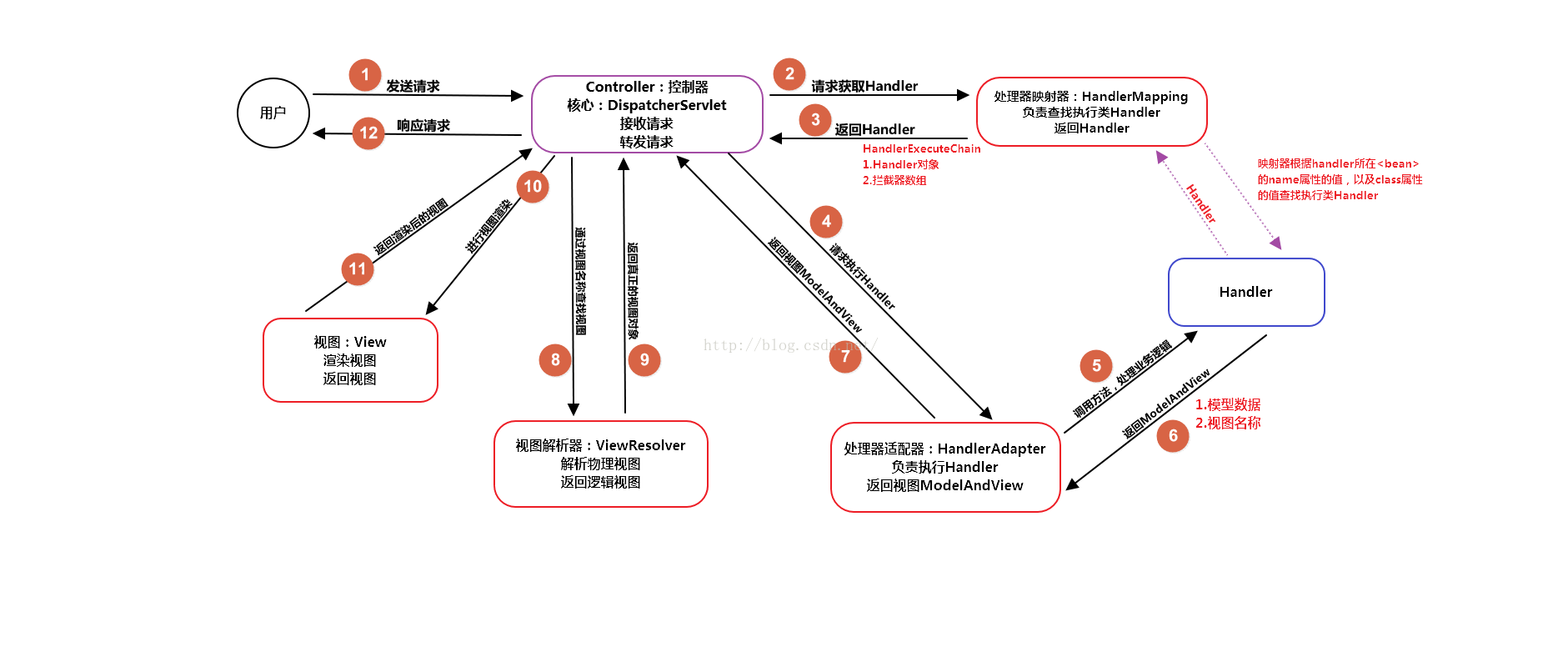
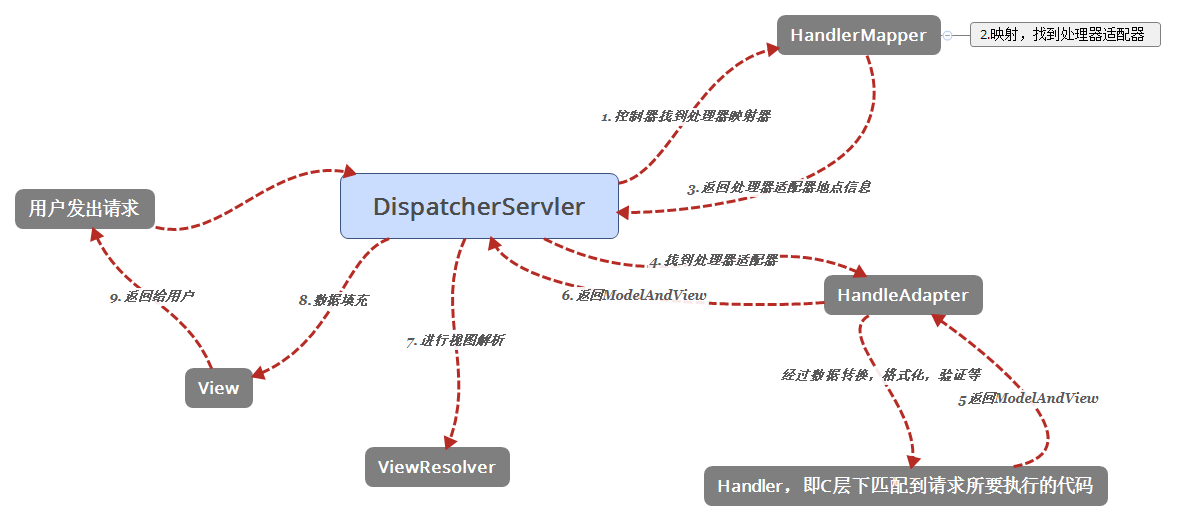
(1)用户发起请求到前端控制器(Controller)
(2)前端控制器没有处理业务逻辑的能力,需要找到具体的模型对象处理(Handler),到处理器映射器(HandlerMapping)中查找Handler对象(Model)。
(3)HandlerMapping返回执行链,包含了2部分内容: ① Handler对象、② 拦截器数组
(4)前端处理器通过处理器适配器包装后执行Handler对象。
(5)处理业务逻辑。
(6)Handler处理完业务逻辑,返回ModelAndView对象,其中view是视图名称,不是真正的视图对象。
(7)将ModelAndView返回给前端控制器。
(8)视图解析器(ViewResolver)返回真正的视图对象(View)。
(9)(此时前端控制器中既有视图又有Model对象数据)前端控制器根据模型数据和视图对象,进行视图渲染。
(10)返回渲染后的视图(html/json/xml)返回。
(11)给用户产生响应。
(1)用户发送请求至前端控制器DispatcherServlet。
(2)DispatcherServlet收到请求调用HandlerMapping处理器映射器。
(3)处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
(4)DispatcherServlet调用HandlerAdapter处理器适配器。
(5)HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
(6)Controller执行完成返回ModelAndView。
(7)HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
(8)DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
(9)ViewReslover解析后返回具体View。
(10)DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
(11)DispatcherServlet响应用户。
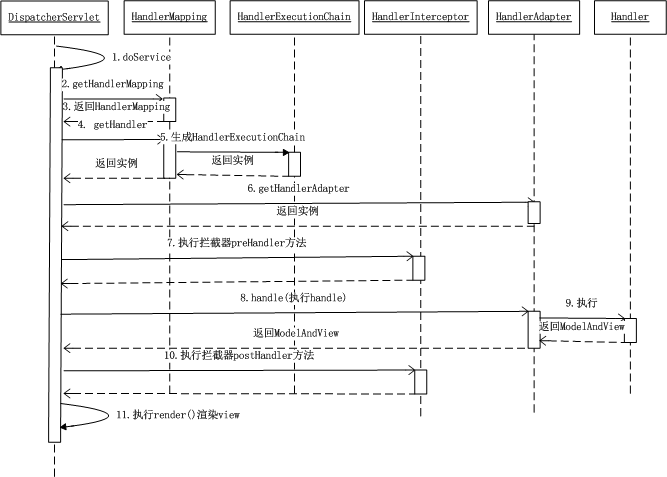
(1)用户向服务器发送HTTP请求,请求被前端控制器 DispatcherServlet 捕获。
(2)DispatcherServlet 根据 <servlet-name>-servlet.xml 中的配置对请求的URL进行解析,得到请求资源标识符(URI)。 然后根据该URI,调用 HandlerMapping 获得该Handler配置的所有相关的对象(包括Handler对象以及Handler对象对应的拦截器),最后以 HandlerExecutionChain 对象的形式返回。
(3)DispatcherServlet 根据获得的Handler,选择一个合适的 HandlerAdapter。(附注:如果成功获得HandlerAdapter后,此时将开始执行拦截器的preHandler(…)方法)。
(4)提取Request中的模型数据,填充Handler入参,开始执行Handler(Controller)。 在填充Handler的入参过程中,根据你的配置,Spring将帮你做一些额外的工作:
HttpMessageConveter: 将请求消息(如Json、xml等数据)转换成一个对象,将对象转换为指定的响应信息。
数据转换:对请求消息进行数据转换。如String转换成Integer、Double等。
数据根式化:对请求消息进行数据格式化。 如将字符串转换成格式化数字或格式化日期等。
数据验证: 验证数据的有效性(长度、格式等),验证结果存储到BindingResult或Error中。
(5)Handler(Controller)执行完成后,向 DispatcherServlet 返回一个 ModelAndView 对象;
(6)根据返回的ModelAndView,选择一个适合的 ViewResolver(必须是已经注册到Spring容器中的ViewResolver)返回给DispatcherServlet。
(7)ViewResolver 结合Model和View,来渲染视图。
(8)视图负责将渲染结果返回给客户端。
组件:
(1)前端控制器DispatcherServlet(不需要工程师开发),由框架提供
作用:接收请求,响应结果,相当于转发器,中央处理器。有了dispatcherServlet减少了其它组件之间的耦合度。
用户请求到达前端控制器,它就相当于mvc模式中的c,dispatcherServlet是整个流程控制的中心,由它调用其它组件处理用户的请求,dispatcherServlet的存在降低了组件之间的耦合性。
(2)处理器映射器HandlerMapping(不需要工程师开发),由框架提供
作用:根据请求的url查找Handler。HandlerMapping负责根据用户请求找到Handler即处理器,springmvc提供了不同的映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
(3)处理器适配器HandlerAdapter
作用:按照特定规则(HandlerAdapter要求的规则)去执行Handler。通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。
(4)处理器Handler(需要工程师开发)
注意:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执行Handler。Handler 是继DispatcherServlet前端控制器的后端控制器,在DispatcherServlet的控制下Handler对具体的用户请求进行处理。由于Handler涉及到具体的用户业务请求,所以一般情况需要工程师根据业务需求开发Handler。
(5)视图解析器View resolver(不需要工程师开发),由框架提供
作用:进行视图解析,根据逻辑视图名解析成真正的视图(view)。View Resolver负责将处理结果生成View视图,View Resolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。 springmvc框架提供了很多的View视图类型,包括:jstlView、freemarkerView、pdfView等。一般情况下需要通过页面标签或页面模版技术将模型数据通过页面展示给用户,需要由工程师根据业务需求开发具体的页面。
(6)视图View(需要工程师开发jsp...)
View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf...)。
SpringMVC注解
@RequestMapping:RequestMapping是一个用来处理请求地址映射的注解(将请求映射到对应的控制器方法中),可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。RequestMapping请求路径映射,如果标注在某个controller的类级别上,则表明访问此类路径下的方法都要加上其配置的路径;最常用是标注在方法上,表明哪个具体的方法来接受处理某次请求。
RequestMapping的属性
value:指定请求的实际url
method:指定请求的method类型, GET、POST、PUT、DELETE等;
@RequestMapping(value="/get/{bookid}",method={RequestMethod.GET,RequestMethod.POST})
params:指定request中必须包含某些参数值是,才让该方法处理。
@RequestMapping(params="action=del"),请求参数包含“action=del”,如:http://localhost:8080/book?action=del
headers:指定request中必须包含某些指定的header值,才能让该方法处理请求。
consumes:指定处理请求的提交内容类型(Content-Type),例如application/json, text/html。
produces: 指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回。
@RequestParam:绑定单个请求参数值
@RequestParam有以下三个参数:
value:参数名字,即入参的请求参数名字,如username表示请求的参数区中的名字为username的参数的值将传入;
required:是否必须,默认是true,表示请求中一定要有相应的参数,否则将抛出异常;
defaultValue:默认值,表示如果请求中没有同名参数时的默认值,设置该参数时,自动将required设为false。
@PathVariable:绑定URI模板变量值
@PathVariable用于将请求URL中的模板变量映射到功能处理方法的参数上。
@ModelAttribute:ModelAttribute可以应用在方法参数上或方法上,他的作用主要是当注解在方法参数上时会将注解的参数对象添加到Model中;当注解在请求处理方法Action上时会将该方法变成一个非请求处理的方法,但其它Action被调用时会首先调用该方法。
@Responsebody:@Responsebody表示该方法的返回结果直接写入HTTP response body中。一般在异步获取数据时使用,在使用@RequestMapping后,返回值通常解析为跳转路径,加上@Responsebody后返回结果不会被解析为跳转路径,而是直接写入HTTP response body中。比如异步获取json数据,加上@Responsebody后,会直接返回json数据。
@RequestBody:将HTTP请求正文插入方法中,使用适合的HttpMessageConverter将请求体写入某个对象。
三、JVM
44、GC是什么?为什么要有GC?
答:GC是垃圾收集的意思,内存处理是编程人员容易出现问题的地方,忘记或者错误的内存回收会导致程序或系统的不稳定甚至崩溃,Java提供的GC功能可以自动监测对象是否超过作用域从而达到自动回收内存的目的,Java语言没有提供释放已分配内存的显示操作方法。Java程序员不用担心内存管理,因为垃圾收集器会自动进行管理。要请求垃圾收集,可以调用下面的方法之一:System.gc() 或Runtime.getRuntime().gc() ,但JVM可以屏蔽掉显示的垃圾回收调用。
垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存。垃圾回收器通常是作为一个单独的低优先级的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清除和回收,程序员不能实时的调用垃圾回收器对某个对象或所有对象进行垃圾回收。在Java诞生初期,垃圾回收是Java最大的亮点之一,因为服务器端的编程需要有效的防止内存泄露问题,然而时过境迁,如今Java的垃圾回收机制已经成为被诟病的东西。移动智能终端用户通常觉得iOS的系统比Android系统有更好的用户体验,其中一个深层次的原因就在于Android系统中垃圾回收的不可预知性。
45、介绍JVM中7个区域,并把每个区域中可能造成的内存溢出情况进行说明
程序计数器:看做当前线程所执行的字节码行号指示器。是线程私有的内存,且唯一一块不报OutOfMemoryError异常。
Java虚拟机栈:用于描述java方法的内存模型:每个方法被执行时都会同时创建一个栈帧用于存储局部变量表,操作数栈,动态链接,方法出口等信息。每一个方法被调用直至执行完成的过程就对应着一个栈帧在虚拟机中从入栈到出栈的过程。如果线程请求的栈深度大于虚拟机所允许的深度就报StackOverflowError,,如果虚拟机栈可以动态扩展,当扩展时无法申请到足够的内存会抛出OutOfMemoryError。Java虚拟机栈是线程私有的。
本地方法栈:与虚拟机栈相似,不同的在于它是为虚拟机使用到的Native方法服务的。会抛出StackOverflowError和OutOfMemoryError。是线程私有的。
Java堆:是所有线程共享的一块内存,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。如果堆上没有内存完成实例的分配就会报OutOfMemoryError。
方法区(永久代):用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。当方法区无法满足内存分配需求时,会抛出OutOfMemoryError。是共享内存。
运行时常量池:用于存放编译器生成的各种字面量和符号引用,是方法区的一部分。无法申请内存时抛出OutOfMemoryError。
直接内存:不是虚拟机运行时数据的一部分,也不是java虚拟机规范中定义的区域,是计算机直接的内存空间。这部分也被频繁使用,如JAVA NIO的引入基于通道和缓存区的I/O使用native函数直接分配堆外内存。如果内存不足会报OutOfMemoryError。
46、怎样判断一个对象是否需要收集?
GC的两种判定方法:引用计数与可达性分析法。
引用计数:给对象添加一个引用计数器,每当有一个地方引用该对象时,计数器值加1,当引用失效时,计数器值减1。任何时候计数器都为0的对象就是不可能再被使用的。引用计数缺陷:引用计数无法解决循环引用问题:假设对象A,B都已经被实例化,让A=B,B=A,除此之外这两个对象再无任何引用,此时计数器的值就永远不可能为0,但是引用计数器无法通知gc回收他们。
可达性分析法(GC Roots Traceing): 通过一系列名为“GC Roots”的对象作为起点,从这些节点开始向下搜索,搜索走过的路径成为引用链,当一个对象到GC Roots没有任何引用链相连时,则证明此对象不可用。 GC Roots对象一般是:虚拟机栈中的引用对象,方法区中类静态属性引用的对象,方法区常量引用的对象等。
对于可达性分析算法而言,未到达的对象并非是“非死不可”的,若要宣判一个对象死亡,至少需要经历两次标记阶段。
1. 如果对象在进行可达性分析后发现没有与GCRoots相连的引用链,则该对象被第一次标记并进行一次筛选,筛选条件为是否有必要执行该对象的finalize方法,若对象没有覆盖finalize方法或者该finalize方法已经被虚拟机执行过了,则均视作不必要执行该对象的finalize方法,即该对象将会被回收。反之,若对象覆盖了finalize方法并且该finalize方法并没有被执行过,那么,这个对象会被放置在一个叫F-Queue的队列中,之后会由虚拟机自动建立的、优先级低的Finalizer线程去执行,而虚拟机不必要等待该线程执行结束,即虚拟机只负责建立线程,其他的事情交给此线程去处理。
2.对F-Queue中对象进行第二次标记,如果对象在finalize方法中拯救了自己,即关联上了GCRoots引用链,如把this关键字赋值给其他变量,那么在第二次标记的时候该对象将从“即将回收”的集合中移除,如果对象还是没有拯救自己,那就会被回收。注意,它只能拯救自己一次,第二次就被回收了。
47、Java中的四种引用
强引用:程序代码中的普通引用。如Object obj = new Object(),只要强引用存在,垃圾回收器就不会回收。
软引用:描述一些有用但并非必须的对象。对于软引用关联的对象在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围之中进行第二次回收。
弱引用(SoftRefence):描述非必须对象,比软引用弱一些。被弱引用关联的对象只能生存到下一次垃圾收集发生之前。无论当前内存是否足够,都会回收掉只被弱引用关联的对象。
虚引用(WeakRefence):最弱的引用,不管是否有虚引用存在,完全不会对对象生存时间构成影响,也无法通过虚引用来取得一个对象实例。唯一目的是希望能够在这个对象被垃圾收集器回收之前收到系统通知。
48、对象创建方法,对象的内存分配,对象的访问定位
Object obj = new Object(); obj 保存在java栈中的局部变量表里,作为一个引用数据出现。New Object()会在java堆上分配一块存储Object类型实例的所有数值的结构化内存,根据类型以及虚拟机实现的对象内存布局不同。这块内存是不固定的。 对象访问方式有两种:句柄和直接指针。
句柄:在java堆中会划分出一块内存作为句柄池,reference中存储的对象是句柄地址。而句柄中包含对象实例数据和类型数据各自的具体地址信息。最大的好处是如果对象地址发生变化不需要改变reference的值,只需要改变句柄中实例数据指针。
直接指针访问:reference直接存储对象的地址,最大的好处是速度更快。
49、Java中堆和栈的区别
Java把内存划分成两种:一种是栈内存,一种是堆内存。
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作它用。
堆内存用来存放由 new 创建的对象和数组,在堆中分配的内存,由 Java 虚拟机的自动垃圾回收器来管理。在堆中产生了一个数组或者对象之后,还可以在栈中定义一个特殊的变量,让栈中的这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或者对象,引用变量就相当于是为数组或者对象起的一个名称。引用变量是普通的变量,定义时在栈中分配,引用变量在程序运行到其作用域之外后被释放。而数组和对象本身在堆中分配,即使程序运行到使用 new 产生数组或者对象的语句所在的代码块之外,数组和对象本身占据的内存不会被释放,数组和对象在没有引用变量指向它的时候,才变为垃圾,不能在被使用,但仍然占据内存空间不放,在随后的一个不确定的时间被垃圾回收器收走(释放掉)。
具体的说:
栈与堆都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
Java堆是一个运行时数据区,类的对象从中分配空间。这些对象通过 new 建立,它们不需要程序代码来显式的释放。堆是由垃圾回收来负责的,堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的,Java 的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。 java 中的对象和数组都存放在堆中。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈中主要存放一些基本类型的变量(int, short, long, byte, float, double, boolean, char)和对象句柄。
栈有一个很重要的特殊性,就是存在栈中的数据可以共享。 假设我们同时定义:
int a = 3; int b = 3;
编译器先处理 int a = 3 ;首先它会在栈中创建一个变量为 a 的引用,然后查找栈中是否有 3 这个值,如果没找到,就将 3 存放进来,然后将 a 指向 3 。接着处理 int b = 3 ;在创建完 b 的引用变量后,因为在栈中已经有 3 这个值,便将 b 直接指向 3 。这样,就出现了 a 与 b 同时均指向 3 的情况。这时,如果再令 a=4 ;那么编译器会重新搜索栈中是否有 4 值,如果没有,则将 4 存放进来,并令 a 指向 4 ;如果已经有了,则直接将 a 指向这个地址。因此 a 值的改变不会影响到 b 的值。要注意这种数据的共享与两个对象的引用同时指向一个对象的这种共享是不同的,因为这种情况 a 的修改并不会影响到 b,它是由编译器完成的,它有利于节省空间。而一个对象引用变量修改了这个对象的内部状态,会影响到另一个对象引用变量。
JVM分代垃圾回收策略
为什么要分代
分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率。
在Java程序运行的过程中,会产生大量的对象,其中有些对象是与业务信息相关,比如Http请求中的Session对象、线程、Socket连接,这类对象跟业务直接挂钩,因此生命周期比较长。但是还有一些对象,主要是程序运行过程中生成的临时变量,这些对象生命周期会比较短,比如:String对象,由于其不变类的特性,系统会产生大量的这些对象,有些对象甚至只用一次即可回收。
试想,在不进行对象存活时间区分的情况下,每次垃圾回收都是对整个堆空间进行回收,花费时间相对会长,同时,因为每次回收都需要遍历所有存活对象,但实际上,对于生命周期长的对象而言,这种遍历是没有效果的,因为可能进行了很多次遍历,但是他们依旧存在。因此,分代垃圾回收采用分治的思想,进行代的划分,把不同生命周期的对象放在不同代上,不同代上采用最适合它的垃圾回收方式进行回收。
如何分代
如图所示:
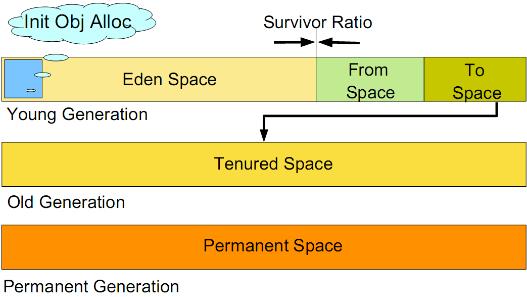
虚拟机中的共划分为三个代:年轻代(Young Generation)、年老代(Old Generation)和持久代(Permanent Generation)。其中持久代主要存放的是Java类的类信息,与垃圾收集要收集的Java对象关系不大。年轻代和年老代的划分是对垃圾收集影响比较大的。
年轻代:
所有新生成的对象首先都是放在年轻代的。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。年轻代分三个区。一个Eden区,两个Survivor区(一般而言)。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor区也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区(Tenured)”。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来的对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor区过来的对象。而且,Survivor区总有一个是空的。同时,根据程序需要,Survivor区是可以配置为多个的(多于两个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
新生代有划分为Eden、From Survivor和To Survivor三个部分,他们对应的内存空间的大小比例为8:1:1,也就是,为对象分配内存的时候,首先使用Eden空间,经过GC后,没有被回收的会首先进入From Survivor区域,任何时候,都会保持一个Survivor区域(From Survivor或To Survivor)完全空闲,也就是说新生代的内存利用率最大为90%。From Survivor和To Survivor两个区域会根据GC的实际情况,进行互换,将From Survivor区域中的对象全部复制到To Survivor区域中,或者反过来,将To Survivor区域中的对象全部复制到From Survivor区域中。
年老代:
在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
GC过程中,当某些对象经过多次GC都没有被回收,可能会进入到年老代。或者,当新生代没有足够的空间来为对象分配内存时,可能会直接在年老代进行分配。
持久代:
用于存放静态文件,如今Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate等,在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize=<N>进行设置。
永久代实际上对应着虚拟机运行时数据区的“方法区”,这里主要存放类信息、静态变量、常量等数据。一般情况下,永久代中对应的对象的GC效率非常低,因为这里的的大部分对象在运行都不要进行GC,它们会一直被利用,直到JVM退出。
JVM内存分配与回收策略
1.对象优先在Eden区分配
对象通常在新生代的Eden区进行分配,当Eden区没有足够空间进行分配时,虚拟机将发起一次Minor GC,与Minor GC对应的是Major GC、Full GC。
Minor GC:指发生在新生代的垃圾收集动作,非常频繁,速度较快。
Major GC:指发生在老年代的GC,出现Major GC,经常会伴随一次Minor GC,同时Minor GC也会引起Major GC,一般在GC日志中统称为GC,不频繁。
Full GC:指发生在老年代和新生代的GC,速度很慢,需要Stop The World。
2.大对象直接进入老年代
需要大量连续内存空间的Java对象称为大对象,大对象的出现会导致提前触发垃圾收集以获取更大的连续的空间来进行大对象的分配。虚拟机提供了-XX:PretenureSizeThreadshold参数来设置大对象的阈值,超过阈值的对象直接分配到老年代。
3.长期存活的对象进入老年代
每个对象有一个对象年龄计数器,与前面的对象的存储布局中的GC分代年龄对应。对象出生在Eden区、经过一次Minor GC后仍然存活,并能够被Survivor容纳,设置年龄为1,对象在Survivor区每次经过一次Minor GC,年龄就加1,当年龄达到一定程度(默认15),就晋升到老年代,虚拟机提供了-XX:MaxTenuringThreshold来进行设置。
4.动态对象年龄判断
对象的年龄到达了MaxTenuringThreshold可以进入老年代,同时,如果在survivor区中相同年龄所有对象大小的总和大于survivor区的一半,年龄大于等于该年龄的对象就可以直接进入老年代。无需等到MaxTenuringThreshold中要求的年龄。
5.空间分配担保
在发生Minor GC时,虚拟机会检查老年代连续的空闲区域是否大于新生代所有对象的总和,若成立,则说明Minor GC是安全的,否则,虚拟机需要查看HandlePromotionFailure的值,看是否运行担保失败,若允许,则虚拟机继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,若大于,将尝试进行一次Minor GC;若小于或者HandlePromotionFailure设置不运行冒险,那么此时将改成一次Full GC,以上是JDK Update 24之前的策略,之后的策略改变了,只要老年代的连续空间大于新生代对象总大小或者历次晋升的平均大小就会进行Minor GC,否则将进行Full GC。
冒险是指经过一次Minor GC后有大量对象存活,而新生代的survivor区很小,放不下这些大量存活的对象,所以需要老年代进行分配担保,把survivor区无法容纳的对象直接进入老年代。
50、内存溢出和内存泄漏
内存溢出:通俗理解就是内存不够,程序所需要的内存远远超出了你虚拟机分配的内存大小,就叫内存溢出。
内存泄漏:内存泄漏也称作“存储渗漏”,用动态存储分配函数动态开辟的空间,在使用完毕后未释放,结果导致一直占据该内存单元。直到程序结束。(其实说白了就是该内存空间使用完毕之后未回收)即所谓内存泄漏。
51、内存溢出了怎么办?
通过内存映像工具如jhat,jconsole等对dump出来的堆转存储快照进行分析,重点是确认内存是出现内存泄露还是内存溢出。 如果是内存泄露进一步使用工具查看泄露的对象到GC Roots的引用链。于是就能找到泄露对象是通过怎样的路径与GC Roots相关联并导致垃圾收集器无法自动回收它们。掌握泄露对象的信息,以及GC Roots引用链的信息,就可以比较准确定位泄露代码的位置。 如果不存在**内存泄露,那就需要通过jinfo,Jconsole等工具分析java堆参数与机器物理内存对比是否还可以调大,从代码上检查是否存在某些对象生命周期过长,持有状态过长的情况,尝试减少程序的运行消耗。
52、Java中有内存泄露吗?
有,Java中,造成内存泄露的原因有很多种。典型的例子是长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄露,尽管短生命周期对象已经不再需要,但是因为长生命周期对象持有它的引用而导致不能被回收,这就是java中内存泄露的发生场景,通俗地说,就是程序员可能创建了一个对象,以后一直不再使用这个对象,这个对象却一直被引用,即这个对象无用但是却无法被垃圾回收器回收的,这就是java中可能出现内存泄露的情况,例如,缓存系统,我们加载了一个对象放在缓存中(例如放在一个全局map对象中),然后一直不再使用它,这个对象一直被缓存引用,但却不再被使用。检查java中的内存泄露,一定要让程序将各种分支情况都完整执行到程序结束,然后看某个对象是否被使用过,如果没有,则才能判定这个对象属于内存泄露。(采用什么工具?) 如果一个外部类的实例对象的方法返回了一个内部类的实例对象,这个内部类对象被长期引用了,即使那个外部类实例对象不再被使用,但由于内部类持有外部类的实例对象,这个外部类对象将不会被垃圾回收,这也会造成内存泄露。
53、什么时候会发生jvm堆内存溢出?
简单的来说 java的堆内存分为两块:permantspace(持久代) 和 heap space。 持久带中主要用于存放静态类型数据,如 Java Class,,Method 等, 与垃圾收集器要收集的Java对象关系不大。 而heap space分为年轻代和年老代 年轻代的垃圾回收叫 Young GC, 年老代的垃圾回收叫 Full GC。 在年轻代中经历了N次(可配置)垃圾回收后仍然存活的对象,就会被复制到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象 年老代溢出原因有 循环上万次的字符串处理、创建上千万个对象、在一段代码内申请上百M甚至上G的内存 持久代溢出原因动态加载了大量Java类而导致溢出,以及生产大量的常量。 永久代内存泄露:以一个部署到应用程序服务器的Java web程序来说,当该应用程序被卸载的时候,你的EAR/WAR包中的所有类都将变得无用。只要应用程序服务器还活着,JVM将继续运行,但是一大堆的类定义将不再使用,理应将它们从永久代(PermGen)中移除。如果不移除的话,我们在永久代(PermGen)区域就会有内存泄漏。
54、OOM你遇到过哪些情况?
java.lang.OutOfMemoryError:Java heap space ------>java堆内存溢出,此种情况最常见,一般由于内存泄露或者堆的大小设置不当引起。
java.lang.OutOfMemoryError:PermGen space ------>java永久代溢出,即方法区溢出了,一般出现于大量Class或者jsp页面,或者采用cglib等反射机制的情况,因为上述情况会产生大量的Class信息存储于方法区。
java.lang.StackOverflowError ------> 不会抛OOM error,但也是比较常见的Java内存溢出。JAVA虚拟机栈溢出,一般是由于程序中存在死循环或者深度递归调用造成的,栈大小设置太小也会出现此种溢出。可以通过虚拟机参数-Xss来设置栈的大小。
55、GC的三种收集方法:标记清除、标记整理、复制算法的原理与特点,分别用在什么地方?
标记清除:首先标记所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象,它的标记的对象。缺点是效率低,且存在内存碎片。主要用于老生代垃圾回收。
复制算法:将内存按容量划分为大小相等的一块,每次只用其中一块。当内存用完了,将还存活的对象复制到另一块内存,然后把已使用过的内存空间一次清理掉。实现简单,高效。一般用于新生代。一般是将内存分为一块较大的Eden空间和两块较小的Survivor空间。HotSpot虚拟机默认比例是8:1,。每次使用Eden和一块Survivor,当回收时将这两块内存中还存活的对象复制到Survivor然后清理掉刚才Eden和Survivor的空间。如果复制过程内存不够使用则向老年代分配担保。
标记整理:首先标记所有需要回收的对象,在标记完成后让所有存活的对象都向一端移动,然后直接清理掉端边界意外的内存。用于老年代。
分代收集算法:根据对象的生存周期将内存划分为新生代和老年代,根据年代的特点采用最适当的收集算法。
56、Minor GC 与 Full GC 分别在什么时候发生?
FullGC 一般是发生在老年代的GC,出现一个FullGC经常会伴随至少一次的Minor GC。速度比MinorGC慢10倍以上。FULL GC发生的情况:
1) 老年代空间不足。老年代空间只有在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误:java.lang.OutOfMemoryError: Java heap space 。措施:为避免以上两种状况引起的FullGC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。
2) Permanet Generation(方法区或永久代)空间满。PermanetGeneration中存放的为一些class的信息等,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息: java.lang.OutOfMemoryError: PermGen space。措施:为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。
3) CMS GC时出现promotion failed和concurrent mode failure 对于采用CMS进行老年代GC的程序而言,尤其要注意GC日志中是否有promotion failed和concurrent mode failure两种状况,当这两种状况出现时可能会触发Full GC。 promotion failed是在进行Minor GC时,survivor space放不下、对象只能放入老年代,而此时老年代也放不下造成的; concurrent mode failure: CMS在执行垃圾回收时需要一部分的内存空间并且此刻用户程序也在运行需要预留一部分内存给用户程序,如果预留的内存无法满足程序需求就出现一次"Concurrent mod failure",并触发一次Full GC。 应对措施为:增大survivor space、老年代空间或调低触发并发GC的比率。
4) 统计得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间。 Hotspot为了避免由于新生代对象晋升到旧生代导致旧生代空间不足的现象,在进行Minor GC时,做了一个判断,如果之前统计所得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间,那么就直接触发Full GC。如果小于并且不允许担保失败也会发生一次Full GC。
MinorGC 指发生在新生代的垃圾收集动作,非常频繁,回收速度也快。一般发生在新生代空间不足时。另外一个FullGC经常会伴随至少一次的Minor GC.。当虚拟机检测晋升到老年代的平均大小是否小于老年代剩余空间大小,如果小于并且允许担保失败,则执行Minor GC。
57、类加载的五个过程:加载、验证、准备、解析、初始化。
类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个java.lang.Class对象,用来封装类在方法区内的数据结构。类的加载的最终产品是位于堆区中的Class对象,Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口。
加载: 根据全限定名来获取定义类的二进制字节流,然后将该字节流所代表的静态结构转化为方法区的运行时数据结构,最后在java堆上生成一个代表该类的Class对象,作为方法区这些数据的访问入口。
验证:主要是为了确保class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。包含四个阶段的验证过程:
1)文件格式验证:保证输入的字节流能够正确地解析并存储在方法区之内,格式上符合描述一个java类型信息的要求。
2)元数据验证:字节码语义信息的验证,以保证描述的信息符合java语言规范。验证点有:这个类是否有父类等。
3)字节码验证:主要是进行数据流和控制流分析,保证被校验类的方法在运行时不会做出危害虚拟机安全的行为.。
4)符号引用验证:对符号引用转化为直接引用过程的验证。
准备:为类变量分配内存并设置变量的初始值,这些内存在方法区进行分配。
这个阶段正式为类变量(被static修饰的变量)分配内存并设置类变量初始值,这个内存分配是发生在方法区中。
(1)注意这里并没有对实例变量进行内存分配,实例变量将会在对象实例化时随着对象一起分配在JAVA堆中。
(2)这里设置的初始值,通常是指数据类型的零值。
private static int a = 3;
这个类变量a在准备阶段后的值是0,将3赋值给变量a是发生在初始化阶段。
解析:将虚拟机常量池中的符号引用转化为直接引用的过程。解析主要是针对类或接口,字段,类方法。
初始化:执行静态变量的赋值操作以及静态代码块,完成初识化。初始化过程保证了父类中定义的初始化优先于子类的初始化,但接口不需要执行父类的初始化。
初始化是类加载机制的最后一步,这个时候才正真开始执行类中定义的JAVA程序代码。在前面准备阶段,类变量已经赋过一次系统要求的初始值,在初始化阶段最重要的事情就是对类变量进行初始化。在Java中对类变量进行初始值设定有两种方式:
①声明类变量时指定初始值
②使用静态代码块为类变量指定初始值
JVM初始化步骤
① 假如这个类还没有被加载和连接,则程序先加载并连接该类。
② 假如该类的直接父类还没有被初始化,则先初始化其直接父类。
③ 假如类中有初始化语句,则系统依次执行这些初始化语句。
类初始化时机:只有当对类主动使用的时候才会导致类的初始化,类的主动使用包括以下四种:
– 使用new关键字实例化对象、读取或者设置一个类的静态字段(被final修饰的静态字段除外)、调用一个类的静态方法的时候。
– 使用java.lang.reflect包中的方法对类进行反射调用的时候。
– 初始化一个类,发现其父类还没有初始化过的时候。
– 虚拟机启动的时候,虚拟机会先初始化用户指定的包含main()方法的那个类。
以上四种情况称为主动使用,其他的情况均称为被动使用,被动使用不会导致初始化。
- 初始化示例说明
① 子类引用父类静态字段(非final),不会导致子类初始化。
package com.demo;
class SuperClass {
static {
System.out.println("super");
}
public static int value = 123;
}
class SubClass extends SuperClass {
static {
System.out.println("sub");
}
}
public class TestInit {
public static void main(String[] args) {
System.out.println(SubClass.value);
}
}
运行结果:
super 123
说明:并没有初始化子类,虽然使用SubClass.value,但实际使用的是子类继承父类的静态字段,不会初始化SubClass。即只有直接定义了这个字段的类才会被初始化。
② 对于类或接口而言,使用其常量字段(final、static)不会导致其初始化。
package com.demo;
class SuperClass {
static {
System.out.println("super");
}
public static final int value = 123;
}
public class TestInit {
public static void main(String[] args) {
System.out.println(SuperClass.value);
}
}
运行结果:
123
说明:类或接口的常量并不会导致类或接口的初始化。因为常量在编译时进行优化,直接嵌入在TestInit.class文件的字节码中。用final修饰某个类变量时,它的值在编译时就已经确定好放入常量池了,所以在访问该类变量时,等于直接从常量池中获取,并没有初始化该类。
③ 对于类而言,初始化子类会导致父类(不包括接口)的初始化。
package com.demo;
class SuperClass {
static {
System.out.println("super");
}
public static final int value = 123;
}
class SubClass extends SuperClass {
public static int i = 3;
static {
System.out.println("sub");
}
}
public class TestInit {
public static void main(String[] args) {
System.out.println(SubClass.i);
}
}
运行结果:
super sub 3
说明:初始化子类会导致父类的初始化,并且父类的初始化在子类初始化的前面。
④ 通过数组定义引用类,不会触发此类的初始化。
package com.demo;
class SuperClass1{
public static int value = 123;
static
{
System.out.println("SuperClass init");
}
}
public class TestMain
{
public static void main(String[] args)
{
SuperClass1[] scs = new SuperClass1[10];
}
}
运行结果:什么也不输出
⑤ 对于接口而言,初始化子接口不会导致父接口的初始化,只有在真正使用到父接口的时候(如使用父接口中定义的常量),才会初始化。
Class.forName()和ClassLoader.loadClass()区别
Class.forName():将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块;
ClassLoader.loadClass():只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
注:Class.forName(name, initialize, loader)带参函数也可控制是否加载static块。并且只有调用了newInstance()方法采用调用构造函数,创建类的对象 。
58、双亲委派模型
除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。顺序依次是:
Bootstrap ClassLoader::启动类加载器,加载java_home/lib中的类。
Extension ClassLoader:扩展类加载器,加载java_home/lib/ext目录下的类库。
Application ClassLoader::应用程序类加载器,加载用户类路径上指定类库。
双亲委派模型的工作原理是:如果一个类加载器收到了类加载请求,它首先不会自己去尝试加载这个类,而把这个请求委派给父类加载器去完成,每一层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父类加载器反馈自己无法完成加载请求时,加载器才尝试自己加载。这种方式保证了Oject类在各个加载器加载环境中都是同一个类。
双亲委派模型的好处
它的好处可以用一句话总结,即防止内存中出现多份同样的字节码。从反向思考这个问题,如果没有双亲委派模型而是由各个类加载器自行加载的话,如果用户编写了一个java.lang.Object的同名类并放在ClassPath中,多个类加载器都去加载这个类到内存中,系统中将会出现多个不同的Object类,那么类之间的比较结果及类的唯一性将无法保证,而且如果不使用这种双亲委派模型将会给虚拟机的安全带来隐患。所以,要让类对象进行比较有意义,前提是他们要被同一个类加载器加载。
(1)启动类加载器:<JAVA_HOME>lib
(2)扩展类加载器:<JAVA_HOME>libext
(3)应用程序类加载器:加载用户类路径上所指定的类库
四、Java多线程
59、进程和线程之间有什么不同?
一个进程是一个独立(self contained)的运行环境,它可以被看作一个程序或者一个应用。而线程是在进程中执行的一个任务。Java运行环境是一个包含了不同的类和程序的单一进程。线程可以被称为轻量级进程。线程需要较少的资源来创建和驻留在进程中,并且可以共享进程中的资源。
60、多线程编程的好处是什么?
在多线程程序中,多个线程被并发的执行以提高程序的效率,CPU不会因为某个线程需要等待资源而进入空闲状态。多个线程共享堆内存(heap memory),因此创建多个线程去执行一些任务会比创建多个进程更好。举个例子,Servlets比CGI更好,是因为Servlets支持多线程而CGI不支持。
61、多线程有什么用?
一个可能在很多人看来很扯淡的一个问题:我会用多线程就好了,还管它有什么用?在我看来,这个回答更扯淡。所谓”知其然知其所以然”,”会用”只是”知其然”,”为什么用”才是”知其所以然”,只有达到”知其然知其所以然”的程度才可以说是把一个知识点运用自如。OK,下面说说我对这个问题的看法:
(1)发挥多核CPU的优势
随着工业的进步,现在的笔记本、台式机乃至商用的应用服务器至少也都是双核的,4核、8核甚至16核的也都不少见,如果是单线程的程序,那么在双核CPU上就浪费了50%,在4核CPU上就浪费了75%。单核CPU上所谓的”多线程”那是假的多线程,同一时间处理器只会处理一段逻辑,只不过线程之间切换得比较快,看着像多个线程”同时”运行罢了。多核CPU上的多线程才是真正的多线程,它能让你的多段逻辑同时工作,多线程,可以真正发挥出多核CPU的优势来,达到充分利用CPU的目的。
(2)防止阻塞
从程序运行效率的角度来看,单核CPU不但不会发挥出多线程的优势,反而会因为在单核CPU上运行多线程导致线程上下文的切换,而降低程序整体的效率。但是单核CPU我们还是要应用多线程,就是为了防止阻塞。试想,如果单核CPU使用单线程,那么只要这个线程阻塞了,比方说远程读取某个数据吧,对端迟迟未返回又没有设置超时时间,那么你的整个程序在数据返回回来之前就停止运行了。多线程可以防止这个问题,多条线程同时运行,哪怕一条线程的代码执行读取数据阻塞,也不会影响其它任务的执行。
(3)便于建模
这是另外一个没有这么明显的优点了。假设有一个大的任务A,单线程编程,那么就要考虑很多,建立整个程序模型比较麻烦。但是如果把这个大的任务A分解成几个小任务,任务B、任务C、任务D,分别建立程序模型,并通过多线程分别运行这几个任务,那就简单很多了。
62、创建多线程的方式
比较常见的一个问题了,一般就是两种:
(1)继承Thread类
(2)实现Runnable接口
至于哪个好,不用说肯定是后者好,因为实现接口的方式比继承类的方式更灵活,也能减少程序之间的耦合度,面向接口编程也是设计模式6大原则的核心。
63、start()方法和run()方法的区别
只有调用了start()方法,才会表现出多线程的特性,不同线程的run()方法里面的代码交替执行。如果只是调用run()方法,那么代码还是同步执行的,必须等待一个线程的run()方法里面的代码全部执行完毕之后,另外一个线程才可以执行其run()方法里面的代码。
start()方法来启动线程,真正实现了多线程运行。这时无需等待run方法体代码执行完毕,可以直接继续执行下面的代码;通过调用Thread类的start()方法来启动一个线程, 这时此线程是处于就绪状态, 并没有运行。 然后通过此Thread类调用方法run()来完成其运行操作的, 这里方法run()称为线程体,它包含了要执行的这个线程的内容,run方法运行结束, 此线程终止。然后CPU再调度其它线程。
run()方法当作普通方法的方式调用。程序还是要顺序执行,要等待run方法体执行完毕后,才可继续执行下面的代码; 程序中只有主线程这一个线程, 其程序执行路径还是只有一条, 这样就没有达到写线程的目的。
记住:多线程就是分时利用CPU,宏观上让所有线程一起执行 ,也叫并发。
64、有哪些不同的线程生命周期?
关于Java中线程的生命周期,首先看一下下面这张较为经典的图:

Java线程具有五种基本状态
新建状态(New):当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread()。
就绪状态(Runnable):当调用线程对象的start()方法(t.start();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行。
运行状态(Running):当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中。
阻塞状态(Blocked):处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才有机会再次被CPU调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
1.等待阻塞 -- 运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
2.同步阻塞 -- 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
3.其他阻塞 -- 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
65、sleep方法和wait方法有什么区别?
(1)sleep()方法是属于Thread类中的。而wait()方法,则是属于Object类中的。
(2)最主要是sleep方法没有释放锁,而wait方法释放了锁。
(3)wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用。
(4)sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常。
详解:
sleep方法属于Thread类中方法,表示让一个线程进入睡眠状态,等待一定的时间之后,自动醒来进入到可运行状态,但它不会马上进入运行状态,因为其它线程可能正在运行而且没有被调度为放弃执行,除非(a) “醒来”的线程具有更高的优先级;(b)正在运行的线程因为其它原因而阻塞。 一个线程对象调用了sleep方法之后,并不会释放他所持有的所有对象锁,所以也就不会影响其他进程对象的运行。但在 sleep的过程中过程中有可能被其他对象调用它的interrupt(),产生InterruptedException异常,如果你的程序不捕获这个异常,线程就会异常终止,进入TERMINATED状态,如果你的程序捕获了这个异常,那么程序就会继续执行catch语句块(可能还有finally语句块)以及以后的代码。注意sleep()方法是一个静态方法,也就是说他只对当前对象有效,不能通过t.sleep()让t对象进入sleep。
wait属于Object的成员方法,一旦一个对象调用了wait方法,必须要采用notify()和notifyAll()方法唤醒该进程。如果线程拥有某个或某些对象的同步锁,那么在调用了wait()后,这个线程就会释放它持有的所有同步资源,而不限于这个被调用了wait()方法的对象。从而使线程所在对象中的其它synchronized数据可被别的线程使用。 wait()方法也同样会在wait的过程中有可能被其他对象调用interrupt()方法而产生InterruptedException,效果以及处理方式同sleep()方法。
sleep指线程被调用时,占着CPU不工作,形象地说明为“占着CPU睡觉”,此时,系统的CPU部分资源被占用,其他线程无法进入,会增加时间限制。wait指线程处于进入等待状态,形象地说明为“等待使用CPU”,此时线程不占用任何资源,不增加时间限制。所以sleep(100L)意思为:占用CPU,线程休眠100毫秒;wait(100L)意思为:不占用CPU,线程等待100毫秒。
例子:
package com.demo.test;
/**
* Thread sleep和wait区别
* @author lixiaoxi
* 2017-12-22
*/
public class SleepWaitTest implements Runnable{
int number = 10;
public void firstMethod() throws Exception {
synchronized (this) {
number += 100;
System.out.println(number);
}
}
public void secondMethod() throws Exception {
synchronized (this) {
/**
* (休息2S,阻塞线程)
* 以验证当前线程对象的机锁被占用时,
* 是否可以访问其他同步代码块
*/
Thread.sleep(2000);
//this.wait(2000);
number *= 200;
}
}
@Override
public void run() {
try {
firstMethod();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
SleepWaitTest threadTest = new SleepWaitTest();
Thread thread = new Thread(threadTest);
thread.start();
threadTest.secondMethod();
System.out.println("number="+threadTest.number);
}
}
使用sleep() 方法输出结果:
2100 number=2100
使用wait() 方法输出结果:
110 number=22000
我们来大致分析一下此段代码,main()方法中实例化ThreadTest并启动该线程,然后调用该线程的一个方法(secondMethod()),因为在主线程中调用方法,所以调用的普通方法secondMethod())会先被执行(但并不是普通方法执行完毕,该对象的线程方法才执行,普通方法执行过程中,该线程的方法也会被执行,他们是交替执行的,只是在主线程的普通方法会先被执行而已),所以程序运行时会先执行secondMethod(),而secondMethod()方法代码片段中有synchronized block,因此secondMethod方法被执行后,该方法会占有该对象机锁导致该对象的线程方法一直处于阻塞状态,不能执行,直到secondeMethod释放锁。
使用Thread.sleep(2000)方法时,因为sleep在阻塞线程的同时,并持有该对象锁,所以该对象的其他同步方法(firstMethod())无法执行,直到synchronized block执行完毕(sleep休眠完毕),firstMethod()方法才可以执行,因此输出结果为number*200+100。最后在main方法中输出的number值跟在firstMethod() 方法中输出的结果一样,都是2100。
使用this.wait(2000)方法时,secondMethod()方法被执行后也锁定了该对象的机锁,执行到this.wait(2000)时,该方法会休眠2s并释放当前持有的锁,此时该线程的同步方法会被执行(因为secondMethod持有的锁,已经被wait()所释放),因此输出的结果为:number+100。而2s 过后,secondMethod方法被唤醒,继续执行wait后面的语句,即number *=200,因此在main方法中输出的结果为number=22000。
66、为什么线程通信的方法wait(), notify()和notifyAll()被定义在Object类里?
(1)这些方法存在于同步中;
(2)使用这些方法必须标识同步所属的锁;
(3)锁可以是任意对象,所以任意对象调用方法一定定义在Object类中。
简单说:因为synchronized中的这把锁可以是任意对象,所以任意对象都可以调用wait()和notify();所以wait和notify属于Object。
专业说:因为这些方法在操作同步线程时,都必须要标识它们操作线程的锁,只有同一个锁上的被等待线程,可以被同一个锁上的notify唤醒,不可以对不同锁中的线程进行唤醒。也就是说,等待和唤醒必须是同一个锁。而锁可以是任意对象,所以可以被任意对象调用的方法是定义在object类中。
67、为什么wait(), notify()和notifyAll()必须在同步方法或者同步块中被调用?
当一个线程需要调用对象的wait()方法的时候,这个线程必须拥有该对象的锁,接着它就会释放这个对象锁并进入等待状态直到其他线程调用这个对象上的notify()方法。同样的,当一个线程需要调用对象的notify()方法时,它会释放这个对象的锁,以便其他在等待的线程就可以得到这个对象锁。由于所有的这些方法都需要线程持有对象的锁,这样就只能通过同步来实现,所以他们只能在同步方法或者同步块中被调用。
注意:wait(),notify(),notifyAll()都必须使用在同步中,因为要对持有监视器(锁)的线程操作。所以要使用在同步中,因为只有同步 才具有锁。
68、线程的sleep()方法和yield()方法有什么区别?
① sleep()方法给其他线程运行机会时不考虑线程的优先级,因此会给低优先级的线程以运行的机会;yield()方法只会给相同优先级或更高优先级的线程以运行的机会;
② 线程执行sleep()方法后转入阻塞(blocked)状态,而执行yield()方法后转入就绪(ready)状态;
③ sleep()方法声明抛出InterruptedException,而yield()方法没有声明任何异常;
④ sleep()方法比yield()方法(跟操作系统CPU调度相关)具有更好的可移植性。
sleep 方法使当前运行中的线程睡眠一段时间,进入不可以运行状态,这段时间的长短是由程序设定的,yield方法使当前线程让出CPU占有权,但让出的时间是不可设定的。yield()也不会释放锁标志。
实际上,yield()方法对应了如下操作:先检测当前是否有相同优先级的线程处于同可运行状态,如有,则把CPU的占有权交给此线程,否则继续运行原来的线程,所以yield()方法称为“退让”,它把运行机会让给了同等级的其他线程。
sleep 方法允许较低优先级的线程获得运行机会,但yield() 方法执行时,当前线程仍处在可运行状态,所以不可能让出较低优先级的线程此时获取CPU占有权。在一个运行系统中,如果较高优先级的线程没有调用sleep方法,也没有受到I/O阻塞,那么较低优先级线程只能等待所有较高优先级的线程运行结束,方可有机会运行。
yield()只是使当前线程重新回到可执行状态,所有执行yield()的线程有可能在进入到可执行状态后马上又被执行,所以yield()方法只能使同优先级的线程有执行的机会。
69、wait() 与 yield() 的比较
我们知道,wait()的作用是让当前线程由“运行状态”进入“等待(阻塞)状态”的同时,也会释放同步锁。而yield()的作用是让步,它也会让当前线程离开“运行状态”。它们的区别是:
(1) wait()是让线程由“运行状态”进入到“等待(阻塞)状态”,而yield()是让线程由“运行状态”进入到“就绪状态”。
(2) wait()是会让线程释放它所持有对象的同步锁,而yield()方法不会释放锁。
70、volatile关键字的作用
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
volatile关键字禁止指令重排序有两层意思:
1)当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
2)在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
可能上面说的比较绕,举个简单的例子:
//x、y为非volatile变量 //flag为volatile变量 x = 2; //语句1 y = 0; //语句2 volatile flag = true; //语句3 x = 4; //语句4 y = -1; //语句5
由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,不会将语句3放到语句1、语句2前面,也不会将语句3放到语句4、语句5后面。但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。并且volatile关键字能保证,执行到语句3时,语句1和语句2必定是执行完毕了的,且语句1和语句2的执行结果对语句3、语句4、语句5是可见的。
volatile与加锁机制的区别:
加锁机制既可以确保可见性又可以确保原子性,而volatile变量只能确保可见性。注意:volatile没办法保证对变量的操作的原子性。
当且仅当满足以下所有条件时,才应该使用volatile变量:
1)对变量的写入操作不依赖变量的当前值,或者你能确保只有单个线程更新变量的值。
2)该变量不会与其他状态变量一起纳入不变性条件中。
3)在访问变量时不需要
volatile的原理和实现机制
下面这段话摘自《深入理解Java虚拟机》:
“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
使用volatile关键字的场景
synchronized关键字是防止多个线程同时执行一段代码,那么就会很影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。通常来说,使用volatile必须具备以下2个条件:
1)对变量的写操作不依赖于当前值
2)该变量没有包含在具有其他变量的不变式中
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。事实上,我的理解就是上面的2个条件需要保证操作是原子性操作,才能保证使用volatile关键字的程序在并发时能够正确执行。
把代码块声明为 synchronized,有两个重要后果,通常是指该代码具有 原子性(atomicity)和 可见性(visibility)。
- 原子性意味着某个时刻,只有一个线程能够执行一段代码,这段代码通过一个monitor object保护。从而防止多个线程在更新共享状态时相互冲突。
- 可见性则更为微妙,它必须确保释放锁之前对共享数据做出的更改对于随后获得该锁的另一个线程是可见的。 —— 如果没有同步机制提供的这种可见性保证,线程看到的共享变量可能是修改前的值或不一致的值,这将引发许多严重问题。
volatile的使用条件
volatile 变量具有 synchronized 的可见性特性,但是不具备原子性。这就是说线程能够自动发现 volatile 变量的最新值。
volatile 变量可用于提供线程安全,但是只能应用于非常有限的一组用例:多个变量之间或者某个变量的当前值与修改后值之间没有约束。因此,单独使用 volatile 还不足以实现计数器、互斥锁或任何具有与多个变量相关的不变式(Invariants)的类(例如 “start <=end”)。
使用条件
您只能在有限的一些情形下使用 volatile 变量替代锁。要使 volatile 变量提供理想的线程安全,必须同时满足下面两个条件:
- 对变量的写操作不依赖于当前值。
- 该变量没有包含在具有其他变量的不变式中。
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
第一个条件的限制使 volatile 变量不能用作线程安全计数器。虽然增量操作(x++)看上去类似一个单独操作,实际上它是一个由(读取-修改-写入)操作序列组成的组合操作,必须以原子方式执行,而 volatile 不能提供必须的原子特性。实现正确的操作需要使x 的值在操作期间保持不变,而 volatile 变量无法实现这点。(然而,如果只从单个线程写入,那么可以忽略第一个条件。)
volatile适用场景
场景1:volatile最适用一个线程写,多个线程读的场合。
如果有多个线程并发写操作,仍然需要使用锁或者线程安全的容器或者原子变量来代替。(摘自Netty权威指南)
疑问:如果只是赋值的原子操作,是否可以多个线程写?(答案:可以,但是一般没有这样的必要,即没有这样的应用场景)
最经典的使用案例:状态标志
也许实现 volatile 变量的规范使用仅仅是使用一个布尔状态标志,用于指示发生了一个重要的一次性事件,例如完成初始化或请求停机。
volatile boolean shutdownRequested;
...
public void shutdown() { shutdownRequested = true; }
public void doWork() {
while (!shutdownRequested) {
// do stuff
}
}
线程1执行doWork()的过程中,可能有另外的线程2调用了shutdown,所以boolean变量必须是volatile。
而如果使用 synchronized 块编写循环要比使用 volatile 状态标志编写麻烦很多。由于 volatile 简化了编码,并且状态标志并不依赖于程序内任何其他状态,因此此处非常适合使用 volatile。
这种类型的状态标记的一个公共特性是:通常只有一种状态转换;shutdownRequested 标志从false 转换为true,然后程序停止。这种模式可以扩展到来回转换的状态标志,但是只有在转换周期不被察觉的情况下才能扩展(从false 到true,再转换到false)。此外,还需要某些原子状态转换机制,例如原子变量。
将 volatile 变量作为状态标志使用:线程以volatile变量作为循环控制变量(例如控制线程是否继续执行,控制线程的生命周期),由另外一个线程控制该变量的值(true or false)。这种情况需要变量具有可见性,volatile变量适合。然而,使用 synchronized 块编写循环要比使用volatile 状态标志编写麻烦很多。由于 volatile 简化了编码,并且状态标志并不依赖于程序内任何其他状态,因此此处非常适合使用 volatile。
场景2:结合使用 volatile 和 synchronized 实现 “开销较低的读-写锁”
如果读操作远远超过写操作,您可以结合使用内部锁和 volatile 变量来减少公共代码路径的开销。
如下显示的线程安全的计数器,使用 synchronized 确保增量操作是原子的,并使用 volatile 保证当前结果的可见性。如果更新不频繁的话,该方法可实现更好的性能,因为读路径的开销仅仅涉及 volatile 读操作,这通常要优于一个无竞争的锁获取的开销。
public class CheesyCounter {
// Employs the cheap read-write lock trick
// All mutative operations MUST be done with the 'this' lock held
@GuardedBy("this") private volatile int value;
//读操作,没有synchronized,提高性能
public int getValue() {
return value;
}
//写操作,必须synchronized。因为x++不是原子操作
public synchronized int increment() {
return value++;
}
}
使用锁进行所有变化的操作,使用 volatile 进行只读操作。其中,锁一次只允许一个线程访问值,volatile 允许多个线程执行读操作。
正确使用volatile关键字
synchronized关键字是防止多个线程同时执行一段代码,那么就会很影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。
volatile 变量具有 synchronized 的可见性特性,但是不具备原子性。这就是说线程能够自动发现 volatile 变量的最新值。volatile 变量可用于提供线程安全,但是只能应用于非常有限的一组用例:多个变量之间或者某个变量的当前值与修改后值之间没有约束。因此,单独使用 volatile 还不足以实现计数器、互斥锁或任何具有与多个变量相关的不变式(Invariants)的类(例如 “start <=end”)。
出于简易性或可伸缩性的考虑,您可能倾向于使用 volatile 变量而不是锁。当使用 volatile 变量而非锁时,某些习惯用法(idiom)更加易于编码和阅读。此外,volatile 变量不会像锁那样造成线程阻塞,因此也很少造成可伸缩性问题。在某些情况下,如果读操作远远大于写操作,volatile 变量还可以提供优于锁的性能优势。
使用条件
您只能在有限的一些情形下使用 volatile 变量替代锁。要使 volatile 变量提供理想的线程安全,必须同时满足下面两个条件:
- 对变量的写操作不依赖于当前值。
- 该变量没有包含在具有其他变量的不变式中。
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
第一个条件就是不能是自增自减等操作。第一个条件的限制使 volatile 变量不能用作线程安全计数器。虽然增量操作(x++)看上去类似一个单独操作,实际上它是一个由(读取-修改-写入)操作序列组成的组合操作,必须以原子方式执行,而 volatile 不能提供必须的原子特性。
第二个条件我们来举个例子它包含了一个不变式 :下界总是小于或等于上界。
public class NumberRange {
private int lower, upper;
public int getLower() { return lower; }
public int getUpper() { return upper; }
public void setLower(int value) {
if (value > upper)
throw new IllegalArgumentException(...);
lower = value;
}
public void setUpper(int value) {
if (value < lower)
throw new IllegalArgumentException(...);
upper = value;
}
}
这种方式限制了范围的状态变量。因此将 lower 和 upper 字段定义为 volatile 类型不能够充分实现类的线程安全;而仍然需要使用同步——使 setLower() 和 setUpper() 操作原子化。
否则,如果凑巧两个线程在同一时间使用不一致的值执行 setLower 和 setUpper 的话,则会使范围处于不一致的状态。例如,如果初始状态是(0, 5),同一时间内,线程 A 调用setLower(4) 并且线程 B 调用setUpper(3),显然这两个操作交叉存入的值是不符合条件的,那么两个线程都会通过用于保护不变式的检查,使得最后的范围值是(4, 3) —— 一个无效值,这显然是不对的。
volatile 与 synchronized 的比较
(1)volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取;synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住;
(2)volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的;
(3)volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性;
(4)volatile不会造成线程的阻塞,即volatile不能用来同步,因为多个线程并发访问volatile修饰的变量不会阻塞;synchronized可能会造成线程的阻塞;
(5)当一个域的值依赖于它之前的值时,volatile就无法工作了,如n=n+1,n++等。如果某个域的值受到其他域的值的限制,那么volatile也无法工作,如Range类的lower和upper边界,必须遵循lower<=upper的限制。
(6)volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化。
总结:
与锁相比,volatile 变量是一种非常简单但同时又非常脆弱的同步机制,它在某些情况下将提供优于锁的性能和伸缩性。如果严格遵循 volatile 的使用条件即变量真正独立于其他变量和自己以前的值 ,在某些情况下可以使用 volatile 代替 synchronized 来简化代码。然而,使用 volatile 的代码往往比使用锁的代码更加容易出错。
线程同步小结
(1)线程同步的目的是为了保护多个线程访问一个资源时对资源的破坏。
(2)线程同步方法是通过锁来实现,每个对象都有且仅有一个锁,这个锁与一个特定的对象关联,线程一旦获取了对象锁,其他访问该对象的线程就无法再访问该对象的其他同步方法。
(3)对于静态同步方法,锁是针对这个类的,锁对象是该类的Class对象。静态和非静态方法的锁互不干预。一个线程获得锁,当在一个同步方法中访问另外对象上的同步方法时,会获取这两个对象锁。
(4)对于同步,要时刻清醒在哪个对象上同步,这是关键。
(5)编写线程安全的类,需要时刻注意对多个线程竞争访问资源的逻辑和安全做出正确的判断,对“原子”操作做出分析,并保证原子操作期间别的线程无法访问竞争资源。
(6)当多个线程等待一个对象锁时,没有获取到锁的线程将发生阻塞。
71、synchronized关键字
当synchronized关键字修饰一个方法的时候,该方法叫做同步方法。如果一个对象有多个synchronized方法,某一时刻某个线程已经进入到了某个synchronized方法,那么在该方法没有执行完毕前,其他线程是无法访问该对象的任何synchronized方法的。
Java中的每个对象都有一个锁(lock),或者叫做监视器(monitor),当一个线程访问某个对象的synchronized方法时,将该对象上锁,其他任何线程都无法再去访问该对象的synchronized方法了(这里是指所有的同步方法,而不仅仅是同一个方法),直到之前的那个线程执行方法完毕后(或者是抛出了异常),才将该对象的锁释放掉,其他线程才有可能再去访问该对象的synchronized方法。注意这时候是给对象上锁,如果是不同的对象,则各个对象之间没有限制关系。
当一个synchronized关键字修饰的方法同时又被static修饰,之前说过,非静态的同步方法会将对象上锁,但是静态方法不属于对象,而是属于类,它会将这个方法所在的类的Class对象上锁。一个类不管生成多少个对象,它们所对应的是同一个Class对象。
(1)当一个线程访问“某对象”的“synchronized方法”或者“synchronized代码块”时,其他线程对“该对象”的该“synchronized方法”或者“synchronized代码块”的访问将被阻塞。
(2)当一个线程访问“某对象”的“synchronized方法”或者“synchronized代码块”时,其他线程仍然可以访问“该对象”的非同步代码块。
(3)当一个线程访问“某对象”的“synchronized方法”或者“synchronized代码块”时,其他线程对“该对象”的其他的“synchronized方法”或者“synchronized代码块”的访问将被阻塞。
(4)如果某个synchronized方法是static的,那么它锁的并不是synchronized方法所在的对象,而是synchronized方法所在对象所对应的Class对象,因为Java中不管一个类有多少对象,这些对象会对应唯一一个Class对象。因此当线程分别访问同一个类的两个对象的两个static synchronized方法时,是顺序执行的,亦即一个线程先执行,完毕之后,另一个才开始执行。
(5)synchronized 方法是一种粗粒度的并发控制,某一时刻,只能有一个线程执行synchronized方法;synchronized块则是一种细粒度的并发控制,只会将块中代码同步,位于方法内,synchronized块之外的代码是可以被多个线程同时访问的。
(6)了解了锁的概念和synchronized修饰方法的用法之后我们可以总结出,两个方法是不是互斥的关键是看两个方法取得的锁是不是互斥的,如果锁是互斥的,那么方法也是互斥访问的,如果锁不是互斥的,那么不同的锁之间是不会有什么影响的,所以这时方法是可以同时访问的。
(7)synchronized进过编译,会在同步块的前后分别形成monitorenter和monitorexit这个两个字节码指令。在执行monitorenter指令时,首先要尝试获取对象锁。如果这个对象没被锁定,或者当前线程已经拥有了那个对象锁,把锁的计算器加1,相应的,在执行monitorexit指令时会将锁计算器就减1,当计算器为0时,锁就被释放了。如果获取对象锁失败,那当前线程就要阻塞,直到对象锁被另一个线程释放为止。
public class SynDemo{
public static void main(String[] arg){
Runnable t1=new MyThread();
new Thread(t1,"t1").start();
new Thread(t1,"t2").start();
}
}
class MyThread implements Runnable {
@Override
public void run() {
synchronized (this) {
for(int i=0;i<10;i++)
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
查看字节码指令:
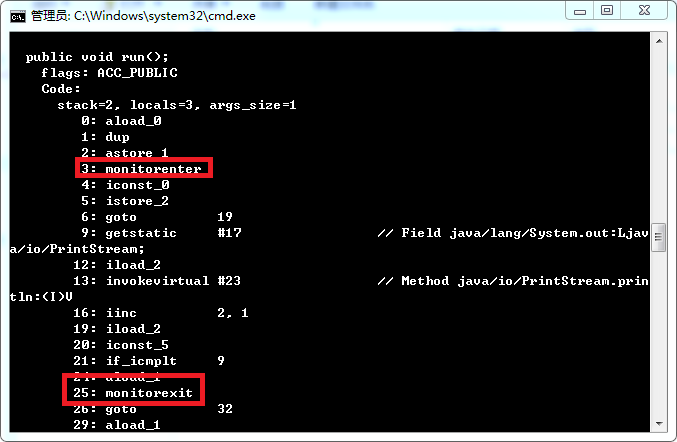
synchronized原理分析
synchronized 使用的一般场景,在对象方法和类方法上使用,以及自定义同步代码块。但是在方法上使用 synchronized 关键字和使用同步代码块是不一样的,方法上采用同步是采用的字节码中的标志位 ACC_SYNCHRONIZED 来进行同步的。而同步代码块则是采用了对象头中的锁指针指向一个监视器(锁),来完成同步。
当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取 monitor ,获取成功之后才能执行方法体,方法执行完后再释放 monitor 。在方法执行期间,其他任何线程都无法再获得同一个 monitor 对象。 其实本质上没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。
(1)synchronized代码块原理
反编译下面的代码得到的字节码如下:
public class SynchronizedTest {
public static void main(String[] args) {
synchronized (SynchronizedTest.class) {
System.out.println("hello");
}
}
public synchronized void test(){
}
}
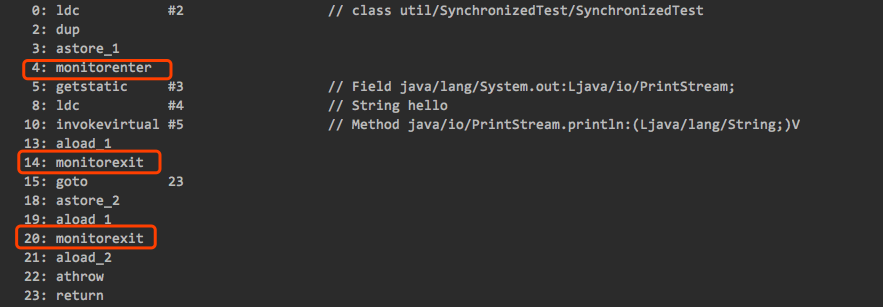
当执行monitorenter指令时,当前线程将试图获取 objectref(即对象锁) 所对应的 monitor 的持有权,当 objectref 的 monitor 的进入计数器为 0,那线程可以成功取得 monitor,并将计数器值设置为 1,取锁成功。如果当前线程已经拥有 objectref 的 monitor 的持有权,那它可以重入这个 monitor ,重入时计数器的值也会加 1。倘若其他线程已经拥有 objectref 的 monitor 的所有权,那当前线程将被阻塞,直到正在执行线程执行完毕,即monitorexit指令被执行,执行线程将释放 monitor(锁)并设置计数器值为0 ,其他线程将有机会持有 monitor 。值得注意的是编译器将会确保无论方法通过何种方式完成,方法中调用过的每条 monitorenter 指令都有执行其对应 monitorexit 指令,而无论这个方法是正常结束还是异常结束。为了保证在方法异常完成时 monitorenter 和 monitorexit 指令依然可以正确配对执行,编译器会自动产生一个异常处理器,这个异常处理器声明可处理所有的异常,它的目的就是用来执行 monitorexit 指令。所以看到上面有两条 monitorexit !
每个对象都有一个与其关联的监视器。当监视器被占有的时候,监视器就处于锁定状态。线程执行moniterenter尝试获得监视器的所有权。如果监视器的进入次数为0,线程进入监视器,并将监视器的进入次数置为1次。接下来此线程就是这个监视器的所有者。如果线程已经拥有了监视器的所有权,当线程重现进入监视器,监视器的进入次数加1。如果其他线程已经拥有了监视器的所有权,那么线程将会阻塞,直到监视器的进入次数减到0时,线程才会再次尝试获取监视器的所有权。
(2)synchronized方法原理
先看一个反编译的实例方法的结果,确实比普通的方法多了一个标志字段。方法级的同步是隐式,即无需通过字节码指令来控制的,它实现在方法调用和返回操作之中。当方法调用时,调用指令将会 检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先持有 monitor , 然后再执行方法,最后再方法完成(无论是正常完成还是非正常完成)时释放monitor。在方法执行期间,执行线程持有了monitor,其他任何线程都无法再获得同一个monitor。如果一个同步方法执行期间抛 出了异常,并且在方法内部无法处理此异常,那这个同步方法所持有的monitor将在异常抛到同步方法之外时自动释放。
对同步方法,JVM采用ACC_SYNCHRONIZED标记符来实现同步。 对于同步代码块。JVM采用monitorenter、monitorexit两个指令来实现同步。同步方法通过ACC_SYNCHRONIZED关键字隐式的对方法进行加锁。当线程要执行的方法被标注上ACC_SYNCHRONIZED时,需要先获得锁才能执行该方法。同步代码块通过monitorenter和monitorexit执行来进行加锁,其中monitorenter指令指向同步代码块的开始位置,monitorexit指令则指明同步代码块的结束位置。当线程执行到monitorenter的时候要先获得所锁,才能执行后面的方法。当线程执行到monitorexit的时候则要释放锁。
方法的同步并没有通过指令monitorenter和monitorexit来完成(理论上其实也可以通过这两条指令来实现),不过相对于普通方法,其常量池中多了ACC_SYNCHRONIZED标示符。JVM就是根据该标示符来实现方法的同步的:当方法调用时,调用指令将会检查方法的ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。 其实本质上没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。
每个对象自身维护这一个被加锁次数的计数器,当计数器数字为0时表示可以被任意线程获得锁。当计数器不为0时,只有获得锁的线程才能再次获得锁,即可重入锁。换句话说,一个线程获取到锁之后可以无限次地进入该临界区。
synchronized关键字锁住的是什么东西?
无论你将synchronized加在方法【非static,static的后面还会说】前还是加在一个变量【非static,static的后面还会说】前,其锁定的都是一个对象。 每一个对象都只有一个锁与之相关联。

上面两种写法是一样的,都是锁定实例对象。
下面的写法都是锁定类对象。在下面的例子中是锁定的Demo3这个类。【当锁定static变量的时候,由于static变量只有一份拷贝,所以此时锁定的也是类对象】

在这种情况下,如果有一个线程thread 访问了这4个方法中的任何一个, 在同一时间内其它的线程都不能访问这4个方法。
在Java中,synchronized关键字是用来控制线程同步的,就是在多线程的环境下,控制synchronized代码段不被多个线程同时执行。synchronized可以保证在同一时刻,只有一个线程可以执行某一个方法或者代码块,同时它还可以保证共享变量的内存可见性。
synchronized是Java中解决并发问题的一种最常用的方法,也是最简单的一种方法。synchronized的作用主要有三个:
(1)确保线程互斥的访问同步代码
(2)保证共享变量的修改能够及时可见
(3)有效解决重排序问题。从语法上讲,它总共有三种使用场合:
(1)修饰实例方法,作用于当前实例加锁,进入同步代码前要获得当前实例的锁
(2)修饰静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁
(3)修饰代码块,指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
- 普通同步方法,锁是当前实例对象
- 静态同步方法,锁是当前类的class对象
- 同步方法块,锁是括号里面的对象
synchronized既可以加在一段代码上,也可以加在方法上。关键是,不要认为给方法或者代码段加上synchronized就万事大吉,看下面一段代码:
class Sync {
public synchronized void test() {
System.out.println("test开始..");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("test结束..");
}
}
class MyThread extends Thread {
public void run() {
Sync sync = new Sync();
sync.test();
}
}
public class Main {
public static void main(String[] args) {
for (int i = 0; i < 3; i++) {
Thread thread = new MyThread();
thread.start();
}
}
}
运行结果: test开始.. test开始.. test开始.. test结束.. test结束.. test结束..
可以看出来,上面的程序起了三个线程,同时运行Sync类中的test()方法,虽然test()方法加上了synchronized,但是还是同时运行起来,貌似synchronized没起作用。 将test()方法上的synchronized去掉,在方法内部加上synchronized(this):
public void test() {
synchronized(this){
System.out.println("test开始..");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("test结束..");
}
}
运行结果: test开始.. test开始.. test开始.. test结束.. test结束.. test结束..
一切还是这么平静,没有看到synchronized起到作用。 实际上,synchronized(this)以及非static的synchronized方法(至于static synchronized方法请往下看),只能防止多个线程同时执行同一个对象的同步代码段。
回到本文的题目上:synchronized锁住的是代码还是对象。答案是:synchronized锁住的是括号里的对象,而不是代码。对于非static的synchronized方法,锁的就是对象本身也就是this。
当synchronized锁住一个对象后,别的线程如果也想拿到这个对象的锁,就必须等待这个线程执行完成释放锁,才能再次给对象加锁,这样才达到线程同步的目的。即使两个不同的代码段,都要锁同一个对象,那么这两个代码段也不能在多线程环境下同时运行。
所以我们在用synchronized关键字的时候,能缩小代码段的范围就尽量缩小,能在代码段上加同步就不要再整个方法上加同步。这叫减小锁的粒度,使代码更大程度的并发。原因是基于以上的思想,锁的代码段太长了,别的线程是不是要等很久。当然这段是题外话,与本文核心思想并无太大关联。
再看上面的代码,每个线程中都new了一个Sync类的对象,也就是产生了三个Sync对象,由于不是同一个对象,所以可以多线程同时运行synchronized方法或代码段。为了验证上述的观点,修改一下代码,让三个线程使用同一个Sync的对象。
class MyThread extends Thread {
private Sync sync;
public MyThread(Sync sync) {
this.sync = sync;
}
public void run() {
sync.test();
}
}
public class Main {
public static void main(String[] args) {
Sync sync = new Sync();
for (int i = 0; i < 3; i++) {
Thread thread = new MyThread(sync);
thread.start();
}
}
}
运行结果: test开始.. test结束.. test开始.. test结束.. test开始.. test结束..
可以看到,此时的synchronized就起了作用。 那么,如果真的想锁住这段代码,要怎么做?也就是,如果还是最开始的那段代码,每个线程new一个Sync对象,怎么才能让test方法不会被多线程执行。
解决也很简单,只要锁住同一个对象不就行了。例如,synchronized后的括号中锁同一个固定对象,这样就行了。这样是没问题,但是,比较多的做法是让synchronized锁这个类对应的Class对象。
class Sync {
public void test() {
synchronized (Sync.class) {
System.out.println("test开始..");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("test结束..");
}
}
}
class MyThread extends Thread {
public void run() {
Sync sync = new Sync();
sync.test();
}
}
public class Main {
public static void main(String[] args) {
for (int i = 0; i < 3; i++) {
Thread thread = new MyThread();
thread.start();
}
}
}
运行结果: test开始.. test结束.. test开始.. test结束.. test开始.. test结束..
上面代码用synchronized(Sync.class)实现了全局锁的效果。
static synchronized方法,static方法可以直接用类名调用,方法中无法使用this,所以它锁的不是this,而是类的Class对象,所以,static synchronized方法也相当于全局锁。
synchronized如果作用在一段代码上,那么是锁什么?
synchronized关键字。除了修饰方法之外,还可以修饰代码块,一共有以下5种用法。
(1)this
synchronized(this){
//互斥代码
}
这里的this指的是执行这段代码的对象,synchronized得到的锁就是this这个对象的锁。
(2)A.class
synchronized(A.class){
//互斥代码
}
这里A.class得到的是A这类,所以synchronized关键字得到的锁是类的锁,这种方法同下面的方法功能是相同的:
public static synchronized void fun(){
//互斥代码
}
所有需要类的锁的方法等不能同时执行,但是它和需要某个对象的锁的方法或者是不需要任何锁的方法可以同时执行。
(3)object.getClass()
synchronized(object.getClass){
//互斥代码
}
这种方法一般情况下同第二种是相同,但是出现继承和多态时,得到的结果却是不相同的。所以一般情况下推荐使用A.class的方式。
(4)object
synchronized(object){
//互斥代码
}
这里synchronized关键字拿到的锁是对象object的锁,所有需要这个对象的锁的方法都不能同时执行。
public class Trans {
private Object lock = new Object();
public void printNum(int num){
synchronized (lock) {
System.out.print(Thread.currentThread());
for(int i=0;i<25;i++){
System.out.print(i+" ");
}
System.out.println();
}
}
}
class MyThread implements Runnable {
private Trans trans;
private int num;
public MyThread(Trans trans, int num) {
this.trans = trans;
this.num = num;
}
public void run() {
while (true)
{
trans.printNum(num);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Test {
public static void main(String[] args) {
Trans t = new Trans();
Trans t1 = new Trans();
Thread a = new Thread(new MyThread(t, 1));
Thread b = new Thread(new MyThread(t1, 2));
a.start();
b.start();
}
}
在上边的例子中试图使用这种方法达到互斥方法打印方法,但是事实是这样做是没有效果的,因为每个Trans对象都有自己的Object对象,这两个对象都有自己的锁,所以两个线程需要的是不同锁,两个锁之间没有任何相互作用,所以不会起到互斥作用。
(5)static object
上边的代码稍作修改就可以起到互斥作用,将Trans类中Object对象的声明改为下面这样:
private static Object lock = new Object();
这样不同的类使用的就是同一个object对象,需要的锁也是同一个锁,就可以达到互斥的效果了。
总结:
synchronized关键字的用法,看似非常复杂,其实抓住要点之后还是很好区分的,只要看synchronized获得的是哪个对象或者类的锁就行啦,其他需要这个锁的方法都不能同时执行,不需要这个锁的方法都能同时执行。最后还要告别一个误区,相信大家都不会再犯这种错误了,synchronized锁住的是一个对象或者类(其实也是对象),而不是方法或者代码段。
volatile和synchronized讲一下?
synchronized保证了当有多个线程同时操作共享数据时,任何时刻只有一个线程能进入临界区操作共享数据,其他线程必须等待。因此它可以保证操作的原子性。synchronized通过同步锁保证线程安全,进入临界区前必须获得对象的锁,其他没有获得锁的线程不可进入。当临界区中的线程操作完毕后,它会释放锁,此时其他线程可以竞争锁,得到锁的那个线程便可以进入临界区。
synchronized还可以保证可见性。因为对一个变量的unlock操作之前,必须先把此变量同步回主内存中。它还可以保证有序性,因为一个变量在任何时刻只能有一个线程对其进行lock操作(也就是任何时刻只有一个线程可以获得该锁对象),这决定了持有同一把锁的两个同步块只能串行进入。
volatile是一个关键字,用于修饰变量。被其修饰的变量具有可见性和有序性。
可见性,当一条线程修改了这个变量的值,新值能被其他线程立刻观察到。具体来说,volatile的作用是:在本CPU对变量的修改直接写入主内存中,同时这个写操作使得其他CPU中对应变量的缓存行无效,这样其他线程在读取这个变量时候必须从主内存中读取,所以读取到的是最新的,这就是上面说得能被立即“看到”。
有序性,volatile可以禁止指令重排。volatile在其汇编代码中有一个lock操作,这个操作相当于一个内存屏障,指令重排不能越过内存屏障。具体来说在执行到volatile变量时,内存屏障之前的语句一定被执行过了且结果对后面是已知的,而内存屏障后面的语句一定还没执行到;在volatile变量之前的语句不能被重排后其之后,相反其后的语句也不能被重排到之前。
72、ReentrantLock
ReentrantLock 是一个可重入的互斥(/独占)锁,又称为“独占锁”。ReentrantLock通过自定义队列同步器(AQS-AbstractQueuedSychronized,是实现锁的关键)来实现锁的获取与释放。其可以完全替代 synchronized 关键字。JDK 5.0 早期版本,其性能远好于 synchronized,但 JDK 6.0 开始,JDK 对 synchronized 做了大量的优化,使得两者差距并不大。
“独占”,就是在同一时刻只能有一个线程获取到锁,而其它获取锁的线程只能处于同步队列中等待,只有获取锁的线程释放了锁,后继的线程才能够获取锁。
“可重入”,就是支持重进入的锁,它表示该锁能够支持一个线程对资源的重复加锁。
该锁还支持获取锁时的公平和非公平性选择。“公平”是指“不同的线程获取锁的机制是公平的”,而“不公平”是指“不同的线程获取锁的机制是非公平的”。
ReentrantLock 类实现了 Lock ,它拥有与 synchronized 相同的并发性和内存语义,但是添加了类似锁投票、定时锁等候和可中断锁等候的一些特性。此外,它还提供了在激烈争用情况下更佳的性能。(换句话说,当许多线程都想访问共享资源时,JVM 可以花更少的时候来调度线程,把更多时间用在执行线程上。)
reentrant 锁意味着什么呢?简单来说,它有一个与锁相关的获取计数器,如果拥有锁的某个线程再次得到锁,那么获取计数器就加1,然后锁需要被释放两次才能获得真正释放。这模仿了 synchronized 的语义,如果线程进入由线程已经拥有的监控器保护的 synchronized 块,就允许线程继续进行,当线程退出第二个(或者后续) synchronized 块的时候,不释放锁,只有线程退出它进入的监控器保护的第一个 synchronized 块时,才释放锁。
Lock 和 synchronized 有一点明显的区别 —— lock 必须在 finally 块中释放。否则,如果受保护的代码将抛出异常,锁就有可能永远得不到释放!这一点区别看起来可能没什么,但是实际上,它极为重要。忘记在 finally 块中释放锁,可能会在程序中留下一个定时炸弹,当有一天炸弹爆炸时,您要花费很大力气才有找到源头在哪。而使用同步,JVM 将确保锁会获得自动释放。
由于ReentrantLock是java.util.concurrent包下提供的一套互斥锁,相比Synchronized,ReentrantLock类提供了一些高级功能,主要有以下3项:
(1)等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当synchronized来说可以避免出现死锁的情况。
(2)公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,synchronized锁非公平锁,ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性能不是很好。
(3)锁绑定多个条件,一个ReentrantLock对象可以同时绑定对个对象。
ReenTrantLock实现的原理:
简单来说,ReenTrantLock的实现是一种自旋锁,通过循环调用CAS操作来实现加锁。它的性能比较好也是因为避免了使线程进入内核态的阻塞状态。想尽办法避免线程进入内核的阻塞状态是我们去分析和理解锁设计的关键钥匙。
什么时候选择用 ReentrantLock 代替 synchronized
既然如此,我们什么时候才应该使用 ReentrantLock 呢?答案非常简单 —— 在确实需要一些 synchronized 所没有的特性的时候,比如时间锁等候、可中断锁等候、无块结构锁、多个条件变量或者锁投票。 ReentrantLock 还具有可伸缩性的好处,应当在高度争用的情况下使用它,但是请记住,大多数 synchronized 块几乎从来没有出现过争用,所以可以把高度争用放在一边。我建议用 synchronized 开发,直到确实证明 synchronized 不合适,而不要仅仅是假设如果使用 ReentrantLock “性能会更好”。请记住,这些是供高级用户使用的高级工具。(而且,真正的高级用户喜欢选择能够找到的最简单工具,直到他们认为简单的工具不适用为止。)。一如既往,首先要把事情做好,然后再考虑是不是有必要做得更快。
73、synchronized 与 ReentrantLock
相似点:
(1)synchronized 与 ReentrantLock关键字一样,属于互斥锁。所谓互斥锁, 指的是一次最多只能有一个线程持有的锁。这两种同步方式有很多相似之处,它们都是加锁方式同步,而且都是阻塞式的同步,也就是说当如果一个线程获得了对象锁,进入了同步块,其他访问该同步块的线程都必须阻塞在同步块外面等待。
(2)从名字上理解,ReenTrantLock的字面意思就是再进入的锁,其实synchronized关键字所使用的锁也是可重入的,两者关于这个的区别不大。两者都是同一个线程每进入一次,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
区别:
(1)锁的实现:
synchronized是依赖于JVM实现的,而ReentrantLock是JDK实现的,有什么区别,说白了就类似于操作系统来控制实现和用户自己敲代码实现的区别。前者的实现是比较难见到的,后者有直接的源码可供阅读。
synchronized是在JVM层面上实现的,不但可以通过一些监控工具监控synchronized的锁定,而且在代码执行时出现异常,JVM会自动释放锁定,但是使用Lock则不行,lock是通过代码实现的,要保证锁定一定会被释放,就必须将unLock()放到finally{}中。
(2)等待可中断:
ReenTrantLock提供了一种能够中断等待锁的线程的机制,通过lock.lockInterruptibly()来实现这个机制。等待可中断,即持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于synchronized来说可以避免出现死锁的情况。
具体来说,假如业务代码中有两个线程,Thread1 Thread2。假设 Thread1 获取了对象object的锁,Thread2将等待Thread1释放object的锁。
使用synchronized。如果Thread1不释放,Thread2将一直等待,不能被中断。synchronized也可以说是Java提供的原子性内置锁机制。内部锁扮演了互斥锁(mutual exclusion lock ,mutex)的角色,一个线程引用锁的时候,别的线程阻塞等待。
使用ReentrantLock。如果Thread1不释放,Thread2等待了很长时间以后,可以中断等待,转而去做别的事情。
(3)公平锁:
ReenTrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。
公平锁是指多个线程在等待同一个锁时,必须按照申请的时间顺序来依次获得锁;而非公平锁则不能保证这一点。非公平锁在锁被释放时,任何一个等待锁的线程都有机会获得锁。 synchronized的锁是非公平锁,ReentrantLock默认情况下也是非公平锁,但可以通过带布尔值的构造函数要求使用公平锁。
(4)绑定多个条件
ReentrantLock可以同时绑定多个Condition对象,只需多次调用newCondition方法即可。 synchronized中,锁对象的wait()和notify()或notifyAll()方法可以实现一个隐含的条件。但如果要和多于一个的条件关联的时候,就不得不额外添加一个锁。
(5)唤醒指定线程
ReenTrantLock提供了一个Condition(条件)类,用来实现分组唤醒需要唤醒的线程们,而不是像synchronized要么随机唤醒一个线程要么唤醒全部线程。
(6)性能的区别:
在synchronized优化以前,synchronized的性能是比ReenTrantLock差很多的,但是自从synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者的性能就差不多了,在两种方法都可用的情况下,官方甚至建议使用synchronized,其实synchronized的优化我感觉就借鉴了ReenTrantLock中的CAS技术。都是试图在用户态就把加锁问题解决,避免进入内核态的线程阻塞。
synchronized和重入锁的区别?
synchronized是JVM的内置锁,而重入锁是Java代码实现的。重入锁是synchronized的扩展,可以完全代替后者。重入锁可以重入,允许同一个线程连续多次获得同一把锁。其次,重入锁独有的功能有:
- 可以响应中断,synchronized要么获得锁执行,要么保持等待。而重入锁可以响应中断,使得线程在迟迟得不到锁的情况下,可以不再等待。主要由
lockInterruptibly()实现,这是一个可以对中断进行响应的锁申请动作,锁中断可以避免死锁。 - 锁的申请可以有等待时限,用
tryLock()可以实现限时等待,如果超时还未获得锁会返回false,也防止了线程迟迟得不到锁时一直等待,可避免死锁。 - 公平锁,即锁的获得按照线程先来后到的顺序依次获得,不会产生饥饿现象。synchronized的锁默认是不公平的,重入锁可通过传入构造方法的参数实现公平锁。
- 重入锁可以绑定多个Condition条件,这些condition通过调用await/singal实现线程间通信。
74、为什么要使用线程池?
假设一个服务器完成一项任务所需时间为:t1 创建线程时间,t2 在线程中执行任务的时间,t3 销毁线程时间,那么线程运行的总时间 T= t1+t2+t3。假如,有些业务逻辑需要频繁的使用线程执行某些简单的任务,那么很多时间都会浪费t1和t3上。为了避免这种问题,JAVA提供了线程池。在线程池中的线程可以复用,当线程运行完任务之后,不被销毁,而是可以继续执行其他的任务。
相对来说,使用线程池,会预创建一些线程,它们不断的从工作队列中取出任务,然后执行该任务。当工作线程执行完一个任务后,就会继续执行工作队列中的另一个任务。优点如下:
- 减少了创建和销毁的次数,每个工作线程都可以一直被重用,能执行多个任务。
- 可以根据系统的承载能力,方便的调整线程池中线程的数目,防止因为消耗过量的系统资源而导致系统崩溃。
在Java中,如果每当一个请求到达就创建一个新线程,开销是相当大的。在实际使用中,每个请求创建新线程的服务器在创建和销毁线程上花费的时间和消耗的系统资源,甚至可能要比花在处理实际的用户请求的时间和资源要多得多。除了创建和销毁线程的开销之外,活动的线程也需要消耗系统资源。如果在一个JVM里创建太多的线程,可能会导致系统由于过度消耗内存或“切换过度”而导致系统资源不足。为了防止资源不足,服务器应用程序需要一些办法来限制任何给定时刻处理的请求数目,尽可能减少创建和销毁线程的次数,特别是一些资源耗费比较大的线程的创建和销毁,尽量利用已有对象来进行服务,这就是“池化资源”技术产生的原因。
线程池主要用来解决线程生命周期开销问题和资源不足问题。通过对多个任务重用线程,线程创建的开销就被分摊到了多个任务上了,而且由于在请求到达时线程已经存在,所以消除了线程创建所带来的延迟。这样,就可以立即为请求服务,使应用程序响应更快。另外,通过适当地调整线程池中的线程数目可以防止出现资源不足的情况。
线程池适合应用的场合
当一个Web服务器接受到大量短小线程的请求时,使用线程池技术是非常合适的,它可以大大减少线程的创建和销毁次数,提高服务器的工作效率。但如果线程要求的运行时间比较长,此时线程的运行时间比创建时间要长得多,单靠减少创建时间对系统效率的提高不明显,此时就不适合应用线程池技术,需要借助其它的技术来提高服务器的服务效率。
75、使用线程池的好处
(1)、降低资源消耗
可以重复利用已创建的线程降低线程创建和销毁造成的消耗。
(2)、提高响应速度
当任务到达时,任务可以不需要等到线程创建就能立即执行。
(3)、提高线程的可管理性
线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。
线程池的核心参数
线程池的核心实现即 ThreadPoolExecutor 类。该类包含了几个核心属性,这些属性在可在构造方法进行初始化。在介绍核心属性前,我们先来看看 ThreadPoolExecutor 的构造方法,如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
如上所示,构造方法的参数即核心参数,这里我用一个表格来简要说明一下各个参数的意义。如下:
| 参数 | 说明 |
|---|---|
| corePoolSize | 核心线程数。当线程数小于该值时,线程池会优先创建新线程来执行新任务 |
| maximumPoolSize | 线程池所能维护的最大线程数 |
| keepAliveTime | 空闲线程的存活时间 |
| workQueue | 任务队列,用于缓存未执行的任务 |
| threadFactory | 线程工厂。可通过工厂为新建的线程设置更有意义的名字 |
| handler | 拒绝策略。当线程池和任务队列均处于饱和状态时,使用拒绝策略处理新任务。默认是 AbortPolicy,即直接抛出异常 |
76、线程池的任务处理策略
- 如果当前线程池中的线程数目小于corePoolSize(核心池大小),则每来一个任务,就会创建一个线程去执行这个任务;
- 如果当前线程池中的线程数目>=corePoolSize,则每来一个任务,会尝试将其添加到任务缓存队列当中,若添加成功,则该任务会等待空闲线程将其取出去执行;若添加失败(一般来说是任务缓存队列已满),则会尝试创建新的线程去执行这个任务;
- 如果当前线程池中的线程数目达到maximumPoolSize(线程池最大线程数),则会采取任务拒绝策略进行处理;
- 如果线程池中的线程数量大于 corePoolSize时,如果某线程空闲时间超过keepAliveTime(表示线程没有任务执行时最多保持多久时间会终止),线程将被终止,直至线程池中的线程数目不大于corePoolSize;如果允许为核心池中的线程设置存活时间,那么核心池中的线程空闲时间超过keepAliveTime,线程也会被终止。
简化一下上面的规则:
| 序号 | 条件 | 动作 |
|---|---|---|
| 1 | 线程数 < corePoolSize | 创建新线程 |
| 2 | 线程数 ≥ corePoolSize,且 workQueue 未满 | 缓存新任务 |
| 3 | corePoolSize ≤ 线程数 < maximumPoolSize,且 workQueue 已满 | 创建新线程 |
| 4 | 线程数 ≥ maximumPoolSize,且 workQueue 已满 | 使用拒绝策略处理 |
流程图:
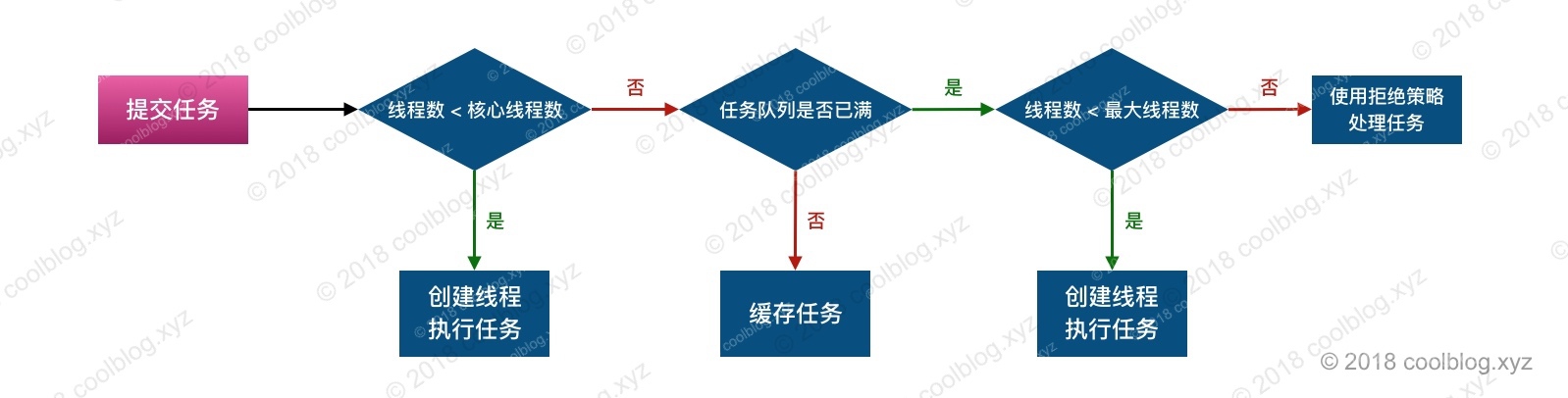
排队策略
如线程创建规则中所说,当线程数量大于等于 corePoolSize,workQueue 未满时,则缓存新任务。这里要考虑使用什么类型的容器缓存新任务,通过 JDK 文档介绍,我们可知道有3中类型的容器可供使用,分别是同步队列,有界队列和无界队列。对于有优先级的任务,这里还可以增加优先级队列。以上所介绍的4中类型的队列,对应的实现类如下:
| 实现类 | 类型 | 说明 |
|---|---|---|
| SynchronousQueue | 同步队列 | 该队列不存储元素,每个插入操作必须等待另一个线程调用移除操作,否则插入操作会一直阻塞 |
| ArrayBlockingQueue | 有界队列 | 基于数组的阻塞队列,按照 FIFO 原则对元素进行排序 |
| LinkedBlockingQueue | 无界队列 | 基于链表的阻塞队列,按照 FIFO 原则对元素进行排序 |
| PriorityBlockingQueue | 优先级队列 | 具有优先级的阻塞队列 |
拒绝策略
如线程创建规则中所说,线程数量大于等于 maximumPoolSize,且 workQueue 已满,则使用拒绝策略处理新任务。Java 线程池提供了4中拒绝策略实现类,如下:
| 实现类 | 说明 |
|---|---|
| AbortPolicy | 丢弃新任务,并抛出 RejectedExecutionException |
| DiscardPolicy | 不做任何操作,直接丢弃新任务 |
| DiscardOldestPolicy | 丢弃队列队首的元素,并执行新任务 |
| CallerRunsPolicy | 由调用线程执行新任务 |
以上4个拒绝策略中,AbortPolicy 是线程池实现类所使用的策略。我们也可以通过方法
public void setRejectedExecutionHandler(RejectedExecutionHandler)
修改线程池决绝策略。
几种常用的线程池
(1)、FixedThreadPool - 线程池大小固定,任务队列无界
下面是 Executors 类 newFixedThreadPool 方法的源码:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
可以看到 corePoolSize 和 maximumPoolSize 设置成了相同的值,此时不存在线程数量大于核心线程数量的情况,所以KeepAlive时间设置不会生效。任务队列使用的是不限制大小的 LinkedBlockingQueue ,由于是无界队列所以容纳的任务数量没有上限,因此,FixedThreadPool的行为如下:
1)从线程池中获取可用线程执行任务,如果没有可用线程则使用ThreadFactory创建新的线程,直到线程数达到nThreads。
2)线程池线程数达到nThreads以后,新的任务将被放入队列。
FixedThreadPool的优点是能够保证所有的任务都被执行,永远不会拒绝新的任务;同时缺点是队列数量没有限制,在任务执行时间无限延长的这种极端情况下会造成内存问题。
(2)、SingleThreadExecutor - 线程池大小固定为1,任务队列无界
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
这个工厂方法中使用无界LinkedBlockingQueue,并且将线程数设置成1,除此以外还使用FinalizableDelegatedExecutorService类进行了包装。这个包装类的主要目的是为了屏蔽ThreadPoolExecutor中动态修改线程数量的功能,仅保留ExecutorService中提供的方法。虽然是单线程处理,一旦线程因为处理异常等原因终止的时候,ThreadPoolExecutor会自动创建一个新的线程继续进行工作。
SingleThreadExecutor 适用于在逻辑上需要单线程处理任务的场景,同时无界的LinkedBlockingQueue保证新任务都能够放入队列,不会被拒绝;缺点和FixedThreadPool相同,当处理任务无限等待的时候会造成内存问题。
(3)、CachedThreadPool - 线程池无限大(MAX INT),等待队列长度为1
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
SynchronousQueue是一个只有1个元素的队列,入队的任务需要一直等待直到队列中的元素被移出。核心线程数是0,意味着所有任务会先入队列;最大线程数是Integer.MAX_VALUE,可以认为线程数量是没有限制的。KeepAlive时间被设置成60秒,意味着在没有任务的时候线程等待60秒以后退出。CachedThreadPool对任务的处理策略是提交的任务会立即分配一个线程进行执行,线程池中线程数量会随着任务数的变化自动扩张和缩减,在任务执行时间无限延长的极端情况下会创建过多的线程。
三种ExecutorService特性总结
|
类型 |
核心线程数 |
最大线程数 |
Keep Alive 时间 |
任务队列 |
任务处理策略 |
|---|---|---|---|---|---|
| FixedThreadPool | 固定大小 | 固定大小(与核心线程数相同) | 0 | LinkedBlockingQueue | 线程池大小固定,没有可用线程的时候任务会放入队列等待,队列长度无限制 |
| SingleThreadExecutor | 1 | 1 | 0 | LinkedBlockingQueue | 与 FixedThreadPool 相同,区别在于线程池的大小为1,适用于业务逻辑上只允许1个线程进行处理的场景 |
| CachedThreadPool | 0 | Integer.MAX_VALUE | 1分钟 | SynchronousQueue | 线程池的数量无限大,新任务会直接分配或者创建一个线程进行执行 |
总结:
1. newSingleThreadExecutor
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
2.newFixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
3. newCachedThreadPool
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,
那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
4.newScheduledThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
线程池的种类,区别和使用场景
newCachedThreadPool:
- 底层:返回ThreadPoolExecutor实例,corePoolSize为0;maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为60L;unit为TimeUnit.SECONDS;workQueue为SynchronousQueue(同步队列)
- 通俗:当有新任务到来,则插入到SynchronousQueue中,由于SynchronousQueue是同步队列,因此会在池中寻找可用线程来执行,若有可用线程则执行,若没有可用线程则创建一个线程来执行该任务;若池中线程空闲时间超过指定大小,则该线程会被销毁。
- 适用:执行很多短期异步的小程序或者负载较轻的服务器
newFixedThreadPool:
- 底层:返回ThreadPoolExecutor实例,接收参数为所设定线程数量nThread,corePoolSize为nThread,maximumPoolSize为nThread;keepAliveTime为0L(不限时);unit为:TimeUnit.MILLISECONDS;WorkQueue为:new LinkedBlockingQueue<Runnable>() 无解阻塞队列
- 通俗:创建可容纳固定数量线程的池子,每个线程的存活时间是无限的,当池子满了就不在添加线程了;如果池中的所有线程均在繁忙状态,对于新任务会进入阻塞队列中(无界的阻塞队列)
- 适用:执行长期的任务,性能好很多
newSingleThreadExecutor:
- 底层:FinalizableDelegatedExecutorService包装的ThreadPoolExecutor实例,corePoolSize为1;maximumPoolSize为1;keepAliveTime为0L;unit为:TimeUnit.MILLISECONDS;workQueue为:new LinkedBlockingQueue<Runnable>() 无解阻塞队列
- 通俗:创建只有一个线程的线程池,且线程的存活时间是无限的;当该线程正繁忙时,对于新任务会进入阻塞队列中(无界的阻塞队列)
- 适用:一个任务一个任务执行的场景
NewScheduledThreadPool:
- 底层:创建ScheduledThreadPoolExecutor实例,corePoolSize为传递来的参数,maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为0;unit为:TimeUnit.NANOSECONDS;workQueue为:new DelayedWorkQueue() 一个按超时时间升序排序的队列
- 通俗:创建一个固定大小的线程池,线程池内线程存活时间无限制,线程池可以支持定时及周期性任务执行,如果所有线程均处于繁忙状态,对于新任务会进入DelayedWorkQueue队列中,这是一种按照超时时间排序的队列结构
- 适用:周期性执行任务的场景
备注:
一般如果线程池任务队列采用LinkedBlockingQueue队列的话,那么不会拒绝任何任务(因为队列大小没有限制),这种情况下,ThreadPoolExecutor最多仅会按照最小线程数来创建线程,也就是说线程池大小被忽略了。
如果线程池任务队列采用ArrayBlockingQueue队列的话,那么ThreadPoolExecutor将会采取一个非常负责的算法,比如假定线程池的最小线程数为4,最大为8所用的ArrayBlockingQueue最大为10。随着任务到达并被放到队列中,线程池中最多运行4个线程(即最小线程数)。即使队列完全填满,也就是说有10个处于等待状态的任务,ThreadPoolExecutor也只会利用4个线程。如果队列已满,而又有新任务进来,此时才会启动一个新线程,这里不会因为队列已满而拒接该任务,相反会启动一个新线程。新线程会运行队列中的第一个任务,为新来的任务腾出空间。
这个算法背后的理念是:该池大部分时间仅使用核心线程(4个),即使有适量的任务在队列中等待运行。这时线程池就可以用作节流阀。如果挤压的请求变得非常多,这时该池就会尝试运行更多的线程来清理;这时第二个节流阀—最大线程数就起作用了。
Java阻塞队列
队列以一种先进先出的方式管理数据,阻塞队列(BlockingQueue)是一个支持两个附加操作的队列,这两个附加的操作是:当从队列中获取或者移除元素时,如果队列为空,需要等待,直到队列不为空;同时如果向队列中添加元素时,此时如果队列无可用空间,也需要等待。在多线程进行合作时,阻塞队列是很有用的工具。
生产者-消费者模式:阻塞队列常用于生产者和消费者的场景,生产者线程可以定期的把中间结果存到阻塞队列中,而消费者线程把中间结果取出并在将来修改它们。队列会自动平衡负载,如果生产者线程集运行的比消费者线程集慢,则消费者线程集在等待结果时就会阻塞;如果生产者线程集运行的快,那么它将等待消费者线程集赶上来。
Java中的阻塞队列
(1)ArrayBlockingQueue:基于数组的FIFO队列,是有界的,创建时必须指定大小
(2)LinkedBlockingQueue: 基于链表的FIFO队列,是无界的,默认大小是 Integer.MAX_VALUE
(3)synchronousQueue:一个比较特殊的队列,虽然它是无界的,但它不会保存任务,每一个新增任务的线程必须等待另一个线程取出任务(即在某次添加任务后必须等待其他线程取走后才能继续添加),也可以把它看成容量为0的队列。
总结:
ArrayBlockingQueue: 基于数组的阻塞队列,在内部维护了一个定长数组,以便缓存队列中的数据对象。并没有实现读写分离,也就意味着生产和消费不能完全并行。是一个有界队列。
LinkedBlockingQueue:基于列表的阻塞队列,在内部维护了一个数据缓冲队列(由一个链表构成),实现采用分离锁(读写分离两个锁),从而实现生产者和消费者操作的完全并行运行。是一个无界队列。 LinkedBlockingQueue之所以能够高效的处理并发数据,是因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
SynchronousQueue: 没有缓存的队列,生存者生产的数据直接会被消费者获取并消费。若没有数据就直接调用出栈方法则会报错。
三种队列使用场景
newFixedThreadPool 线程池采用的队列是LinkedBlockingQueue。其优点是无界可缓存,内部实现读写分离,并发的处理能力高于ArrayBlockingQueue。
newCachedThreadPool 线程池采用的队列是SynchronousQueue。其优点就是无缓存,接收到的任务均可直接处理,再次强调,慎用!
并发量不大,服务器性能较好,可以考虑使用SynchronousQueue。并发量较大,服务器性能较好,可以考虑使用LinkedBlockingQueue。并发量很大,服务器性能无法满足,可以考虑使用ArrayBlockingQueue。系统的稳定最重要。
任务队列主要有ArrayBlockingQueue有界队列、LinkedBlockingQueue无界队列、SynchronousQueue直接提交队列。
使用ArrayBlockingQueue,当线程池中实际线程数小于核心线程数时,直接创建线程执行任务;当大于核心线程数而小于最大线程数时,提交到任务队列中;因为这个队列是有界的,当队列满时,在不大于最大线程的前提下,创建线程执行任务;若大于最大线程数,执行拒绝策略。
使用LinkedBlockingQueue时,当线程池中实际线程数小于核心线程数时,直接创建线程执行任务;当大于核心线程数而小于最大线程数时,提交到任务队列中;因为这个队列是有无界的,所以之后提交的任务都会进入任务队列中。newFixedThreadPool就采用了无界队列,同时指定核心线程和最大线程数一样。
使用SynchronousQueue时,该队列没有容量,对提交任务的不做保存,直接增加新线程来执行任务。newCachedThreadPool使用的是直接提交队列,核心线程数是0,最大线程数是整型的最大值,keepAliveTime是60s,因此当新任务提交时,若没有空闲线程都是新增线程来执行任务,不过由于核心线程数是0,当60s就会回收空闲线程。
当线程池中的线程达到最大线程数时,就要开始执行拒绝策略了。有如下几种
- 直接抛出异常
- 在调用者的线程中,运行当前任务
- 丢弃最老的一个请求,也就是将队列头的任务poll出去
- 默默丢弃无法处理的任务,不做任何处理
77、ThreadLocal总结
(1)ThreadLocal大概的意思有两点:
1)、ThreadLocal提供了一种访问某个变量的特殊方式:访问到的变量属于当前线程,即保证每个线程的变量不一样,而同一个线程在任何地方拿到的变量都是一致的,这就是所谓的线程隔离。
2)、如果要使用ThreadLocal,通常定义为private static类型,在我看来最好是定义为private static final类型。
(2)ThreadLocal可以总结为一句话:ThreadLocal的作用是提供线程内的局部变量,这种变量在线程的生命周期内起作用,减少同一个线程内多个函数或者组件之间一些公共变量的传递的复杂度。
(3)ThreadLocal 的实现思想,即每个线程维护一个 ThreadLocalMap 的映射表,映射表的 key 是 ThreadLocal 实例本身,value 是要存储的副本变量。ThreadLocal 实例本身并不存储值,它只是提供一个在当前线程中找到副本值的 key。
(4)线程隔离的秘密,就在于ThreadLocalMap这个类。ThreadLocalMap是ThreadLocal类的一个静态内部类,它实现了键值对的设置和获取(对比Map对象来理解),每个线程中都有一个独立的ThreadLocalMap副本,它所存储的值,只能被当前线程读取和修改。ThreadLocal类通过操作每一个线程特有的ThreadLocalMap副本,从而实现了变量访问在不同线程中的隔离。因为每个线程的变量都是自己特有的,完全不会有并发错误。还有一点就是,ThreadLocalMap存储的键值对中的键是this对象指向的ThreadLocal对象,而值就是你所设置的对象了。
(5)ThreadLocalMap并不是为了解决线程安全问题,而是提供了一种将实例绑定到当前线程的机制,类似于隔离的效果,实际上自己在方法中new出来变量也能达到类似的效果。ThreadLocalMap跟线程安全基本不搭边,绑定上去的实例也不是多线程公用的,而是每个线程new一份,这个实例肯定不是共用的,如果共用了,那就会引发线程安全问题。ThreadLocalMap最大的用处就是用来把实例变量共享成全局变量,在程序的任何方法中都可以访问到该实例变量而已。网上很多人说ThreadLocalMap是解决了线程安全问题,其实是望文生义,两者不是同类问题。
(6)ThreadLocal对象通常用于防止对可变的单实例变量或全局变量进行共享。当你想在多个方法中使用某个变量,这个变量是当前线程的状态,其它线程不依赖这个变量,你第一时间想到的就是把变量定义在方法内部,然后再方法之间传递参数来使用,这个方法能解决问题,但是有个烦人的地方就是,每个方法都需要声明形参,多处声明,多处调用。影响代码的美观和维护。有没有一种方法能将变量像private static形式来访问呢?这样在类的任何一处地方就都能使用。这个时候ThreadLocal大显身手了。
ThreadLocal的主要应用场景为多线程多实例(每个线程对应一个实例)的对象的访问,并且这个对象很多地方都要用到。例如:同一个网站登录用户,每个用户服务器会为其开一个线程,每个线程中创建一个ThreadLocal,里面存用户基本信息等,在很多页面跳转时,会显示用户信息或者得到用户的一些信息等频繁操作,这样多线程之间并没有联系而且当前线程也可以及时获取想要的数据。
(7)ThreadLocal 与 synchronized 的对比
1)ThreadLocal和synchonized都用于解决多线程并发访问。但是ThreadLocal与synchronized有本质的区别。synchronized是利用锁的机制,使变量或代码块在某一时该只能被一个线程访问。而ThreadLocal为每一个线程都提供了变量的副本,使得每个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享。而synchronized却正好相反,它用于在多个线程间通信时能够获得数据共享。
synchronized采取的是“以时间换空间”的策略,本质上是对关键资源上锁,让大家排队操作。而ThreadLocal采取的是“以空间换时间”的思路,为每个使用该变量的线程提供独立的变量副本,在本线程内部,它相当于一个“全局变量”,可以保证本线程任何时间操纵的都是同一个对象。
2)synchronized用于线程间的数据共享,而ThreadLocal则用于线程间的数据隔离。
每个Thread线程内部都有一个Map,Tread类的ThreadLocal.ThreadLocalMap属性。Map里面存储线程本地对象(key也就是当前的ThreadLoacal对象)和线程的变量副本(value)。Thread内部的Map是由ThreadLocal维护的,由ThreadLocal负责向map获取和设置线程的变量值。
数据结构:
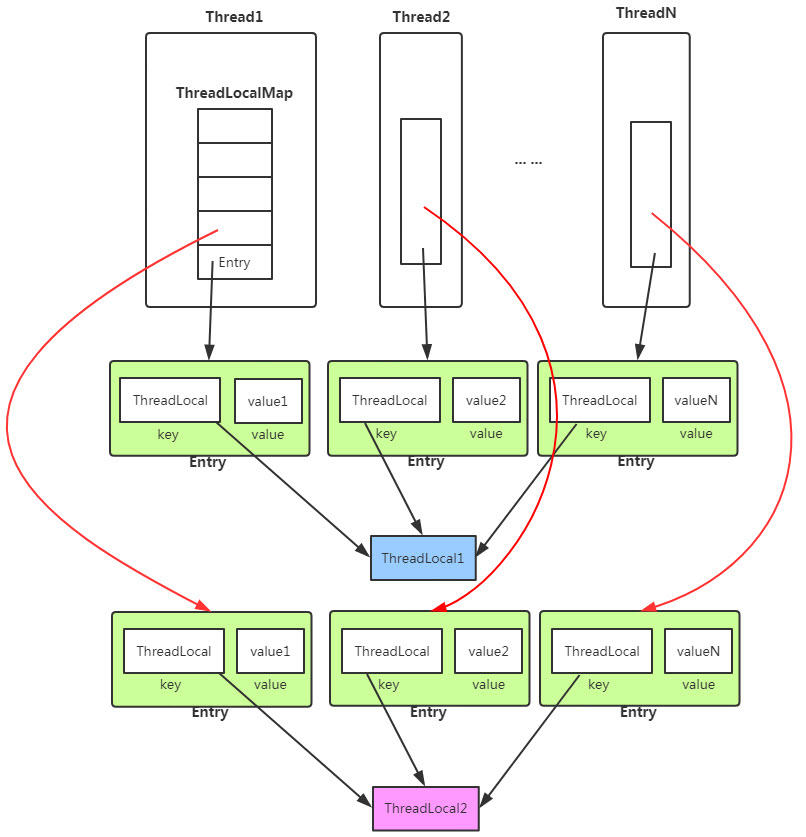
ThreadLocal核心方法:
- get():返回此线程局部变量的当前线程副本中的值。
- initialValue():返回此线程局部变量的当前线程的“初始值”。
- remove():移除此线程局部变量当前线程的值。
- set(T value):将此线程局部变量的当前线程副本中的值设置为指定值。
内部类 ThreadLocalMap:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
Entry继承自WeakReference(弱引用,生命周期只能存活到下次GC前),但只有Key是弱引用类型的,Value并非弱引用。
set和get的实现:
// set方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
// 上面的getMap方法
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
// get方法
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
从源码中可以看出:每一个线程拥有一个ThreadLocalMap,这个map存储了该线程拥有的所有局部变量。
set时先通过Thread.currentThread()获取当前线程,进而获取到当前线程的ThreadLocalMap,然后以ThreadLocal自己为key,要存储的对象为值,存到当前线程的ThreadLocalMap中。
get时也是先获得当前线程的ThreadLocalMap,以ThreadLocal自己为key,取出和该线程的局部变量。
内存泄漏问题:
ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用来引用它,那么系统 GC 的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value永远无法回收,造成内存泄漏。
其实,ThreadLocalMap的设计中已经考虑到这种情况,也加上了一些防护措施:在ThreadLocal的get(),set(),remove()的时候都会清除线程ThreadLocalMap里所有key为null的value。
但是这些被动的预防措施并不能保证不会内存泄漏:
使用static的ThreadLocal,延长了ThreadLocal的生命周期,可能导致的内存泄漏。
分配使用了ThreadLocal又不再调用get(),set(),remove()方法,那么就会导致内存泄漏。
解决:
每次使用完ThreadLocal,都调用它的remove()方法,清除数据。
在使用线程池的情况下,没有及时清理ThreadLocal,不仅是内存泄漏的问题,更严重的是可能导致业务逻辑出现问题。所以,使用ThreadLocal就跟加锁完要解锁一样,用完就清理。
在上面提到过,每个thread中都存在一个map, map的类型是ThreadLocal.ThreadLocalMap. Map中的key为一个threadlocal实例. 这个Map的确使用了弱引用,不过弱引用只是针对key. 每个key都弱引用指向threadlocal. 当把threadlocal实例置为null以后,没有任何强引用指向threadlocal实例,所以threadlocal将会被gc回收. 但是,我们的value却不能回收,因为存在一条从current thread连接过来的强引用. 只有当前thread结束以后, current thread就不会存在栈中,强引用断开, Current Thread, Map, value将全部被GC回收.
所以得出一个结论就是只要这个线程对象被gc回收,就不会出现内存泄露,但在threadLocal设为null和线程结束这段时间不会被回收的,就发生了我们认为的内存泄露。其实这是一个对概念理解的不一致,也没什么好争论的。最要命的是线程对象不被回收的情况,这就发生了真正意义上的内存泄露。比如使用线程池的时候,线程结束是不会销毁的,会再次使用的。就可能出现内存泄露。
Runnable 与 Callable的区别
(1)Runnable是自从java1.1就有了,而Callable是1.5之后才加上去的。
(2)Callable规定的方法是call(),Runnable规定的方法是run()。
(3)Callable的任务执行后可返回值,而Runnable的任务是不能返回值(是void),这是核心区别。
(4)call方法可以抛出异常,run方法不可以。
(5)运行Callable任务可以拿到一个Future对象,表示异步计算的结果。它提供了检查计算是否完成的方法,以等待计算的完成,并检索计算的结果。通过Future对象可以了解任务执行情况,可取消任务的执行,还可获取执行结果。
(6)加入线程池运行,Runnable使用ExecutorService的execute方法,Callable使用submit方法。
注意点:
Callable接口支持返回执行结果,此时需要调用FutureTask.get()方法实现,此方法会阻塞主线程直到获取到结果;当不调用此方法时,主线程不会阻塞!
死锁
所谓死锁是指多个线程因竞争资源而造成的一种僵局(互相等待),若无外力作用,这些进程都将无法向前推进。
所谓死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
下面我们通过一些实例来说明死锁现象。
先看生活中的一个实例,两个人面对面过独木桥,甲和乙都已经在桥上走了一段距离,即占用了桥的资源,甲如果想通过独木桥的话,乙必须退出桥面让出桥的资源,让甲通过,但是乙不服,为什么让我先退出去,我还想先过去呢,于是就僵持不下,导致谁也过不了桥,这就是死锁。
死锁产生的原因
1、系统资源的竞争
通常系统中拥有的不可剥夺资源,其数量不足以满足多个进程运行的需要,使得进程在运行过程中,会因争夺资源而陷入僵局,如磁带机、打印机等。只有对不可剥夺资源的竞争才可能产生死锁,对可剥夺资源的竞争是不会引起死锁的。
2、进程推进顺序非法
进程在运行过程中,请求和释放资源的顺序不当,也同样会导致死锁。例如,并发进程 P1、P2分别保持了资源R1、R2,而进程P1申请资源R2,进程P2申请资源R1时,两者都会因为所需资源被占用而阻塞。
Java中死锁最简单的情况是,一个线程T1持有锁L1并且申请获得锁L2,而另一个线程T2持有锁L2并且申请获得锁L1,因为默认的锁申请操作都是阻塞的,所以线程T1和T2永远被阻塞了。导致了死锁。这是最容易理解也是最简单的死锁的形式。但是实际环境中的死锁往往比这个复杂的多。可能会有多个线程形成了一个死锁的环路,比如:线程T1持有锁L1并且申请获得锁L2,而线程T2持有锁L2并且申请获得锁L3,而线程T3持有锁L3并且申请获得锁L1,这样导致了一个锁依赖的环路:T1依赖T2的锁L2,T2依赖T3的锁L3,而T3依赖T1的锁L1。从而导致了死锁。
从上面两个例子中,我们可以得出结论,产生死锁可能性的最根本原因是:线程在获得一个锁L1的情况下再去申请另外一个锁L2,也就是锁L1想要包含了锁L2,也就是说在获得了锁L1,并且没有释放锁L1的情况下,又去申请获得锁L2,这个是产生死锁的最根本原因。另一个原因是默认的锁申请操作是阻塞的。
死锁产生的必要条件
产生死锁必须同时满足以下四个条件,只要其中任一条件不成立,死锁就不会发生。
(1)互斥条件:一个资源每次只能被一个进程使用。独木桥每次只能通过一个人。
(2)请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。乙不退出桥面,甲也不退出桥面。
(3)不剥夺条件: 进程已获得的资源,在未使用完之前,不能强行剥夺。甲不能强制乙退出桥面,乙也不能强制甲退出桥面。
(4)循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。如果乙不退出桥面,甲不能通过,甲不退出桥面,乙不能通过。
死锁例子
package com.demo.test;
/**
* 一个简单的死锁类
* t1先运行,这个时候flag==true,先锁定obj1,然后睡眠1秒钟
* 而t1在睡眠的时候,另一个线程t2启动,flag==false,先锁定obj2,然后也睡眠1秒钟
* t1睡眠结束后需要锁定obj2才能继续执行,而此时obj2已被t2锁定
* t2睡眠结束后需要锁定obj1才能继续执行,而此时obj1已被t1锁定
* t1、t2相互等待,都需要得到对方锁定的资源才能继续执行,从而死锁。
*/
public class DeadLock implements Runnable{
private static Object obj1 = new Object();
private static Object obj2 = new Object();
private boolean flag;
public DeadLock(boolean flag){
this.flag = flag;
}
@Override
public void run(){
System.out.println(Thread.currentThread().getName() + "运行");
if(flag){
synchronized(obj1){
System.out.println(Thread.currentThread().getName() + "已经锁住obj1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized(obj2){
// 执行不到这里
System.out.println("1秒钟后,"+Thread.currentThread().getName()
+ "锁住obj2");
}
}
}else{
synchronized(obj2){
System.out.println(Thread.currentThread().getName() + "已经锁住obj2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized(obj1){
// 执行不到这里
System.out.println("1秒钟后,"+Thread.currentThread().getName()
+ "锁住obj1");
}
}
}
}
}
package com.demo.test;
public class DeadLockTest {
public static void main(String[] args) {
Thread t1 = new Thread(new DeadLock(true), "线程1");
Thread t2 = new Thread(new DeadLock(false), "线程2");
t1.start();
t2.start();
}
}
运行结果:
线程1运行 线程1已经锁住obj1 线程2运行 线程2已经锁住obj2
线程1锁住了obj1(甲占有桥的一部分资源),线程2锁住了obj2(乙占有桥的一部分资源),线程1企图锁住obj2(甲让乙退出桥面,乙不从),进入阻塞,线程2企图锁住obj1(乙让甲退出桥面,甲不从),进入阻塞,死锁了。
从这个例子也可以反映出,死锁是因为多线程访问共享资源,由于访问的顺序不当所造成的,通常是一个线程锁定了一个资源A,而又想去锁定资源B;在另一个线程中,锁定了资源B,而又想去锁定资源A以完成自身的操作,两个线程都想得到对方的资源,而不愿释放自己的资源,造成两个线程都在等待,而无法执行的情况。
避免死锁的方式
1、让程序每次至多只能获得一个锁。当然,在多线程环境下,这种情况通常并不现实。
2、设计时考虑清楚锁的顺序,尽量避免嵌套封锁。避免嵌套封锁:这是死锁最主要的原因的,如果你已经有一个资源了就要避免封锁另一个资源。如果你运行时只有一个对象封锁,那是几乎不可能出现一个死锁局面的。
3、加锁时限。既然死锁的产生是两个线程无限等待对方持有的锁,那么只要等待时间有个上限不就好了。当然synchronized不具备这个功能,但是我们可以使用Lock类中的tryLock方法去尝试获取锁,这个方法可以指定一个超时时限,在等待超过该时限之后便会返回一个失败信息。
我们可以使用ReentrantLock.tryLock()方法,在一个循环中,如果tryLock()返回失败,那么就释放以及获得的锁,并睡眠一小段时间。这样就打破了死锁的闭环。比如:线程T1持有锁L1并且申请获得锁L2,而线程T2持有锁L2并且申请获得锁L3,而线程T3持有锁L3并且申请获得锁L1。此时如果T3申请锁L1失败,那么T3释放锁L3,并进行睡眠,那么T2就可以获得L3了,然后T2执行完之后释放L2, L3,所以T1也可以获得L2了执行完然后释放锁L1, L2,然后T3睡眠醒来,也可以获得L1, L3了。打破了死锁的闭环。
Java中的Atomic类
Java1.5的Atomic包名为java.util.concurrent.atomic。这个包提供了一系列原子类。这些类可以保证多线程环境下,当某个线程在执行atomic的方法时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个线程执行。Atomic类在软件层面上是非阻塞的,它的原子性其实是在硬件层面上借助相关的指令来保证的。
Atomic包是java.util.concurrent下的另一个专门为线程安全设计的Java包,包含多个原子操作类。这个包里面提供了一组原子变量类。其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。实际上是借助硬件的相关指令来实现的,不会阻塞线程(或者说只是在硬件级别上阻塞了)。可以对基本数据、数组中的基本数据、对类中的基本数据进行操作。原子变量类相当于一种泛化的volatile变量,能够支持原子的和有条件的读-改-写操作。
Atomic包中的类可以分成4组:
(1)原子方式更新基本类型:AtomicBoolean(原子更新布尔类型)、AtomicInteger(原子更新整型)、AtomicLong(原子更新长整型)。
(2)原子方式更新数组:AtomicIntegerArray(原子更新整型数组里的元素)、AtomicLongArray(原子更新长整型数组里的元素)、AtomicReferenceArray(原子更新引用类型数组里的元素)。注意这里操作的不是整个数组,而是数组中的单个元素。
(3)原子方式更新引用:AtomicReference(原子更新引用类型)、AtomicReferenceFieldUpdater(原子更新引用类型里的字段)、AtomicMarkableReference:(原子更新带有标记位的引用类型)。以上三个类是以原子方式更新引用,与其它不同的是,更新引用可以更新多个变量,而不是一个变量。
(4)原子方式更新字段:AtomicIntegerFieldUpdater(原子更新整型字段的更新器)、AtomicLongFieldUpdater(原子更新长整型字段的更新器)、AtomicStampedReference(原子更新带有版本号的引用类型,用于解决使用CAS进行原子更新时,可能出现的ABA问题)。
AtomicInteger
在Java语言中,i++这类的操作不是原子操作,并非是线程安全的。i++可以分成三个操作:
(1)获取变量当前值
(2)给获取的当前变量值+1
(3)写回新的值到变量
假设i的初始值为10,当进行并发操作的时候,可能出现线程A和线程B都进行到了1操作,之后又同时进行2操作。A先进行到3操作+1,现在值为11;注意刚才AB获取到的当前值都是10,所以B执行3操作后,i的值依然是11。这个结果显然不符合我们的要求。这时候可以使用synchronized关键字进行同步。而AtomicInteger则通过一种线程安全的操作接口自动实现同步,不需要再人为的增加同步控制。
先来看一下最简单的AtomicInteger有哪些常见的方法以及这些方法的作用。
1 // 取得当前值 2 public final int get() 3 // 设置当前值 4 public final void set(int newValue) 5 // 设置新值,并返回旧值 6 public final int getAndSet(int newValue) 7 // 如果当前值为expect,则设置为u 8 public final boolean compareAndSet(int expect, int u) 9 // 当前值加1,返回旧值 10 public final int getAndIncrement() 11 // 当前值减1,返回旧值 12 public final int getAndDecrement() 13 // 当前值增加delta,返回旧值 14 public final int getAndAdd(int delta) 15 // 当前值加1,返回新值 16 public final int incrementAndGet() 17 // 当前值减1,返回新值 18 public final int decrementAndGet() 19 // 当前值增加delta,返回新值 20 public final int addAndGet(int delta)
AtomicInteger源码分析:
下面通过AtomicInteger的源码来看一下是怎么在没有锁的情况下保证数据正确性。首先看一下AtomicInteger类变量的定义:
1 private static final Unsafe unsafe = Unsafe.getUnsafe();
2 private static final long valueOffset;
3
4 static {
5 try {
6 valueOffset = unsafe.objectFieldOffset
7 (AtomicInteger.class.getDeclaredField("value"));
8 } catch (Exception ex) { throw new Error(ex); }
9 }
10
11 private volatile int value;
关于这段代码中出现的几个成员属性:
1、Unsafe是CAS的核心类。
Unsafe简介
sun.misc.Unsafe类型从名字看,这个类应该是封装了一些不安全的操作。
(1)可以用来在任意内存地址位置处读写数据,可见,对于普通用户来说,使用起来还是比较危险的;
(2)还支持一些CAS原子操作。
简单讲一下这个类。Java无法直接访问底层操作系统,而是通过本地(native)方法来访问。不过尽管如此,JVM还是开了一个后门,JDK中有一个类Unsafe,它提供了硬件级别的原子操作。
这个类尽管里面的方法都是public的,但是并没有办法使用它们,JDK API文档也没有提供任何关于这个类的方法的解释。总而言之,对于Unsafe类的使用都是受限制的,只有授信的代码才能获得该类的实例,当然JDK库里面的类是可以随意使用的。
从第一行的描述可以了解到Unsafe提供了硬件级别的操作,比如说获取某个属性在内存中的位置,比如说修改对象的字段值,即使它是私有的。不过Java本身就是为了屏蔽底层的差异,对于一般的开发而言也很少会有这样的需求。
举个例子,比方说:
public native long staticFieldOffset(Field paramField);
这个方法可以用来获取给定的paramField的内存地址偏移量,这个值对于给定的field是唯一的且是固定不变的。
2、valueOffset表示的是变量值在内存中的偏移地址,因为Unsafe就是根据内存偏移地址获取数据的原值的。
3、value是用volatile修饰的,这是非常关键的。
volatile包含以下语义:
- Java 存储模型不会对valatile指令的操作进行重排序:这个保证对volatile变量的操作时按照指令的出现顺序执行的。
- volatile变量不会被缓存在寄存器中(只有拥有线程可见)或者其他对CPU不可见的地方,每次总是从主存中读取volatile变量的结果。也就是说对于volatile变量的修改,其它线程总是可见的,并且不是使用自己线程栈内部的变量。也就是在happens-before法则中,对一个valatile变量的写操作后,其后的任何读操作理解可见此写操作的结果。
简而言之volatile 的作用是当一个线程修改了共享变量时,另一个线程可以读取到这个修改后的值。
AtomicInteger中有很多方法,例如incrementAndGet() 相当于i++ 和getAndAdd() 相当于i+=n 。从源码中我们可以看出这几种方法的实现很相似,所以我们主要分析incrementAndGet() 方法的源码。
源码如下:
1 public final int incrementAndGet() {
2 for (;;) {
3 // 获取当前值value
4 int current = get();
5 // 当前值+1
6 int next = current + 1;
7 //循环执行到递增成功
8 if (compareAndSet(current, next))
9 // 如果成功, 则返回新值
10 return next;
11
12 // 如果失败了, 说明其他线程已经修改了数据, 与期望不相符,
13 // 则继续无限循环, 直到成功. 这种乐观锁, 理论上只要等两三个时钟周期就可以设值成功
14 // 相比于直接通过synchronized独占锁的方式操作int, 要大大节约等待时间.
15 }
16 }
在这里采用了CAS操作,每次从内存中读取数据然后将此数据和+1后的结果进行CAS操作,如果成功就返回结果,否则重试直到成功为止。
而compareAndSet利用JNI来完成CPU指令的操作:
public final boolean compareAndSet(int expect, int update) {
// 通过unsafe 基于CPU的CAS指令来实现, 可以认为无阻塞.
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
整体的过程就是这样子的,利用CPU的CAS指令,同时借助JNI来完成Java的非阻塞算法。其它原子操作都是利用类似的特性完成的。
其中unsafe.compareAndSwapInt(this, valueOffset, expect, update) 类似:
if (this == expect) {
this = update
return true;
} else {
return false;
}
compareAndSet()方法调用的compareAndSwapInt()方法是一个native方法。其作用是每次从内存中根据内存偏移量(valueOffset)取出数据,将取出的值跟expect 比较,如果数据一致就把内存中的值改为update。这样使用CAS就保证了原子操作。其余几个方法的原理跟这个相同。
compareAndSet所做的为调用 Sun 的 UnSafe 的 compareAndSwapInt 方法来完成,此方法为 native 方法,compareAndSwapInt 基于的是CPU 的 CAS指令来实现的。所以基于 CAS 的操作可认为是无阻塞的,一个线程的失败或挂起不会引起其它线程也失败或挂起。并且由于 CAS 操作是 CPU 原语,所以性能比较好。
下面结合实例来分析一下incrementAndGet()方法如何在不加锁的情况下通过CAS实现线程安全,我们不妨考虑一下方法的执行:
(1)假设AtomicInteger里面的value原始值为3,即主内存中AtomicInteger的value为3,根据Java内存模型,线程1和线程2各自持有一份value的副本,值为3。
(2)线程1运行到第四行获取到当前的value为3,线程切换。
(3)线程2开始运行,获取到value为3,利用CAS对比内存中的值也为3,比较成功,修改内存,此时内存中的value改变,加1后值为4,线程切换。
(4)线程1恢复运行,利用CAS比较发现自己的value为3,内存中的value为4,得到一个重要的结论-->此时value正在被另外一个线程修改,所以我不能去修改它。
(5)线程1的compareAndSet失败,循环判断,因为value是volatile修饰的,所以它具备可见性的特性,线程2对于value的改变能被线程1看到,只要线程1发现当前获取的value是4,内存中的value也是4,说明线程2对于value的修改已经完毕并且线程1可以尝试去修改它。
(6)最后说一点,比如说此时线程3也准备修改value了,没关系,因为比较-交换是一个原子操作不可被打断,线程3修改了value,线程1进行compareAndSet的时候必然返回的false,这样线程1会继续循环去获取最新的value并进行compareAndSet,直至获取的value和内存中的value一致为止。
整个过程中,利用CAS机制保证了对于value的修改的线程安全性。
具体看下实现的源码:
(1)递增的方法:incrementAndGet()

incrementAndGet方法是在一个死循环里面调用compareAndSet方法,如果compareAndSet返回失败,就会一直从头开始循环,不会退出incrementAndGet方法,直到compareAndSet返回true。
(2)compareAndSet方法:
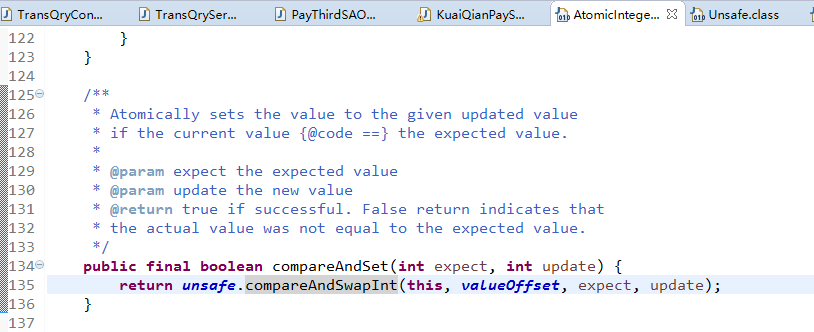
AtomicInteger中Unsafe实例调用compareAndSwapInt方法。
(3)compareAndSwapInt源码:
看到这里知道是一个本地方法的调用,比较并置换,这里利用Unsafe类的JNI方法实现,使用CAS指令,可以保证读-改-写是一个原子操作。compareAndSwapInt有4个参数,this - 当前AtomicInteger对象,valueOffset- value属性在内存中的位置(需要强调的不是value值在内存中的位置),expect - 预期值,update - 新值,根据上面的CAS操作过程,当内存中的value值等于expect值时,则将内存中的value值更新为update值,并返回true,否则返回false。在这里我们有必要对Unsafe有一个简单点的认识,从名字上来看,不安全,确实,这个类是用于执行低级别的、不安全操作的方法集合,这个类中的方法大部分是对内存的直接操作,所以不安全,但当我们使用反射、并发包时,都间接的用到了Unsafe。
并发情况处理流程
(1)首先valueOffset获取value的偏移量,假设value=0,valueOffset=0(valueOffset其实是内存地址,便于表达-后面用valueOffset=n表示对应值的地址)。
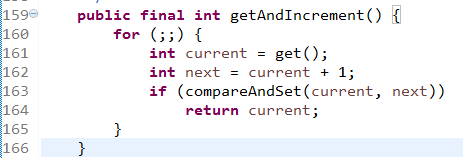
(2)线程A调用getAndIncrement方法,执行到161行,获取current=0,next=1,准备执行compareAndSet方法。
(3)线程B几乎与线程A同时调用getAndIncrement方法,执行完161行后,获取current=0,next=1,并且先于线程A执行compareAndSet方法,此时value=1,valueOffset=1。
(4)线程A调用compareAndSet发现预期值(current=0)与内存中对应的值(valueOffset=1,被线程B修改)不相等,即在本线程执行期间有被修改过,则放弃此次修改,返回false。
(5)线程B接着循环,通过get()获取的值是最新的(volatile修饰的value的值会强迫线程从主内存获取),current=1,next=2,然后发现valueOffset=current=1,修改valueOffset=2。
AtomicInteger的使用:
package com.demo.Atomic;
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicIntegerDemo extends Thread{
private static AtomicInteger i = new AtomicInteger();
@Override
public void run() {
for (int k = 0; k < 100; k++) {
i.incrementAndGet();
//System.out.println(Thread.currentThread().getName()+"-------------"+i.get());
}
}
public static void main(String[] args) throws InterruptedException {
AtomicIntegerDemo[] ts = new AtomicIntegerDemo[10];
for (int k = 0; k < 10; k++) {
ts[k] = new AtomicIntegerDemo();
}
for (int k = 0; k < 10; k++) {
ts[k].start();
}
for (int k = 0; k < 10; k++) {
ts[k].join();
}
System.out.println("最终结果:"+ i);
}
}
运行结果:
最终结果:1000
多个线程对AtomicInteger类型的变量进行自增操作,运算结果无误,也就是说AtomicInteger可以实现原子操作,即在多线程环境中,执行的操作不会被其他线程打断。若用普通的int变量,i++多线程操作可能导致结果有误。
现在再来思考这个问题:AtomicInteger是如何实现线程安全呢?请大家自己先考虑一下这个问题,其实我们在语言层面是没有做任何同步的操作的,大家也可以看到源码没有任何锁加在上面,可它为什么是线程安全的呢?这就是Atomic包下这些类的奥秘:语言层面不做处理,我们将其交给硬件—CPU和内存,利用CPU的多处理能力,实现硬件层面的阻塞,再加上volatile变量的特性即可实现基于原子操作的线程安全。所以说,CAS并不是无阻塞,只是阻塞并非在语言、线程方面,而是在硬件层面,所以无疑这样的操作会更快更高效!
总结一下,AtomicInteger 中主要实现了整型的原子操作,防止并发情况下出现异常结果,其内部主要依靠JDK 中的unsafe 类操作内存中的数据来实现的。volatile 修饰符保证了value在内存中其他线程可以看到其值得改变。CAS操作保证了AtomicInteger 可以安全的修改value 的值。
CAS
CAS 指的是现代 CPU 广泛支持的一种对内存中的共享数据进行操作的一种特殊指令。这个指令会对内存中的共享数据做原子的读写操作。简单介绍一下这个指令的操作过程:首先,CPU 会将内存中将要被更改的数据与期望的值做比较。然后,当这两个值相等时,CPU 才会将内存中的数值替换为新的值。否则便不做操作。最后,CPU 会将旧的数值返回。这一系列的操作是原子的。它们虽然看似复杂,但却是 Java 5 并发机制优于原有锁机制的根本。简单来说,CAS 的含义是“我认为原有的值应该是什么,如果是,则将原有的值更新为新值,否则不做修改,并告诉我原来的值是多少”。(这段描述引自《Java并发编程实践》)
简单的来说,CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则返回V。这是一种乐观锁的思路,它相信在它修改之前,没有其它线程去修改它;而synchronized是一种悲观锁,它认为在它修改之前,一定会有其它线程去修改它,悲观锁效率很低。
CAS应用
CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
乐观锁:其实现机制是基于CAS的,每次不加锁,假设没有冲突完成操作,如果有冲突,重试直到成功为止。
(1)非阻塞算法 (nonblocking algorithms)
即一个线程的失败或者挂起不应该影响其他线程的失败或挂起的算法。
现代的CPU提供了特殊的指令,可以自动更新共享数据,而且能够检测到其他线程的干扰,而 compareAndSet() 就用这些代替了锁定。
(2)Java原子类:AtomicInteger等
CAS原理
CAS通过调用JNI的代码实现的。JNI:Java Native Interface为JAVA本地调用,允许java调用其他语言。
而compareAndSwapInt就是借助C来调用CPU底层指令实现的。
下面从分析比较常用的CPU(intel x86)来解释CAS的实现原理。下面是sun.misc.Unsafe类的compareAndSwapInt()方法的源代码:
public final native boolean compareAndSwapInt(Object o, long offset, int expected, int x);
可以看到这是个本地方法调用。这个本地方法在openjdk中依次调用的c++代码为:unsafe.cpp,atomic.cpp和atomicwindowsx86.inline.hpp。这个本地方法的最终实现在openjdk的如下位置:openjdk-7-fcs-src-b147-27jun2011openjdkhotspotsrcoscpuwindowsx86vm atomicwindowsx86.inline.hpp(对应于windows操作系统,X86处理器)。下面是对应于intel x86处理器的源代码的片段:
// Adding a lock prefix to an instruction on MP machine
// VC++ doesn't like the lock prefix to be on a single line
// so we can't insert a label after the lock prefix.
// By emitting a lock prefix, we can define a label after it.
#define LOCK_IF_MP(mp) __asm cmp mp, 0
__asm je L0
__asm _emit 0xF0
__asm L0:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
// alternative for InterlockedCompareExchange
int mp = os::is_MP();
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}
如上面源代码所示,可以看出最后调用的是Atomic:comxchg这个方法,程序会根据当前处理器的类型来决定是否为cmpxchg指令添加lock前缀。如果程序是在多处理器上运行,就为cmpxchg指令加上lock前缀(lock cmpxchg)。反之,如果程序是在单处理器上运行,就省略lock前缀(单处理器自身会维护单处理器内的顺序一致性,不需要lock前缀提供的内存屏障效果)。
intel的手册对lock前缀的说明如下:
(1)确保对内存的读-改-写操作原子执行。在Pentium及Pentium之前的处理器中,带有lock前缀的指令在执行期间会锁住总线,使得其他 处理器暂时无法通过总线访问内存。很显然,这会带来昂贵的开销。从Pentium 4,Intel Xeon及P6处理器开始,intel在原有总线锁的基础上做了一个很有意义的优化:如果要访问的内存区域(area of memory)在lock前缀指令执行期间已经在处理器内部的缓存中被锁定(即包含该内存区域的缓存行当前处于独占或以修改状态),并且该内存区域被完全包含在单个缓存行(cache line)中,那么处理器将直接执行该指令。由于在指令执行期间该缓存行会一直被锁定,其它处理器无法读/写该指令要访问的内存区域,因此能保证指令执行的原子性。这个操作过程叫做缓存锁定(cache locking),缓存锁定将大大降低lock前缀指令的执行开销,但是当多处理器之间的竞争程度很高或者指令访问的内存地址未对齐时,仍然会锁住总线。
(2)禁止该指令与之前和之后的读和写指令重排序。
(3)把写缓冲区中的所有数据刷新到内存中。
关于处理器如何实现原子操作有以下三种:
(1)处理器自动保证基本内存操作的原子性
首先处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存当中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址。奔腾6和最新的处理器能自动保证单处理器对同一个缓存行里进行16/32/64位的操作是原子的,但是复杂的内存操作处理器不能自动保证其原子性,比如跨总线宽度,跨多个缓存行,跨页表的访问。但是处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
(2)使用总线锁保证原子性
第一个机制是通过总线锁保证原子性。如果多个处理器同时对共享变量进行读改写(i++就是经典的读改写操作)操作,那么共享变量就会被多个处理器同时进行操作,这样读改写操作就不是原子的,操作完之后共享变量的值会和期望的不一致,举个例子:如果i=1,我们进行两次i++操作,我们期望的结果是3,但是有可能结果是2。如下图:
原因是有可能多个处理器同时从各自的缓存中读取变量i,分别进行加一操作,然后分别写入系统内存当中。那么想要保证读改写共享变量的操作是原子的,就必须保证CPU1读改写共享变量的时候,CPU2不能操作缓存了该共享变量内存地址的缓存。
处理器使用总线锁就是来解决这个问题的。所谓总线锁就是使用处理器提供的一个LOCK#信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,那么该处理器可以独占使用共享内存。
(3)使用缓存锁保证原子性
第二个机制是通过缓存锁定保证原子性。在同一时刻我们只需保证对某个内存地址的操作是原子性即可,但总线锁会把CPU和内存之间通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,所以总线锁定的开销比较大,最近的处理器在某些场合下使用缓存锁定代替总线锁定来进行优化。
频繁使用的内存会缓存在处理器的L1,L2和L3高速缓存里,那么原子操作就可以直接在处理器内部缓存中进行,并不需要声明总线锁,在奔腾6和最近的处理器中可以使用“缓存锁定”的方式来实现复杂的原子性。所谓“缓存锁定”就是如果缓存在处理器缓存行中内存区域在LOCK操作期间被锁定,当它执行锁操作回写内存时,处理器不在总线上声言LOCK#信号,而是修改内部的内存地址,并允许它的缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改被两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓存行的数据时会起缓存行无效,在例1中,当CPU1修改缓存行中的i时使用缓存锁定,那么CPU2就不能同时缓存了i的缓存行。
但是有两种情况下处理器不会使用缓存锁定。第一种情况是:当操作的数据不能被缓存在处理器内部,或操作的数据跨多个缓存行(cache line),则处理器会调用总线锁定。第二种情况是:有些处理器不支持缓存锁定。对于Inter486和奔腾处理器,就算锁定的内存区域在处理器的缓存行中也会调用总线锁定。
以上两个机制我们可以通过Inter处理器提供了很多LOCK前缀的指令来实现。比如位测试和修改指令BTS,BTR,BTC,交换指令XADD,CMPXCHG和其他一些操作数和逻辑指令,比如ADD(加),OR(或)等,被这些指令操作的内存区域就会加锁,导致其他处理器不能同时访问它。
CAS存在的问题
CAS虽然很高效的解决原子操作,但是CAS仍然存在三大问题。ABA问题,循环时间长开销大和只能保证一个共享变量的原子操作。
(1)ABA问题。
因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A。
从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
所谓ABA问题基本是这个样子:
(1)进程P1在共享变量中读到值为A
(2)P1被抢占了,进程P2执行
(3)P2把共享变量里的值从A改成了B,再改回到A,此时被P1抢占。
(4)P1回来看到共享变量里的值没有被改变,于是继续执行。
虽然P1以为变量值没有改变,继续执行了,但是这个会引发一些潜在的问题。ABA问题最容易发生在lock free 的算法中的,CAS首当其冲,因为CAS判断的是指针的地址。如果这个地址被重用了呢,问题就很大了。(地址被重用是很经常发生的,一个内存分配后释放了,再分配,很有可能还是原来的地址)
这个例子你可能没有看懂,维基百科上给了一个活生生的例子——
你拿着一个装满钱的手提箱在飞机场,此时过来了一个火辣性感的美女,然后她很暖昧地挑逗着你,并趁你不注意的时候,把用一个一模一样的手提箱和你那装满钱的箱子 调了个包,然后就离开了,你看到你的手提箱还在那,于是就提着手提箱去赶飞机去了。
这就是ABA问题。
(2)循环时间长开销大。
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
(3)只能保证一个共享变量的原子操作。
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
总结
CAS利用CPU调用底层指令实现,即CAS操作正是利用了处理器提供的CMPXCHG指令实现的。
单一处理器,进行简单的读写操作时,能保证自身读取的原子性,多处理器或复杂的内存操作时,CAS采用总线加锁或缓存加锁方式保证原子性。
(1)总线加锁
如i=0初始化,多处理器多线程环境下进行i++操作下,处理器A和B同时读取i值到各自缓存,分别进行递增,回写值i=1相同。处理器提供LOCK#信号,进行总线加锁后,处理器A读取i值并递增,处理器B被阻塞不能读取i值。
(2)缓存加锁
总线加锁,在LOCK#信号下,其他线程无法操作内存,性能较差,缓存加锁能较好处理该问题。
缓存加锁,处理器A和B同时读取i值到缓存,处理器A提前完成递增,数据立即回写到主内存,并让处理器B缓存该数据失效,处理器B需重新读取i值。
虽然基于CAS的线程安全机制很好很高效,但要说的是,并非所有线程安全都可以用这样的方法来实现,这只适合一些粒度比较小,型如计数器这样的需求用起来才有效,否则也不会有锁的存在了。
AQS
AQS定义了一套多线程访问共享资源的同步器框架,许多同步类实现都依赖于它,如常用的ReentrantLock/Semaphore/CountDownLatch...。
AQS,它维护了一个volatile int state(代表共享资源)状态变量和一个FIFO线程等待队列(多线程争用资源被阻塞时会进入此队列)。
AQS是JUC中很多同步组件的构建基础,简单来讲,它内部实现主要是状态变量state和一个FIFO队列来完成,同步队列的头结点是当前获取到同步状态的结点,获取同步状态state失败的线程,会被构造成一个结点(或共享式或独占式)加入到同步队列尾部(采用自旋CAS来保证此操作的线程安全),随后线程会阻塞;释放时唤醒头结点的后继结点,使其加入对同步状态的争夺中。
AQS的主要使用方式是继承,子类通过继承同步器并实现它的抽象方法来管理同步状态。
AQS使用一个int类型的成员变量state来表示同步状态,当state>0时表示已经获取了锁,当state = 0时表示释放了锁。它提供了三个方法(getState()、setState(int newState)、compareAndSetState(int expect,int update))来对同步状态state进行操作,当然AQS可以确保对state的操作是安全的。
AQS通过内置的FIFO同步队列来完成资源获取线程的排队工作,如果当前线程获取同步状态失败(锁)时,AQS则会将当前线程以及等待状态等信息构造成一个节点(Node)并将其加入同步队列,同时会阻塞当前线程,当同步状态释放时,则会把节点中的线程唤醒,使其再次尝试获取同步状态。
CountDownLatch
CountDownLatch类位于java.util.concurrent包下,利用它可以实现类似计数器的功能。比如有一个任务A,它要等待其他4个任务执行完毕之后才能执行,此时就可以利用CountDownLatch来实现这种功能了。
CountDownLatch类只提供了一个构造器:
public CountDownLatch(int count) { }; //参数count为计数值
然后下面这3个方法是CountDownLatch类中最重要的方法:
//调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行
public void await() throws InterruptedException { };
//和await()类似,只不过等待一定的时间后count值还没变为0的话就会继续执行
public boolean await(long timeout, TimeUnit unit) throws InterruptedException { };
//将count值减1
public void countDown() { };
CountDownLatch类是一个同步计数器,构造时传入int参数,该参数就是计数器的初始值,每调用一次countDown()方法,计数器减1,计数器大于0 时,await()方法会阻塞程序继续执行。CountDownLatch可以看作是一个倒计数的锁存器,当计数减至0时触发特定的事件。利用这种特性,可以让主线程等待子线程的结束。
java.util.concurrent.CountDownLatch它是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
用给定的计数初始化 CountDownLatch。在调用countDown() 方法,使当前计数减一,且当前计数到达零之前,await 方法会一直受阻塞。当前计数到达零之后,会释放所有等待的线程,await 的所有后续调用都将立即返回。这种现象只出现一次——计数无法被重置。如果需要重置计数,请考虑使用 CyclicBarrier。
CountDownLatch的一个非常典型的应用场景是:有一个任务想要往下执行,但必须要等到其他的任务执行完毕后才可以继续往下执行。假如我们这个想要继续往下执行的任务调用一个CountDownLatch对象的await()方法,其他的任务执行完自己的任务后调用同一个CountDownLatch对象上的countDown()方法,这个调用await()方法的任务将一直阻塞等待,直到这个CountDownLatch对象的计数值减到0为止。
CountDownLatch 是一个通用同步工具,主要有以下三种用法:
(1)将计数1初始化的 CountDownLatch 用作一个简单的开/关锁存器,或入口。在通过调用 countDown() 的线程打开入口前,所有调用 await 的线程都一直在入口处等待。
(2)用N初始化的 CountDownLatch 可以使一个线程在 N 个线程完成某项操作之前一直等待,或者使其在某项操作完成 N 次之前一直等待。
(3)它不要求调用 countDown 方法的线程等到计数到达零时才继续,而在所有线程都能通过之前,它只是阻止任何线程继续通过一个await。即调用countDown 方法的线程并不会阻塞。CountDownLatch调用await方法将阻塞当前线程,直到其他线程调用countDown 方法,使其计数到达零时才继续。
实现原理
CountDownLatch是通过“共享锁”实现的。在创建CountDownLatch中时,会传递一个int类型参数count,该参数是“锁计数器”的初始状态,表示该“共享锁”最多能被count个线程同时获取。当某线程调用该CountDownLatch对象的await()方法时,该线程会等待“共享锁”可用时,才能获取“共享锁”进而继续运行。而“共享锁”可用的条件,就是“锁计数器”的值为0!而“锁计数器”的初始值为count,每当一个线程调用该CountDownLatch对象的countDown()方法时,才将“锁计数器”-1;通过这种方式,必须有count个线程调用countDown()之后,“锁计数器”才为0,而前面提到的等待线程才能继续运行!
示例:
下面通过CountDownLatch实现:"主线程"等待"5个子线程"全部都完成"指定的工作(休眠1000ms)"之后,再继续运行。
package com.demo.aqs;
import java.util.concurrent.CountDownLatch;
public class CountDownLatchTest {
private static int LATCH_SIZE = 5;
private static CountDownLatch doneSignal;
public static void main(String[] args) {
try {
doneSignal = new CountDownLatch(LATCH_SIZE);
// 新建5个任务
for(int i=0; i<LATCH_SIZE; i++)
new InnerThread().start();
System.out.println("main await begin.");
// "主线程"等待5个任务的完成
doneSignal.await();
System.out.println("main await finished.");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static class InnerThread extends Thread{
public void run() {
try {
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName() + " sleep 1000ms.");
// 将CountDownLatch的数值减1
doneSignal.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行结果:
main await begin. Thread-2 sleep 1000ms. Thread-0 sleep 1000ms. Thread-1 sleep 1000ms. Thread-3 sleep 1000ms. Thread-4 sleep 1000ms. main await finished.
结果说明:主线程通过doneSignal.await()等待其它线程将doneSignal递减至0。其它的5个InnerThread线程,每一个都通过doneSignal.countDown()将doneSignal的值减1;当doneSignal为0时,main被唤醒后继续执行。
示例2:
package com.demo.aqs;
import java.util.concurrent.CountDownLatch;
public class Test {
public static void main(String[] args) {
final CountDownLatch latch = new CountDownLatch(2);
new Thread(){
public void run() {
try {
System.out.println("子线程"+Thread.currentThread().getName()+"正在执行");
Thread.sleep(3000);
System.out.println("子线程"+Thread.currentThread().getName()+"执行完毕");
latch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
};
}.start();
new Thread(){
public void run() {
try {
System.out.println("子线程"+Thread.currentThread().getName()+"正在执行");
Thread.sleep(3000);
System.out.println("子线程"+Thread.currentThread().getName()+"执行完毕");
latch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
};
}.start();
try {
System.out.println("等待2个子线程执行完毕...");
latch.await();
System.out.println("2个子线程已经执行完毕");
System.out.println("继续执行主线程");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
运行结果:
子线程Thread-0正在执行 等待2个子线程执行完毕... 子线程Thread-1正在执行 子线程Thread-1执行完毕 子线程Thread-0执行完毕 2个子线程已经执行完毕 继续执行主线程
CyclicBarrier
字面意思回环栅栏,通过它可以实现让一组线程等待至某个状态之后再全部同时执行。叫做回环是因为当所有等待线程都被释放以后,CyclicBarrier可以被重用。我们暂且把这个状态就叫做barrier,当调用await()方法之后,线程就处于barrier了。
CyclicBarrier是一个同步辅助类,允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。因为该 barrier 在释放等待线程后可以重用,所以称它为循环 的 barrier。CyclicBarrier是通过ReentrantLock(独占锁)和Condition来实现的。
CyclicBarrier类位于java.util.concurrent包下,CyclicBarrier提供2个构造器:
public CyclicBarrier(int parties, Runnable barrierAction) {
}
public CyclicBarrier(int parties) {
}
参数parties指让多少个线程或者任务等待至barrier状态;参数barrierAction为当这些线程都达到barrier状态时会执行的内容。然后CyclicBarrier中最重要的方法就是await方法,它有2个重载版本:
public int await() throws InterruptedException, BrokenBarrierException { };
public int await(long timeout, TimeUnit unit)throws InterruptedException,BrokenBarrierException,TimeoutException { };
第一个版本比较常用,用来挂起当前线程,直至所有线程都到达barrier状态再同时执行后续任务;第二个版本是让这些线程等待至一定的时间,如果还有线程没有到达barrier状态就直接让到达barrier的线程执行后续任务。
下面举几个例子就明白了:
假若有若干个线程都要进行写数据操作,并且只有所有线程都完成写数据操作之后,这些线程才能继续做后面的事情,此时就可以利用CyclicBarrier了:
package com.demo.aqs;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class TestCyclicBarrier {
public static void main(String[] args) {
int N = 4;
CyclicBarrier barrier = new CyclicBarrier(N);
for(int i=0;i<N;i++)
new Writer(barrier).start();
}
static class Writer extends Thread{
private CyclicBarrier cyclicBarrier;
public Writer(CyclicBarrier cyclicBarrier) {
this.cyclicBarrier = cyclicBarrier;
}
@Override
public void run() {
System.out.println("线程"+Thread.currentThread().getName()+"正在写入数据...");
try {
Thread.sleep(5000);//以睡眠来模拟写入数据操作
System.out.println("线程"+Thread.currentThread().getName()+"写入数据完毕,等待其他线程写入完毕");
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
}catch(BrokenBarrierException e){
e.printStackTrace();
}
System.out.println("所有线程写入完毕,继续处理其他任务...");
}
}
}
运行结果:
线程Thread-0正在写入数据... 线程Thread-3正在写入数据... 线程Thread-2正在写入数据... 线程Thread-1正在写入数据... 线程Thread-3写入数据完毕,等待其他线程写入完毕 线程Thread-2写入数据完毕,等待其他线程写入完毕 线程Thread-0写入数据完毕,等待其他线程写入完毕 线程Thread-1写入数据完毕,等待其他线程写入完毕 所有线程写入完毕,继续处理其他任务... 所有线程写入完毕,继续处理其他任务... 所有线程写入完毕,继续处理其他任务... 所有线程写入完毕,继续处理其他任务...
从上面输出结果可以看出,每个写入线程执行完写数据操作之后,就在等待其他线程写入操作完毕。当所有线程线程写入操作完毕之后,所有线程就继续进行后续的操作了。
如果说想在所有线程写入操作完之后,进行额外的其他操作可以为CyclicBarrier提供Runnable参数:
package com.demo.aqs;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class TestCyclicBarrier1 {
public static void main(String[] args) {
int N = 4;
CyclicBarrier barrier = new CyclicBarrier(N,new Runnable() {
@Override
public void run() {
System.out.println("当前线程"+Thread.currentThread().getName());
}
});
for(int i=0;i<N;i++)
new Writer(barrier).start();
}
static class Writer extends Thread{
private CyclicBarrier cyclicBarrier;
public Writer(CyclicBarrier cyclicBarrier) {
this.cyclicBarrier = cyclicBarrier;
}
@Override
public void run() {
System.out.println("线程"+Thread.currentThread().getName()+"正在写入数据...");
try {
Thread.sleep(5000); //以睡眠来模拟写入数据操作
System.out.println("线程"+Thread.currentThread().getName()+"写入数据完毕,等待其他线程写入完毕");
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
}catch(BrokenBarrierException e){
e.printStackTrace();
}
System.out.println("所有线程写入完毕,继续处理其他任务...");
}
}
}
运行结果:
线程Thread-0正在写入数据... 线程Thread-1正在写入数据... 线程Thread-2正在写入数据... 线程Thread-3正在写入数据... 线程Thread-0写入数据完毕,等待其他线程写入完毕 线程Thread-1写入数据完毕,等待其他线程写入完毕 线程Thread-2写入数据完毕,等待其他线程写入完毕 线程Thread-3写入数据完毕,等待其他线程写入完毕 当前线程Thread-3 所有线程写入完毕,继续处理其他任务... 所有线程写入完毕,继续处理其他任务... 所有线程写入完毕,继续处理其他任务... 所有线程写入完毕,继续处理其他任务...
从结果可以看出,当四个线程都到达barrier状态后,会从四个线程中选择一个线程去执行Runnable。
另外CyclicBarrier是可以重用的,看下面这个例子:
package com.demo.aqs;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class TestCyclicBarrier2 {
public static void main(String[] args) {
int N = 4;
CyclicBarrier barrier = new CyclicBarrier(N);
for(int i=0;i<N;i++) {
new Writer(barrier).start();
}
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("CyclicBarrier重用");
for(int i=0;i<N;i++) {
new Writer(barrier).start();
}
}
static class Writer extends Thread{
private CyclicBarrier cyclicBarrier;
public Writer(CyclicBarrier cyclicBarrier) {
this.cyclicBarrier = cyclicBarrier;
}
@Override
public void run() {
System.out.println("线程"+Thread.currentThread().getName()+"正在写入数据...");
try {
Thread.sleep(1000); //以睡眠来模拟写入数据操作
System.out.println("线程"+Thread.currentThread().getName()+"写入数据完毕,等待其他线程写入完毕");
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
}catch(BrokenBarrierException e){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"所有线程写入完毕,继续处理其他任务...");
}
}
}
运行结果:
线程Thread-0正在写入数据... 线程Thread-1正在写入数据... 线程Thread-3正在写入数据... 线程Thread-2正在写入数据... 线程Thread-2写入数据完毕,等待其他线程写入完毕 线程Thread-1写入数据完毕,等待其他线程写入完毕 线程Thread-0写入数据完毕,等待其他线程写入完毕 线程Thread-3写入数据完毕,等待其他线程写入完毕 Thread-3所有线程写入完毕,继续处理其他任务... Thread-1所有线程写入完毕,继续处理其他任务... Thread-0所有线程写入完毕,继续处理其他任务... Thread-2所有线程写入完毕,继续处理其他任务... CyclicBarrier重用 线程Thread-4正在写入数据... 线程Thread-5正在写入数据... 线程Thread-6正在写入数据... 线程Thread-7正在写入数据... 线程Thread-7写入数据完毕,等待其他线程写入完毕 线程Thread-6写入数据完毕,等待其他线程写入完毕 线程Thread-5写入数据完毕,等待其他线程写入完毕 线程Thread-4写入数据完毕,等待其他线程写入完毕 Thread-4所有线程写入完毕,继续处理其他任务... Thread-7所有线程写入完毕,继续处理其他任务... Thread-6所有线程写入完毕,继续处理其他任务... Thread-5所有线程写入完毕,继续处理其他任务...
从执行结果可以看出,在初次的4个线程越过barrier状态后,又可以用来进行新一轮的使用。而CountDownLatch无法进行重复使用。
比较CountDownLatch和CyclicBarrier:
(1) CountDownLatch的作用是允许1或N个线程等待其他线程完成执行;而CyclicBarrier则是允许N个线程相互等待。
(2) CountDownLatch的计数器无法被重置;CyclicBarrier的计数器可以被重置后使用,因此它被称为是循环的barrier。
Semaphore
Semaphore翻译成字面意思为信号量,Semaphore可以控同时访问的线程个数,通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可。
Semaphore也是一个线程同步的辅助类,可以维护当前访问自身的线程个数,并提供了同步机制。使用Semaphore可以控制同时访问资源的线程个数,例如,实现一个文件允许的并发访问数。
Semaphore类位于java.util.concurrent包下,它提供了2个构造器:
public Semaphore(int permits) {//参数permits表示许可数目,即同时可以允许多少线程进行访问
sync = new NonfairSync(permits);
}
public Semaphore(int permits, boolean fair) {//这个多了一个参数fair表示是否是公平的,即等待时间越久的越先获取许可
sync = (fair)? new FairSync(permits) : new NonfairSync(permits);
}
下面说一下Semaphore类中比较重要的几个方法,首先是acquire()、release()方法:
public void acquire() throws InterruptedException { } //获取一个许可
public void acquire(int permits) throws InterruptedException { } //获取permits个许可
public void release() { } //释放一个许可
public void release(int permits) { } //释放permits个许可
acquire()用来获取一个许可,若无许可能够获得,则会一直等待,直到获得许可。release()用来释放许可。注意,在释放许可之前,必须先获获得许可。这4个方法都会被阻塞,如果想立即得到执行结果,可以使用下面几个方法:
//尝试获取一个许可,若获取成功,则立即返回true,若获取失败,则立即返回false
public boolean tryAcquire() { };
//尝试获取一个许可,若在指定的时间内获取成功,则立即返回true,否则则立即返回false
public boolean tryAcquire(long timeout, TimeUnit unit) throws InterruptedException { };
//尝试获取permits个许可,若获取成功,则立即返回true,若获取失败,则立即返回false
public boolean tryAcquire(int permits) { };
//尝试获取permits个许可,若在指定的时间内获取成功,则立即返回true,否则则立即返回false
public boolean tryAcquire(int permits, long timeout, TimeUnit unit) throws InterruptedException { };
另外还可以通过availablePermits()方法得到可用的许可数目。
下面通过一个例子来看一下Semaphore的具体使用。假若一个工厂有5台机器,但是有8个工人,一台机器同时只能被一个工人使用,只有使用完了,其他工人才能继续使用。那么我们就可以通过Semaphore来实现:
package com.demo.aqs;
import java.util.concurrent.Semaphore;
public class TestSemaphore {
public static void main(String[] args) {
int N = 8; //工人数
Semaphore semaphore = new Semaphore(5); //机器数目
for(int i=0;i<N;i++)
new Worker(i,semaphore).start();
}
static class Worker extends Thread{
private int num;
private Semaphore semaphore;
public Worker(int num,Semaphore semaphore){
this.num = num;
this.semaphore = semaphore;
}
@Override
public void run() {
try {
semaphore.acquire();
System.out.println("工人"+this.num+"占用一个机器在生产...");
Thread.sleep(2000);
System.out.println("工人"+this.num+"释放出机器");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行结果:
工人1占用一个机器在生产... 工人0占用一个机器在生产... 工人4占用一个机器在生产... 工人3占用一个机器在生产... 工人2占用一个机器在生产... 工人4释放出机器 工人0释放出机器 工人5占用一个机器在生产... 工人3释放出机器 工人1释放出机器 工人7占用一个机器在生产... 工人2释放出机器 工人6占用一个机器在生产... 工人5释放出机器 工人7释放出机器 工人6释放出机器
总结
(1)CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不同:CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;另外,CountDownLatch是不能够重用的,而CyclicBarrier是可以重用的。
(2)Semaphore其实和锁有点类似,它一般用于控制对某组资源的访问权限。
两个线程交替打印奇偶数
方法一:使用同步方法实现
package com.demo.printOddEven;
public class Num {
private int count = 1;
/**
* 打印奇数
*/
public synchronized void printOdd() {
try {
if (count % 2 != 1) {
this.wait();
}
System.out.println(Thread.currentThread().getName() + "----------" + count);
count++;
this.notify();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 打印偶数
*/
public synchronized void printEven() {
try {
if (count % 2 != 0) {
this.wait();
}
System.out.println(Thread.currentThread().getName() + "----------" + count);
count++;
this.notify();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
打印奇数的线程:
package com.demo.printOddEven;
/**
* 打印奇数的线程
* @author lixiaoxi
*
*/
public class Odd implements Runnable{
private Num num;
public Odd(Num num) {
this.num = num;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
num.printOdd();
}
}
}
打印偶数的线程:
package com.demo.printOddEven;
/**
* 打印偶数的线程
* @author lixiaoxi
*
*/
public class Even implements Runnable {
private Num num;
public Even(Num num) {
this.num = num;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
num.printEven();
}
}
}
测试:
package com.demo.printOddEven;
public class TestPrint {
public static void main(String[] args) {
Num num = new Num();
Odd odd = new Odd(num);
Even even = new Even(num);
Thread t1 = new Thread(odd, "threadOdd");
Thread t2 = new Thread(even, "threadEven");
t1.start();
t2.start();
}
}
运行结果:
threadOdd----------1 threadEven----------2 threadOdd----------3 threadEven----------4 threadOdd----------5 threadEven----------6 threadOdd----------7 threadEven----------8 threadOdd----------9 threadEven----------10
方法二:使用同步块实现
package com.demo.printOddEven;
public class Number {
private int count = 1;
private Object lock = new Object();
/**
* 打印奇数
*/
public void printOdd() {
synchronized(lock) {
try {
if(count % 2 != 1) {
lock.wait();
}
System.out.println(Thread.currentThread().getName() + "=======" + count);
count++;
lock.notify();
} catch(InterruptedException e) {
}
}
}
/**
* 打印偶数
*/
public void printEven() {
synchronized(lock) {
try {
if(count % 2 != 0) {
lock.wait();
}
System.out.println(Thread.currentThread().getName() + "=======" + count);
count++;
lock.notify();
} catch(InterruptedException e) {
}
}
}
}
打印奇数的线程:
package com.demo.printOddEven;
/**
* 打印奇数的线程
* @author lixiaoxi
*
*/
public class OddPrinter implements Runnable {
private Number num;
public OddPrinter(Number num) {
this.num = num;
}
public void run() {
for (int i = 0; i < 5; i++) {
num.printOdd();
}
}
}
打印偶数的线程:
package com.demo.printOddEven;
/**
* 打印偶数的线程
* @author lixiaoxi
*
*/
public class EvenPrinter implements Runnable{
private Number num;
public EvenPrinter(Number num) {
this.num = num;
}
public void run() {
for (int i = 0; i < 5; i++) {
num.printEven();
}
}
}
测试:
package com.demo.printOddEven;
public class PrintOddEven {
public static void main(String[] args) {
Number num = new Number();
OddPrinter oddPrinter = new OddPrinter(num);
EvenPrinter evenPrinter = new EvenPrinter(num);
Thread oddThread = new Thread(oddPrinter, "oddThread");
Thread evenThread = new Thread(evenPrinter, "evenThread");
oddThread.start();
evenThread.start();
}
}
运行结果:
oddThread=======1 evenThread=======2 oddThread=======3 evenThread=======4 oddThread=======5 evenThread=======6 oddThread=======7 evenThread=======8 oddThread=======9 evenThread=======10
方法三:使用ReentrantLock实现
package com.demo.printOddEven;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class Number1 {
private int count = 1;
private ReentrantLock lock = new ReentrantLock();
// 为打印奇数的线程注册一个Condition
public Condition conditionOdd = lock.newCondition();
// 为打印偶数的线程注册一个Condition
public Condition conditionEven = lock.newCondition();
/**
* 打印奇数
*/
public void printOdd() {
try {
lock.lock();
if(count % 2 != 1) {
conditionOdd.await();
}
System.out.println(Thread.currentThread().getName() + "=======" + count);
count++;
conditionEven.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
/**
* 打印偶数
*/
public void printEven() {
try {
lock.lock();
if(count % 2 != 0) {
conditionEven.await();
}
System.out.println(Thread.currentThread().getName() + "=======" + count);
count++;
conditionOdd.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
测试:
package com.demo.printOddEven;
public class PrintOddEven1 {
public static void main(String[] args) {
final Number1 num = new Number1();
/**
* 打印奇数的线程
*/
Thread oddThread = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
num.printOdd();
}
}
}, "oddThread");
/**
* 打印偶数的线程
*/
Thread evenThread = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
num.printEven();
}
}
}, "evenThread");
oddThread.start();
evenThread.start();
}
}
运行结果:
oddThread=======1 evenThread=======2 oddThread=======3 evenThread=======4 oddThread=======5 evenThread=======6 oddThread=======7 evenThread=======8 oddThread=======9 evenThread=======10
三个线程交替打印ABC
如果要实现3个线程交替打印ABC呢?这次打算使用重入锁,和上面没差多少,但是由于现在有三个线程了,在打印完后需要唤醒其他线程,注意不可使用sigal(),因为唤醒的线程是随机的,不能保证打印顺序不说,还会造成死循环。一定要使用sigalAll()唤醒所有线程。
package com.demo.printABC;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class ThreeThreadPrintABC {
private static ReentrantLock lock = new ReentrantLock();
private static Condition wait = lock.newCondition();
// 用来控制该打印的线程
private static int count = 0;
static class PrintA implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
lock.lock();
try {
while ((count % 3) != 0) {
wait.await();
}
System.out.println(Thread.currentThread().getName() + " A");
count++;
wait.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
static class PrintB implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
lock.lock();
try {
while ((count % 3) != 1) {
wait.await();
}
System.out.println(Thread.currentThread().getName() + " B");
count++;
wait.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
static class PrintC implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
lock.lock();
try {
while ((count % 3) != 2) {
wait.await();
}
System.out.println(Thread.currentThread().getName() + " C");
count++;
wait.signalAll();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
public static void main(String[] args) {
Thread printA = new Thread(new PrintA());
Thread printB = new Thread(new PrintB());
Thread printC = new Thread(new PrintC());
printA.start();
printB.start();
printC.start();
}
}
运行结果:
Thread-0 A Thread-1 B Thread-2 C Thread-0 A Thread-1 B Thread-2 C Thread-0 A Thread-1 B Thread-2 C Thread-0 A Thread-1 B Thread-2 C
如果觉得不好理解,重入锁是可以绑定多个条件的。创建3个Condition分别让三个打印线程在上面等待。A打印完了,唤醒等待在conditionB对象上的PrintB;B打印完了唤醒在conditionC对象上的PrintC;C打印完了,唤醒在conditionA对象上等待的PrintA,如此循环地唤醒对方即可。
package com.demo.printABC;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class ThreeThreadPrintABC1 {
private static ReentrantLock lock = new ReentrantLock();
private static Condition conditionA = lock.newCondition();
private static Condition conditionB = lock.newCondition();
private static Condition conditionC = lock.newCondition();
// 用来控制该打印的线程
private static int count = 0;
static class PrintA implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
lock.lock();
try {
if (count % 3 != 0) {
conditionA.await();
}
System.out.println(Thread.currentThread().getName() + "------A");
count++;
conditionB.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
static class PrintB implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
lock.lock();
try {
if (count % 3 != 1) {
conditionB.await();
}
System.out.println(Thread.currentThread().getName() + "------B");
count++;
conditionC.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
static class PrintC implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
lock.lock();
try {
if (count % 3 != 2) {
conditionC.await();
}
System.out.println(Thread.currentThread().getName() + "------C");
count++;
conditionA.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
public static void main(String[] args) {
Thread printA = new Thread(new PrintA());
Thread printB = new Thread(new PrintB());
Thread printC = new Thread(new PrintC());
printA.start();
printB.start();
printC.start();
}
}
运行结果:
Thread-0------A Thread-1------B Thread-2------C Thread-0------A Thread-1------B Thread-2------C Thread-0------A Thread-1------B Thread-2------C Thread-0------A Thread-1------B Thread-2------C
另一种实现:
package com.demo.printABC;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
/**
* 基于一个ReentrantLock和三个conditon实现连续打印abcabc...
* @author lixiaoxi
*
*/
public class PrintABCTest implements Runnable {
// 打印次数
private static final int PRINT_COUNT = 10;
// 打印锁
private final ReentrantLock lock;
// 本线程打印所需的condition
private final Condition thisCondition;
// 下一个线程打印所需的condition
private final Condition nextCondition;
// 打印字符
private final char printChar;
public PrintABCTest(ReentrantLock lock, Condition thisCondition, Condition nextCondition, char printChar) {
this.lock = lock;
this.thisCondition = thisCondition;
this.nextCondition = nextCondition;
this.printChar = printChar;
}
@Override
public void run() {
// 获取打印锁 进入临界区
lock.lock();
try {
// 连续打印PRINT_COUNT次
for (int i = 0; i < PRINT_COUNT; i++) {
//打印字符
System.out.println(printChar);
// 使用nextCondition唤醒下一个线程
// 因为只有一个线程在等待,所以signal或者signalAll都可以
nextCondition.signal();
// 不是最后一次则通过thisCondtion等待被唤醒
// 必须要加判断,不然虽然能够打印10次,但10次后就会直接死锁
if (i < PRINT_COUNT -1) {
try {
// 本线程让出锁并等待唤醒
thisCondition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
} finally {
// 释放打印锁
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
// 写锁
ReentrantLock lock = new ReentrantLock();
// 打印a线程的condition
Condition conditionA = lock.newCondition();
// 打印b线程的condition
Condition conditionB = lock.newCondition();
// 打印c线程的condition
Condition conditionC = lock.newCondition();
// 实例化A线程
Thread printerA = new Thread(new PrintABCTest(lock, conditionA, conditionB, 'A'));
// 实例化B线程
Thread printerB = new Thread(new PrintABCTest(lock, conditionB, conditionC, 'B'));
// 实例化C线程
Thread printerC = new Thread(new PrintABCTest(lock, conditionC, conditionA, 'C'));
// 依次开始A B C线程
printerA.start();
Thread.sleep(100);
printerB.start();
Thread.sleep(100);
printerC.start();
}
}
运行结果:
A B C A B C A B C A B C
五、Mybatis
1、Mybatis的实现原理
mybatis底层还是采用原生jdbc来对数据库进行操作的,只是通过 SqlSessionFactory,SqlSession,Executor,StatementHandler,ParameterHandler,ResultHandler和TypeHandler等几个处理器封装了这些过程。其中StatementHandler用通过ParameterHandler与ResultHandler分别进行参数预编译与结果处理。而ParameterHandler与ResultHandler都使用TypeHandler进行映射。如下图:
2、Mybatis的工作过程
Mybatis的运行分为两部分,第一部分是读取配置文件缓存到Coufiguration对象,用以创建SqlSessionFactory,第二部分是SqlSession的执行过程。
初始化过程:
MyBatis的初始化的过程其实就是解析配置文件和初始化Configuration的过程,MyBatis的初始化过程可用以下几行代码来表述:
String resource = "mybatis.xml";
// 加载mybatis的配置文件(它也加载关联的映射文件)
InputStream inputStream = null;
try {
inputStream = Resources.getResourceAsStream(resource);
} catch (IOException e) {
e.printStackTrace();
}
// 构建sqlSession的工厂
sessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
MyBatis初始化基本过程总结如下:SqlSessionFactoryBuilder根据传入的数据流生成Configuration对象,然后根据Configuration对象创建默认的SqlSessionFactory实例。其中序列图如下:
上图的初始化过程经过以下的几步:
- 1. 调用SqlSessionFactoryBuilder对象的build(inputStream)方法;
- 2. SqlSessionFactoryBuilder会根据输入流inputStream等信息创建XMLConfigBuilder对象;
- 3. SqlSessionFactoryBuilder调用XMLConfigBuilder对象的parse()方法;
- 4. XMLConfigBuilder对象返回Configuration对象;
- 5. SqlSessionFactoryBuilder根据Configuration对象创建一个DefaultSessionFactory对象;
- 6. SqlSessionFactoryBuilder返回 DefaultSessionFactory对象给Client,供Client使用。
总结:MyBatis的初始化的过程其实就是解析配置文件和初始化Configuration的过程。首先把核心配置文件也就是mybatis.xml文件加载进来,然后调用SqlSessionFactoryBuilder对象的build(inputStream)方法,根据输入流inputStream等信息创建XMLConfigBuilder对象。XMLConfigBuilder对象再解析配置的XML文件,读取配置参数,并将读取的数据存入到Configuration类中。其次使用Configuration对象去创建SqlSessionFactory。
SqlSession的工作过程
1.开启一个数据库访问会话---创建SqlSession对象:MyBatis使用SQLSession对象来封装一次数据库的会话访问。通过该对象实现对事务的控制和数据查询。
SqlSession sqlSession = factory.openSession();
MyBatis封装了对数据库的访问,把对数据库的会话和事务控制放到了SqlSession对象中。
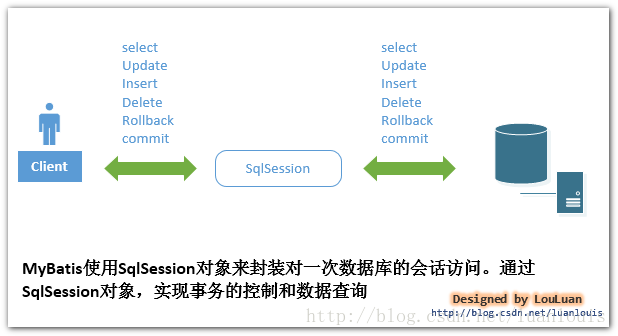
2.为SqlSession传递一个配置的Sql语句的StatementId和参数params,然后返回结果:
List<Employee> result = sqlSession.selectList("com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary",params);
上述的"com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary",是配置在EmployeesMapper.xml 的Statement ID,params 是传递的查询参数。
MyBatis在初始化的时候,会将MyBatis的配置信息全部加载到内存中,使用org.apache.ibatis.session.Configuration实例来维护。使用者可以使用sqlSession.getConfiguration()方法来获取。MyBatis的配置文件中配置信息的组织格式和内存中对象的组织格式几乎完全对应的。例如:
<select id="selectByMinSalary" resultMap="BaseResultMap" parameterType="java.util.Map" >
select
EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY
from LOUIS.EMPLOYEES
<if test="min_salary != null">
where SALARY < #{min_salary,jdbcType=DECIMAL}
</if>
</select>
加载到内存中会生成一个对应的MappedStatement对象,然后会以key="com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary" ,value为MappedStatement对象的形式维护到Configuration的一个Map中。当以后需要使用的时候,只需要通过Id值来获取就可以了。
从上述的代码中我们可以看到SqlSession的职能是:SqlSession根据Statement Id,在mybatis配置对象Configuration中获取到对应的MappedStatement对象,然后调用mybatis执行器来执行具体的操作。
3.MyBatis执行器Executor根据SqlSession传递的参数执行query()方法。Executor.query()方法会创建一个StatementHandler对象,然后将必要的参数传递给StatementHandler,使用StatementHandler来完成对数据库的查询,最终返回List结果集。
Executor的功能和作用是:
(1)、根据传递的参数,完成SQL语句的动态解析,生成BoundSql对象,供StatementHandler使用;
(2)、为查询创建缓存,以提高性能;
(3)、创建JDBC的Statement连接对象,传递给StatementHandler对象,返回List查询结果。
4.StatementHandler对象负责设置Statement对象中的查询参数、处理JDBC返回的resultSet,将resultSet加工为List 集合返回。
StatementHandler对象主要完成两个工作:
(1)、对于JDBC的PreparedStatement类型的对象,创建的过程中,SQL语句字符串会包含若干个'?'占位符,之后再对占位符进行设值。StatementHandler通过parameterize(statement)方法对Statement进行设值;
(2)、StatementHandler通过List<E> query(Statement statement, ResultHandler resultHandler)方法来完成执行Statement,和将Statement对象返回的resultSet封装成List。
5.StatementHandler 的parameterize(statement) 方法调用了 ParameterHandler的setParameters(statement)方法。
6.ParameterHandler的setParameters(Statement)方法负责 根据我们输入的参数,对statement对象的'?'占位符处进行赋值。StatementHandler 的List<E> query(Statement statement, ResultHandler resultHandler)方法调用了ResultSetHandler的handleResultSets(Statement) 方法。ResultSetHandler的handleResultSets(Statement) 方法会将Statement语句执行后生成的resultSet 结果集转换成List<E> 结果集。
主要过程:
1.DefaultSqlSession根据id在configuration中找到MappedStatement对象(要执行的语句)
2.Executor调用MappedStatement对象的getBoundSql得到可执行的sql和参数列表
3.StatementHandler根据Sql生成一个Statement
4.ParameterHandler为Statement设置相应的参数
5.Executor中执行sql语句
6.如果是更新(update/insert/delete)语句,sql的执行工作得此结束
7.如果是查询语句,ResultSetHandler再根据执行结果生成ResultMap相应的对象返回。
3、Mybatis的主要构件及其相互关系
从MyBatis代码实现的角度来看,MyBatis的主要的核心部件有以下几个:
- Configuration MyBatis所有的配置信息都保存在Configuration对象之中,配置文件中的大部分配置都会存储到该类中
- SqlSession 作为MyBatis工作的主要顶层API,表示和数据库交互时的会话,完成必要数据库增删改查功能
- Executor MyBatis执行器,是MyBatis 调度的核心,负责SQL语句的生成和查询缓存的维护
- StatementHandler 封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数等
- ParameterHandler 负责对用户传递的参数转换成JDBC Statement 所对应的数据类型
- ResultSetHandler 负责将JDBC返回的ResultSet结果集对象转换成List类型的集合
- TypeHandler 负责java数据类型和jdbc数据类型(也可以说是数据表列类型)之间的映射和转换
- MappedStatement MappedStatement维护一条<select|update|delete|insert>节点的封装。Mapped Statement也是mybatis一个底层封装对象,它包装了 mybatis配置信息及sql映射信息等。mapper.xml文件中一个sql对应一个Mapped Statement对象,sql的id即是Mapped statement的id。
- SqlSource 负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回
- BoundSql 表示动态生成的SQL语句以及相应的参数信息
它们的关系如下图所示:
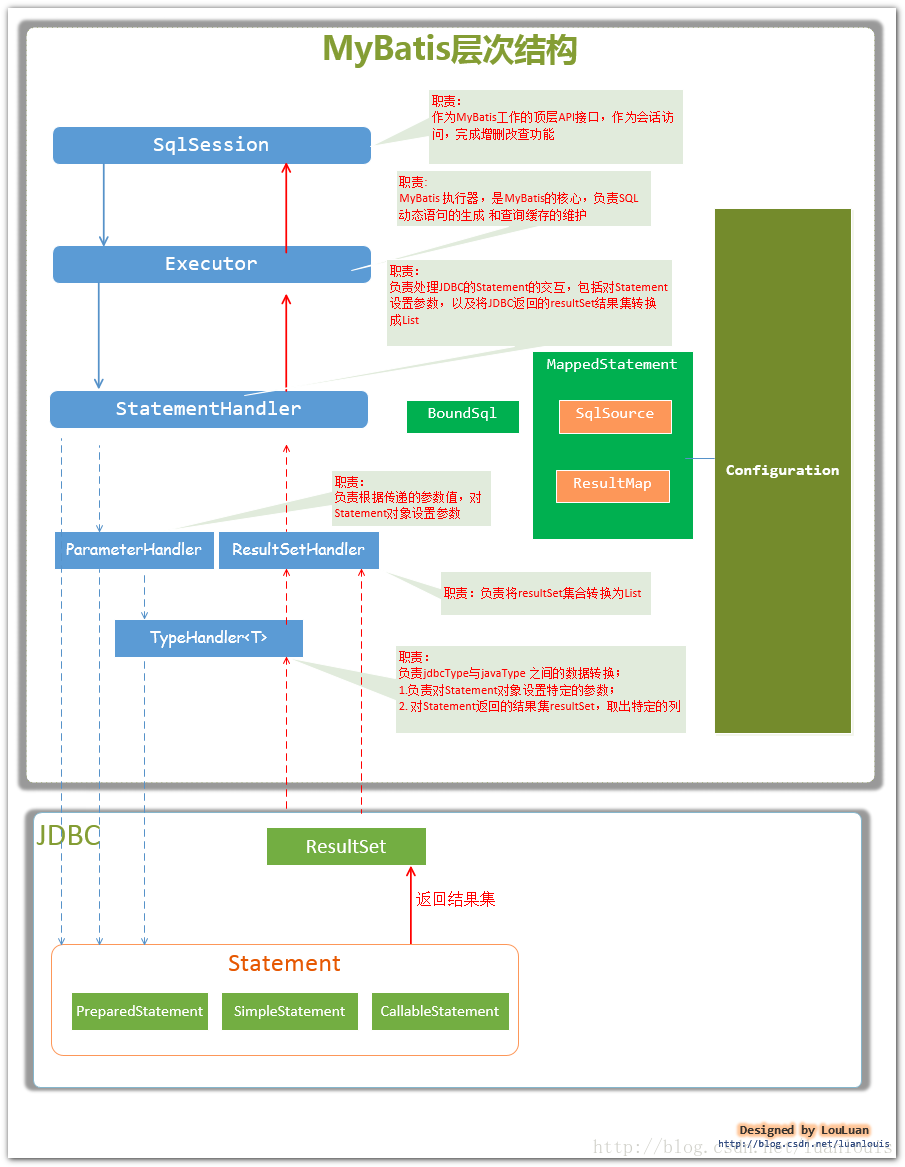
4、Mybatis和数据库的交互方式
(1)使用传统的MyBatis提供的API
这是传统的传递Statement Id 和查询参数给 SqlSession 对象,使用 SqlSession对象完成和数据库的交互;MyBatis 提供了非常方便和简单的API,供用户实现对数据库的增删改查数据操作,以及对数据库连接信息和MyBatis 自身配置信息的维护操作。

上述使用MyBatis 的方法,是创建一个和数据库打交道的SqlSession对象,然后根据Statement Id 和参数来操作数据库,这种方式固然很简单和实用,但是它不符合面向对象语言的概念和面向接口编程的编程习惯。由于面向接口的编程是面向对象的大趋势,MyBatis 为了适应这一趋势,增加了第二种使用MyBatis支持接口(Interface)调用方式。
(2)使用Mapper接口
MyBatis 将配置文件中的每一个<mapper> 节点抽象为一个 Mapper 接口,而这个接口中声明的方法和跟<mapper> 节点中的<select|update|delete|insert> 节点相对应,即<select|update|delete|insert> 节点的id值为Mapper 接口中的方法名称,parameterType 值表示Mapper 对应方法的入参类型,而resultMap 值则对应了Mapper 接口表示的返回值类型或者返回结果集的元素类型。
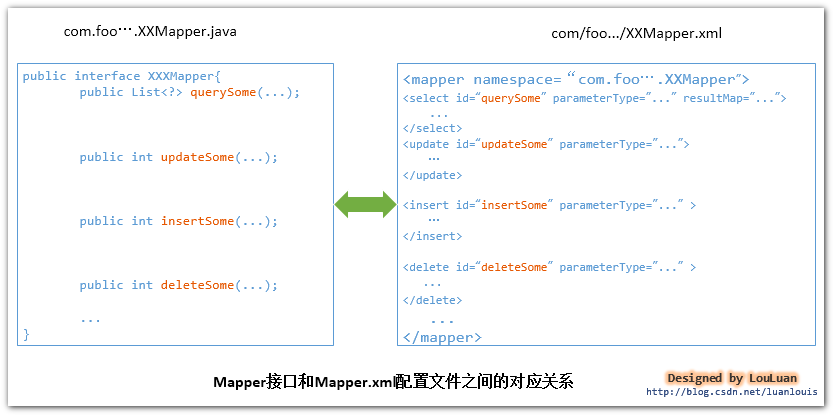
根据MyBatis 的配置规范配置好后,通过SqlSession.getMapper(XXXMapper.class) 方法,MyBatis 会根据相应的接口声明的方法信息,通过动态代理机制生成一个Mapper 实例,我们使用Mapper 接口的某一个方法时,MyBatis 会根据这个方法的方法名和参数类型,确定Statement Id,底层还是通过SqlSession.select("statementId",parameterObject);或者SqlSession.update("statementId",parameterObject); 等等来实现对数据库的操作。
MyBatis 引用Mapper 接口这种调用方式,纯粹是为了满足面向接口编程的需要。(其实还有一个原因是在于,面向接口的编程,使得用户在接口上可以使用注解来配置SQL语句,这样就可以脱离XML配置文件,实现“0配置”)。
5、#{} 和 ${}的区别是什么?
#{}是sql的参数占位符,Mybatis会将sql中的#{}替换为?号,在sql执行前会使用PreparedStatement的参数设置方法,按序给sql的?号占位符设置参数值,比如
PreparedStatement ps = conn.prepareStatement(sql); ps.setInt(1,id);
这样做的好处是:更安全,更迅速,通常也是首选做法。#{item.name}的取值方式为使用反射从参数对象中获取item对象的name属性值,相当于param.getItem().getName()。
${}是Properties文件中的变量占位符,它可以用于标签属性值和sql内部,属于静态文本替换,比如${driver}会被静态替换为com.mysql.jdbc.Driver。
(1)#相当于对数据加上双引号,$相当于直接显示数据。
(2) #将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by "111",如果传入的值是id,则解析成的sql为order by "id"。
(3)$将传入的数据直接显示生成在sql中。如:order by $user_id$,如果传入的值是111,那么解析成sql时的值为order by 111,如果传入的值是id,则解析成的sql为order by id。
(4)#方式能够很大程度防止sql注入,$方式无法防止Sql注入。
(5)$方式一般用于传入数据库对象,例如传入表名。
(6)一般能用#的就别用$。
(7)MyBatis排序时使用order by 动态参数时需要注意,用$而不是#。
默认情况下,使用#{}格式的语法会导致MyBatis创建预处理语句属性并以它为背景设置安全的值(比如?)。这样做很安全,很迅速也是首选做法,有时你只是想直接在SQL语句中插入一个不改变的字符串。比如,像ORDER BY,你可以这样来使用:ORDER BY ${columnName} 这里MyBatis不会修改或转义字符串。
(1)先上结论
#{}:占位符号,好处防止sql注入
${}:sql拼接符号
(2)具体分析
动态 SQL 是 mybatis 的强大特性之一,也是它优于其他 ORM 框架的一个重要原因。mybatis 在对 sql 语句进行预编译之前,会对 sql 进行动态解析,解析为一个 BoundSql 对象,也是在此处对动态 SQL 进行处理的。在动态 SQL 解析阶段, #{ } 和 ${ } 会有不同的表现。
#{ }:解析为一个 JDBC 预编译语句(prepared statement)的参数标记符。例如,Mapper.xml中如下的 sql 语句:
select * from user where name = #{name};
动态解析为:
select * from user where name = ?;
一个 #{ } 被解析为一个参数占位符 ? ,而${ } 仅仅为一个纯碎的 string 替换,在动态 SQL 解析阶段将会进行变量替换。
例如,Mapper.xml中如下的 sql:
select * from user where name = ${name};
当我们传递的参数为 "Jack" 时,上述 sql 的解析为:
select * from user where name = "Jack";
预编译之前的 SQL 语句已经不包含变量了,完全已经是常量数据了。 综上所得, ${ } 变量的替换阶段是在动态 SQL 解析阶段,而 #{ }变量的替换是在 DBMS 中。
(3)用法
1、能使用 #{ } 的地方就用 #{ }
首先这是为了性能考虑的,相同的预编译 sql 可以重复利用。其次,${ } 在预编译之前已经被变量替换了,这会存在 sql 注入问题。例如,如下的 sql:
select * from ${tableName} where name = #{name}
假如,我们的参数 tableName 为 user; delete user; --,那么 SQL 动态解析阶段之后,预编译之前的 sql 将变为:
select * from user; delete user; -- where name = ?;
-- 之后的语句将作为注释,不起作用,因此本来的一条查询语句偷偷的包含了一个删除表数据的 SQL。
2、表名作为变量时,必须使用 ${ }
这是因为,表名是字符串,使用 sql 占位符替换字符串时会带上单引号 '',这会导致 sql 语法错误,例如:
select * from #{tableName} where name = #{name};
预编译之后的sql 变为:
select * from ? where name = ?;
假设我们传入的参数为 tableName = "user" , name = "Jack",那么在占位符进行变量替换后,sql 语句变为:
select * from 'user' where name='Jack';
上述 sql 语句是存在语法错误的,表名不能加单引号 ''(注意,反引号 ``是可以的)。
(4)sql预编译
1、定义:
sql 预编译指的是数据库驱动在发送 sql 语句和参数给 DBMS 之前对 sql 语句进行编译,这样 DBMS 执行 sql 时,就不需要重新编译。
2、为什么需要预编译
JDBC 中使用对象 PreparedStatement 来抽象预编译语句,使用预编译。预编译阶段可以优化 sql 的执行。预编译之后的 sql 多数情况下可以直接执行,DBMS 不需要再次编译,越复杂的sql,编译的复杂度将越大,预编译阶段可以合并多次操作为一个操作。预编译语句对象可以重复利用。把一个 sql 预编译后产生的 PreparedStatement 对象缓存下来,下次对于同一个sql,可以直接使用这个缓存的 PreparedState 对象。mybatis 默认情况下,将对所有的 sql 进行预编译。
6、最佳实践中,通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。在Mybatis中,每一个<select>、<insert>、<update>、<delete>标签,都会被解析为一个MappedStatement对象。
Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
7、使用Mybatis的mapper接口调用时有哪些要求?
① Mapper接口方法名和mapper.xml中定义的每个sql的id相同
② Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
③ Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
④ Mapper.xml文件中的namespace即是mapper接口的类路径。
8、Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
举例:select * from student,拦截sql后重写为:select t.* from (select * from student)t limit 0,10
9、简述Mybatis的插件运行原理,以及如何编写一个插件。
Mybatis仅可以编写针对ParameterHandler、ResultSetHandler、StatementHandler、Executor这4种接口的插件,Mybatis使用JDK的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这4种接口对象的方法时,就会进入拦截方法,具体就是InvocationHandler的invoke()方法,当然,只会拦截那些你指定需要拦截的方法。
实现Mybatis的Interceptor接口并复写intercept()方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
10、Mybatis动态sql是做什么的?都有哪些动态sql?能简述一下动态sql的执行原理不?
Mybatis动态sql可以让我们在Xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能。总体说来mybatis 动态SQL 语句主要有以下几类:
1. if 语句 (简单的条件判断)
2. choose (when,otherwize) ,相当于java 语言中的 switch ,与 jstl 中的choose 很类似.
3. trim (对包含的内容加上 prefix,或者 suffix 等,前缀,后缀)
4. where (主要是用来简化sql语句中where条件判断的,能智能的处理 and or ,不必担心多余导致语法错误)
5. set (主要用于更新时)
6. foreach (在实现 mybatis in 语句查询时特别有用)
下面分别介绍这几种处理方式
1、mybatis if语句处理
<select id="dynamicIfTest" parameterType="Blog" resultType="Blog">
select * from t_blog where 1 = 1
<if test="title != null">
and title = #{title}
</if>
<if test="content != null">
and content = #{content}
</if>
<if test="owner != null">
and owner = #{owner}
</if>
</select>
解析:
如果你提供了title参数,那么就要满足title=#{title},同样如果你提供了Content和Owner的时候,它们也需要满足相应的条件,之后就是返回满足这些条件的所有Blog,这是非常有用的一个功能。
以往我们使用其他类型框架或者直接使用JDBC的时候, 如果我们要达到同样的选择效果的时候,我们就需要拼SQL语句,这是极其麻烦的,比起来,上述的动态SQL就要简单多了。
2、choose (when,otherwize) ,相当于java 语言中的 switch ,与 jstl 中的choose 很类似
<select id="dynamicChooseTest" parameterType="Blog" resultType="Blog">
select * from t_blog where 1 = 1
<choose>
<when test="title != null">
and title = #{title}
</when>
<when test="content != null">
and content = #{content}
</when>
<otherwise>
and owner = "owner1"
</otherwise>
</choose>
</select>
when元素表示当when中的条件满足的时候就输出其中的内容,跟JAVA中的switch效果差不多的是按照条件的顺序,当when中有条件满足的时候,就会跳出choose,即所有的when和otherwise条件中,只有一个会输出,当所有的我很条件都不满足的时候就输出otherwise中的内容。所以上述语句的意思非常简单,当title!=null的时候就输出and titlte = #{title},不再往下判断条件,当title为空且content!=null的时候就输出and content = #{content},当所有条件都不满足的时候就输出otherwise中的内容。
3、trim (对包含的内容加上 prefix,或者 suffix 等,前缀,后缀)
<select id="dynamicTrimTest" parameterType="Blog" resultType="Blog">
select * from t_blog
<trim prefix="where" prefixOverrides="and |or">
<if test="title != null">
title = #{title}
</if>
<if test="content != null">
and content = #{content}
</if>
<if test="owner != null">
or owner = #{owner}
</if>
</trim>
</select>
trim元素的主要功能是可以在自己包含的内容前加上某些前缀,也可以在其后加上某些后缀,与之对应的属性是prefix和suffix;可以把包含内容的首部某些内容覆盖,即忽略,也可以把尾部的某些内容覆盖,对应的属性是prefixOverrides和suffixOverrides;正因为trim有这样的功能,所以我们也可以非常简单的利用trim来代替where元素的功能。
trim标记是一个格式化的标记,可以完成set或者是where标记的功能,如下代码:
select * from user
<trim prefix="WHERE" prefixoverride="AND |OR">
<if test="name != null and name.length()>0">
AND name=#{name}
</if>
<if test="gender != null and gender.length()>0">
AND gender=#{gender}
</if>
</trim>
假如说name和gender的值都不为null的话打印的SQL为:select * from user where name = 'xx' and gender = 'xx'
在红色标记的地方是不存在第一个and的,上面两个属性的意思如下:
prefix:前缀
prefixoverride:去掉第一个and或者是or
update user
<trim prefix="set" suffixoverride="," suffix=" where id = #{id} ">
<if test="name != null and name.length()>0">
name=#{name} ,
</if>
<if test="gender != null and gender.length()>0">
gender=#{gender} ,
</if>
</trim>
假如说name和gender的值都不为null的话打印的SQL为:update user set name='xx' , gender='xx' where id='x'
在红色标记的地方不存在逗号,而且自动加了一个set前缀和where后缀,上面三个属性的意义如下,其中prefix意义如上:
suffixoverride:去掉最后一个逗号(也可以是其他的标记,就像是上面前缀中的and一样)
suffix:后缀
4、where (主要是用来简化sql语句中where条件判断的,能智能的处理 and or 条件)
<select id="dynamicWhereTest" parameterType="Blog" resultType="Blog">
select * from t_blog
<where>
<if test="title != null">
title = #{title}
</if>
<if test="content != null">
and content = #{content}
</if>
<if test="owner != null">
and owner = #{owner}
</if>
</where>
</select>
where元素的作用是会在写入where元素的地方输出一个where,另外一个好处是你不需要考虑where元素里面的条件输出是什么样子的,MyBatis会智能的帮你处理,如果所有的条件都不满足那么MyBatis就会查出所有的记录,如果输出后是and 开头的,MyBatis会把第一个and忽略,当然如果是or开头的,MyBatis也会把它忽略;此外,在where元素中你不需要考虑空格的问题,MyBatis会智能的帮你加上。像上述例子中,如果title=null, 而content != null,那么输出的整个语句会是select * from t_blog where content = #{content},而不是select * from t_blog where and content = #{content},因为MyBatis会智能的把首个and 或 or 给忽略。
5、set (主要用于更新时)
<update id="dynamicSetTest" parameterType="Blog">
update t_blog
<set>
<if test="title != null">
title = #{title},
</if>
<if test="content != null">
content = #{content},
</if>
<if test="owner != null">
owner = #{owner}
</if>
</set>
where id = #{id}
</update>
set元素主要是用在更新操作的时候,它的主要功能和where元素其实是差不多的,主要是在包含的语句前输出一个set,然后如果包含的语句是以逗号结束的话将会把该逗号忽略,如果set包含的内容为空的话则会出错。有了set元素我们就可以动态的更新那些修改了的字段。
6、foreach (在实现 mybatis in 语句查询时特别有用)
foreach的主要用在构建in条件中,它可以在SQL语句中进行迭代一个集合。foreach元素的属性主要有item,index,collection,open,separator,close。
(1)item表示集合中每一个元素进行迭代时的别名。
(2)index指定一个名字,用于表示在迭代过程中,每次迭代到的位置。
(3)open表示该语句以什么开始。
(4)separator表示在每次进行迭代之间以什么符号作为分隔符。
(5)close表示以什么结束。
在使用foreach的时候最关键的也是最容易出错的就是collection属性,该属性是必须指定的,但是在不同情况下,该属性的值是不一样的,主要有一下3种情况:
(1)如果传入的是单参数且参数类型是一个List的时候,collection属性值为list
(2)如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array
(3)如果传入的参数是多个的时候,我们就需要把它们封装成一个Map了,当然单参数也可以封装成map,实际上如果你在传入参数的时候,在MyBatis里面也是会把它封装成一个Map的,map的key就是参数名,所以这个时候collection属性值就是传入的List或array对象在自己封装的map里面的key。
1、单参数List的类型
<select id="dynamicForeachTest" resultType="com.mybatis.entity.User">
select * from t_user where id in
<foreach collection="list" index="index" item="item" open="(" separator="," close=")">
#{item}
</foreach>
</select>
上述collection的值为list,对应的Mapper是这样的:
/**mybatis Foreach测试 */ public List<User> dynamicForeachTest(List<Integer> ids);
测试:
@Test
public void dynamicForeachTest() {
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<Integer> ids = new ArrayList<Integer>();
ids.add(1);
ids.add(2);
ids.add(6);
List<User> userList = mapper.dynamicForeachTest(ids);
for (User user : userList){
System.out.println(user);
}
sqlSession.close();
}
2、数组类型的参数
<select id="dynamicForeach2Test" resultType="com.mybatis.entity.User">
select * from t_user where id in
<foreach collection="array" index="index" item="item" open="(" separator="," close=")">
#{item}
</foreach>
</select>
对应mapper:
public List<User> dynamicForeach2Test(int[] ids);
测试:
@Test
public void dynamicForeach2Test() {
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
int[] ids = {1,2,6};
List<User> userList = mapper.dynamicForeach2Test(ids);
for (User user : userList){
System.out.println(user);
}
sqlSession.close();
}
3、Map类型的参数
<select id="dynamicForeach3Test" resultType="com.mybatis.entity.User">
select * from t_user where username like '%${username}%' and id in
<foreach collection="ids" index="index" item="item" open="(" separator="," close=")">
#{item}
</foreach>
</select>
mapper 应该是这样的接口:
/**mybatis Foreach测试 */ public List<User> dynamicForeach3Test(Map<String, Object> params);
测试:
@Test
public void dynamicForeach3Test() {
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<Integer> ids = new ArrayList<Integer>();
ids.add(1);
ids.add(2);
ids.add(6);
Map map =new HashMap();
map.put("username", "小");
map.put("ids", ids);
List<User> userList = mapper.dynamicForeach3Test(map);
System.out.println("------------------------");
for (User user : userList){
System.out.println(user);
}
sqlSession.close();
}
mybatis的动态sql的执行原理为,使用OGNL从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql,以此来完成动态sql的功能。
11、mybatis中resultType和resultMap使用时的区别
MyBatis中关于resultType和resultMap的具体区别如下:
MyBatis中在查询进行select映射的时候,返回类型可以用resultType,也可以用resultMap,resultType是直接表示返回类型的(对应着我们的model对象中的实体),而resultMap则是对外部ResultMap的引用(提前定义了db和model之间的隐射key-->value关系),但是resultType跟resultMap不能同时存在。
在MyBatis进行查询映射时,其实查询出来的每一个属性都是放在一个对应的Map里面的,其中键是列名,值则是其对应的值。
1.当提供的返回类型属性是resultType时,MyBatis会将Map里面的键值对取出赋给resultType所指定的对象对应的属性。所以其实MyBatis的每一个查询映射的返回类型都是ResultMap,只是当提供的返回类型属性是resultType的时候,MyBatis会自动把对应的值赋给resultType所指定对象的属性。
2.当提供的返回类型是resultMap时,因为Map不能很好表示领域模型,就需要自己再进一步的把它转化为对应的对象,这常常在复杂查询中很有作用。
(1)resultType可以映射结果集为基本类型的,而resultMap不能映射结果集为基本类型。
(2)使用resultType进行输出映射,只有查询出来的列名和pojo中的属性名一致,该列才可以映射成功。如果查询出来的列名和pojo中的属性名全部不一致,没有创建pojo对象。只要查询出来的列名和pojo中的属性有一个一致,就会创建pojo对象。对于列名和属性名不一致的情况,就需要通过resultMap来解决。即用resultType进行输出映射,只有查询出来的列名和pojo中的属性名一致,该列才可以映射成功。如果查询出来的列名和pojo的属性名不一致,通过定义一个resultMap对列名和pojo属性名之间作一个映射关系。
(3)resultType 通常用于接收基本类型,包装类型的结果集映射(包装类型的时候就有要求了,必须包装类型中的属性值跟查询结果的字段对应的上,否则的话对应不上的属性是接收不到查询结果的)。而resultMap用于解决复杂查询时的映射问题。比如:列名和对象属性名不一致时可以使用resultMap来配置;还有查询的对象中包含其他的对象等。
(4)resultMap可以实现延迟加载,resultType无法实现延迟加载。
12、Mybatis中的一对一、一对多查询
一对一查询:
a.resultType:使用resultType实现较为简单,如果pojo中没有包括查询出来的列名,需要增加列名对应的属性,即可完成映射。
b.如果没有查询结果的特殊要求建议使用resultType。
c.resultMap:需要单独定义resultMap,实现有点麻烦,如果对查询结果有特殊的要求,使用resultMap可以完成将关联查询映射pojo的属性中。
d.resultMap可以实现延迟加载,resultType无法实现延迟加载。
在一对一结果映射时,使用resultType更加简单方便,如果有特殊要求(对象嵌套对象)时,需要使用resultMap进行映射,比如:查询订单列表,然后在点击列表中的查看订单明细按钮,这个时候就需要使用resultMap进行结果映射。而resultType更适用于查询明细信息,比如,查询订单明细列表。
一对多查询(例如查询订单及订单明细):
mybatis使用resultMap的collection对关联查询的多条记录映射到一个list集合属性中。
而使用resultType实现:将订单明细映射到orders中的orderdetails中,需要自己处理,使用双重循环遍历,去掉重复记录,将订单明细放在orderdetails中。
总结:
resultType:
作用:将查询结果按照sql列名pojo属性名一致性映射到pojo中。
场合:常见一些明细记录的展示,比如用户购买商品明细,将关联查询信息全部展示在页面时,此时可直接使用resultType将每一条记录映射到pojo中,在前端页面遍历list(list中是pojo)即可。
resultMap:
使用association和collection完成一对一和一对多高级映射(对结果有特殊的映射要求)。
association:
作用:将关联查询信息映射到一个pojo对象中。
场合:为了方便查询关联信息可以使用association将关联订单信息映射为用户对象的pojo属性中,比如:查询订单及关联用户信息。使用resultType无法将查询结果映射到pojo对象的pojo属性中,根据对结果集查询遍历的需要选择使用resultType还是resultMap。
collection:
作用:将关联查询信息映射到一个list集合中。
场合:为了方便查询遍历关联信息可以使用collection将关联信息映射到list集合中,比如:查询用户权限范围模块及模块下的菜单,可使用collection将模块映射到模块list中,将菜单列表映射到模块对象的菜单list属性中,这样的作的目的也是方便对查询结果集进行遍历查询。如果使用resultType无法将查询结果映射到list集合中。
13、Mybatis缓存
MyBatis 提供了查询缓存来缓存数据,以提高查询的性能。MyBatis 的缓存分为一级缓存和二级缓存。
1、一级缓存是sqlSession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构(HashMap),用于存储缓存数据。不同的sqlSession之间的缓存区域(HashMap)是互不影响的。
2、二级缓存是mapper级别的缓存,多个sqlSession去操作同一个Mapper的sql语句,多个SqlSession可以公用二级缓存,二级缓存是跨sqlSession的。
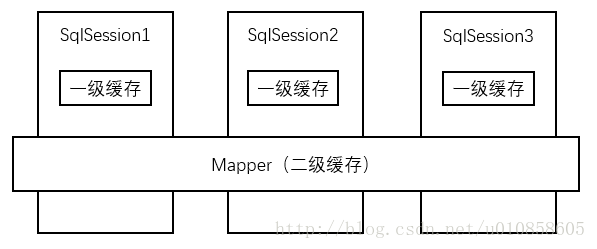
一级缓存
一级缓存是 SqlSession 级别的缓存,是基于 HashMap 的本地缓存。不同的 SqlSession 之间的缓存数据区域互不影响。
一级缓存的作用域是 SqlSession 范围,当同一个 SqlSession 执行两次相同的 sql 语句时,第一次执行完后会将数据库中查询的数据写到缓存,第二次查询时直接从缓存获取不用去数据库查询。当 SqlSession 执行 insert、update、delete 操做并提交到数据库时,会清空缓存,保证缓存中的信息是最新的。
MyBatis默认开启一级缓存。
注意事项:
1.如果SqlSession执行了DML操作(insert、update、delete),并commit了,那么mybatis就会清空当前SqlSession缓存中的所有缓存数据,这样可以保证缓存中的存的数据永远和数据库中一致,避免出现脏读。
2.当一个SqlSession结束后那么他里面的一级缓存也就不存在了,mybatis默认是开启一级缓存,不需要配置。
3.mybatis的缓存是基于[namespace:sql语句:参数]来进行缓存的,意思就是,SqlSession的HashMap存储缓存数据时,是使用[namespace:sql:参数]作为key,查询返回的语句作为value保存的。
二级缓存
二级缓存是 mapper 级别的缓存,同样是基于 HashMap 进行存储,多个 SqlSession 可以共用二级缓存,其作用域是 mapper 的同一个 namespace。不同的 SqlSession 两次执行相同的 namespace 下的 sql 语句,会执行相同的 sql,第二次查询只会查询第一次查询时读取数据库后写到缓存的数据,不会再去数据库查询。
MyBatis 默认没有开启二级缓存,开启只需在配置文件中写入如下代码:
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
注意事项:
1.如果SqlSession执行了DML操作(insert、update、delete),并commit了,那么mybatis就会清空当前mapper缓存中的所有缓存数据,这样可以保证缓存中的存的数据永远和数据库中一致,避免出现脏读
2.mybatis的缓存是基于[namespace:sql语句:参数]来进行缓存的,意思就是,SqlSession的HashMap存储缓存数据时,是使用[namespace:sql:参数]作为key,查询返回的语句作为value保存的。
总结:
1、一级缓存: 基于PerpetualCache 的 HashMap本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该Session中的所有 Cache 就将清空。
2、二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。
3、对于缓存数据更新机制,当某一个作用域(一级缓存Session/二级缓存Namespaces)的进行了 C/U/D 操作后,默认该作用域下所有 select 中的缓存将被clear。
14、Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
15、为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半自动ORM映射工具。
六、MySQL
B+Tree的定义
B+Tree是B树的变种,有着比B树更高的查询性能,来看下m阶B+Tree特征:
(1)有m个子树的节点包含有m个元素(B-Tree中是m-1)。
(2)根节点和分支节点中不保存数据,只用于索引,所有数据都保存在叶子节点中。
(3)所有分支节点和根节点都同时存在于子节点中,在子节点元素中是最大或者最小的元素。
(4)叶子节点会包含所有的关键字,以及指向数据记录的指针,并且叶子节点本身是根据关键字的大小从小到大顺序链接。
B+Tree相对于B-Tree有几点不同:
(1)非叶子节点只存储键值信息。
(2)所有叶子节点之间都有一个链指针。
(3)数据记录都存放在叶子节点中。
作为B树的加强版,B+树与B树的差异在于
(1)有n棵子树的节点含有n个关键字(也有认为是n-1个关键字)
(2)所有的叶子节点包含了全部的关键字,及指向含这些关键字记录的指针,且叶子节点本身根据关键字自小而大顺序连接
(3)非叶子节点可以看成索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字
数据库为什么要用B+树结构?
为什么使用B+树?言简意赅,就是因为:
(1)索引文件很大,不可能全部存储在内存中,故要存储到磁盘上
(2)索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数(为什么使用B-/+Tree,还跟磁盘存取原理有关。)
(3)局部性原理与磁盘预读,预读的长度一般为页(page)的整倍数,(在许多操作系统中,页得大小通常为4k)。
(4)数据库系统巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入,(由于节点中有两个数组,所以地址连续)。而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。
对于B-Tree而言,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。B树的每个节点可以存储多个关键字,它将节点大小设置为磁盘页的大小,充分利用了磁盘预读的功能。每次读取磁盘页时就会读取一整个节点。也正因每个节点存储着非常多个关键字,树的深度就会非常的小。进而要执行的磁盘读取操作次数就会非常少,更多的是在内存中对读取进来的数据进行查找。
为什么红黑树不适合做索引?
红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。也就是说,使用红黑树(平衡二叉树)结构的话,每次磁盘预读中的很多数据是用不上的数据。因此,它没能利用好磁盘预读的提供的数据。然后又由于深度大(较B树而言),所以进行的磁盘IO操作更多。
B树的查询,主要发生在内存中,而平衡二叉树的查询,则是发生在磁盘读取中。因此,虽然B树查询查询的次数不比平衡二叉树的次数少,但是相比起磁盘IO速度,内存中比较的耗时就可以忽略不计了。因此,B树更适合作为索引。
比B树更适合作为索引的结构——B+树
比B树更适合作为索引的结构是B+树。MySQL中也是使用B+树作为索引。它是B树的变种,因此是基于B树来改进的。为什么B+树会比B树更加优秀呢?
B树:有序数组+平衡多叉树;
B+树:有序数组链表+平衡多叉树;
从B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
B+树的关键字全部存放在叶子节点中,非叶子节点用来做索引,而叶子节点中有一个指针指向一下个叶子节点。做这个优化的目的是为了提高区间访问的性能。而正是这个特性决定了B+树更适合用来存储外部数据。
数据库索引采用B+树的主要原因是B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
B+树的优势
(1)单节点可以存储更多的元素,使得查询磁盘IO次数更少。首先B+树的中间节点不存储数据,所以同样大小的磁盘页可以容纳更多的节点元素,如此一来,相同数量的数据下,B+树就相对来说要更加矮胖些,磁盘IO的次数更少。
(2)所有查询都要查找到叶子节点,查询性能稳定。由于只有叶子节点才保存数据,B+树每次查询都要到叶子节点;而B树每次查询则不一样,最好的情况是根节点,最坏的情况是叶子节点,没有B+树稳定。
(3)所有叶子节点形成有序链表,便于范围查询。
servlet的生命周期
Servlet运行在Servlet容器中,其生命周期由容器来管理。Servlet的生命周期通过javax.servlet.Servlet接口中的init()、service()和destroy()方法来表示。
Servlet的生命周期包含了下面4个阶段:
(1)加载和实例化
Servlet容器负责加载和实例化Servlet。当Servlet容器启动时,或者在容器检测到需要这个Servlet来响应第一个请求时,创建Servlet实例。当Servlet容器启动后,它必须要知道所需的Servlet类在什么位置,Servlet容器可以从本地文件系统、远程文件系统或者其他的网络服务中通过类加载器加载Servlet类,成功加载后,容器创建Servlet的实例。因为容器是通过Java的反射API来创建Servlet实例,调用的是Servlet的默认构造方法(即不带参数的构造方法),所以我们在编写Servlet类的时候,不应该提供带参数的构造方法。
(2)初始化
在Servlet实例化之后,容器将调用Servlet的init()方法初始化这个对象。初始化的目的是为了让Servlet对象在处理客户端请求前完成一些初始化的工作,如建立数据库的连接,获取配置信息等。对于每一个Servlet实例,init()方法只被调用一次。在初始化期间,Servlet实例可以使用容器为它准备的ServletConfig对象从Web应用程序的配置信息(在web.xml中配置)中获取初始化的参数信息。在初始化期间,如果发生错误,Servlet实例可以抛出ServletException异常或者UnavailableException异常来通知容器。ServletException异常用于指明一般的初始化失败,例如没有找到初始化参数;而UnavailableException异常用于通知容器该Servlet实例不可用。例如,数据库服务器没有启动,数据库连接无法建立,Servlet就可以抛出UnavailableException异常向容器指出它暂时或永久不可用。
(3)请求处理
Servlet容器调用Servlet的service()方法对请求进行处理。service()方法为Servlet的核心方法,客户端的业务逻辑应该在该方法内执行,典型的服务方法的开发流程为:解析客户端请求-〉执行业务逻辑-〉输出响应页面到客户端。要注意的是,在service()方法调用之前,init()方法必须成功执行。在service()方法中,Servlet实例通过ServletRequest对象得到客户端的相关信息和请求信息,在对请求进行处理后,调用ServletResponse对象的方法设置响应信息。在service()方法执行期间,如果发生错误,Servlet实例可以抛出ServletException异常或者UnavailableException异常。如果UnavailableException异常指示了该实例永久不可用,Servlet容器将调用实例的destroy()方法,释放该实例。此后对该实例的任何请求,都将收到容器发送的HTTP 404(请求的资源不可用)响应。如果UnavailableException异常指示了该实例暂时不可用,那么在暂时不可用的时间段内,对该实例的任何请求,都将收到容器发送的HTTP 503(服务器暂时忙,不能处理请求)响应。
(4)服务终止
当容器检测到一个Servlet实例应该从服务中被移除的时候,容器就会调用实例的destroy()方法,以便让该实例可以释放它所使用的资源,保存数据到持久存储设备中。当需要释放内存或者容器关闭时,容器就会调用Servlet实例的destroy()方法。在destroy()方法调用之后,容器会释放这个Servlet实例,该实例随后会被Java的垃圾收集器所回收。如果再次需要这个Servlet处理请求,Servlet容器会创建一个新的Servlet实例。
在整个Servlet的生命周期过程中,创建Servlet实例、调用实例的init()和destroy()方法都只进行一次,当初始化完成后,Servlet容器会将该实例保存在内存中,通过调用它的service()方法,为接收到的请求服务。
总结:web容器加载servlet,生命周期开始。通过调用servlet的init() 方法进行servlet的初始化。通过调用service() 方法实现,根据请求的不同调用不同的do***() 方法。结束服务,web容器调用servlet 的 destory() 方法。
设计模式
1、单例模式
单例模式,它的定义就是确保某一个类只有一个实例,并且提供一个全局访问点。
单例模式具备典型的3个特点:1、只有一个实例。 2、自我实例化。 3、提供全局访问点。
因此当系统中只需要一个实例对象或者系统中只允许一个公共访问点,除了这个公共访问点外,不能通过其他访问点访问该实例时,可以使用单例模式。
单例模式的主要优点就是节约系统资源、提高了系统效率,同时也能够严格控制客户对它的访问。也许就是因为系统中只有一个实例,这样就导致了单例类的职责过重,违背了“单一职责原则”,同时也没有抽象类,所以扩展起来有一定的困难。
实现方式
JSP和Servlet有哪些相同点和不同点,他们之间的联系是什么?
JSP是Servlet技术的扩展,本质上是Servlet的简易方式,更强调应用的外表表达。JSP 编译后是"类servlet"。Servlet和JSP最主要的不同点在于,Servlet的应用逻辑是在Java文件中,并且完全从表示层中的HTML 里分离开来。而JSP的情况是Java和HTML可以组合成一个扩展名为.jsp的文件。JSP侧重于视图,Servlet主要用于控制逻辑。
3、Hashcode的作用,与 equals 有什么区别
同样用于鉴定2个对象是否相等的,java集合中有 list 和 set 两类,其中 set不允许元素重复出现,那么这个不允许重复出现的方法,如果用 equals 去比较的话,如果存在1000个元素,你 new 一个新的元素出来,需要去调用1000次 equals 去逐个和他们比较是否是同一个对象,这样会大大降低效率。hashcode实际上是返回对象的存储地址,如果这个位置上没有元素,就把元素直接存储在上面,如果这个位置上已经存在元素,这个时候才去调用equals方法与新元素进行比较,相同的话就不存了,散列到其他地址上。
4、String、StringBuffer与StringBuilder的区别
String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象。
StringBuffer和StringBuilder底层是 char[]数组实现的。
StringBuffer是线程安全的,而StringBuilder是线程不安全的。