1、SQL语句尽量用大写的:
因为oracle总是先解析SQL语句,把小写的字母转换成大写的再执行。
2、使用表的别名:
当在SQL语句中连接多个表时, 尽量使用表的别名并把别名前缀于每个列上。这样一来,就可以减少解析的时间并减少那些由列歧义引起的语法错误。
3.表名的顺序选择要高效:
ORACLE 的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表)将会被最先处理,假如FROM子句中包含多个表,必须选择记录条数最少的表作为基础表,如果有3个以上的表连接查询, 那就需要选择中间表作为基础表, 中间表是指那个被其他表所引用的表,也可以称为关联映射表。
4、WHERE子句中的连接顺序:
ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件写在WHERE子句的末尾。
5、SELECT子句中避免使用 * :
ORACLE在解析的过程中, 会将'*' 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 这样将耗费更多的时间,尽量只查询有用的字段。
6.避免使用耗费资源的操作:
带有DISTINCT、UNION、MINUS、INTERSECT、ORDER BY的SQL语句会启动SQL引擎执行耗费资源的排序(SORT)功能。DISTINCT需要一次排序操作,而其他的至少需要执行两次排序。
7.优化GROUP BY:
将不需要的记录在GROUP BY之前过滤掉,比如
SELECT JOB,AVG(AGE) FROM EMP WHERE JOB = 'STUDENT' OR JOB = 'MANAGER' GROUP BY JOB;
8.根据需要用UNION ALL替换UNION:
SQL语句需要UNION两个查询结果集合时,这两个结果集合会以UNION-ALL的方式被合并,然后在输出最终结果前进行排序。如果用UNION ALL替代UNION, 这样排序就不必要了,效率就会因此得到提高。
9.尽量多使用COMMIT:
只要有可能,在程序中尽量多使用COMMIT,这样程序的性能得到提高,需求也会因为COMMIT所释放的资源而减少。
10.用Where子句替换HAVING子句:
避免使用HAVING子句,HAVING只会在检索出所有记录之后才对结果集进行过滤。这个处理需要排序,总计等操作。最好能通过WHERE子句限制记录的数目。
on是先把不符合条件的记录过滤后才进行统计,可以减少中间运算要处理的数据,速度是最快的;
where比having快点,因为它过滤数据后才进行sum,在两个表联接时才用on的
11.避免在索引列上使用NOT:
NOT会产生在和在索引列上使用函数相同的影响。当ORACLE遇到NOT,就会停止使用索引转而执行全表扫描。
12.避免在索引列上使用IS NULL和IS NOT NULL
提到索引:可以简单的总结下关于Oracle索引-----------------
1)索引是数据库对象之一,用于加快数据的检索,类似于书籍的索引。在数据库中索引可以减少数据库程序查询结果时需要读取的数据量,类似于在书籍中我们利用索引可以不用翻阅整本书即可找到想要的信息。
2)索引是建立在表上的可选对象;索引的关键在于通过一组排序后的索引键来取代默认的全表扫描检索方式,从而提高检索效率
3)索引在逻辑上和物理上都与相关的表和数据无关,当创建或者删除一个索引时,不会影响基本的表;
4)索引一旦建立,在表上进行DML操作时(例如在执行插入、修改或者删除相关操作时),oracle会自动管理索引,索引删除,不会对表产生影响
5)索引对用户是透明的,无论表上是否有索引,sql语句的用法不变
6)oracle创建主键时会自动在该列上创建索引
如图:
索引原理
什么是索引:索引是帮助高效获取数据的数据结构,(为了加速对表中数据行的检索而创建的一种分散存储的数据结构)索引是一个文件。
1. 若没有索引,搜索某个记录时(例如查找name='wish')需要搜索所有的记录,因为不能保证只有一个wish,必须全部搜索一遍
2. 若在name上建立索引,oracle会对全表进行一次搜索,将每条记录的name值哪找升序排列,然后构建索引条目(name和rowid),存储到索引段中,查询name为wish时即可直接查找对应地方
3.创建了索引并不一定就会使用,oracle自动统计表的信息后,决定是否使用索引,表中数据很少时使用全表扫描速度已经很快,没有必要使用索引
13.关于count(*) 和Count(列)的访问速度,由于优化器里的算法关于列的偏移量决定了查询的性能,列越靠后,访问的开销越大,由于count(*) 最快的算法与列偏移量无关,所以count(*)最快,count(最后列)最慢,所以在开发设计表结构的时候尽量把不常访问的列放在最后的位置。
14.
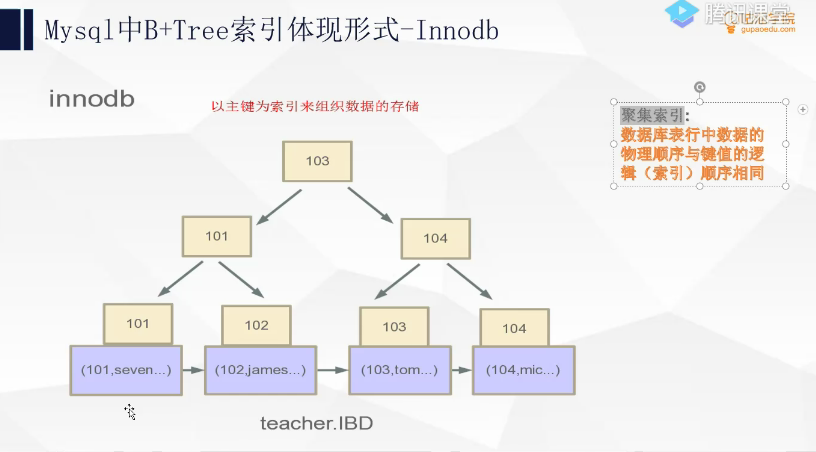
15.聚集索引