第四模块 并发编程(多进程)
一 进程理论
1.进程
正在进行的一个过程或者说一个任务。负责执行的任务则是CPU
2.进程与程序的区别
程序是一堆代码,而进程指的是程序的运行过程
3.并发与并行
并发: 是伪并行,看起来同时运行。单个CPU+多道技术就以实现并发
并行: 同时运行, 只有多个CPU才能实现并行
4.进程的创建
1.系统初始化
2.一个进程在运行过程中开启子进程
3. 用户交互请求,而创建一个新进程
4. 一个批处理作业初始化
在Unix中系统调用时: fork,fork会创建一个与父进程一模一样的副本,二者有相同的存储映像,同样的环境字符串和同样的打开文件(在shell解释器进程中, 执行一个命令就会创建一个子进程)
5.进程的终止
1.正常退出(自愿,如果用户点击交互页面的叉号,或程序执行完毕调用发起系统调用正常退出,在linux中用exit,Windows 用 ExitProcess)
2.出错退出
3. 严重错误(引用不存在的内存, I/0等, 可以捕捉异常 ,try except)
4. 被其他进程杀死 kill 9
6.进程的层次结构
1.在Unix中所有的进程,都是以init进程为根,组成树形结构,父子进程国通组成一个进程组,当键盘发出一个信号时,该信号被送给当前与键盘相关的进程组中的所有成员
2. 在Windows中, 没有进程层次概念,所有的进程都是地位相同的, 唯一类似于进程层次的暗示,是在创建进程时,父进程得到一个特别的令牌(称为句柄),该句柄可以用来控制子进程,但父进程有权吧该句柄传给其他子进程, 这样就没有层次概念
7.进程的状态
tailf test.log | grep yyy
执行程序 tail, 开启一个子进程,执行程序grep, 开启另外一个子进程,连个进程之间基于管道 通讯,讲tail的结果作为grep的输出
进程grep在等待输入 (即I/0)时的状态称为阻塞, 此时grep命令都无法运行。
2种情况下会导致一个进程在逻辑上不能运行
1. 进程挂起自身原因,遇到I/0阻塞,便让出CPU让其他进程去执行。这样保证CPU一直在工作
2. 与进程无关, 是操作系统层面,可能会因为一个进程占用时间过多,或者优先级等原因,而调用其他的进程去使用CPU
进程的三种状态: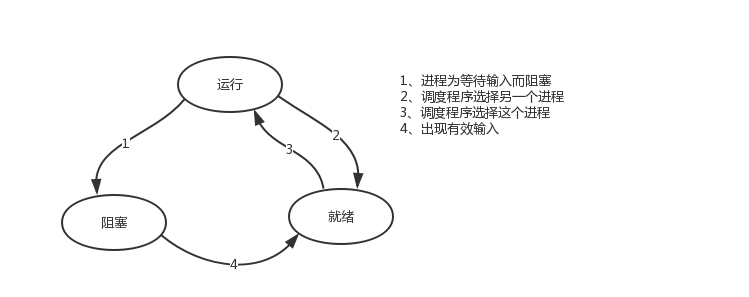
二 开启进程的方式
需要掌握multiprocessing模块开启进程的两种方式
1.multiprocessing模块介绍
Python中多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看)在Python中大部分情况下需要使用多进程
Python 提供了multiprocessing。multiprocessing模块用来开启子进程,并在进程执行我们定制的任务(比如函数),该模块与多线程模块threading的编程接口类似,multiprocessing模块的功能众多;支持子进程,通信和共享数据,执行不同形式的同步 提供了 Process Queue Pipe Lock 等组件
需要强调的是: 与线程不同 进程没有任何共享状态,进程修改的数据, 改动仅限于该进程内
2. Process类的介绍
创建进程的类
Process(group=None, target=None, name=None, args=(), kwargs={}),由该类实例化得到的对象,可用来开启一个子进程
需要注意是:
使用关键字的方式来指定参数
args指定的传给target函数的位置参数,是一个元组形式, 必须有逗号
参数介绍
group 参数为使用,值始终未None target表示调用对象,即子进程要执行的任务 args 表示调用对象的位置参数元组,args=(1,2,3,) kwargs 表示调用对象的字典,kwargs= {"name":"augustyang,"age":18} name为子进程的名称
方法介绍
p.start() 启动进程,并调用该子进程中的p.run()
p.run() 进程启动时运行的方法,正是它去调用target指定的函数,我们自定义的类中一定要实现该方法
p.terminate() 强制终止进程p 不会进行任何清理操作,如果p创建了子进程 该进程就成了僵尸进程,使用该方法需要特别小心这种情况,如果p还保持了一个锁那么也将不会被释放,进而导致死锁
p.is_alive() 如果p运行 返回True
p.join(timeout=None) 主进程等待p终止(强调 是主线程处于等的状态,而p处于运行的状态)。 timeout 是可选的超时时间
属性介绍
p.daemon 默认值为False,如果设为True, 代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止 并且设定为True后,p不能创建自己的新进程,必须在p.start() 之前设置
p.name 进程的名称
p.pid 进程pid
3. Process类的使用
在windows中Process() 必须放到 if __name__=="__main__" 下
创建并开启子进程的方式一
from multiprocessing import Process import time,random def start_course(name): print("%s learning"%name) time.sleep(random.randint(1,8)) print("%s endding "%name) if __name__ == "__main__": p1 = Process(target=start_course,args=("english",)) p2 = Process(target=start_course,args=("chinese",)) p3 = Process(target=start_course,args=("maths",)) p4 = Process(target=start_course,args=("python",)) p1.start() p2.start() p3.start() p4.start() print("主")
创建并开启子进程的方式二
from multiprocessing import Process import time,random class start_course(Process): def __init__(self,name): super().__init__() self.name = name def run(self): print("%s learning"%self.name) time.sleep(random.randint(1,8)) print("%s endding "%self.name) if __name__ == "__main__": p1 = start_course("english") p2 = start_course("chinese") p3 = start_course("chinese") p4 = start_course("python") p1.start() p2.start() p3.start() p4.start() print("主")
2. 基于多进程实现并发的套接字通信
server:
from socket import * from multiprocessing import Process def connent(ip,port): s = socket(AF_INET,SOCK_STREAM) s.bind((ip,port)) s.listen(5) while True: conn,addr = s.accept() t = Process(target=server, args=(conn,)) t.start() s.close() def server(conn): while True: try: data = conn.recv(1024) conn.send(data.upper()) except ConnectionResetError: break conn.close() if __name__ == "__main__": connent("127.0.0.1", 6666)
client:
from socket import * def client(ip,port): c = socket(AF_INET,SOCK_STREAM) c.connect((ip,port)) while True: data = input(">>>: ").strip() if not data:continue c.send(data.encode("utf-8")) data = c.recv(1024) print(data.decode("utf-8")) if __name__ == "__main__": c = client("127.0.0.1",6666)
三 join方法
在主进程运行过程中如果想并发地执行其他任务,我们可以开启子进程。此时主进程的任务与子进程的任务分两种情况。
情况一:
在主进程的任务与子进程的任务彼此独立的情况下,主进程的任务先执行完毕后,主进程还需要等待子进程执行完毕,然后统一回收资源。
情况二:
如果主进程的任务在执行到某个阶段时,需要等待子进程执行完毕后才能继续执行,就需要有一种机制能够让主进程检测子进程是否运行完毕,在子进程执行完毕后才继续执行,否则一直在原地阻塞,这就是join方法的作用
1. join的使用
# 一 并行 from multiprocessing import Process import time,random def start_course(name): print("%s learning"%name) time.sleep(random.randint(1,8)) print("%s endding "%name) if __name__ == "__main__": p1 = Process(target=start_course, args=("python",)) p2 = Process(target=start_course, args=("english",)) p1.start() p2.start() p1.join() # 等待p停止, 才执行下一行代码 p2.join() print("zhu") # 二 Python执行完 才能执行English from multiprocessing import Process import time,random def start_course(name): print("%s learning"%name) time.sleep(random.randint(1,8)) print("%s endding "%name) if __name__ == "__main__": p1 = Process(target=start_course, args=("python",)) p2 = Process(target=start_course, args=("english",)) p1.start() p1.join() p2.start() p2.join() print("zhu")
2 进程的其他方法: terminate 与 is_alive
from multiprocessing import Process import time,random def start_course(name): print("%s learning"%name) time.sleep(random.randint(1,8)) print("%s endding "%name) if __name__ == "__main__": p1 = Process(target=start_course, args=("python",)) p1.start() p1.terminate() # 关闭进程, 不会立刻关闭,所以 is_alive 可以查看结果可能还是存活 print(p1.is_alive()) # 结果为True print('主') print(p1.is_alive()) # 结果为False
3 进程的其他方法: name 与 pid
from multiprocessing import Process import time,random def start_course(name): print("%s learning"%name) time.sleep(random.randint(1,8)) print("%s endding "%name) if __name__ == "__main__": p1 = Process(target=start_course, args=("python",)) p1.start() print(p1.name,p1.pid) ''' Process-1 12796 python learning python endding '''
四 守护进程
主进程创建子进程, 然后将该进程设置成守护自己的进程, 守护进程就好比崇祯皇帝身边的老太监,崇祯皇帝已死老太监就跟着殉葬
守护进程需要关注2两点:
1. 守护进程会在主进程代码执行结束后就终止
2. 守护进程内无法再开启子进程,否则抛出异常 AssertionError: daemonic processes are not allowed to have children
守护进程案例
from multiprocessing import Process import random def start_course(name): print("%s learning"%name) time.sleep(random.randint(1,8)) print("%s endding "%name) if __name__ == "__main__": p1 = Process(target=start_course, args=("python",)) p1.daemon = True p1.start() print("end...") ''' end... ''' from multiprocessing import Process import time def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(1) print("end456") if __name__ == "__main__": p1 = Process(target=foo) p2 = Process(target=bar) p1.daemon = True p1.start() p2.start() print("main....") ''' main.... 456 end456 '''
五 互斥锁
进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件, 或同一个打印终端,是没有问题的,而共享带来的竞争,竞争带来的结果就是错乱
并发运行, 效率高,单竞争同一打印终端,带来了打印错乱
# 并发运行, 效率高,单竞争同一打印终端,带来了打印错乱 from multiprocessing import Process import os,time,random def work(): print("%s is running "% os.getpid()) time.sleep(random.randint(1,5)) print("%s is done" %os.getpid()) if __name__ == "__main__": for i in range(3): p = Process(target=work) p.start() ''' 3912 is running 9720 is running 11924 is running 11924 is done 3912 is done 9720 is done '''
如何控制打印错乱,就是加锁处理,而互斥锁的意思就是互相排斥,如果把多个进程比喻成多个人,互斥锁的工资原理就是多个人都要争夺同给一个资源: 卫生间,
一个人抢到卫生间后上一把锁, 其他人都要等着, 等到这个完成任务后释放锁,其他人才有可能有一个抢到。。。。所以互斥锁的原理,就是把并发改成串行,降低了效率,但保证了数据安全不错乱
把并行上加上锁,牺牲了运行效率,但避免了竞争
# 并行改成串行,牺牲了运行效率,但避免了竞争 from multiprocessing import Process,Lock import os,time,random def work(lock): lock.acquire() # 加锁 print("%s is running "% os.getpid()) time.sleep(random.randint(1,5)) print("%s is done" %os.getpid()) lock.release() # 释放锁 if __name__ == "__main__": lock= Lock() for i in range(3): p = Process(target=work,args=(lock,)) p.start() ''' 11448 is running 11448 is done 7816 is running 7816 is done 6440 is running 6440 is done '''
六 队列
进程彼此之间相互隔离, 要实现进程间通信(IPC), multiprocessing模块支持两种形式,队列和管道,这两种方式都是使用消息传递的
参数介绍
maxsize是队列中允许最大项数,省略则无大小限制
需要明确
1. 队列内存存放的是消息而非大数据
2. 队列暂用的是内存空间,因而maxsize即便是无大小限制也受限于内存大小
主要方法介绍
q.put 方法用以插入数据到队列中
q.get 方法可以从队列读取并删除一个元素
队列的使用
from multiprocessing import Process,Queue q = Queue(3) q.put(1) q.put(2) q.put(3) print(q.full()) # True print(q.get()) print(q.get()) print(q.get())
七 生产者消费者模型
1.生产者消费者模型介绍:
为什么要使用生产者消费者模型
生产者指的是生产数据的任务,消费者指的是处理数据的任务,在并发编程中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据,同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式
什么是生产者和消费者模式
生产者消费者是通过一个容器来解决生产者和消费者的强耦合问题。 生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列相当于一个缓存区,平衡了生产者和消费者的处理能力
2. 生产者消费者模型实现
from multiprocessing import Process,Queue import time,random def consumer(q,name): while True: res = q.get() time.sleep(random.randint(1,3)) print("%s 吃 %s" %(name,res)) def producer(q,name,food): for i in range(3): time.sleep(random.randint(1,3)) res = "%s%s" %(food,i) q.put(res) print("%s 生产了 %s" %(name,res)) if __name__ == "__main__": q = Queue() # 生产者 p1 = Process(target=producer,args=(q,'egon','包子')) #消费者 c1 = Process(target=consumer,args=(q,'alex')) p1.start() c1.start() print('主')
解决方式无非是让生产者在生产完毕后,往队列中再发一个结束信号,这样消费者在接收到结束信号后就可以break出死循环
from multiprocessing import Process,Queue import time,random def consumer(q,name): while True: res = q.get() if res is None:break time.sleep(random.randint(1,3)) print("%s 吃 %s" %(name,res)) def producer(q,name,food): for i in range(3): time.sleep(random.randint(1,3)) res = "%s%s" %(food,i) q.put(res) print("%s 生产了 %s" %(name,res)) if __name__ == "__main__": q = Queue() # 生产者 p1 = Process(target=producer,args=(q,'egon','包子')) #消费者 c1 = Process(target=consumer,args=(q,'alex')) p1.start() c1.start() p1.join() q.put(None) print('主')
from multiprocessing import Process,JoinableQueue import time,random def consumer(q,name): while True: res = q.get() time.sleep(random.randint(1,3)) print("%s 吃了 %s" %(name,res)) q.task_done() # 发送q.join() 说明已经从队列中取走一个数据并处理完毕 def producer(q,name,food): for i in range(3): time.sleep(random.randint(1,3)) res = "%s %s" %(food,i) q.put(res) print("%s 生产了 %s" %(name,res)) q.join() if __name__ == "__main__": q = JoinableQueue() # 生产者 p1= Process(target=producer,args=(q,"egon1","包子")) p2= Process(target=producer,args=(q,"egon2","包子111")) # 消费者 c1 = Process(target=consumer,args=(q,'alex1')) c1.daemon = True # 开始 p1.start() p2.start() c1.start() p1.join() p2.join() print("主") ''' JoinableQueue 的实例p除了与Queue对象相同的方法之外还具有: q.task_done(): 使用者使用此方法发出信号,表示q.get()的返回项目已经被处理。如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常 q.join(): 生产者调用此方法进行阻塞,直到队列中所有的项目均被处理。阻塞将持续到队列中的每个项目均调用q.task_done()方法为止 '''