Atitit.字节数组转字符串 base64 base16 Quoted-printable 编码原理设计 attilax 总结
5. Base64的俩个子模式 urlsafe Or url unsafe 3
7. private static char toChar(int index, boolean isURLSafe) { 4
1. Base64编码,
是我们程序开发中经常使用到的编码方法。它是一种基于用64个可打印字符来表示二进制数据的表示方法。它通常用作存储、传输一些二进制数据编码方法!也是MIME(多用途互联网邮件扩展,主要用作电子邮件标准)中一种可打印字符表示二进制数据的常见编码方法!它其实只是定义用可打印字符传输内容一种方法,并不会产生新的字符集!有时候,我们学习转换的思路后,我们其实也可以结合自己的实际需要,构造一些自己接口定义编码方式。好了,我们一起看看,它的转换思路吧!
作者:: 老哇的爪子 Attilax 艾龙, EMAIL:1466519819@qq.com
转载请注明来源: http://blog.csdn.net/attilax
2. Base64实现转换原理
它是用64个可打印字符表示二进制所有数据方法。由于2的6次方等于64,所以可以用每6个位元为一个单元,对应某个可打印字符。我们知道三个字节有24个位元,就可以刚好对应于4个Base64单元,即3个字节需要用4个Base64的可打印字符来表示。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9 ,这样共有62个字符,此外两个可打印符号在不同的系统中一般有所不同。但是,我们经常所说的Base64另外2个字符是:“+/”。这64个字符,所对应表如下。
3. Base16 md5编码
4. Quoted-printable 编码 QP编码
编码后的数据比原始数据略长,为原来的4/3。无论什么样的字符都会全部被编码,因此不像Quoted-printable 编码,还保留部分可打印字符。所以,它的可读性不如Quoted-printable 编码!
Quoted-printable 可译为“可打印字符引用编码”、“使用可打印字符的编码”,我们收邮件,查看信件原始信息,经常会看到这种类型的编码!
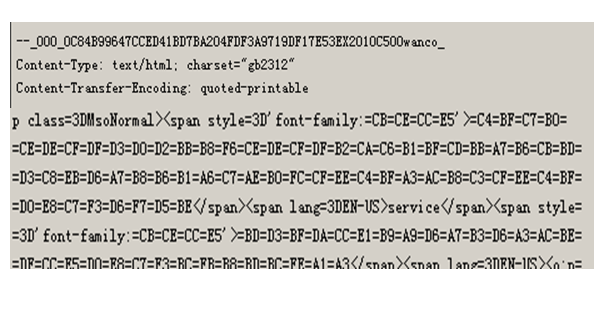
最多时候,我们在邮件头里面能够看到这样的编码!Content-Transfer-Encoding:quoted-printable
它是多用途互联网邮件扩展(MIME) 一种实现方式。其中MIME是一个互联网标准,它扩展了电子邮件标准,致力于使其能够支持非ASCII字符、二进制格式附件等多种格式的邮件消息。目前http协议中,很多采用MIME框架!quoted-printable 就是说用一些可打印常用字符,表示一个字节(8位)中所有非打印字符方法!
5. Base64的俩个子模式 urlsafe Or url unsafe
case 62: c = isURLSafe? '-': '+'; break;
case 63: c = isURLSafe? '_': '/'; break;
default: throw new RuntimeException("Cannot happen.");
6. UUencode编码
起先用在unix网络中,先是Unix系统下将二进制的资料借由uucp邮件系统传输的一个编码程式,也是一种二进制到文字的编码。不属于MIME编码中一员。它也是定义了用可打印字符表示二进制文字一种方法,并不是一种新的编码集合。主要解决,二进制字符在传输、存储中问题。它早期在电子邮件中使用较多,最近这些年来基本上被MIME 中Base64所取代了。E-mail中一般采用UU、MIME、BINHEX三种编码标准! 我想,了解下这种编码将二进制字符转换为可打印字符实现思路!对我们以后做类似处理工作,应该会有很多的启示。
思考问题:它的字符范围都是可打印字符,我们会发现64字符集合中,有很多是特殊字符:”!”#¥%&‘()*+=’” 等等。这些字符在不同应用中,可能都有些特殊用途。因此,在使用该编码时候,或许会出现一些问题。我想这也许是UUencode编码方法,逐渐被Base64所取代的原因吧。
7. private static char toChar(int index, boolean isURLSafe) {
char c;
switch(index) {
case 0: c = 'A'; break;
case 1: c = 'B'; break;
case 2: c = 'C'; break;
case 3: c = 'D'; break;
case 4: c = 'E'; break;
case 5: c = 'F'; break;
case 6: c = 'G'; break;
case 7: c = 'H'; break;
case 8: c = 'I'; break;
case 9: c = 'J'; break;
case 10: c = 'K'; break;
case 11: c = 'L'; break;
case 12: c = 'M'; break;
case 13: c = 'N'; break;
case 14: c = 'O'; break;
case 15: c = 'P'; break;
case 16: c = 'Q'; break;
case 17: c = 'R'; break;
case 18: c = 'S'; break;
case 19: c = 'T'; break;
case 20: c = 'U'; break;
case 21: c = 'V'; break;
case 22: c = 'W'; break;
case 23: c = 'X'; break;
case 24: c = 'Y'; break;
case 25: c = 'Z'; break;
case 26: c = 'a'; break;
case 27: c = 'b'; break;
case 28: c = 'c'; break;
case 29: c = 'd'; break;
case 30: c = 'e'; break;
case 31: c = 'f'; break;
case 32: c = 'g'; break;
case 33: c = 'h'; break;
case 34: c = 'i'; break;
case 35: c = 'j'; break;
case 36: c = 'k'; break;
case 37: c = 'l'; break;
case 38: c = 'm'; break;
case 39: c = 'n'; break;
case 40: c = 'o'; break;
case 41: c = 'p'; break;
case 42: c = 'q'; break;
case 43: c = 'r'; break;
case 44: c = 's'; break;
case 45: c = 't'; break;
case 46: c = 'u'; break;
case 47: c = 'v'; break;
case 48: c = 'w'; break;
case 49: c = 'x'; break;
case 50: c = 'y'; break;
case 51: c = 'z'; break;
case 52: c = '0'; break;
case 53: c = '1'; break;
case 54: c = '2'; break;
case 55: c = '3'; break;
case 56: c = '4'; break;
case 57: c = '5'; break;
case 58: c = '6'; break;
case 59: c = '7'; break;
case 60: c = '8'; break;
case 61: c = '9'; break;
case 62: c = isURLSafe? '-': '+'; break;
case 63: c = isURLSafe? '_': '/'; break;
default: throw new RuntimeException("Cannot happen.");
}
return c;
}
8. 参考
Base64 编码介绍、Base64编码转换原理、算法-程默的博客.html
Quoted-printable 编码介绍、编码解码转换-程默的博客.html
UUencode 编码,UU编码介绍、UUencode编码转换原理、算法-程默的博客.html