一 . numpy
-- 数据分析:就是把一些看似杂乱无章的数据信息提炼出来,总结出所研究的内在规律
-- 数据分析三剑客:Numpy,Pandas,Matplotlib
-- Numpy(Numerical Python)是python语言的一个扩展程序库,支持大量的纬度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库.
1. 创建ndarray
import numpy
# 一维数组的创建
array1 = numpy.array([1,2,3])
# 二维数组的创建(通常用的是二维)
array2 = numpy.array([[1,'two',3],[4,5,6]])
!!! 注意:
numpy默认里面的所有元素类型都是相同的,全是数字,全是字母等
如果传进来的列表中数据类型不统一,则统一为同一类型,优先级:str>float>int
1.1 使用matplotlib.pyplot获取一个numpy数组,数据来源一张图片
import matplotlib.pyplot as plt
img_array = plt.imread('./sjl.jpg')
plt.imshow(img_array) # 显示图片
操作numpy数据同步到图片中(修图底层就是这么实现的)
img_array = img_array - 50
plt.imshow(img_array)
img_array.shape # 得到(396, 406, 3), 前两个参数是像素,第三个是颜色,上面直接-50,是把这三个数都减了50
1.2 numpy的一些用法(下面就默认已经导入了numpy啦)
numpy.full(shape=(5,6),fill_value=66) # 返回5行6列,值为66的数组
numpy.linspace(0,100,num=10) # 获得等差数列
numpy.arange(0,10,2) # 从0-9,步长是2
numpy.random.randint(0,50,size=(3,3)) #0-50的随机数组成3x3的矩阵
# 固定随机性(随机因子)
numpy.random.seed(5) # 系统指定的当前时间戳,指定之后就不变了,怎么随机都是这些数
numpy.random.randint(0,50,size=(3,3))
2. ndarry的属性
四个必须记住的参数:
ndim(纬度)
shape(形状,各维度的长度)
size(总长度)
dtype(元素类型)
应用: (img_array还是上面那个图片)
img_array.ndim # 3
img_array.size # 482328
img_array.dtype # dtype('uint8')
type(img_array) # numpy.ndarray
3. ndarray的基本操作
3.1 索引 (一维与列表一样,多维同理)
array2 = numpy.array([[1,'two',3],[4,5,6]])
array2[0][1] # two
3.2 切片 (一维与列表一样,多维同理)
numpy.random.seed(1)
array3 = numpy.random.randint(0,100,size=(4,4))
array3[0:2] # 获取二维数组的前两行
# 获取二数组的前两列
array3[:,0:2] # 一个逗号用做二维数组,逗号前边是行,不要行数据的话用冒号表示
array3[0:2,0:2] # 获取前两行中的前两列
array3[::-1] # 将二维数组的 行 进行倒序
array3[:,::-1] # 列倒序
array3[::-1,::-1] # 全部都倒序
# 这里可以应用到图片旋转上(还是上面那个图片)
# img_array[row,col,color]
plt.imshow(img_array[:,::-1,:])
plt.imshow(img_array[::-1,::-1,::-1])
3. 变形
# 将一维数组变成多维
array2 = [['1', 'two', '3'],['4', '5', '6']]
array2 .reshape((2,3)) # 改成2行,每行3个数据,正好6个 参数一定要是tuple
# 将多维数组变成一维
arr = [['1', 'two', '3'],
['4', '5', '6']]
arr = arr .reshape((6)) # array2这个二维数组一共有6个数,也就是说,里面的tuple参数一定要是 6
# 自动计算,用-1,前提必须其他的数都是已知数
arr.reshape((-1,2)) # 固定参数是2列,自动计算出3行
4. 级联
numpy.concatenate()
一维,二维,多维数组的级联,实际操作中多数是二维数组
# 先建3个数组
np.random.seed(5)
a1 = numpy.random.randint(0,50,size=(4,4))
a2 = numpy.random.randint(0,50,size=(4,4))
a3 = numpy.random.randint(0,50,size=(3,4))
display(a1,a2,a3)
numpy.concatenate((a1,a2),axis=0) # 二维数组axis只能是0或者1, 0代表列拼在一起,1代表行拼在一起
九宫格照片
img_array = plt.imread('./sjl.jpg')
img_3 = np.concatenate((img_array,img_array,img_array),axis=0)
img_9 = np.concatenate((img_3,img_3,img_3),axis=1)
plt.imshow(img_9)

5. 切分
与级联类似,三个函数完成切分工作:
numpy.split(array,行号/列号,轴),参数2是一个列表类型
numpy.vsplit
numpy.nsplit
a1 = np.random.randint(0,50,size=(4,4))
np.split(a1,[2],axis=0) # 切的是列(就是横着切)
# 裁剪图片,用切片方法
# img_array[row,col,color]
plt.imshow(img_array[20:280,100:300,])
6.ndarry聚合操作
a1 = np.random.randint(0,50,size=(4,4))
a1.sum(axis=0) # axis=0,就列的和,axis=1,求行的和,不写参数,求所有数的和
最大值最小值:np.max/np.min 同理
平均值:np.mean() 同理
7. numpy.array的排序
np.sort()nd.array.sort() 都可以,但有区别:
np.sort()不改变原数组 常用这个,因为不要轻易改变数据
ndarray.sory()本地处理,但不占用空间,但改变原数组
二 . Pandas
先导入包,下面所有的代码就直接用了,不在导包了
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
Series
Series是一种类似于一维数组的对象,由下面两个部分组成:
values:一组数据(ndarray类型)
index:相关的数据索引标签
Series的创建
三种创建方式:
1.列表创建
2.numpy数组创建
3.字典创建
默认索引为0到n-1的整数索引
Series的一些操作
# 使用列表创建Series 隐式索引(就是索引是下标0,1,2,3)
s1 = Series(data=[1,2,3,4]) # s1[0] 取到的是1
# 使用列表创建Series 显示索引,(使用显示索引,也可以使用隐式索引)
s2 = Series(data=[1,2,3,4],index=['a','b','c','d']) # s2[0]和s2['a'] 取到的都是1
================================================
# 使用numpy创建Series
s3 = Series(data=np.random.randint(0,20,size=(5,)))
dic = {
'English':100,
'math':30
}
Series(data=dic)
取索引的方法还有:
s2.loc['a'] #一定要拿显示索引
s2.iloc[1] # 一定要拿隐式索引
s2['xxx'] = 666 # 添加
可以通过shape,size,index,values等拿到series的属性
s2.shape # (5,)
s2.size # 5
s2.index # 只能拿到显示索引 Index(['a', 'b', 'c', 'd', 'xxx'], dtype='object')
s2.values # array([ 1, 2, 3, 4, 666], dtype=int64)
head()与tail() 是查看前/后多少个元素
s2.head(2) # 查看前两个
对series去重与数据清洗
去重
s = Series(data=[1,1,1,1,2,2,2,2,3,3,3,4,4])
s.unique() # array([1, 2, 3, 4], dtype=int64)
数据清洗
s3 = Series(data=[1,2,3,4],index=['a','b','c','d'])
s4 = Series(data=[1,2,3,4],index=['a','b','c','x'])
s = s3 + s4
print(s) # 发现d和x都是NaN
a 2.0
b 4.0
c 6.0
d NaN
x NaN
s.isnull()
s.notnull()
a True
b True
c True
d False
x False
dtype: bool
s[s.notnull()]
DataFrame
DataFrame是一个 表格型 的数据结构.DataFrame由按一定顺序排列的多列数据组成,设计初衷是将Series使用场景从一维拓展到多维,DateFrame既有行索引,又有列索引.
- 行索引: index
- 列索引: columns
- 值: values
DataFrame的创建
最常用的方法是传递一个字典来创建,DateFrame以字典的键作为每一列的名称,以字典的值(一个数组)作为每一列.
此外,DataFrame会自动加上每一行的索引.
使用字典创建DataFrame后,columns参数则不可用.
同Series一样,若传入的类与字典的键不匹配,则相应的值为NaN.
df = DataFrame(data=np.random.randint(1,10,size=(3,3)),index=['a','b','c'],columns=['A','B','C'])
df.values
array([[1, 6, 5],
[1, 8, 4],
[7, 3, 1]])
使用字典创建DataFrame
dic = {
'张三':[150,150,150,150],
'李四':[0,0,0,0]
}
df = DataFrame(data=dic,index=['语文','数学','英语','理综'])
张三 李四
语文 150 0
数学 150 0
英语 150 0
理综 150 0
DateFrame的索引
对列进行索引:
- 通过类似字典的方式 df['key']
- 通过属性的方式 df.key
可以将DataFrame的列获取为一个Series.返回的Series拥有相同的索引,且name属性也已经设置好了,就是相应的列名
# 修改列索引
df.columns = ['王五','赵六']
# 获取列数据,用[]去只能去列并且只能是显示索引
df['王五']
df[['赵六','王五']]
df.loc['语文']
对行进行索引
- 使用loc[] 里面写显示索引
- 使用iloc[] 里面写隐性索引
df.iloc[0]
取出确定位置的数据 df.loc[row,col]
df.loc['理综','王五']
# 王五的语文与数学成绩
df.loc[['语文','数学'],'王五']
# 可用loc或iloc中取列
df.iloc[:,0]
切片
!!!注意->直接用中括号时:
- 索引表示的是列索引
- 切片表示的行索引
实操
# 切前2行数据
df[0:2]
# 切前2列
df.iloc[:,0:2]
# 通过索引切片,可以直接写显示索引
df.loc['语文':'数学']
运算
first_exam = df
last_exam = df
# 求first_exam与last_exam的平均成绩
(first_exam+last_exam)/2
# 王五的first_exam语文成绩取消,为0
first_exam.loc['语文','王五'] = 0
# 赵六的所有first_exam成绩加100
first_exam['赵六']=first_exam['赵六'] + 100
pandas数据处理
# 删除重复元素
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True
keep参数:指定保留哪一个重复的行数据
创建具有重复元素行DataFrame
# 创建一个df
df = DataFrame(data=numpy.random.randint(0,100,size=(8,4)))
df.iloc[1] = [666,666,666,666]
df.iloc[3] = [666,666,666,666]
df.iloc[6] = [666,666,666,666]

使用duplicated()函数检测重复的行
~df.duplicated(keep='first') # False对应的重复的值,注意前面取反了,first保留第一行,last最后一行,False全不要
df.loc[~df.duplicated(keep='first')]
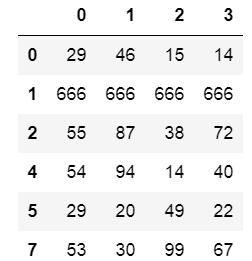
使用df.drop_duplicates(keep='first/last'/False)删除重复的行
df.drop_duplicates(keep='first')