一 . 先了解一下scrapy五大组件的工作流程
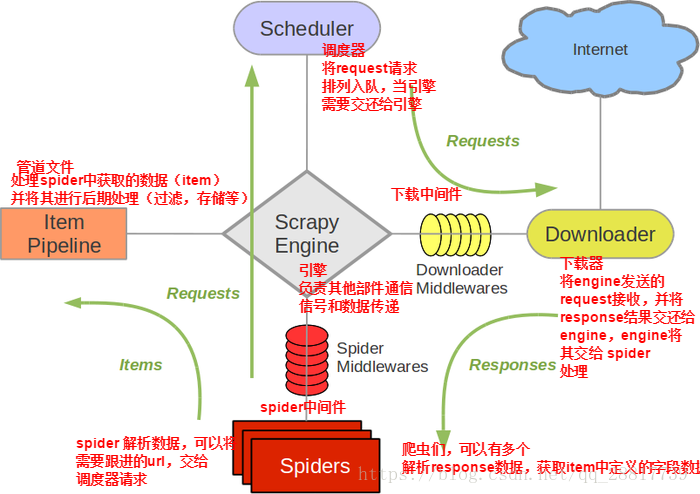
二 . 中间件的应用
从上图可以看出来,scrapy的工作流程中有两个中间件,分别是spider中间件,一个是Downloader中间件
这里我们先介绍一下Downloader中间件
爬虫文件(middle.py)
import scrapy
class MiddleSpider(scrapy.Spider):
name = 'middle'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.baidu.com/s?wd=ip']
def parse(self, response):
page_text = response.text
# 这里直接保存一个页面看一下效果,就不写到数据库啦
with open('./ip.html', 'w', encoding='utf-8') as f:
f.write(page_text)
middlewares.py


1 from scrapy import signals 2 import random 3 class MiddleproDownloaderMiddleware(object): 4 5 # 这是UA池,基本包含了各大浏览器的UA 6 user_agent_list = [ 7 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 " 8 "(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", 9 "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 " 10 "(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", 11 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 " 12 "(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", 13 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 " 14 "(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", 15 "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 " 16 "(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", 17 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 " 18 "(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", 19 "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 " 20 "(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", 21 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " 22 "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", 23 "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 " 24 "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", 25 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 " 26 "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", 27 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " 28 "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", 29 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " 30 "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", 31 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " 32 "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", 33 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " 34 "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", 35 "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 " 36 "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", 37 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " 38 "(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", 39 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 " 40 "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", 41 "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 " 42 "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" 43 ] 44 PROXY_http = [ 45 '153.180.102.104:80', 46 '195.208.131.189:56055', 47 ] 48 PROXY_https = [ 49 '120.83.49.90:9000', 50 '95.189.112.214:35508', 51 ] 52 @classmethod 53 def from_crawler(cls, crawler): 54 # This method is used by Scrapy to create your spiders. 55 s = cls() 56 crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 57 return s 58 59 # 可以处理拦截到所有的非异常的请求 60 # spider参数表示的就是爬虫类实例化的一个对象 61 def process_request(self, request, spider): 62 print('this is process_request()') 63 #UA伪装 64 request.headers['User-Agent'] = random.choice(self.user_agent_list) 65 66 # 测试:代理操作是否生效 67 request.meta['proxy'] = 'https://218.60.8.83:3129' 68 return None 69 # 拦截所有的响应 70 def process_response(self, request, response, spider): 71 72 return response 73 # 拦截发生异常的请求对象 74 def process_exception(self, request, exception, spider): 75 if request.url.split(':')[0] == 'https': 76 request.meta['proxy'] = 'https://'+random.choice(self.PROXY_https) 77 else: 78 request.meta['proxy'] = 'http://' + random.choice(self.PROXY_http) 79 80 def spider_opened(self, spider): 81 spider.logger.info('Spider opened: %s' % spider.name)
应用selenium和中间件对动态生成的 响应数据进行处理
爬虫文件(news.py)
# -*- coding: utf-8 -*-
import scrapy
from ..items import MiddleWareItem
from selenium import webdriver
class NewsSpider(scrapy.Spider):
# scrapy中应用selenium获取动态加载数据
browser = webdriver.Chrome(r'D:spiderchromedriver.exe')
name = 'news'
sort_urls = [] # 放两个分类的url
# allowed_domains = ['www.xxx.com']
start_urls = ['https://news.163.com/']
def newsContentParse(self, response):
item = response.meta['item']
# 解析新闻内容,然后直接存储到item中
content_list = response.xpath('//div[@id="endText"]//text()').extract()
item['news_content'] = ''.join(content_list)
yield item
# 用来解析分类对应页面中的新闻数据
def parse_detail(self, response):
div_list = response.xpath('//div[@class="ndi_main"]/div')
for div in div_list:
news_title = div.xpath('.//h3/a/text()').extract_first()
detail_news_url = div.xpath('.//h3/a/@href').extract_first()
item = MiddleWareItem()
item['news_title'] = news_title
# 获取新闻的内容,进行请求传参,将item传递给下一个解析方法
yield scrapy.Request(url=detail_news_url, callback=self.newsContentParse, meta={'item': item})
def parse(self, response):
# 解析出两个分类对应url,为了使用一个爬虫函数,要保证这两个分类排版一样
li_list = response.xpath('//div[@class="ns_area list"]/ul/li')
# 取到国内和国际新闻的li标签索引
indexs = [3, 4]
sort_li_list = [] # 放置选出的两个分类对应的li
for index in indexs:
li = li_list[index]
sort_li_list.append(li)
# 解析出两个板块的url
for li in sort_li_list:
sort_url = li.xpath('./a/@href').extract_first()
self.sort_urls.append(sort_url)
# 对每一个分类的url发起请求获取详情页的页面源码数据
yield scrapy.Request(url=sort_url, callback=self.parse_detail)
middlewares.py
from scrapy import signals
from time import sleep
from scrapy.http import HtmlResponse
class MiddleWareDownloaderMiddleware(object):
def process_request(self, request, spider):
return None
# 改方法可以拦截到所有的响应对象(需求中需要处理的是指定的某些响应对象)
def process_response(self, request, response, spider):
"""
1.找出指定的响应对象进行处理操作
2.可以根据指定的请求对象定位到指定的响应对象
3.指定的请求对象可以通过请求的url进行定位
4.定位指定的url方法: spider.sort_urls
"""
sort_urls = spider.sort_urls
browser = spider.browser
if request.url in sort_urls:
"""
1.通过指定的url就定位到了指定request
2.通过指定request就定位到了指定的response(不符合需求的)
3.自己手动创建2个符合要求的新的响应对象
4.使用新的响应对象替换原始的响应对象
"""
browser.get(request.url) # 使用浏览器对两类板块对应的url发起请求
sleep(2) # 看清楚一点
js = 'window.scrollTo(0,document.body.scrollHeight)'
browser.execute_script(js)
sleep(2)
# 页面源码数据中包含来了动态加载出来的新闻数据
page_text = browser.page_source
# 手动创建一个新的响应对象,将page_text作为响应数据封装到响应对象中
return HtmlResponse(url=browser.current_url, body=page_text, encoding='utf-8', request=request)
# body参数表示的就是响应数据
return response
items.py
import scrapy
class MiddleWareItem(scrapy.Item):
news_title = scrapy.Field()
news_content = scrapy.Field()