ngx_hash源码解析
ngx_hash是nginx中的hash表结构,具有以下特点:
- 静态结构,hash表创建后无法动态添加/删除KV。
- 采用连续存储方式解决碰撞问题。即出现碰撞的KV存放在连续地址。
- 支持前缀和后缀通配符匹配。
以上特点决定了其高效性与功能局限性。
内存结构&hash_find
根据结构体定义与ngx_hash_find函数可以看出其内存存放结构
typedef struct {
void *value;
u_short len;
u_char name[1];
} ngx_hash_elt_t;
typedef struct {
//hash表分多个桶,每个桶内存放hash(key)碰撞的元素
ngx_hash_elt_t **buckets;
ngx_uint_t size;
} ngx_hash_t;
void *
ngx_hash_find(ngx_hash_t *hash, ngx_uint_t key, u_char *name, size_t len)
{
ngx_uint_t i;
ngx_hash_elt_t *elt;
//key % hash->size 选择桶
elt = hash->buckets[key % hash->size];
if (elt == NULL) {
return NULL;
}
while (elt->value) {
if (len != (size_t) elt->len) {
goto next;
}
//比对key
for (i = 0; i < len; i++) {
if (name[i] != elt->name[i]) {
goto next;
}
}
return elt->value;
next:
//计算下一个ele地址,每个ele长度不固定。
elt = (ngx_hash_elt_t *) ngx_align_ptr(&elt->name[0] + elt->len, sizeof(void *));
continue;
}
return NULL;
}
示意图如下:
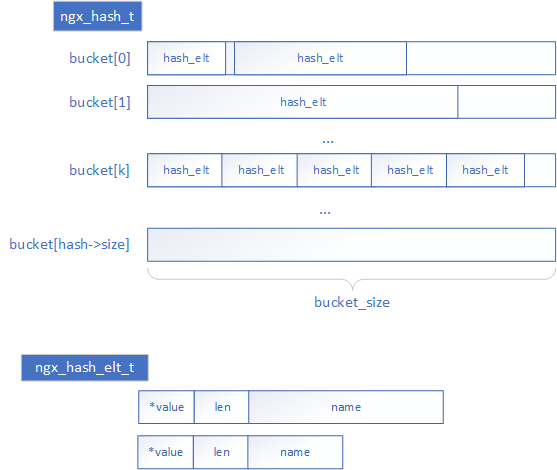
整个hash表结构分成若干个bucket,每个bucket内存放key值碰撞的元素。
- 每个bucket的大小是初始化时指定的一个值(bucket_size),要求大于最大元素的大小。即bucket_size约束了元素的大小。但实际的桶大小还要根据各种信息具体确定,详见下文初始化部分。
- bucket的数量时初始化时根据各种信息计算得到,详见下文初始化部分。
每个元素内保存了完整的key值,注意ngx_hash_elt_t.name实际存储的内容包括完成的key,不仅是1个字节,len表示其真实长度。所以每个元素的大小是不一致的,根据key的实际长度决定。
hash表结构初始化
初始化使用的是ngx_int_t ngx_hash_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names, ngx_uint_t nelts)函数。
ngx_hash_init_t *hinit结构如下:
typedef struct {
ngx_hash_t *hash; //出参,初始化好的hash表,后续通过ngx_hash_find()函数使用
ngx_hash_key_pt key; //hash计算函数,常用选项有ngx_hash_key和ngx_hash_key_lc
ngx_uint_t max_size; //最大桶数量,实际数量在函数中计算。
ngx_uint_t bucket_size; //每个桶的大小。
char *name; //表名词
ngx_pool_t *pool; //数据pool
ngx_pool_t *temp_pool; //临时pool,仅在需要通配符的hash表初始化是使用,ngx_hash_init()不需要使用
} ngx_hash_init_t;
ngx_hash_key_t *names和ngx_uint_t nelts组成一组key不重复的KV集合。nginx提供了另外一组函数ngx_hash_keys_array_init()和ngx_hash_add_key()用于创造不重复的KV集合列表。
typedef struct {
ngx_str_t key;
ngx_uint_t key_hash;
void *value;
} ngx_hash_key_t;
ngx_hash_init()逻辑如下
//计算元素大小,元素结构参考ngx_hash_elt_t
#define NGX_HASH_ELT_SIZE(name)
(sizeof(void *) + ngx_align((name)->key.len + 2, sizeof(void *)))
ngx_int_t
ngx_hash_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names, ngx_uint_t nelts)
{
u_char *elts;
size_t len;
u_short *test;
ngx_uint_t i, n, key, size, start, bucket_size;
ngx_hash_elt_t *elt, **buckets;
//入参判断
if (hinit->max_size == 0) {
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"could not build %s, you should "
"increase %s_max_size: %i",
hinit->name, hinit->name, hinit->max_size);
return NGX_ERROR;
}
//元素的大小都小于桶大小,保证1个桶能存放至少任意1个元素。
for (n = 0; n < nelts; n++) {
if (hinit->bucket_size < NGX_HASH_ELT_SIZE(&names[n]) + sizeof(void *))
{
ngx_log_error(NGX_LOG_EMERG, hinit->pool->log, 0,
"could not build %s, you should "
"increase %s_bucket_size: %i",
hinit->name, hinit->name, hinit->bucket_size);
return NGX_ERROR;
}
}
//test用于计算每个桶所需要的大小,即hash(key)碰撞的几个元素大小之和
test = ngx_alloc(hinit->max_size * sizeof(u_short), hinit->pool->log);
if (test == NULL) {
return NGX_ERROR;
}
//计算一个初始的桶数量,算法含义没理解。
bucket_size = hinit->bucket_size - sizeof(void *);
start = nelts / (bucket_size / (2 * sizeof(void *)));
start = start ? start : 1;
if (hinit->max_size > 10000 && nelts && hinit->max_size / nelts < 100) {
start = hinit->max_size - 1000;
}
//逐步调整,找到一个能放下所有元素的桶数量。
for (size = start; size <= hinit->max_size; size++) {
ngx_memzero(test, size * sizeof(u_short));
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
key = names[n].key_hash % size;
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
//test[key] > bucket_size 表示hash(key)相同的元素总大小 > 桶大小
//则调整桶数量(size++),减少碰撞,减少hash(key)相同的元素总大小
if (test[key] > (u_short) bucket_size) {
goto next;
}
}
goto found;
next:
continue;
}
size = hinit->max_size;
ngx_log_error(NGX_LOG_WARN, hinit->pool->log, 0,
"could not build optimal %s, you should increase "
"either %s_max_size: %i or %s_bucket_size: %i; "
"ignoring %s_bucket_size",
hinit->name, hinit->name, hinit->max_size,
hinit->name, hinit->bucket_size, hinit->name);
found:
//重新赋值test[],如果是goto found,和之前的test[]是一样的。
//test[i]表示第i个桶的大小
for (i = 0; i < size; i++) {
test[i] = sizeof(void *);
}
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
key = names[n].key_hash % size;
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
}
//计算表的大小,且保证每个桶起始地址可以是cacheline对齐
len = 0;
for (i = 0; i < size; i++) {
if (test[i] == sizeof(void *)) {
continue;
}
test[i] = (u_short) (ngx_align(test[i], ngx_cacheline_size));
len += test[i];
}
//申请hinit->hash和hinit->hash->buckets基本结构空间
if (hinit->hash == NULL) {
hinit->hash = ngx_pcalloc(hinit->pool, sizeof(ngx_hash_wildcard_t)
+ size * sizeof(ngx_hash_elt_t *));
if (hinit->hash == NULL) {
ngx_free(test);
return NGX_ERROR;
}
buckets = (ngx_hash_elt_t **)((u_char *) hinit->hash + sizeof(ngx_hash_wildcard_t));
} else {
buckets = ngx_pcalloc(hinit->pool, size * sizeof(ngx_hash_elt_t *));
if (buckets == NULL) {
ngx_free(test);
return NGX_ERROR;
}
}
//分配元素空间,且保证元素起始地址是cacheline对齐的
elts = ngx_palloc(hinit->pool, len + ngx_cacheline_size);
if (elts == NULL) {
ngx_free(test);
return NGX_ERROR;
}
elts = ngx_align_ptr(elts, ngx_cacheline_size);
//buckets[]与元素空间关联
for (i = 0; i < size; i++) {
if (test[i] == sizeof(void *)) {
continue;
}
buckets[i] = (ngx_hash_elt_t *) elts;
elts += test[i];
}
for (i = 0; i < size; i++) {
test[i] = 0;
}
//将names[]的KV列表复制到hash表结构中
for (n = 0; n < nelts; n++) {
if (names[n].key.data == NULL) {
continue;
}
key = names[n].key_hash % size;
elt = (ngx_hash_elt_t *) ((u_char *) buckets[key] + test[key]);
elt->value = names[n].value;
elt->len = (u_short) names[n].key.len;
ngx_strlow(elt->name, names[n].key.data, names[n].key.len);
test[key] = (u_short) (test[key] + NGX_HASH_ELT_SIZE(&names[n]));
}
//配置每个桶内最后一个ele->value = NULL;
for (i = 0; i < size; i++) {
if (buckets[i] == NULL) {
continue;
}
elt = (ngx_hash_elt_t *) ((u_char *) buckets[i] + test[i]);
elt->value = NULL;
}
ngx_free(test);
hinit->hash->buckets = buckets;
hinit->hash->size = size;
return NGX_OK;
}
辅助初始化
在使用ngx_int_t ngx_hash_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names, ngx_uint_t nelts)时要求names[]时一个key内容不重复列表。构造内容不重复的列表如果每次采用循环判断当列表巨大时,时间开销较大,nginx提供2个辅助函数ngx_int_t ngx_hash_keys_array_init(ngx_hash_keys_arrays_t *ha, ngx_uint_t type)和ngx_int_t ngx_hash_add_key(ngx_hash_keys_arrays_t *ha, ngx_str_t *key, void *value, ngx_uint_t flags)通过一个简易的链状hash进行重复检查。代码中部分涉及通配符处理的先略过下文再说。
typedef struct {
ngx_uint_t hsize; //简易hash表的桶数量
ngx_pool_t *pool;
ngx_pool_t *temp_pool;
ngx_array_t keys; //精确匹配的key列表
ngx_array_t *keys_hash; //使用二维数组构造的简易hash表,用于检查key是否重复。
...
} ngx_hash_keys_arrays_t;
ngx_int_t
ngx_hash_keys_array_init(ngx_hash_keys_arrays_t *ha, ngx_uint_t type)
{
...
if (ngx_array_init(&ha->keys, ha->temp_pool, asize, sizeof(ngx_hash_key_t))
!= NGX_OK) {
return NGX_ERROR;
}
if (ngx_array_init(&ha->dns_wc_head, ha->temp_pool, asize, sizeof(ngx_hash_key_t)) != NGX_OK) {
return NGX_ERROR;
}
...
}
ngx_int_t
ngx_hash_add_key(ngx_hash_keys_arrays_t *ha, ngx_str_t *key, void *value,
ngx_uint_t flags)
{
...
//计算hash(key)
for (i = 0; i < last; i++) {
if (!(flags & NGX_HASH_READONLY_KEY)) {
key->data[i] = ngx_tolower(key->data[i]);
}
k = ngx_hash(k, key->data[i]);
}
k %= ha->hsize;
/* check conflicts in exact hash */
//在简易hash表的桶中查找是否有相同key
name = ha->keys_hash[k].elts;
if (name) {
for (i = 0; i < ha->keys_hash[k].nelts; i++) {
if (last != name[i].len) {
continue;
}
if (ngx_strncmp(key->data, name[i].data, last) == 0) {
//通过简易hash表判断,找到相同key
return NGX_BUSY;
}
}
} else {
if (ngx_array_init(&ha->keys_hash[k], ha->temp_pool, 4, sizeof(ngx_str_t)) != NGX_OK){
return NGX_ERROR;
}
}
//将key放入简易hash表中
name = ngx_array_push(&ha->keys_hash[k]);
if (name == NULL) {
return NGX_ERROR;
}
*name = *key;
//将不重复的key放入结果ha->keys列表中
hk = ngx_array_push(&ha->keys);
if (hk == NULL) {
return NGX_ERROR;
}
hk->key = *key;
hk->key_hash = ngx_hash_key(key->data, last);
hk->value = value;
return NGX_OK;
...
}
通配符匹配
nginx支持3种形式的通配符匹配。
.example.com可以匹配example.com和www.example.com*.example.com只可以匹配www.example.com不能匹配example.comwww.example.*可以匹配www.example.com
内部是使用3张hash表分别保存精确匹配、头部统配、尾部统配。再查找是也区分精确查找、头部统配查找、尾部统配查找。
typedef struct {
ngx_hash_t hash;
ngx_hash_wildcard_t *wc_head;
ngx_hash_wildcard_t *wc_tail;
} ngx_hash_combined_t;
typedef struct {
ngx_hash_t hash;
void *value;
} ngx_hash_wildcard_t;//这个结构的含义见下文。
void * ngx_hash_find_combined(ngx_hash_combined_t *hash, ngx_uint_t key, u_char *name, size_t len) {
void *value;
//在精确表查找
if (hash->hash.buckets) {
value = ngx_hash_find(&hash->hash, key, name, len);
if (value) {
return value;
}
}
if (len == 0) {
return NULL;
}
//在头部统配表查找
if (hash->wc_head && hash->wc_head->hash.buckets) {
value = ngx_hash_find_wc_head(hash->wc_head, name, len);
if (value) {
return value;
}
}
//在尾部统配表查找
if (hash->wc_tail && hash->wc_tail->hash.buckets) {
value = ngx_hash_find_wc_tail(hash->wc_tail, name, len);
if (value) {
return value;
}
}
return NULL;
}
关于在前缀表和后缀表种如何查找,需要先了解前缀表和后缀表的结构。
为了查找方便,特别是为了实现头部匹配表的查找,对于3中统配形式会进行一定的变化。
.example.com形式的通配符会在 精确表中加入example.com在头部匹配中加入com.example。*.example.com形式的通配符会在头部匹配中加入com.example.www.example.*形式的通配符会在尾部匹配中加入www.example
处理后都就能实现成从左到右分段匹配。处理代码详见ngx_hash_add_key()函数的wildcard:部分该部分有注释,比较好读。
进行初步处理后,就要开始构造分段的hash结构了,相关代码在ngx_hash_wildcard_init()。
示例有以下三个处理后的统配符号和对应的value
{
www.aaa.com : X1,
img.aaa.com : X2,
www.bbb.com. : X3,
}
将保存成形如这样的结构
{
www : {
aaa : {
com : X1
},
bbb : {
com : X2
}
},
img : {
bbb : {
com : X3
}
}
}
相关代码如下:
ngx_int_t
ngx_hash_wildcard_init(ngx_hash_init_t *hinit, ngx_hash_key_t *names,
ngx_uint_t nelts)
{
size_t len, dot_len;
ngx_uint_t i, n, dot;
ngx_array_t curr_names, next_names;
ngx_hash_key_t *name, *next_name;
ngx_hash_init_t h;
ngx_hash_wildcard_t *wdc;
...
for (n = 0; n < nelts; n = i) {
//按.进行拆分
dot = 0;
for (len = 0; len < names[n].key.len; len++) {
if (names[n].key.data[len] == '.') {
dot = 1;
break;
}
}
//第一段保存在curr_names中
name = ngx_array_push(&curr_names);
if (name == NULL) {
return NGX_ERROR;
}
name->key.len = len;
name->key.data = names[n].key.data;
name->key_hash = hinit->key(name->key.data, name->key.len);
name->value = names[n].value;
dot_len = len + 1;
if (dot) {
len++;
}
//非第一段保存在next_names中
next_names.nelts = 0;
if (names[n].key.len != len) {
next_name = ngx_array_push(&next_names);
if (next_name == NULL) {
return NGX_ERROR;
}
next_name->key.len = names[n].key.len - len;
next_name->key.data = names[n].key.data + len;
next_name->key_hash = 0;
next_name->value = names[n].value;
}
for (i = n + 1; i < nelts; i++) {
if (ngx_strncmp(names[n].key.data, names[i].key.data, len) != 0) {
break;
}
//将第一段相同的 后面部分添加到next_name
if (!dot && names[i].key.len > len && names[i].key.data[len] != '.') {
break;
}
next_name = ngx_array_push(&next_names);
if (next_name == NULL) {
return NGX_ERROR;
}
next_name->key.len = names[i].key.len - dot_len;
next_name->key.data = names[i].key.data + dot_len;
next_name->key_hash = 0;
next_name->value = names[i].value;
}
if (next_names.nelts) {
h = *hinit;
h.hash = NULL;
//递归构造表
if (ngx_hash_wildcard_init(&h, (ngx_hash_key_t *) next_names.elts, next_names.nelts) != NGX_OK) {
return NGX_ERROR;
}
wdc = (ngx_hash_wildcard_t *) h.hash;
if (names[n].key.len == len) {
wdc->value = names[n].value;
}
//bit[0]表示最后是否有.
//bit[1]是否指向中间hash结构,即是否为根节点
name->value = (void *) ((uintptr_t) wdc | (dot ? 3 : 2));
} else if (dot) {
name->value = (void *) ((uintptr_t) name->value | 1);
}
}
if (ngx_hash_init(hinit, (ngx_hash_key_t *) curr_names.elts, curr_names.nelts) != NGX_OK)
{
return NGX_ERROR;
}
return NGX_OK;
}
理解内部存放结构后在看ngx_hash_find_wc_tail()与ngx_hash_find_wc_head()就非常简单了,通过value指针的bit[1]判断是否为根节点,根据bit[0]判断后续段是否必须。
void * ngx_hash_find_wc_tail(ngx_hash_wildcard_t *hwc, u_char *name, size_t len)
{
void *value;
ngx_uint_t i, key;
key = 0;
for (i = 0; i < len; i++) {
if (name[i] == '.') {
break;
}
key = ngx_hash(key, name[i]);
}
if (i == len) {
return NULL;
}
value = ngx_hash_find(&hwc->hash, key, name, i);
if (value) {
/*
* the 2 low bits of value have the special meaning:
* 00 - value is data pointer;
* 11 - value is pointer to wildcard hash allowing "example.*".
*/
if ((uintptr_t) value & 2) {
i++;
hwc = (ngx_hash_wildcard_t *) ((uintptr_t) value & (uintptr_t) ~3);
//递归查找
value = ngx_hash_find_wc_tail(hwc, &name[i], len - i);
if (value) {
return value;
}
return hwc->value;
}
return value;
}
return hwc->value;
}