范式的级别
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
范式越高,冗余最低,一般到三范式,再往上,表越多,可能导致查询效率下降。所以有时为了提高运行效率,可以让数据冗余(反三范式,一般某个数据经常被访问时,比如数据表里存放了语文数学英语成绩,但是如果在某个时间经常要得到它的总分,每次都要进行计算会降低性能,可以加上总分这个冗余字段)。
后面的范式是在满足前面范式的基础上,比如满足第二范式的一定满足第一范式。
第一范式(1NF):确保每一列的原子性
如果每一列都是不可再分的最小数据单元,则满足第一范式。
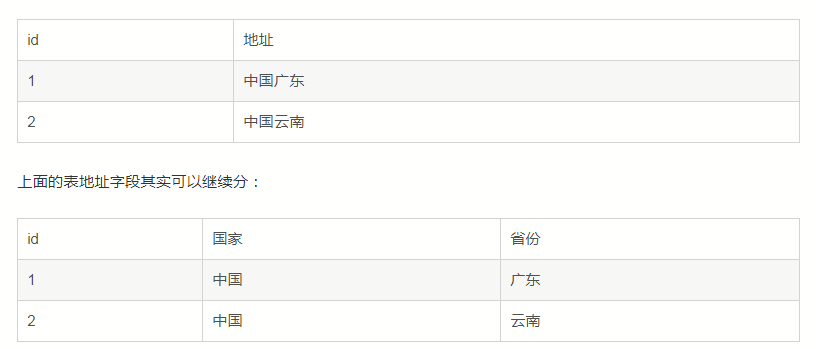
但是具体地址到底要不要拆分 还要看具体情形,比如看看将来会不会按国家或者省市进行分类汇总或者排序,如果需要,最好就拆,如果不需要而仅仅起字符串的作用,可以不拆,操作起来更方便。
第二范式:非主键字段必须依赖于主键字段
如果一个关系满足1NF,并且除了主键以外的其它列,都依赖与该主键,则满足二范式(2NF),第二范式要求每个表只描述一件事。
例如:
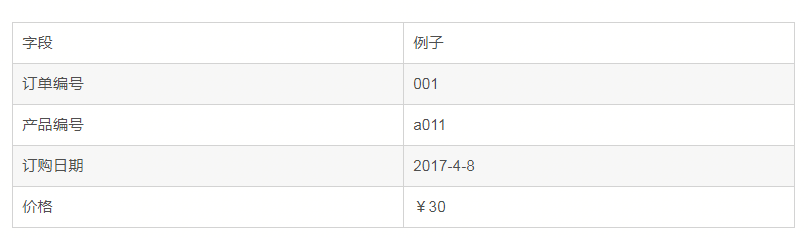
而实际上,产品编号与订单编号并没有明确的关系,订购日期与订单编号有关系,因为一旦订单编号确定下来了,订购日期也确定了,价格与订单编号也没有直接关系,而与产品有关,所以上面的表实际上可以拆分:
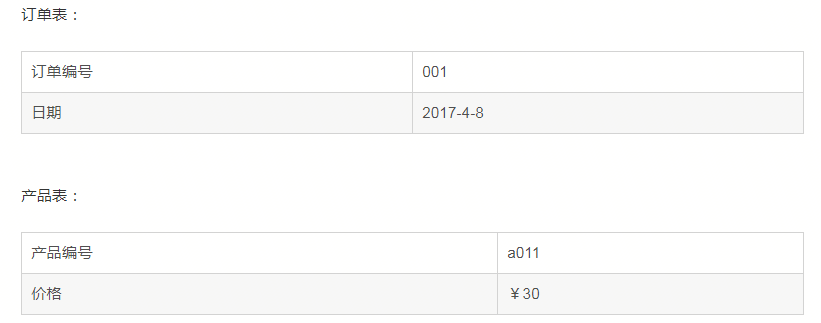
第三范式:在1NF基础上,除了主键以外的其它列都不传递依赖于主键列,或者说: 任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
例如:
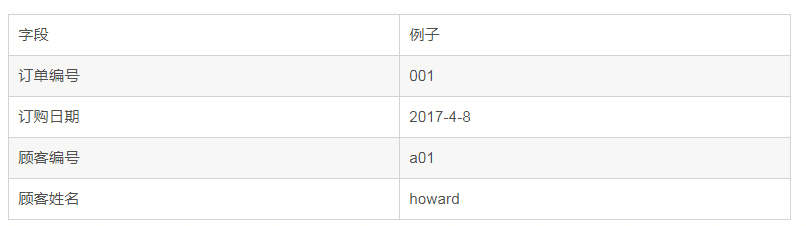
上面的满足第一和第二范式,但是不满足第三范式,原因如下:
通过顾客编号可以确定顾客姓名,通过顾客姓名可以确定顾客编号,即在这个订单表里,这两个字段存在传递依赖,只需要一个就够了。
又如:
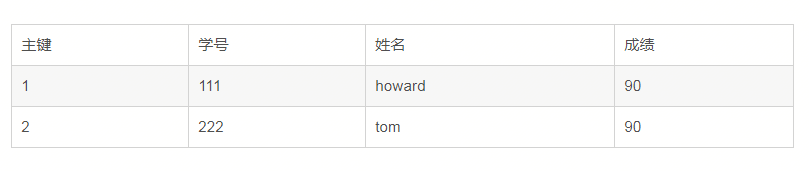
上面的表,学号和姓名存在传递依赖,因为(学号,姓名)->成绩,学号->成绩,姓名->成绩。所以学号和姓名有一个冗余了,只需要保留一个。
参考文章:https://blog.csdn.net/zymx14/article/details/69789326