基于DDD领域驱动设计的思想,在开发具体系统时,需要先建立不同的层级包。主要是梳理不同层面(应用层,领域层,基础设施层,展示层)包括的功能目录。
分层
1:展示层
展现层(用户接口层):负责接受Web请求,然后将请求路由给Application层执行,并返回结果,其载体通常是DTO(Data Transfer Object)。
展示层有两个任务:
1):从用户处接收命令操作,改变底层系统状态。
2):从用户处接收查询操作,将底层系统状态以合适的形式呈现给用户。
项目目录
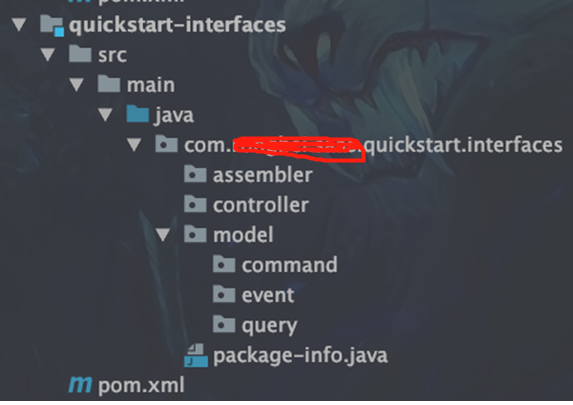
1)命令目录(command): 对象命名为XxxCommand,指调用方明确想让系统操作的指令,其预期是对一个系统有影响,也就是写操作。通常来讲指令需要有一个明确的返回值(如同步的操作结果,或异步的指令已经被接受)。
2)查询目录(query): 对象命名为XxxQuery,指调用方明确想查询的东西,包括查询参数、过滤、分页等条件,其预期是对一个系统的数据完全不影响的,也就是只读操作。
3)事件目录(event): 对象命名为XxxEvent,指一件已经发生过的既有事实,需要系统根据这个事实作出改变或者响应的,通常事件处理都会有一定的写操作。事件处理器不会有返回值。这里的Event更多是外部一种通知机制而已。
4)控制层(Controller): 提供restful接口,供外部系统调用
5)转换(assembler):实体(Entity)转变为 DTO的方法,基于org.mapstruct.Mapper实现
规范
ApplicationService的接口入参只能是一个Command、Query或Event对象,CQE对象需要能代表当前方法的语意。唯一可以的例外是根据单一ID查询的情况,可以省略掉一个Query对象的创建
CQE,DTO,都是Value Object,但是从语义上来看有比较大的差异,主要是从命名上区别出来。
1):CQE:CQE对象是ApplicationService的输入,是有明确的“意图”的,所以这个对象必须保证其"正确性"。为验证部分字段的格式,必填性,可基于Spring Validation等模式做基础数据验证。
2):DTO:Dto对象只是数据容器,只是为了和外部交互,所以本身不包含任何逻辑,只是贫血对象。
2:应用层
主要负责获取输入,组装上下文,做输入校验,调用领域层做业务处理,如果需要的话,发送消息通知。当然,层次是开放的,若有需要,应用层也可以直接访问基础实施层。相对于领域层,应用层是很薄的一层,应用层定义了软件要完成的任务,要尽量简单.它不包含任务业务规则或知识, 为下一层的领域对象协助任务、委托工作。
对外:为展现层提供各种应用功能(service)。
对内:调用领域层(领域对象或领域服务)完成各种业务逻辑任务
项目目录
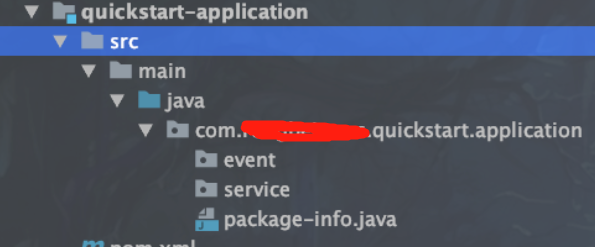
事件(event): 对象命名为XxxEvent,跨聚合根,或部分业务处理完成后,需要通知其他模块的,本例采用 Spring event模式
应用服务(service): 对象命名为XxxService,应用层的服务
规范
一个应用层通常包括以下三种服务:
1)业务处理类:XxxCommandService
2)业务查询类:XxxQueryService
3)业务事件类:XxxEventService
3:领域层
主要是封装了核心业务逻辑,并通过领域服务(Domain Service)和领域对象(Entities)的函数对外部提供业务逻辑的计算和处理。
领域层主要负责表达业务概念,业务状态信息和业务规则。是一个纯内存化的操作。Domain层是整个系统的核心层,几乎全部的业务逻辑会在该层实现。领域层不关注数据是如何落地存储的,领域层也不直接调用底层仓库接口保存数据,但是可以进行查询操作。
项目目录
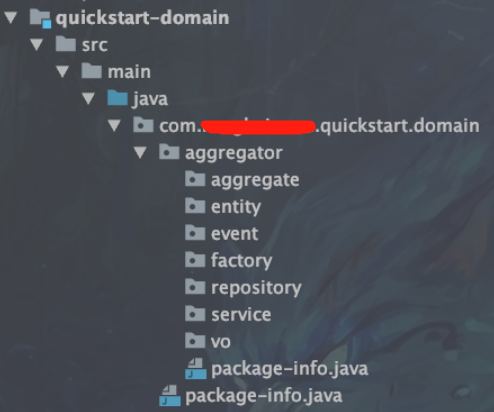
规范
1)实体(entity): 对象命名为XxxE,具有唯一标识的对象,所有实体统一用E作为后缀,如PersonE
2)工厂(factory): 接口命名规则为XxxFactory,创建复杂的实体,聚合根,只做创建处理
3)值对象(vo): 对象命名为XxxV,无需唯一标识的对象,所有值对像统一同V作为后缀 ,如PersonV,实体的主键编码以Id结尾
4)领域服务(service): 接口命名规则为XxxDomainService,一些行为无法归类到实体对象或值对象上,本质是一些操作,而非事物(与本例中domain/service包下的含义不同)
5)仓储(repository): 接口命名规则为XxxRepository,创建复杂对象,隐藏创建细节,提供查找和持久化对象的方法,领域层仅编写仓库的接口,接口实现放在基础层
6)聚合/聚合根(aggregates,aggregate roots): 对象命名为XxxA,聚合是指一组具有内聚关系的相关对象的集合,每个聚合都有一个root和boundary,所有聚合统一用A作为后缀,如PersonA
4:基础层
1)为应用层 传递消息(比如通知)
2)为应用层 提供持久化机制(最底层的实现)
项目目录
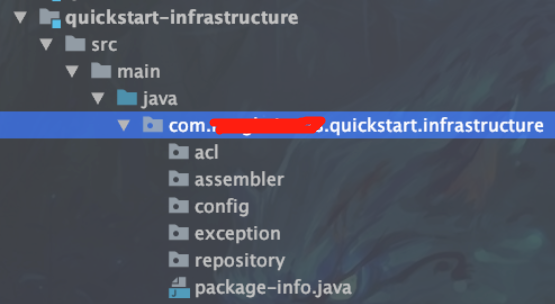
1)防腐层(acl): 实体对接外部系统,实体与外部系统之间,不同领域之间,不同的参数转换,语义转换等
2)转换层(assembler): 数据转换工具类,如DO(Data Object)转换为实体,实体转换为数据表(DO)对象,基于org.mapstruct.Mapper实现
3)仓库层(repository): 仓库实现层,实体与DB之间存储的功能层
4)异常管理(exception): 封装具体业务的异常处理信息
5)配置模块(config): 封装配置信息,包括一些基础静态字段,基于阿波罗等获取的配置信息
5:其他
1)实体保存时,仓库层的入参不能为基础的数据表对象,入参对象应设置为实体。
2)其他命令操作时,应用层调用仓库层保存数据,入参可根据实际的情况传入对应的实体或入参命令对象(比如只是修改数据的个别字段可传入修改命令,修改大量字段信息,传入实体)。
3)领域层只做纯内存的业务规则操作,原则上不能在领域层中直接调用仓库层存储数据。
4)应用层的出参设置为DTO或基础数据对象(如主键编码),不能直接返回实体;
5)当一个业务涉及到多个实体时,不能在一个实体中直接调用另外一个实体(聚合根可调用内部的子实体),应该基于应用层或第三方领域服务协调处理。
6)明确各个层的职能,不要混用。
7)领域层做业务规则处理,针对不同的规则场景,建议采用策略设计模式,多用设计模式实现领域服务便于系统后续的扩展和调整。
8)涉及到主子记录的情况,一般建立聚合根,基于聚合根统一的保存数据。
9)当业务需要多个实体同时处理时,可在应用层统一加上事务管理。
10)针对一些基础配置的需求,无业务逻辑,或比较简单的业务(CRUD),采用DDD模式也很费力,此刻不一定非要使用DDD模式。