银行的面试官问了个简单的问题,满足第二范式,但是不满足第三范式的例子
首先我们要搞清楚 第一,第二,第三范式的定义
网上很多,但是都不好理解我这里简单总结下
1、第一范式,
定义:实体表中的数据(字段)不可再分; 对数据项(字段)的要求是具备独立性,不可再分;
重点:就是列不能再拆分了,比如你定义的某个列 叫信息
举个栗子:
/*学号 年龄 信息*/
Sno Sage Sinfo
1001 19 陕西省西安市,电话:10086
1001 20 陕西,宝鸡
看看第三列里面的信息,里面包罗万象,很明显不是原子的,这就不满足第一范式;
2、第二范式:
定义:
1、每张表必须要有主属性(主键)唯一,该表上的其他字段都可以由该字段来推导其相关内容;
2、其它属性数据项(非主键)要完全依赖于主属性(主键);
重点:
1、满足第一范式,必须有主键;
2、只有当一个表中,主码由两个或以上的属性组成的时候,才会出现不符合第二范式的情况。
其实就是 联合主键才会出现不符合第二的情况,后面的列只依赖于联合主键中的某一个键;
举个栗子:(以下例子 不符合 第二范式)
/*学号 课程号 得分 课程名*/
Sno Cno Score Sname
1001 001 99 数据库
主键: Sno,Cno (注意是联合主键)
不满足原因:Sname不完全依赖于码,课程名部分依赖于码Cno。
3、第三范式
定义:所有的非主属性(非主键)都直接由其它表的主属性(主键)推导生成,而不需要传递依赖。
重点:
1)满足第二范式。
2)不能传递依赖,非主属性不能部分或者传递依赖于码。
举个栗子: (异常的情况,就是冗余数据 ,比如我们之前的系统,场馆里面的座位,冗余的场馆的name,位置等信息)
表: 学号, 姓名, 年龄, 学院名称, 学院电话
因为存在依赖传递: (学号) → (学生)→(所在学院) → (学院电话) 。
可能会存在问题:
数据冗余:有重复值;更新异常:有重复的冗余信息,修改时需要同时修改多条记录,否则会出现数据不一致的情况 。
正确做法:
学生:(学号, 姓名, 年龄, 所在学院);
学院:(学院, 电话)。
第一范式: (1NF)
实体表中的数据(字段)不可再分; 对数据项(字段)的要求是具备独立性,不可再分;
第二范式:(2NF)
1、每张表必须要有主属性(主键)唯一,该表上的其他字段都可以由该字段来推导其相关内容;
2、其它属性数据项(非主键)要完全依赖于主属性(主键);
第三范式:(3NF)
所有的非主属性(非主键)都直接由其它表的主属性(主键)推导生成,而不需要传递依赖(第三范式重点是不能传递依赖)。
数据库范式第一第二第三范式的区别是:1、第一范式就是无重复的列;2、第二范式就是属性完全依赖于主键;3、第三范式就是属性不依赖于其它非主属性。
第一范式(1NF)无重复的列
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。
1NF的定义为:符合1NF的关系中的每个属性都不可再分
下表所示情况,便不符合1NF的要求:
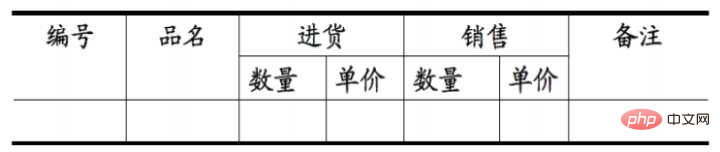
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
第二范式(2NF)属性完全依赖于主键
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。这个惟一属性列被称为主关键字或主键、主码。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。简而言之,第二范式就是属性完全依赖于主键。
第三范式(3NF)
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在的员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。
简而言之,第三范式就是属性不依赖于其它非主属性。 也就是说, 如果存在非主属性对于码的传递函数依赖,则不符合3NF的要求。