在开发环境下实现第一个程序wordcount
1、下载和配置scala,注意不要下载2.13,在spark-core明确支持scala2.13前,使用2.12或者2.11比较好。
https://www.scala-lang.org/download/
2、windows环境下的scala配置,可选
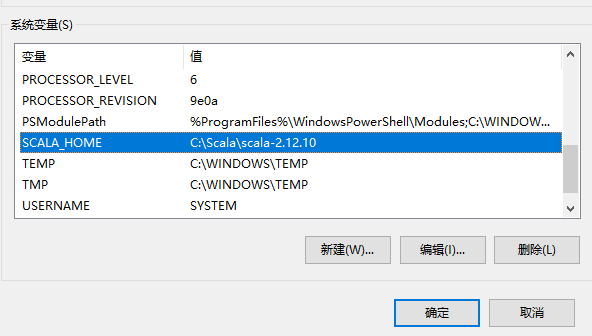

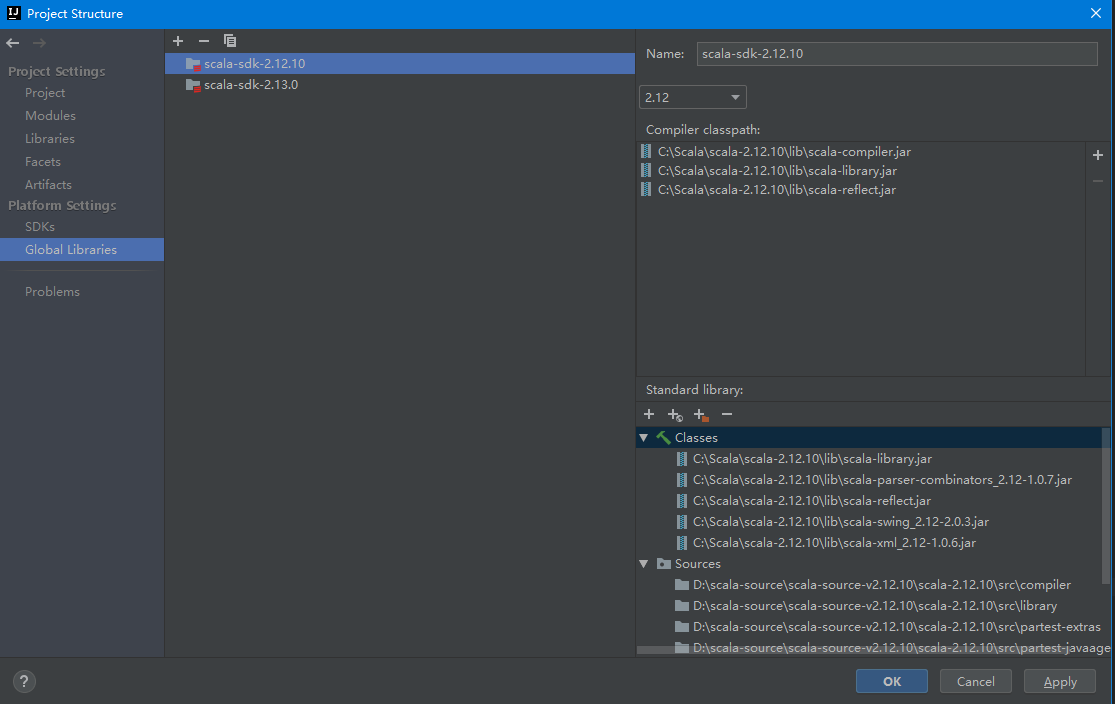
3、开发工具IDEA环境设置,全局环境添加scala的sdk,注意scala的源码要手动下载和添加
4、在IDEA中新建MAVEN项目,添加scala框架支持

5、在MAVEN工程添加spark-core依赖,注意根据自己需要选择对应的版本,版本不对很可能会出现运行期异常。
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>2.4.4</version> </dependency> </dependencies>
6、wordcount代码
在项目根目录(与src平级)中新建一个input目录,里面放入需要统计词频的文本文件
package com.home.spark import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { //获取环境 val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkWordCount") //获取上下文 val sc: SparkContext = new SparkContext(conf) //读取每一行 val lines: RDD[String] = sc.textFile("input") //扁平化,将每行数据拆分成单个词(自定义业务逻辑) val words: RDD[String] = lines.flatMap(_.split(" ")) //结构转换,对每个词获得初始词频 val wordToOne: RDD[(String, Int)] = words.map((_,1)) //词频计数 val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_+_) //按词频数量降序排序 val wordToSorted: RDD[(String, Int)] = wordToSum.sortBy(_._2,false) //数据输出 val result: Array[(String, Int)] = wordToSorted.collect() //打印 result.foreach(println) //关闭上下文 sc.stop() } }