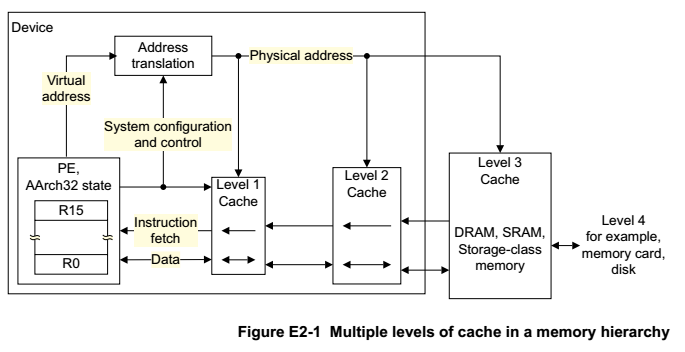
《ARM Architecture Reference Manual ARMv8-A》里面有Memory层级框架图,从中可以看出L1、L2、DRAM、Disk、MMU之间的关系,以及他们在整个存储系统中扮演的角色。
涉及到的相关文档有:
《ARM Architecture Reference Manual ARMv8-A》:E2 The AArch32 Application Level Memory Model和G3 The AArch32 System Level Memory Model两个章节,从总体架构上介绍了ARMv8-A Memory系统。
《Cortex-A53 TRM》:6 Level 1 Memory System、5 Memory Management Unit、7 Level 2 Memory System三个章节介绍了MMU/L1/L2三个模块在A53上的实现。
具体到MMU:
《MMU-500 TRM》:MMU-500技术参考手册。
《ARM SMMUv2》:System MMU 架构规格 version 2.0。
具体到L2:
《L2C-310 TRM》:L2控制器技术参考手册。
在Linux内核中查看L1/L2/L3缓存:
lscpu ... L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 6144K ... 或者读取节点: cat /sys/devices/system/cpu/cpu0/cache/indexx/size cat /sys/devices/system/cpu/cpu0/cache/indexx/level
ARM Architecture Reference Manual ARMv8
ARM Corelink MMU-500 System Memory Management Unit Revision r2p4
1 Introduction
VA:Virtual Address
PA:Physical Address
IPA:Intermediate Physical Address
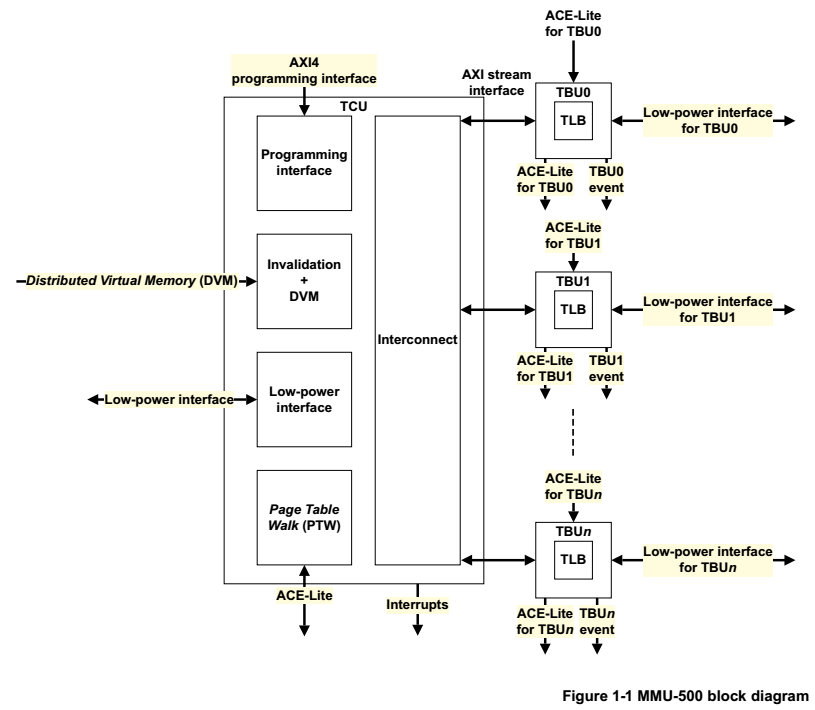
MMU-500是系统级的存储管理单元,它基于自身寄存器和转换表中的地址映射和存储器属性,将虚拟地址转换成物理地址。
将这个转换过程分为两个阶段:
- Stage 1 - 将输入的VA转换成PA或者IPA输出。
- Stage 2 - 将IPA转换成PA。
- 或者结合Stage 1和Stage 2将输入的VA->IPA->PA。
MMU-500可以将 转换表查找结果缓存到TLB中。
MMU-500包含一下主要部件:
TBU(Translation Buffer Unit) - 包含缓存页表的TLB,MMU-500给每个Master配置了一个TBU,专属于Master。
TCU(Translation Control Unit) - 控制和管理地址转换,一个MMU-500仅包含一个TCU。
Interconnect - 多TBU到TCU之间的连接。
Master可能包括GPU、Video engines、DMA Controller、LCD Controller、Network Controller等。
2 Functional description
2.1 About the functions
从Figure 1-1可知,一个MMU有多个TBU和一个TCU。TBU包含TLB,主要用于缓存经常使用的地址范围;TCU主要查找页表。
2.2 Interfaces
L2 Cache
摘录A53规格书中关于L2 Cache一段属性描述:
Optional tightly-coupled L2 cache that includes:
— Configurable L2 cache size of 128KB, 256KB, 512KB, 1MB and 2MB.---多种大小可配置
— Fixed line length of 64 bytes.------------------------------------每条Cache Line大小是64Bytes
— Physically indexed and tagged cache.
— 16-way set-associative cache structure.
— Optional ACP interface if an L2 cache is configured.
— Optional ECC protection
Cache Line可以简单的理解为CPU Cache中的最小缓存单位。
大小为64Bytes大小的Cache Line,128KB的L2 Cache,一共有128KB/64B=2048个Cache Line。
那么Cache存放规则是什么呢?Fully Associative、Direct Mapped、N-Way Set Associative。
Fully Associative是全关联的意思:如果在一个Cache集内,任何一个地址的数据都可以缓存在任何一个Cache Line里,那么我们称这个Cache是Fully Associative。
给一个内存地址,要知道他是否存在于Cache中,就需要遍历所有Cache Line并比较缓存内容的地址。
Direct Mapped给定一个内存地址,就唯一确定了一条Cache Line。以4GB内存空间,128KB L2 Cache,64B Cache Line,那么4GB/(128KB/64B)=2MB共用一条Cache Line,使用率太低。
N-Way Set Associative是吧一个缓存按照N个Cache Line作为一组(Set),缓存按组划为等分。
同样以上面32位系统中L2 Cache规格为例,低6位是Cache Line中的偏移量;128KB/16/64B=128,中间7位表示Cache组号(Set Index);剩余高19位就是内存地址的唯一ID。
给定一个内存地址可以唯一对应一个Set,对于Set中只需遍历16个元素就可以确定对象是否在缓存中。
128KB的Cache,分成128个Set;一个Set包含16根Cache Line;每根Cache Line大小64Byte。
即在连续内存地址中每Cache Line Offset+Set Index长度8KB就会出现一个处于同一Cache Set的缓存对象,争抢一个仅有16个空位的缓存池。
每Cache Line Offset+Set Index+16 Way=128KB才会导致一个Set内的Conflict。
L2C-310在Linux
#
# Processor Type
#
CONFIG_CPU_V7=y
CONFIG_CPU_32v6K=y
CONFIG_CPU_32v7=y
CONFIG_CPU_ABRT_EV7=y
CONFIG_CPU_PABRT_V7=y
CONFIG_CPU_CACHE_V7=y
CONFIG_CPU_CACHE_VIPT=y
CONFIG_CPU_COPY_V6=y
CONFIG_CPU_TLB_V7=y
CONFIG_CPU_HAS_ASID=y
CONFIG_CPU_CP15=y
CONFIG_CPU_CP15_MMU=y
#
# Processor Features
#
CONFIG_OUTER_CACHE=y CONFIG_OUTER_CACHE_SYNC=y CONFIG_MIGHT_HAVE_CACHE_L2X0=y CONFIG_CACHE_L2X0=y CONFIG_CACHE_PL310=y CONFIG_ARM_L1_CACHE_SHIFT_6=y CONFIG_ARM_L1_CACHE_SHIFT=6 CONFIG_ARM_DMA_MEM_BUFFERABLE=y CONFIG_ARM_NR_BANKS=8 CONFIG_CPU_HAS_PMU=y CONFIG_MULTI_IRQ_HANDLER=y # CONFIG_ARM_ERRATA_430973 is not set # CONFIG_ARM_ERRATA_458693 is not set # CONFIG_ARM_ERRATA_460075 is not set CONFIG_PL310_ERRATA_588369=y CONFIG_ARM_ERRATA_720789=y CONFIG_PL310_ERRATA_727915=y CONFIG_ARM_ERRATA_743622=y CONFIG_ARM_ERRATA_751472=y CONFIG_PL310_ERRATA_753970=y CONFIG_ARM_ERRATA_754322=y CONFIG_PL310_ERRATA_769419=y # CONFIG_ARM_ERRATA_775420 is not set # CONFIG_FIQ_DEBUGGER is not set
在setup_processor中将cache相关操作函数赋给cpu_cache,同时还包括cpu_tld和cpu_user。
start_kernel--> setup_arch--> setup_processor--> static void __init setup_processor(void) { ... list = lookup_processor_type(read_cpuid_id()); ... processor = *list->proc; cpu_tlb = *list->tlb; cpu_user = *list->user; cpu_cache = *list->cache; ... }
内核对这些函数的使用又进行了封装,同时对应底层汇编(以v7为例)。在arch/arm/mm/proc-v7.S中实现了汇编函数。
extern struct cpu_cache_fns cpu_cache; #define __cpuc_flush_icache_all cpu_cache.flush_icache_all #define __cpuc_flush_kern_all cpu_cache.flush_kern_all #define __cpuc_flush_user_all cpu_cache.flush_user_all #define __cpuc_flush_user_range cpu_cache.flush_user_range #define __cpuc_coherent_kern_range cpu_cache.coherent_kern_range #define __cpuc_coherent_user_range cpu_cache.coherent_user_range #define __cpuc_flush_dcache_area cpu_cache.flush_kern_dcache_area /* * These are private to the dma-mapping API. Do not use directly. * Their sole purpose is to ensure that data held in the cache * is visible to DMA, or data written by DMA to system memory is * visible to the CPU. */ #define dmac_map_area cpu_cache.dma_map_area #define dmac_unmap_area cpu_cache.dma_unmap_area #define dmac_flush_range cpu_cache.dma_flush_range
关于TCM
TCM(Tighyly Coupled Memory,紧耦合内存)是一个固定大小的RAM,紧密地耦合至处理器内核,提供与cache相当的性能。
相比于cache的有点是,程序代码可以精确地控制什么函数或什么代码放在哪儿。当然TCM永远不会被踢出主存储器,他会有一个用户预设性能,而不是cache那样是统计特性的提高。
TCM对于以下几种情况的代码是非常有用、也是需要的:可预见的实时处理(中断处理)、时间可预见(加密算法)、避免cache分析(加密算法)、或者只是要求高性能的代码(编解码功能)。
随着cache大小的增加以及总线性能的规模,TCM将会变得越来越不重要,但是他提供了一个让你权衡的机会。
如何使用TCM?
再支持TCM的处理上,包含头文件#include <asm/tcm.h>。
使用__tcmdata、__tcmconst、__tcmfunc、__tcmlocalfunc修饰符,将变量、函数放到特定的tcm段中。
还可以使用tcm_alloc/tcm_free申请释放内存。
延伸阅读:
《对ARM紧致内存TCM的理解》- 关于TCM的介绍,以及和Cache相比的优劣。
《内核中tcm(arm)与sram代码》- 如何使用TCM。