说明:
M3,M4内核都支持硬件位带操作,M7内核不支持。
硬件位带操作优势
优势1:
比如我们在地址0x2000 0000定义了一个变量unit8_t a, 如果我们要将此变量的bit0清零,而其它bit不变。
a & = ~0x01
这个过程就需要读变量a,修改bit0,然后重新赋值给变量a,也就是读 - 修改 - 写经典三部曲,如果我们使用硬件位带就可以一步就完成,也就是所谓的原子操作,优势是不用担心中断或者RTOS任务打断。
优势2:
操作便捷,适合用于需要频繁操作修改的场合,移植性强。不频繁的直接标准库或者HAL库配置即可。
背景知识
这个点知道不知道都没有关系,不影响我们使用硬件位带,可以直接看下面案例的操作方法,完全不需要用户去了解。
位带操作就是对变量每个bit的操作,以M4内核的STM32F4为例:
(1)将1MB地址范围 0x20000000 - 0x200FFFFF 映射到32MB空间范围0x22000000 - 0x23FFFFFF ----> 这个对应STM32F4的通用RAM空间。
也就是说1MB空间每个bit都拓展为32bit来访问控制

下面这个图非常具有代表性。
0x20000000地址的字节变量 bit0 映射到0x22000000来控制。
0x20000000地址的字节变量 bit1 映射到0x22000004来控制。
0x20000000地址的字节变量 bit2 映射到0x22000008来控制。
..........依次类推

(2)将1MB地址范围 0x40000000 - 0x400FFFFF 映射到32MB空间范围0x42000000 - 0x43FFFFFF ----> 这个对应STM32F4的外设空间。
同样也是1MB空间每个bit都拓展为32bit来访问控制

(3)举例,比如访问0x2000 0010地址里面字节变量的bit2
那么实际要访问的就是:
bit_word_addr = bit_band_base + (byte_offset x 32) + (bit_number × 4)
0x22000208 = 0x22000000 + (0x10*32) + (2*4)
通过对地址空间0x22000208 进行赋值为0x01就表示bit2置位,赋值为0x00就表示bit2清零,对这个地址空间读取操作就可以反应bit2的数值。
超简单实现方案和四个经典案例
这种硬件未带让用户去使用非常不方便,还需要倒腾地址计算。
这里以MDK为例,提供一种IDE支持的,直接加后缀__attribute__((bitband))即可,对于M3和M4可以直接转换为硬件位带实现。
案例1:超简单控制RAM空间变量:
定义:
typedef struct { uint8_t bit0 : 1; uint8_t bit1 : 1; uint8_t bit2 : 1; uint8_t bit3 : 1; uint8_t bit4 : 1; uint8_t bit5 : 1; uint8_t bit6 : 1; uint8_t bit7 : 1; } TEST __attribute__((bitband)); TEST tTestVar;
我们定义了一个8bit的变量tTestVar,控制每个bit的方法如下:
tTestVar.bit0 = 1; tTestVar.bit1 = 1; tTestVar.bit2 = 1; tTestVar.bit3 = 0; tTestVar.bit4 = 0; tTestVar.bit5 = 1; tTestVar.bit6 = 1; tTestVar.bit7 = 1;
看汇编,已经修改为硬件位带:

案例2:超简单控制GPIO输入输出寄存器:
GPIO里面最常用的就是输入输出。
GPIO输出寄存器定义如下,每个bit控制一个IO引脚。

我们软件定义如下:
typedef struct { uint16_t ODR0 : 1; uint16_t ODR1 : 1; uint16_t ODR2 : 1; uint16_t ODR3 : 1; uint16_t ODR4 : 1; uint16_t ODR5 : 1; uint16_t ODR6 : 1; uint16_t ODR7 : 1; uint16_t ODR8 : 1; uint16_t ODR9 : 1; uint16_t ODR10 : 1; uint16_t ODR11 : 1; uint16_t ODR12 : 1; uint16_t ODR13 : 1; uint16_t ODR14 : 1; uint16_t ODR15 : 1; uint16_t Reserved : 16; } GPIO_ORD __attribute__((bitband)); GPIO_ORD *GPIOA_ODR = (GPIO_ORD *)(&GPIOA->ODR); GPIO_ORD *GPIOB_ODR = (GPIO_ORD *)(&GPIOB->ODR); GPIO_ORD *GPIOC_ODR = (GPIO_ORD *)(&GPIOC->ODR); GPIO_ORD *GPIOD_ODR = (GPIO_ORD *)(&GPIOD->ODR); GPIO_ORD *GPIOE_ODR = (GPIO_ORD *)(&GPIOE->ODR); GPIO_ORD *GPIOF_ODR = (GPIO_ORD *)(&GPIOF->ODR); GPIO_ORD *GPIOJ_ODR = (GPIO_ORD *)(&GPIOJ->ODR); GPIO_ORD *GPIOK_ODR = (GPIO_ORD *)(&GPIOK->ODR);
GPIO输入寄存器定义如下:

我们软件定义如下:
typedef struct { uint16_t IDR0 : 1; uint16_t IDR1 : 1; uint16_t IDR2 : 1; uint16_t IDR3 : 1; uint16_t IDR4 : 1; uint16_t IDR5 : 1; uint16_t IDR6 : 1; uint16_t IDR7 : 1; uint16_t IDR8 : 1; uint16_t IDR9 : 1; uint16_t IDR10 : 1; uint16_t IDR11 : 1; uint16_t IDR12 : 1; uint16_t IDR13 : 1; uint16_t IDR14 : 1; uint16_t IDR15 : 1; uint16_t Reserved : 16; } GPIO_IDR __attribute__((bitband)); GPIO_IDR *GPIOA_IDR = (GPIO_IDR *)(&GPIOA->IDR); GPIO_IDR *GPIOB_IDR = (GPIO_IDR *)(&GPIOB->IDR); GPIO_IDR *GPIOC_IDR = (GPIO_IDR *)(&GPIOC->IDR); GPIO_IDR *GPIOD_IDR = (GPIO_IDR *)(&GPIOD->IDR); GPIO_IDR *GPIOE_IDR = (GPIO_IDR *)(&GPIOE->IDR); GPIO_IDR *GPIOF_IDR = (GPIO_IDR *)(&GPIOF->IDR); GPIO_IDR *GPIOJ_IDR = (GPIO_IDR *)(&GPIOJ->IDR); GPIO_IDR *GPIOK_IDR = (GPIO_IDR *)(&GPIOK->IDR);
实际操作效果动态,注意看调试状态寄存器变化,控制GPIOA的PIN0到PIN3
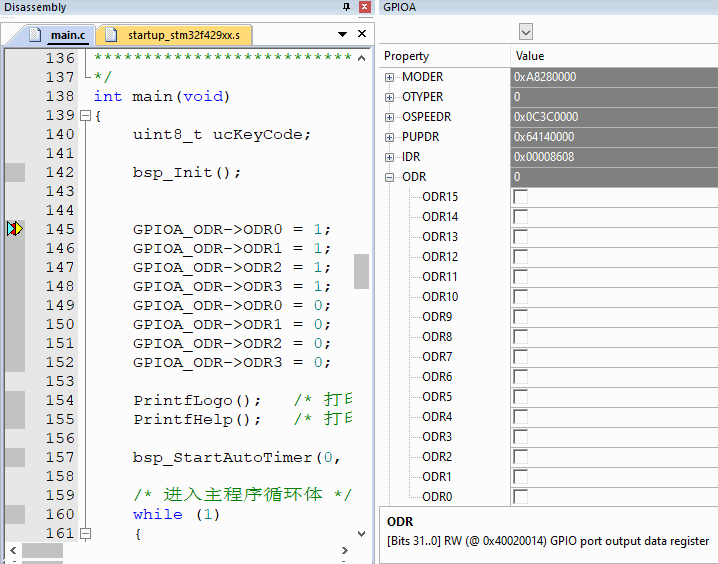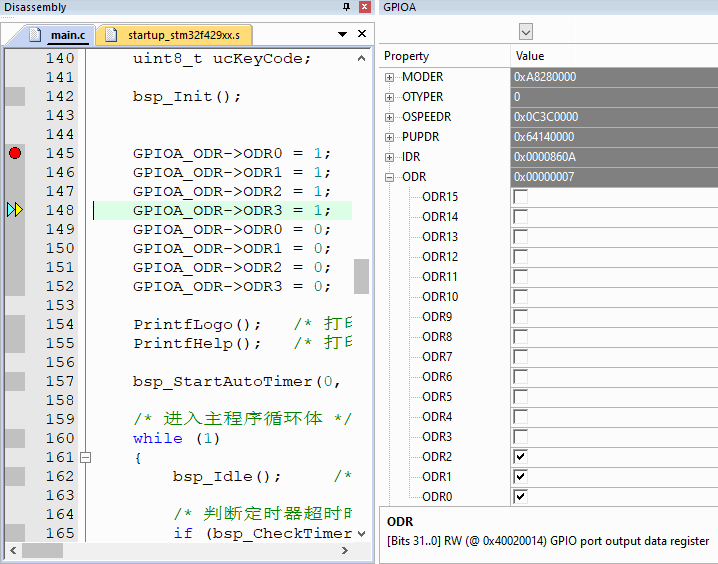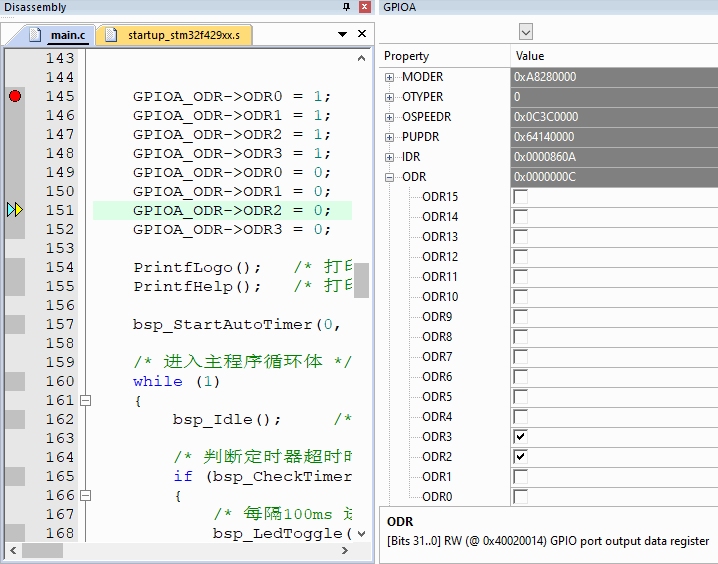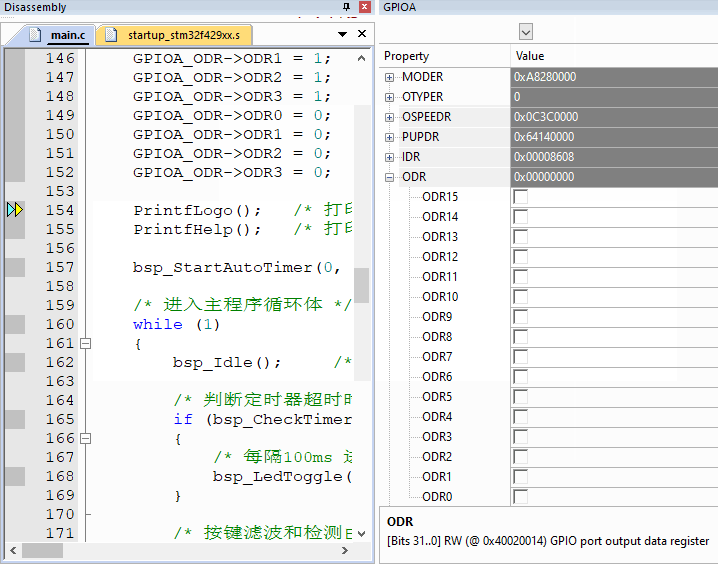
案例3:超方便的寄存器修改:
比如定时器TIM1的CR寄存器:

我们的定义如下:
typedef struct { uint16_t CEN : 1; uint16_t UDIS : 1; uint16_t URS : 1; uint16_t OPM : 1; uint16_t DIR : 1; uint16_t CMS : 2; uint16_t APRE : 1; uint16_t CKD : 2; uint16_t Reserved : 6; } TIM_CR1 __attribute__((bitband)); TIM_CR1 *TIM1_CR1 = (TIM_CR1 *)(&TIM1->CR1);
实际操作动态效果,注意看调试状态寄存器变化,设置TIM1 CR1寄存器的每个bit控制:
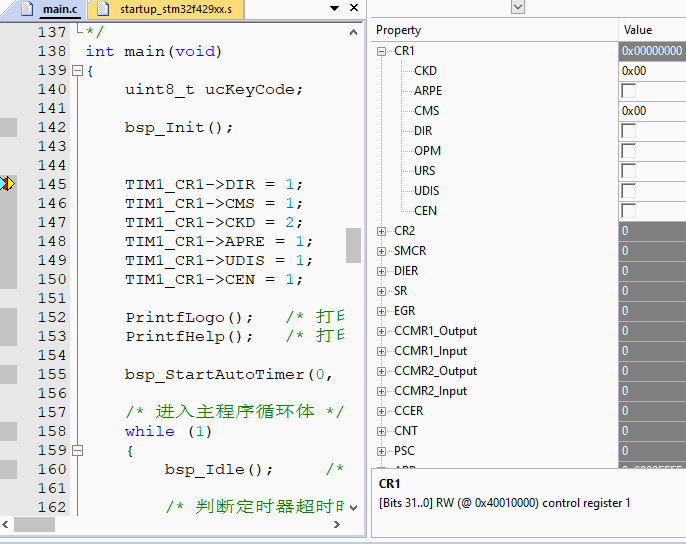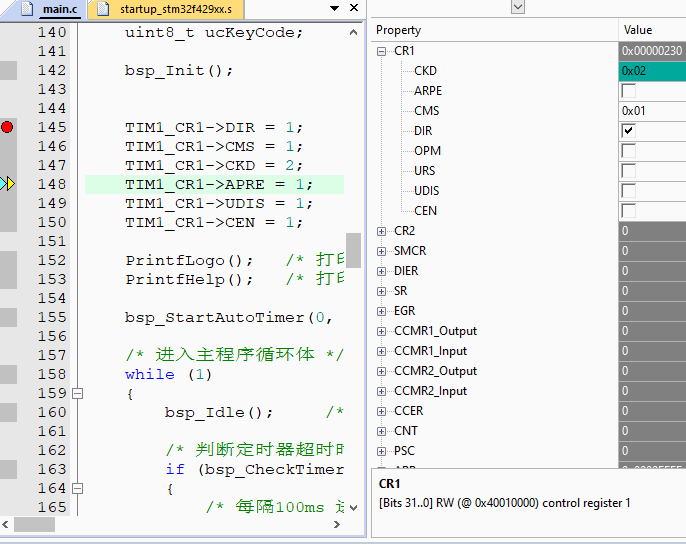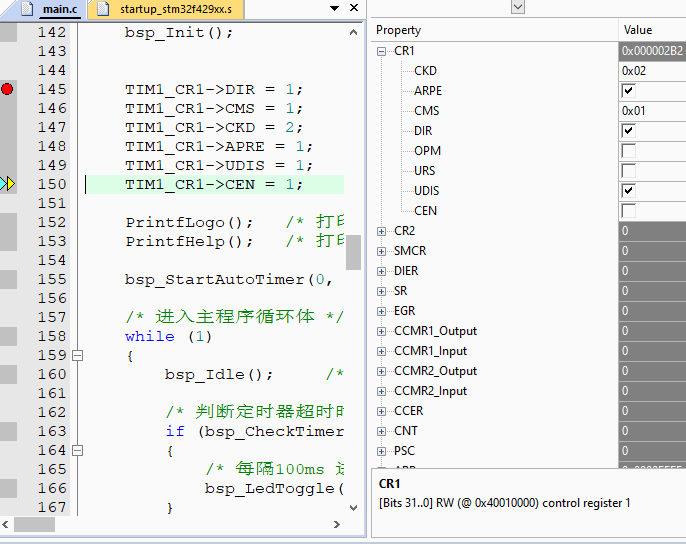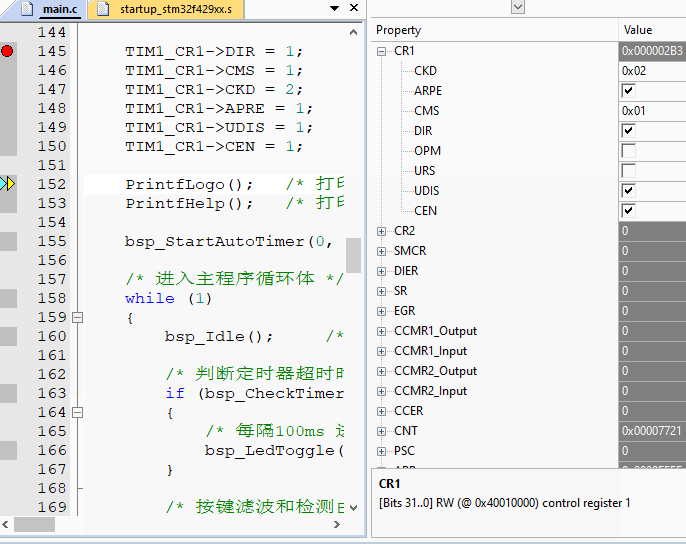
由于标准库,HAL库配置这些已经非常方便了,我们再使用这种方式意义不是很大,但对于需要频繁操作的地方,这种方式就非常好使了,言简意赅,移植性强,强力推荐,而且是原子操作方式,不用怕中断打断。
案例4:应用进阶:
最后我们来个进阶,比如我们通过32位带宽的FMC总线扩展出来32个GPIO,如果我们采用如下使用方式就非常不直观
#define HC574_PORT *(uint32_t *)0x64001000
操作bit1 =0清零,就需要如下操作:
HC574_PORT &= ~(1<<1);
操作bit2和bit10置位,就需要如下操作:
HC574_PORT |= ( ( 1<< 2) | (1<<10))
这种操作会导致以后的代码修改非常不便,别人移植使用也非常不方便。如果我们改成如下方式,就方便太多了。
typedef struct { uint32_t tGPRS_TERM_ON : 1; uint32_t tGPRS_RESET :1; uint32_t tNRF24L01_CE :1; uint32_t tNRF905_TX_EN :1; uint32_t tNRF905_TRX_CE :1; uint32_t tNRF905_PWR_UP :1; uint32_t tESP8266_G0 :1; uint32_t tESP8266_G2 :1; uint32_t tLED1 :1; uint32_t tLED2 :1; uint32_t tLED3 :1; uint32_t tLED4 :1; uint32_t tTP_NRST :1; uint32_t tAD7606_OS0 :1; uint32_t tAD7606_OS1 :1; uint32_t tAD7606_OS2 :1; uint32_t tY50_0 :1; uint32_t tY50_1 :1; uint32_t tY50_2 :1; uint32_t tY50_3 :1; uint32_t tY50_4 :1; uint32_t tY50_5 :1; uint32_t tY50_6 :1; uint32_t tY50_7 :1; uint32_t tAD7606_RESET :1; uint32_t tAD7606_RANGE :1; uint32_t tY33_2 :1; uint32_t tY33_3 :1; uint32_t tY33_4 :1; uint32_t tY33_5 :1; uint32_t tY33_6 :1; uint32_t tY33_7 :1; }FMCIO_ODR __attribute__((bitband)); FMCIO_ODR *FMC_EXTIO = (FMCIO_ODR *)0x60001000;
比如控制AD7606的OS0引脚高电平就是
FMC_EXTIO->tAD7606_OS0 = 1;
控制OS0引脚是低电平就是:
FMC_EXTIO->tAD7606_OS0 = 0;
简单易用,超方便。
M7内核为什么不支持
M内核权威指南作者Joseph Yiu回复:
1、Cache问题,如果SRAM所在区域开启了读写Cache,使用位带操作的话,会有数据一致性问题。
2、位带需要总线锁机制,在AHB总线协议中这相对容易实现,但在AXI总线协议中这有点混乱,并且在锁定序列期间,它可能导致其他总线主控的延迟更长。
