I. 正则表达式(regular expression)
正则表达式是专门处理文本字符串的正式语言(这个是基础中的基础,就不再详细叙述,不了解的可以看这里)。
- []: 分割符,匹配任何在中括号里面的字符。比如
[Ww]匹配大小写W;[0-9]匹配所有数字 - ^(在字符前): 负选择,匹配除括号以外的字符。比如
[^A-W]匹配所有非大写字符;[^e^]匹配所有e和^以外的字符 - |:或者。比如a|b|c等价于
[a-c] - *:匹配大于等于0个符号前面的字符;+:匹配至少一个前面的字符;.:匹配所有单个字符;?:匹配0或1个前面的字符
- :转义符:将特殊字符转化为简单字符。比如.匹配所有字符,.匹配.。
- 锚定符。^:匹配开头;(:匹配结尾。比如:^[a-z]匹配非小写字母开头的字符串;.)匹配所有.结尾的字符串。
匹配的错误类型:
- 一类错误(type I error):假阳性。匹配上不想匹配的字符串。比如只想匹配单词the却匹配上了other。
- 二类错误(type II error):假阴性。没有匹配上想要的字符串。比如像匹配单词the却没有匹配The。
基本上在NLP分析过程(甚至是所有机器学习问题)都是在处理这两类错误。减少一类错误(假阳性)意味着提高模型精度;减少二类错误(假阴性)意味着增加召回率。
总结:
正则表达式很强大,通配操作很方便,一般也是文本处理的第一步。在许多困难的任务中用到的机器学习分类器也会使用正则表达式作为特征。
II. 分词
文本标准化一般操作:1.断句。 2.分词。 3. 统一词格式(大小写,复数单数形式,所有格形式等)。
词根(lemma)和词形(wordform)
<img src="http://images2015.cnblogs.com/blog/947235/201612/947235-20161218161223042-1917227413.png" width="60% />
**类型(type)和标记(token)
类型是指词典中的一个成分(不计重复和词形变化)
token是指类型具体的一个例子。(可以重复)
比如:

例子中的San Francisco可以拆开作为两个token,也可以整个作为一个token;而前后两个the只能算作一个type,而they和their也可以看成一个type
统计语料(corpus)时,一般默认用N代表tokens的数量;用V代表词汇库,即所有类型;|V|代表词汇库的大小。
Church & Gale(1990)提出|V| > O(N^1/2)
{kind=link}
分词过程的一些问题:
- 缩写(有些包含标点符号)

- 其他语言
- 法语:

- 德语:复合名称之间没有空格

- 中文和日文:单词之间没有空格
中文分词:
中文由字符组成,每个字符一般时单音节和单字形的;平均每个单词包含2.4个字符。中文标准基线的分词算法是最大匹配算法(maximum matching algorithm)或贪婪算法(greedy algorithm)。

这里,由于中文的单词长度相对比较一致,因此这个方法效果比较好,但是这个方法对英语来说并不合适,因为英文单词长短差异很大且常长度不同的单词一般都混杂在一起使用。因此目前主流的分词算法都采用了概率模型。
III. 词标准化和词干提取
- 标准化
信息提取的时候,indexed text和query terms需要有相同的格式。比如U.S.A --> USA
上述处理可以通过删除词内.号实现。
非对称推广(asymmetric expansion):比如:

但是实际操作中为了降低时间复杂性等考虑一般还是会采用对称推广。 - 大小写折叠(Case Folding):将所有大写字符转换成小写字符
可能的例外:句中间的大写字符,比如General Motors;缩写单词的大写字符,比如Fed(Federal reserve bank) - 词形还原(lemmatization)
将词的变体转换为原型词根(寻找不同变体的共同词头)。比如:
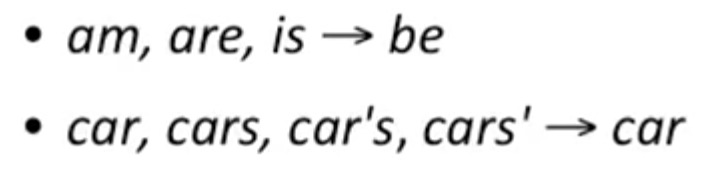
构词(morphology):词素(morpheme)是指构成词的最小的有语法意义单位。由词干(stem)和词缀(affix)组成。

其中方框内的就是词干,而圆圈内的就是词缀。 - 词干化(stemming)
在信息提取时将词转换成其词干形式,而词干化就是将词的词缀去除留下词干(这一过程时语言依赖的,不同语言的词干化规则不同)。比如:

最著名的词干分析器是Porter's algorithm:这是由一系列按顺序排列的词干化规则组成

IV. 分句
将文本分成按边界一个个单句。!和?是很清晰的句子边界标志,但是.号不是。.号可以作为句子边界,缩写标志(Inc.和Dr.等)以及浮点数(.2%和4.3等)。因此在判断.号是否为边界的时候可以采用包括决策树,正则表达式,SVM,logistic regression , neural network等分类器来进行判断。
由于决策树只需通过if-else进行判断,所以利用决策树作为分类器十分直观易懂。决策树的关键在于选取特征。比如提取.号相关的文本特征:

但是除非特征数很少,否则很难手动进行决策树的构建,因为对于大部分数字型特征都需要设定阈值。所以一般都是通过机器学习的方式从语料自动学习来生成结构。